
Maison >Périphériques technologiques >IA >NTU et Shanghai AI Lab ont compilé plus de 300 articles : la dernière revue de la segmentation visuelle basée sur Transformer est publiée
NTU et Shanghai AI Lab ont compilé plus de 300 articles : la dernière revue de la segmentation visuelle basée sur Transformer est publiée

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-07-04 12:25:081333parcourir
SAM (Segment Anything), en tant que modèle de segmentation visuelle de base, a attiré l'attention et le suivi de nombreux chercheurs en seulement 3 mois. Si vous souhaitez comprendre systématiquement la technologie derrière SAM, suivre le rythme de l'involution et être capable de créer votre propre modèle SAM, alors cette enquête de segmentation basée sur un transformateur est à ne pas manquer ! Récemment, plusieurs chercheurs de l'Université technologique de Nanyang et du Laboratoire d'intelligence artificielle de Shanghai ont rédigé une revue sur la segmentation basée sur Transformer, examinant systématiquement les modèles de segmentation et de détection basés sur Transformer ces dernières années. Le dernier modèle étudié date de juin de cette année ! Dans le même temps, la revue comprend également les derniers articles dans des domaines connexes et un grand nombre d'analyses et de comparaisons expérimentales, et révèle un certain nombre d'orientations de recherche futures avec de larges perspectives !
La segmentation visuelle est conçue pour diviser des images, des images vidéo ou des nuages de points en plusieurs segments ou groupes. Cette technologie a de nombreuses applications concrètes, telles que la conduite autonome, l’édition d’images, la perception des robots et l’analyse médicale. Au cours de la dernière décennie, les méthodes basées sur le deep learning ont fait des progrès significatifs dans ce domaine. Récemment, Transformer est devenu un réseau neuronal basé sur un mécanisme d'auto-attention, initialement conçu pour le traitement du langage naturel, qui surpasse considérablement les méthodes convolutives ou récurrentes précédentes dans diverses tâches de traitement visuel. Plus précisément, Vision Transformer fournit des solutions puissantes, unifiées et encore plus simples pour une variété de tâches de segmentation. Cette revue fournit un aperçu complet de la segmentation visuelle basée sur Transformer, résumant les avancées récentes. Tout d'abord, cet articlepasse en revue le contexte, y compris la définition du problème, les ensembles de données et les méthodes de convolution précédentes. Ensuite, cet article résume une méta-architecture qui unifie toutes les méthodes récentes basées sur Transformer. Sur la base de cette méta-architecture, cet article étudie diverses conceptions de méthodes, y compris les modifications de cette méta-architecture et les applications associées. De plus, cet article présente également plusieurs paramètres connexes, notamment la segmentation des nuages de points 3D, le réglage du modèle de base, la segmentation adaptative de domaine, la segmentation efficace et la segmentation médicale. De plus, cet article compile et réévalue ces méthodes sur plusieurs ensembles de données largement reconnus. Enfin, l'article identifie les défis ouverts dans ce domaine et propose des orientations pour les recherches futures. Cet article continuera et suivra les dernières méthodes de segmentation et de détection basées sur Transformer.
Pictures Adresse du projet : https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
Adresse du projet : https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
Adresse papier : https://arxiv.org/pdf/2304.09854.pdf
Motivation de la recherche
L'émergence de ViT et DETR a fait de pleins progrès dans le domaine de la segmentation et de la détection. Actuellement, les méthodes les mieux classées sur presque tous les benchmarks d'ensembles de données sont basées sur Transformer. Pour cette raison, il est nécessaire de résumer et de comparer systématiquement les méthodes et caractéristiques techniques de cette direction.
- Les architectures de grands modèles récentes sont toutes basées sur la structure Transformer, y compris les modèles multimodaux et les modèles de base de segmentation (SAM), et diverses tâches visuelles se rapprochent de la modélisation de modèles unifiées.
- La segmentation et la détection ont dérivé de nombreuses tâches connexes en aval, et bon nombre de ces tâches sont également résolues à l'aide de la structure Transformer.
- Caractéristiques de révision
- Systématique et lisible.
- Cet article passe systématiquement en revue chaque définition de tâche de segmentation, ainsi que les définitions de tâches associées et les indicateurs d'évaluation. Et cet article part de la méthode de convolution et résume une méta-architecture basée sur ViT et DETR. Sur la base de cette méta-architecture, cette revue résume et résume les méthodes associées, et passe systématiquement en revue les méthodes récentes. Le parcours d’examen technique spécifique est illustré à la figure 1. Classement détaillé d'un point de vue technique.
