
Maison >Périphériques technologiques >IA >Il peut surpasser les humains en deux heures ! Le dernier speedrun IA de DeepMind exécute 26 jeux Atari
Il peut surpasser les humains en deux heures ! Le dernier speedrun IA de DeepMind exécute 26 jeux Atari

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-07-03 20:57:171504parcourir
L’agent IA de DeepMind se taquine encore !
Regardez ce type nommé BBF. Il a maîtrisé 26 jeux Atari en seulement 2 heures. Son efficacité est comparable à celle des humains, surpassant tous ses prédécesseurs.
Il faut savoir que les agents d'IA ont toujours été efficaces pour résoudre des problèmes grâce à l'apprentissage par renforcement, mais le plus gros problème est que cette méthode est très inefficace et nécessite beaucoup de temps à explorer.
 Photos
Photos
La avancée apportée par BBF se situe justement en termes d'efficacité.
Pas étonnant que son nom complet puisse être appelé Bigger, Better ou Faster.
Et il peut effectuer une formation sur une seule carte, et les besoins en puissance de calcul sont également considérablement réduits.
BBF a été proposé conjointement par Google DeepMind et l'Université de Montréal. Les données et le code sont actuellement open source.
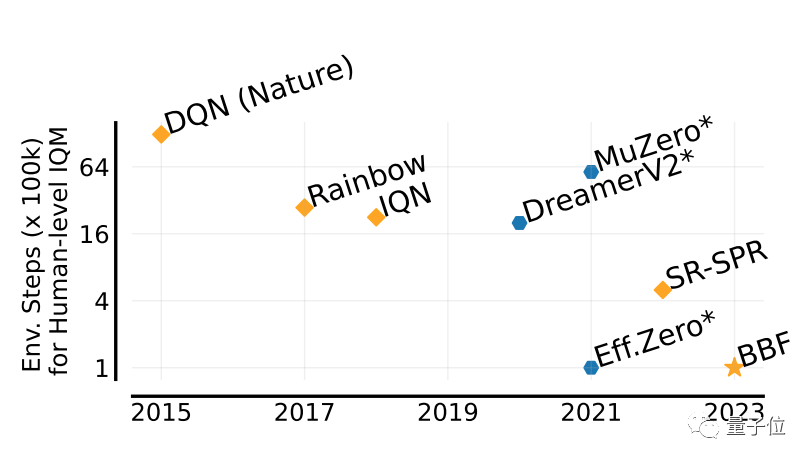
Peut atteindre jusqu'à 5 fois les performances des humains
La valeur utilisée pour évaluer les performances des jeux BBF est appelée IQM.
IQM est un score complet de performances de jeu à multiples facettes. Les scores IQM présentés dans cet article sont normalisés sur la base des humains.
Par rapport à plusieurs résultats précédents, BBF a obtenu le score IQM le plus élevé dans l'ensemble de données de test Atari 100K contenant 26 jeux Atari.
Et, dans les 26 jeux sur lesquels il a été entraîné, les performances de BBF ont dépassé celles des humains.
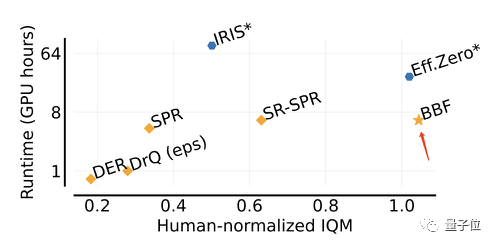
Comparé à Eff.Zero, qui fonctionne de manière similaire, BBF consomme près de la moitié du temps GPU.
Quant à SPR et SR-SPR, qui consomment le même temps GPU, leurs performances sont loin derrière BBF.
 Photo
Photo
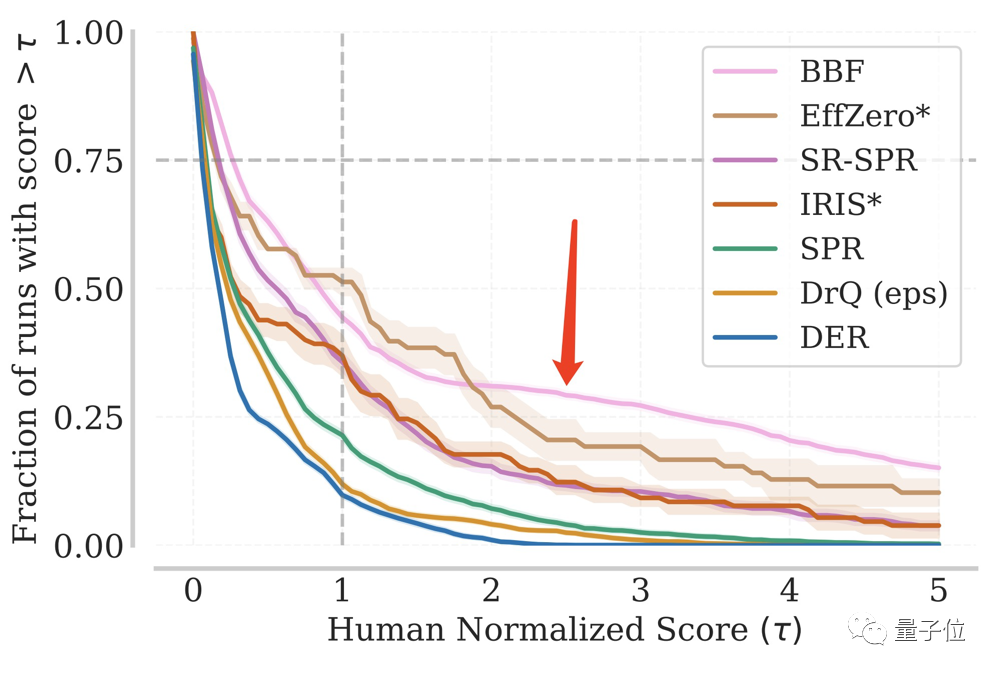
Dans des tests répétés, la proportion de BBF atteignant un certain score IQM est toujours restée à un niveau élevé.
Même dans plus d'un huitième du total des tests, il a atteint 5 fois les performances des humains.
 Photos
Photos
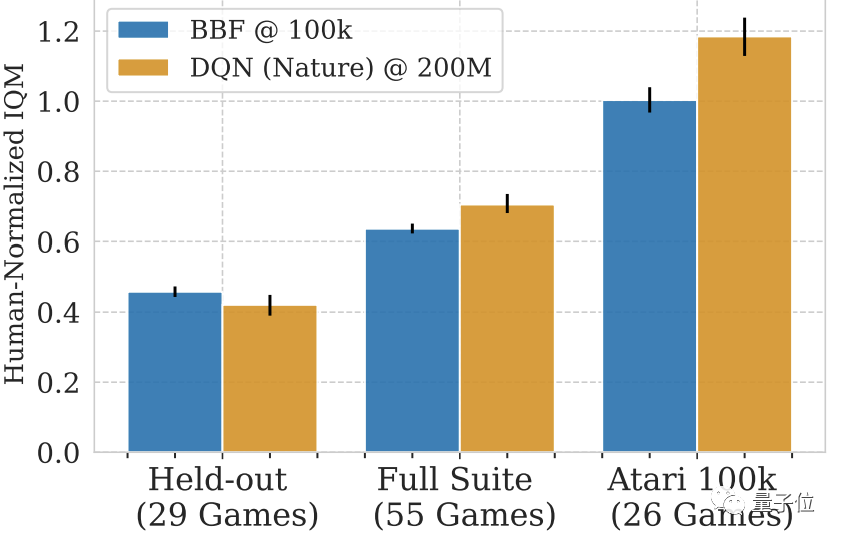
Même avec l'ajout d'autres jeux Atari sans formation, BBF peut atteindre plus de la moitié du score IQM d'un humain.
Si vous regardez uniquement ces 29 jeux non entraînés, le score de BBF est de 40 à 50 % celui des humains.
 Photos
Photos
Modifiées sur la base du SR-SPR
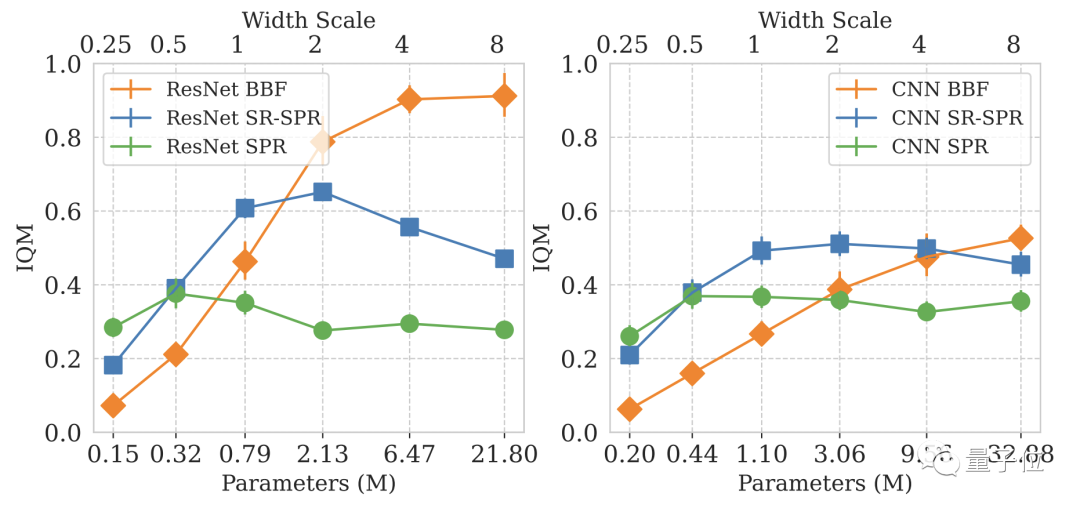
Le problème qui anime la recherche BBF est de savoir comment étendre les réseaux d'apprentissage par renforcement profond lorsque la taille de l'échantillon est clairsemée.
Pour étudier ce problème, DeepMind s'est concentré sur le benchmark Atari 100K.
Mais DeepMind a vite découvert que la simple augmentation de la taille du modèle n'améliorait pas ses performances.
 Photos
Photos
Dans la conception de modèles de deep learning, le nombre de mises à jour par étape (Replay Ratio, RR) est un paramètre important.
Spécifiquement pour les jeux Atari, plus la valeur RR est élevée, plus les performances du modèle dans le jeu sont élevées.
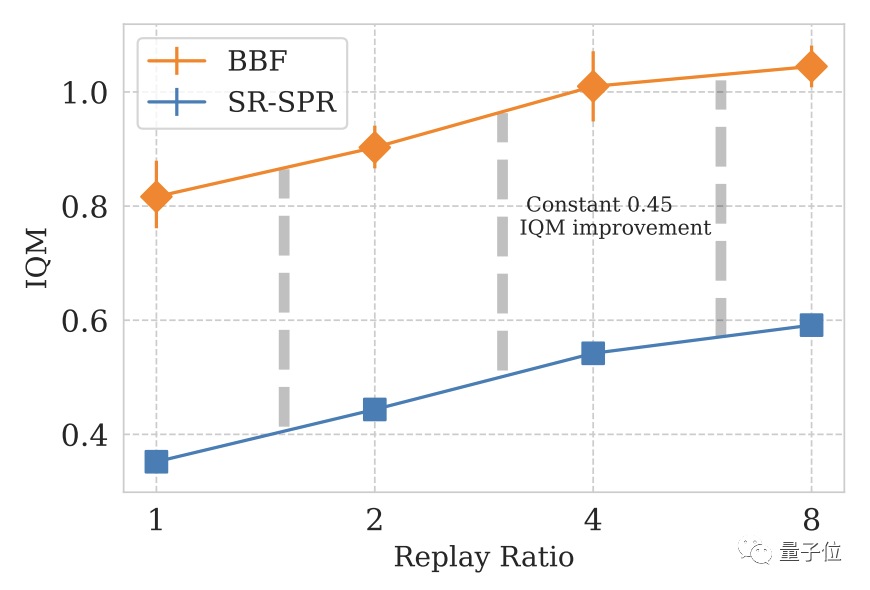
Enfin, DeepMind utilise SR-SPR comme moteur de base, et la valeur RR de SR-SPR peut atteindre jusqu'à 16.
Après un examen approfondi, DeepMind a choisi 8 comme valeur RR de BBF.
Considérant que certains utilisateurs ne sont pas disposés à dépenser le coût informatique de RR=8, DeepMind a également développé la version RR=2 de BBF
 Pictures
Pictures
Après que DeepMind ait modifié de nombreux contenus dans SR-SPR, il a adopté le sien La formation en supervision obtenue par BBF comprend principalement les aspects suivants :
- Force de réinitialisation de la couche de convolution plus élevée : l'augmentation de la force de réinitialisation de la couche de convolution peut augmenter l'amplitude de perturbation pour des cibles aléatoires, permettant au modèle de mieux fonctionner et de réduire les pertes. Une fois la force de réinitialisation de BBF augmentée, l'amplitude de perturbation passe de SR à SR. . -SPR augmenté de 20% à 50%
- Taille du réseau plus grande : augmentez le nombre de couches de réseau neuronal de 3 à 15 couches et augmentez la largeur de 4 fois
- Réduction de la plage de mise à jour (n) : vous souhaitez améliorer le modèle. La performance nécessite l'utilisation de valeurs non fixes de n. BBF est réinitialisé tous les 40 000 pas de gradient. Au cours des 10 000 premiers pas de gradient de chaque réinitialisation, n diminue de façon exponentielle de 10 à 3. La phase de décroissance représente 25 % du processus de formation du BBF
- Facteur de décroissance plus important (γ) : certaines personnes ont a constaté que l'augmentation de la valeur γ pendant le processus d'apprentissage peut améliorer les performances du modèle. La valeur γ de BBF passe de la valeur traditionnelle de 0,97 à 0,997
- Atténuation du poids : pour éviter l'apparition d'un surapprentissage, l'atténuation de BBF est d'environ 0,1
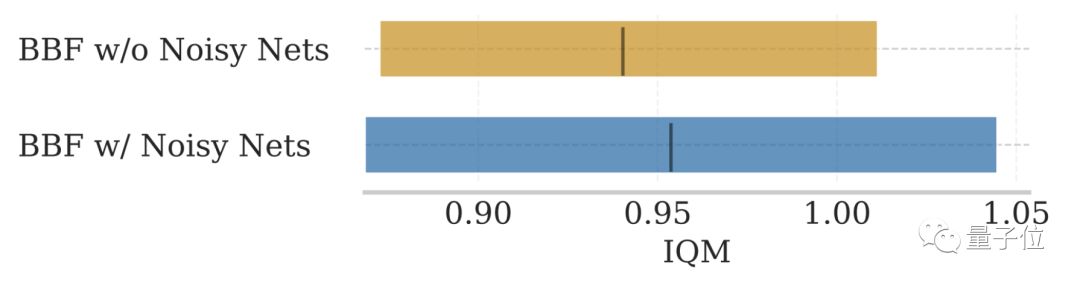
- Supprimer NoisyNet. : NoisyNet inclus dans le SR-SPR d'origine ne peut pas améliorer les performances du modèle
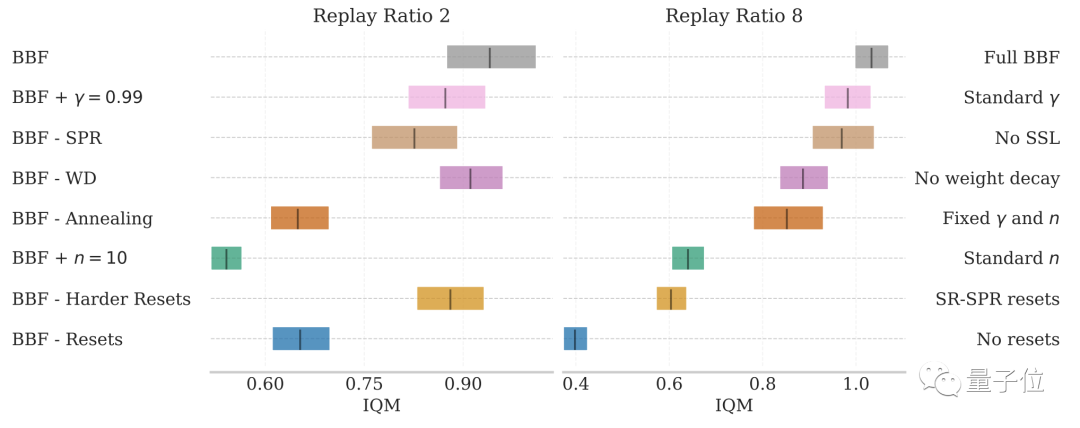
Les résultats expérimentaux d'ablation montrent que dans les conditions de 2 et 8 mises à jour par étape, les facteurs ci-dessus ont différents degrés d'impact sur les performances de BBF.
 Photos
Photos
Parmi eux, l'impact de la réinitialisation matérielle et de la réduction de la plage de mise à jour est le plus important.
 Photos
Photos
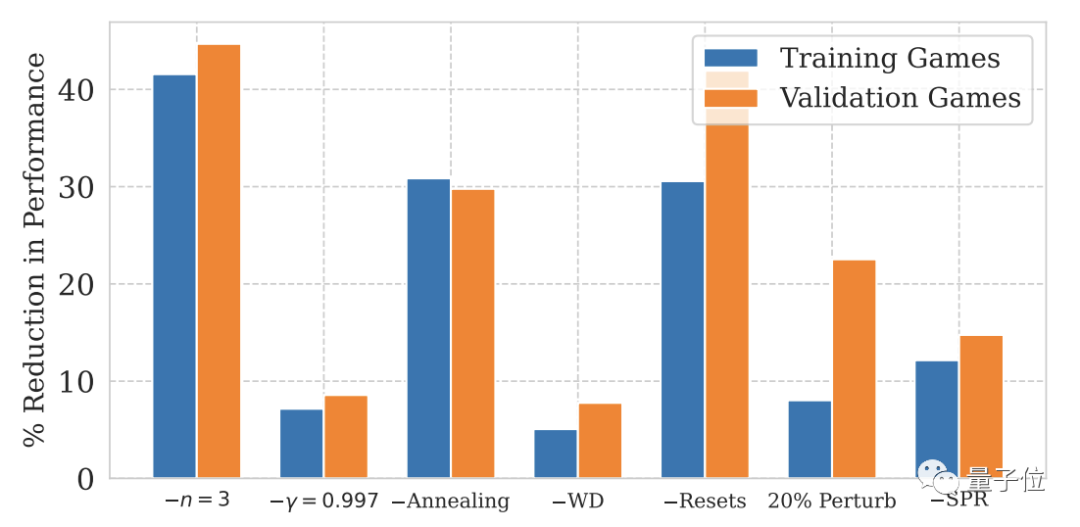
Pour NoisyNet, qui n'est pas mentionné dans les deux chiffres ci-dessus, l'impact sur les performances du modèle n'est pas significatif.
 Photos
Photos
Adresse papier : https://arxiv.org/abs/2305.19452Page du projet GitHub : https://github.com/google-research/google-research/tree/master/bigger_better_faster
Lien de référence : [1]https://www.php.cn/link/69b4fa3be19bdf400df34e41b93636a4
[2]https://www.marktechpost.com/2023/06/12/superhuman-performance-on-the -atari-100k-benchmark-the-power-of-bbf-a-new-value-based-rl-agent-from-google-deepmind-mila-and-universite-de-montreal/
— Fin —
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI