
Maison >Périphériques technologiques >IA >Nouvelle recherche menée par l'équipe de Tian Yuandong : réglage fin < 1 000 étapes, extension du contexte LLaMA à 32 000
Nouvelle recherche menée par l'équipe de Tian Yuandong : réglage fin < 1 000 étapes, extension du contexte LLaMA à 32 000

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-30 15:26:132059parcourir
Alors que chacun continue de mettre à niveau et d'itérer ses propres grands modèles, la capacité du LLM (Large Language Model) à traiter les fenêtres contextuelles est également devenue un indicateur d'évaluation important.
Par exemple, gpt-3.5-turbo d'OpenAI fournit une option de fenêtre contextuelle de 16 000 jetons, et AnthropicAI a augmenté la capacité de traitement des jetons de Claude à 100 000. Quel est le concept d'une grande fenêtre contextuelle de traitement de modèle ? Par exemple, GPT-4 prend en charge 32 000 jetons, ce qui signifie que GPT-4 peut mémoriser jusqu'à environ 50 pages de contenu lors de la conversation ou de la génération. texte.
De manière générale, la capacité des grands modèles de langage à gérer la taille de la fenêtre contextuelle est prédéterminée. Par exemple, la taille du jeton d'entrée du modèle LLaMA publié par Meta AI doit être inférieure à 2048.
Cependant, dans des applications telles que mener de longues conversations, résumer de longs documents ou exécuter des plans à long terme, la limite de fenêtre contextuelle prédéfinie est souvent dépassée et, par conséquent, les LLM capables de gérer des fenêtres contextuelles plus longues sont plus populaires.
Mais cela se heurte à un nouveau problème. Former un LLM avec une longue fenêtre contextuelle à partir de zéro nécessite beaucoup d'investissement. Cela nous amène naturellement à la question : pouvons-nous étendre la fenêtre contextuelle des LLM pré-formés existants ?
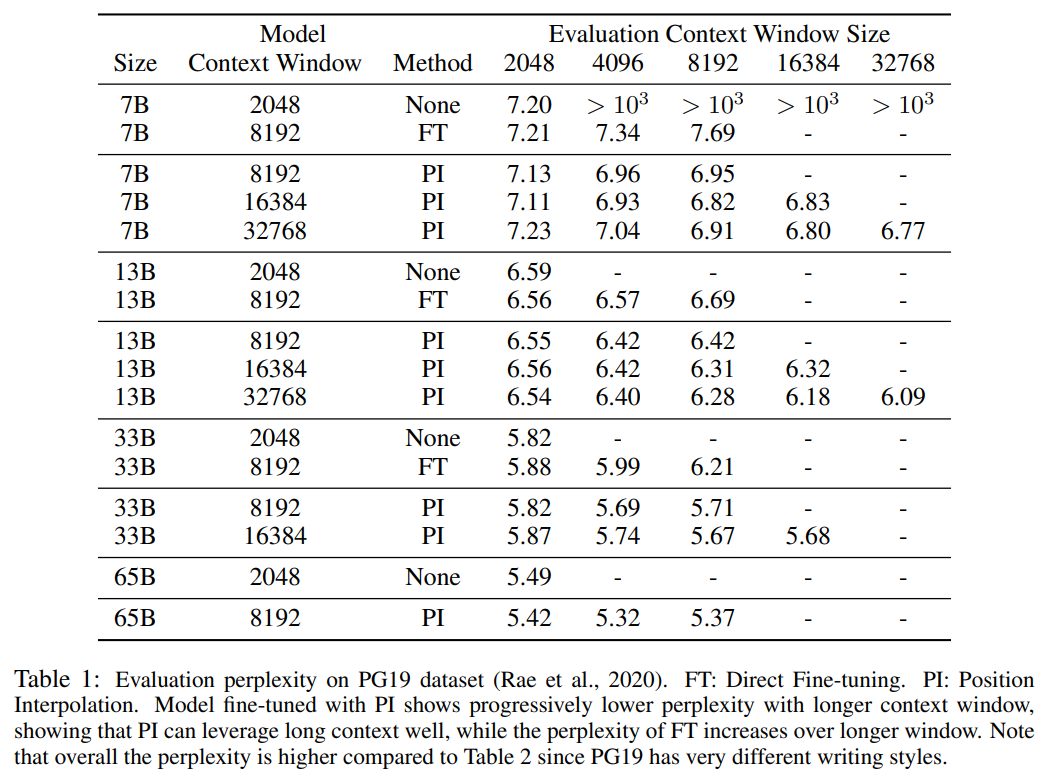
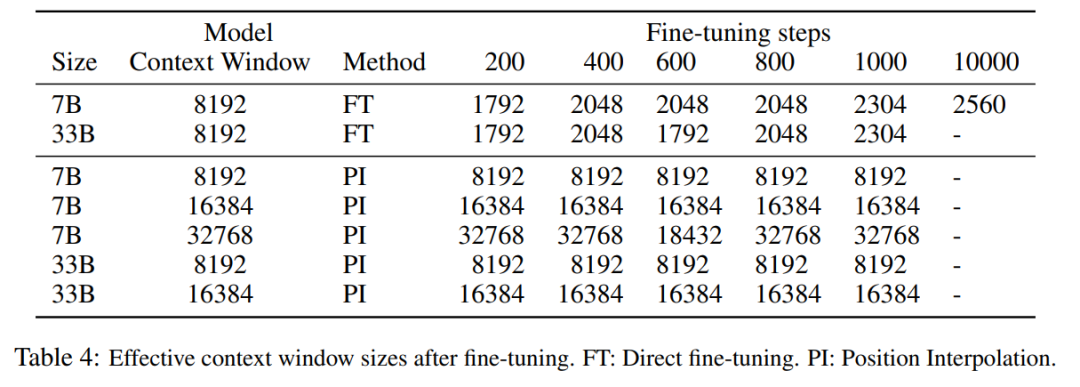
Une approche simple consiste à affiner le Transformer pré-entraîné existant pour obtenir une fenêtre contextuelle plus longue. Cependant, les résultats empiriques montrent que les modèles ainsi formés s’adaptent très lentement aux longues fenêtres contextuelles. Après 10 000 lots de formation, l'augmentation de la fenêtre de contexte effective est encore très faible, seulement de 2 048 à 2 560 (comme le montre le tableau 4 de la section expérimentale). Cela suggère que cette approche est inefficace pour s’adapter à des fenêtres contextuelles plus longues.
Dans cet article, des chercheurs de Meta ont présenté Position Interpolation (PI) pour étendre la fenêtre contextuelle de certains LLM pré-entraînés existants (y compris LLaMA). Les résultats montrent que la fenêtre contextuelle LLaMA évolue de 2 000 à 32 000 avec moins de 1 000 étapes de réglage précis.
 Photos
Photos
Adresse papier : https://arxiv.org/pdf/2306.15595.pdf
L'idée clé de cette recherche n'est pas d'effectuer une extrapolation, mais de réduire directement la position index, Faire en sorte que l'index de position maximum corresponde à la limite de la fenêtre contextuelle de la phase de pré-entraînement. En d’autres termes, afin de prendre en charge davantage de jetons d’entrée, cette étude interpole les codages de position à des positions entières adjacentes, en tirant parti du fait que les codages de position peuvent être appliqués à des positions non entières, par opposition à une extrapolation au-delà des positions entraînées. cette dernière peut conduire à des valeurs catastrophiques. La méthode PI étend la taille de la fenêtre contextuelle des LLM pré-entraînés basés sur RoPE (Rotation Positional Encoding) tels que LLaMA jusqu'à 32 768 avec un réglage fin minimal (dans les 1 000 étapes). Cette recherche fonctionne bien sur une variété de tâches qui nécessitent un contexte long, y compris la récupération, la modélisation du langage et la synthèse de documents longs du LLaMA 7B au 65B. Dans le même temps, le modèle étendu par PI conserve une qualité relativement bonne dans sa fenêtre contextuelle d'origine.
Méthode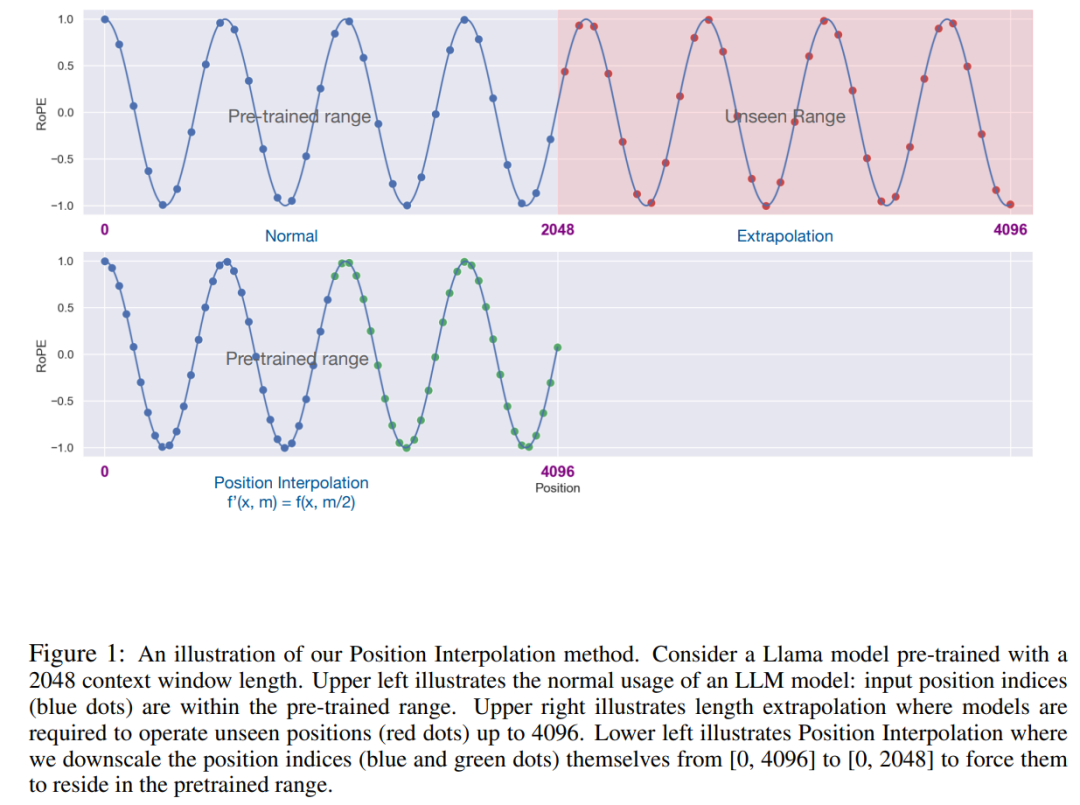
RoPE est présente dans les grands modèles de langage tels que LLaMA, ChatGLM-6B et PaLM que nous connaissons. Cette méthode a été proposée par Su Jianlin et d'autres de Zhuiyi Technology et est implémentée via l'absolu. encodage. Encodage de position relative.
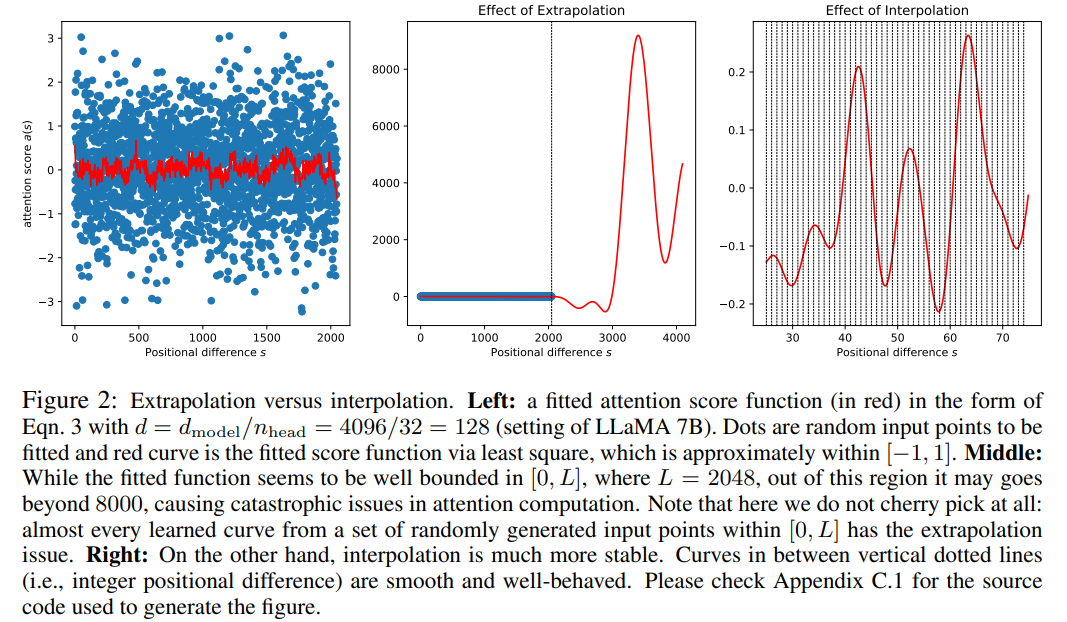
Bien que le score d'attention dans RoPE ne dépende que de la position relative, ses performances d'extrapolation ne sont pas bonnes. En particulier, lors d'une mise à l'échelle directe vers des fenêtres contextuelles plus grandes, la perplexité peut atteindre des nombres très élevés (c'est-à-dire > 10 ^ 3).
Cet article utilise la méthode d'interpolation de position, et sa comparaison avec la méthode d'extrapolation est la suivante. En raison de la fluidité des fonctions de base ϕ_j, l’interpolation est plus stable et ne conduit pas à des valeurs aberrantes.
Picture
Cette étude a remplacé RoPE f par f′ et a obtenu la formule suivante
 Picture
Picture
Cette étude appelle la conversion par interpolation positionnelle d'encodage positionnel. Cette étape réduit l'indice de position de [0, L′ ) à [0, L) pour correspondre à la plage d'index d'origine avant le calcul de RoPE. Par conséquent, en entrée de RoPE, la distance relative maximale entre deux jetons quelconques a été réduite de L ′ à L . En alignant la plage d'indices de position et les distances relatives avant et après l'expansion, l'impact sur