- Par rapport aux critiques précédentes de Transformer, la classification des méthodes de cet article sera plus détaillée. Cet article rassemble des articles ayant des idées similaires et compare leurs similitudes et leurs différences. Par exemple, cet article classifiera les méthodes qui modifient simultanément le côté décodeur de la méta-architecture en modélisation d'attention croisée basée sur l'image et en modélisation d'attention croisée spatio-temporelle basée sur la vidéo. Exhaustivité de la question de recherche.
- Cet article passera systématiquement en revue toutes les directions de segmentation, y compris les tâches de segmentation d'images, de vidéos et de nuages de points. Dans le même temps, cet article passera également en revue les orientations connexes telles que les modèles de segmentation et de détection en ensembles ouverts, la segmentation non supervisée et la segmentation faiblement supervisée.
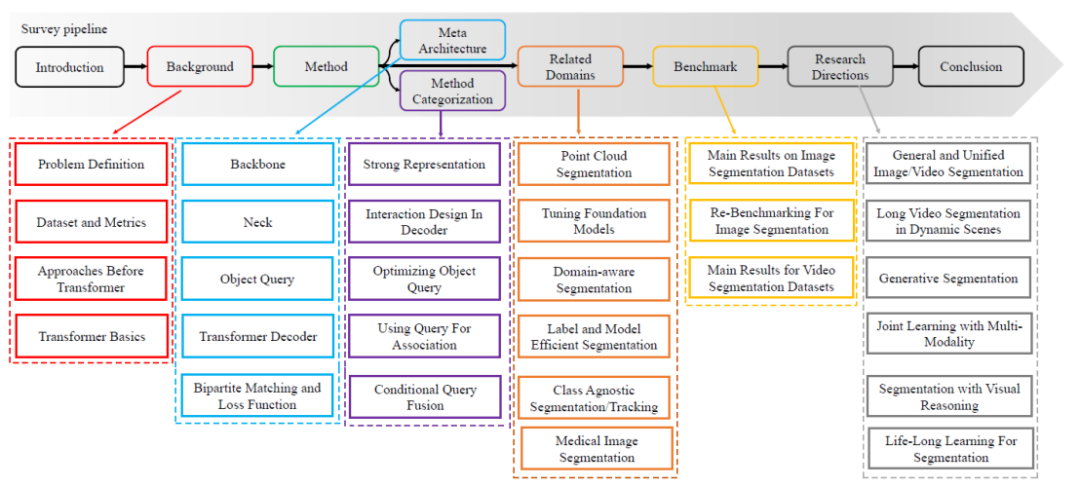 Figure 1. Feuille de route du contenu de l'enquête
Figure 1. Feuille de route du contenu de l'enquête
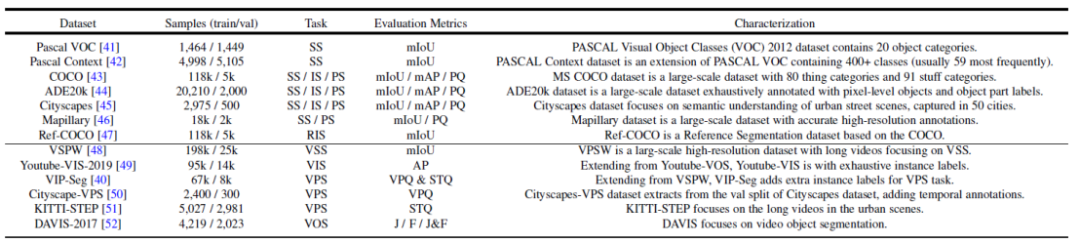
Figure 2. Résumé des ensembles de données et des tâches de segmentation couramment utilisés
Résumé et comparaison des méthodes de segmentation et de détection basées sur les transformateurs
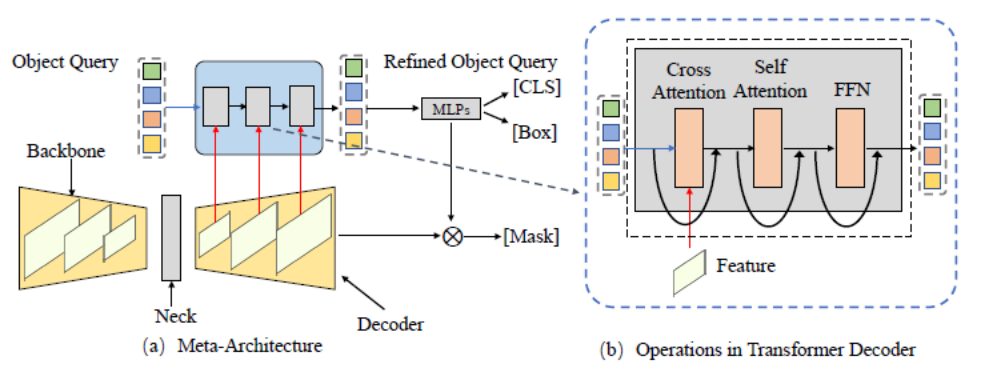
Figure 3. Cadre général de méta-architecture (méta - Architecture)
Cet article résume dans un premier temps une méta-architecture basée sur les frameworks DETR et MaskFormer. Ce modèle comprend les différents modules suivants :
- Backbone : Extracteur de fonctionnalités, utilisé pour extraire les fonctionnalités de l'image.
- Cou : Créez des fonctionnalités multi-échelles pour gérer des objets multi-échelles.
- Requête d'objet : Objet de requête, utilisé pour représenter chaque entité de la scène, y compris les objets de premier plan et les objets d'arrière-plan.
- Decoder : Decoder, utilisé pour optimiser progressivement la requête d'objet et les fonctionnalités correspondantes.
- Formation de bout en bout : La conception basée sur Object Query peut réaliser une optimisation de bout en bout.
Sur la base de cette méta-architecture, les méthodes existantes peuvent être divisées dans les cinq directions différentes suivantes pour l'optimisation et l'ajustement en fonction des tâches. Comme le montre la figure 4, chaque direction contient plusieurs sous-directions différentes.
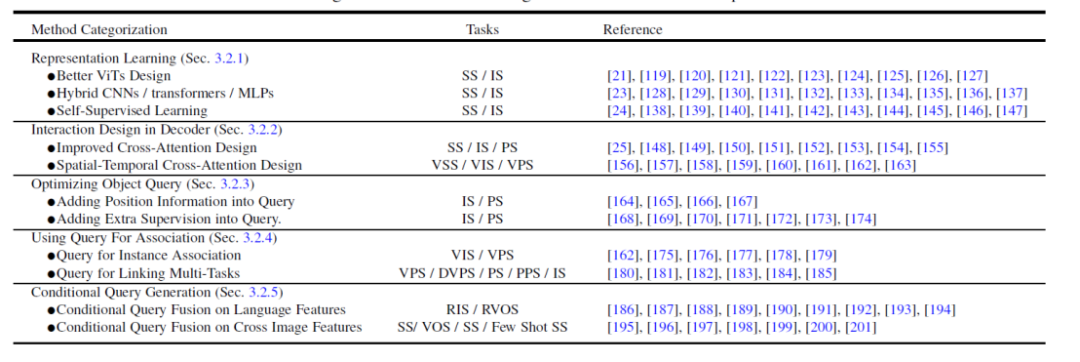
Figure 4. Résumé et comparaison des méthodes de segmentation basée sur un transformateur
- Meilleur apprentissage de l'expression des fonctionnalités, apprentissage de la représentation. Une représentation visuelle puissante des caractéristiques conduit toujours à de meilleurs résultats de segmentation. Cet article divise les travaux connexes en trois aspects : une meilleure conception visuelle du Transformer, un CNN/Transformer/MLP hybride et un apprentissage auto-supervisé.
- Method design côté décodeur, Interaction Design in Decoder. Ce chapitre passe en revue la nouvelle conception du décodeur Transformer. Cet article divise la conception du décodeur en deux groupes : l'un est utilisé pour améliorer la conception de l'attention croisée dans la segmentation d'images, et l'autre est utilisé pour améliorer la conception de l'attention croisée spatio-temporelle dans la segmentation vidéo. Le premier se concentre sur la conception d’un meilleur décodeur qui améliore celui du DETR original. Ce dernier étend les détecteurs et segmenteurs d'objets basés sur des requêtes au domaine vidéo pour la détection d'objets vidéo (VOD), la segmentation d'instances vidéo (VIS) et la segmentation de pixels vidéo (VPS), en se concentrant sur la modélisation de la cohérence temporelle et de la corrélation sexuelle.
- Essayez d'optimiser la requête d'objet du point de vue de l'optimisation des objets de requête. Par rapport à Faster-RCNN, DETR a un calendrier de convergence plus long. En raison du rôle clé des objets de requête, certaines méthodes existantes ont été étudiées pour accélérer la formation et améliorer les performances. Selon la méthode de requête d'objet, cet article divise la littérature suivante en deux aspects : l'ajout d'informations de localisation et l'utilisation d'une supervision supplémentaire. Les informations de localisation fournissent des indices pour un échantillonnage de formation rapide des fonctionnalités de requête. Une supervision supplémentaire se concentre sur la conception de fonctions de perte spécifiques en plus de la fonction de perte par défaut DETR.
- Utilisez des objets de requête pour associer des fonctionnalités et des instances, à l'aide de Query For Association. Bénéficiant de la simplicité des objets de requête, plusieurs études récentes les ont utilisés comme outils de corrélation pour résoudre des tâches en aval. Il existe deux utilisations principales : l'une est l'association au niveau de l'instance et l'autre est l'association au niveau de la tâche. Le premier utilise l'idée de discrimination d'instance pour résoudre les problèmes de correspondance au niveau des instances dans les vidéos, tels que la segmentation et le suivi des vidéos. Ce dernier utilise des objets de requête pour relier différentes sous-tâches afin de réaliser un apprentissage multitâche efficace.
- Génération d'objets de requête conditionnelle multimodale, génération de requêtes conditionnelles. Ce chapitre se concentre principalement sur les tâches de segmentation multimodale. Les objets de requête de requête conditionnelle sont principalement utilisés pour gérer les tâches de correspondance de fonctionnalités intermodales et inter-images. En fonction des conditions de saisie de la tâche, la tête de décodage utilise différentes requêtes pour obtenir les masques de segmentation correspondants. Selon les sources des différentes entrées, cet article divise ces travaux en deux aspects : les caractéristiques du langage et les caractéristiques de l'image. Ces méthodes sont basées sur la stratégie de fusion d'objets de requête avec différentes fonctionnalités de modèle et ont obtenu de bons résultats dans plusieurs tâches de segmentation multimodale et dans la segmentation en quelques coups.
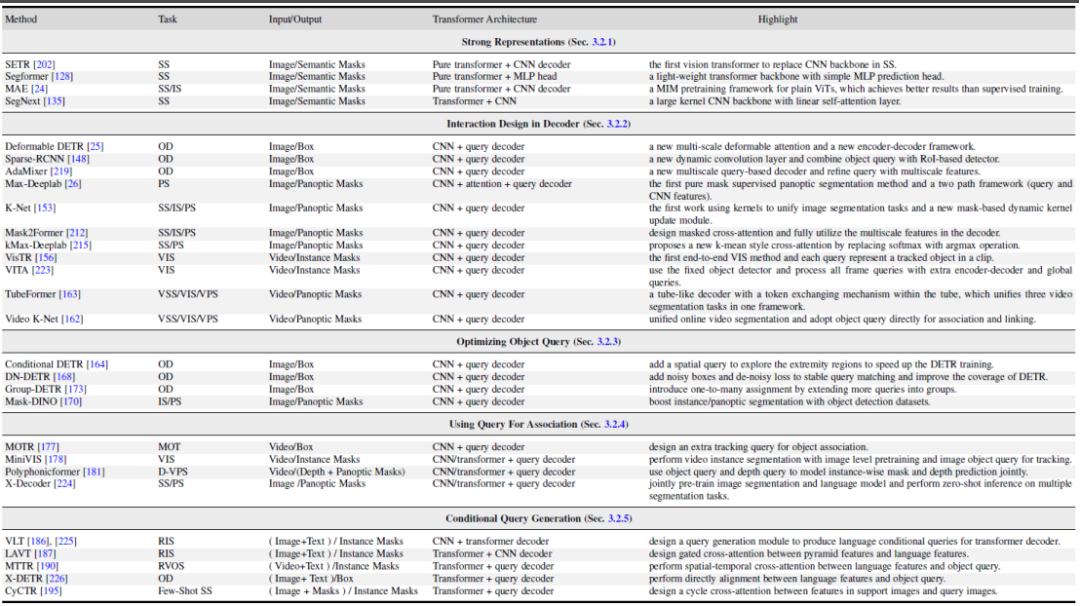
La figure 5 montre quelques comparaisons de travaux représentatives dans ces 5 directions différentes. Pour des détails et des comparaisons plus spécifiques sur les méthodes, veuillez vous référer au contenu de l’article.
 Photos
Photos
Figure 5. Résumé et comparaison des méthodes représentatives de segmentation et de détection basées sur un transformateur
Résumé et comparaison des méthodes dans des domaines de recherche connexes
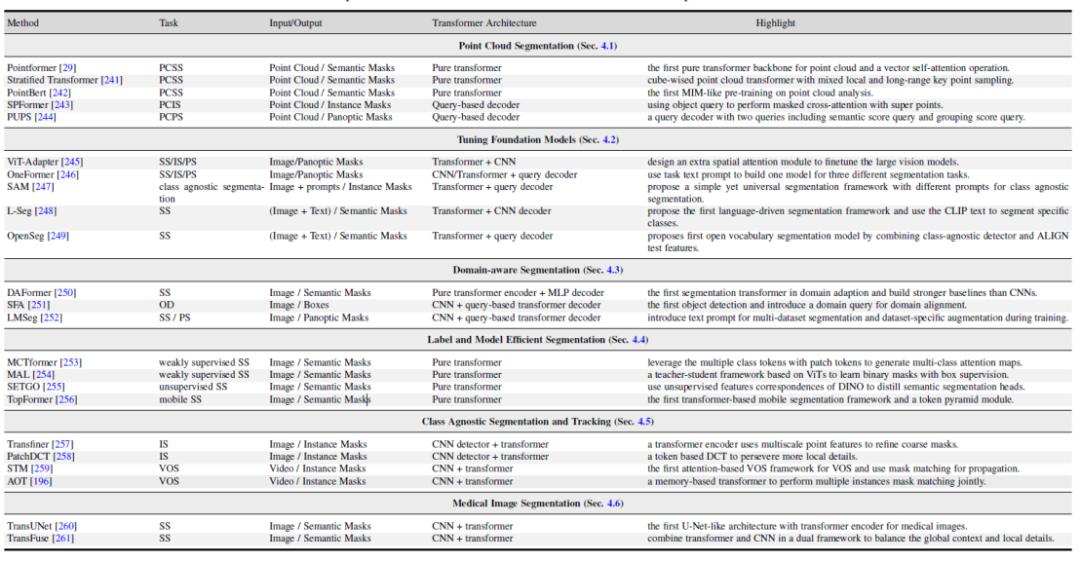
Cet article explore également plusieurs domaines connexes : 1. Méthode de segmentation des nuages de points basée sur un transformateur. 2. Vision et réglage multimodal des grands modèles. 3. Recherche sur les modèles de segmentation liés au domaine, y compris l'apprentissage par transfert de domaine et l'apprentissage par généralisation de domaine. 4. Segmentation sémantique efficace : modèles de segmentation non supervisés et faiblement supervisés. 5. Segmentation et suivi indépendants de la classe. 6. Segmentation des images médicales.
 Photos
Photos
Figure 6. Résumé et comparaison des méthodes basées sur les transformateurs dans des domaines de recherche connexes ensemble de données de segmentation
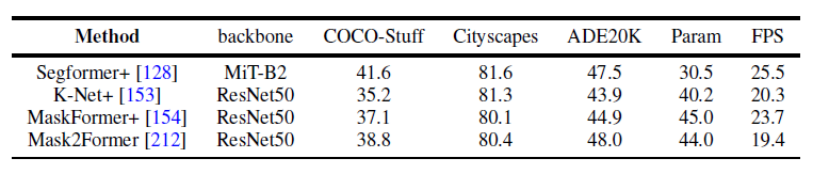
Cet article utilise également uniformément les mêmes conditions de conception expérimentale pour comparer les résultats de plusieurs travaux représentatifs sur plusieurs ensembles de données sur la segmentation panoramique et la segmentation sémantique. Il a été constaté qu’en utilisant la même stratégie de formation et le même encodeur, l’écart entre les performances des méthodes se réduirait. De plus, cet article compare également les résultats des récentes méthodes de segmentation basées sur Transformer sur plusieurs ensembles de données et tâches différents. (Segmentation sémantique, segmentation d'instance, segmentation panoramique et tâches de segmentation vidéo correspondantes) De plus, cet article fournit également une analyse de certaines orientations de recherche futures possibles. Trois directions différentes sont données ici à titre d’exemple. Pour plus d'orientations de recherche, veuillez vous référer à l'article original. Orientations futures
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI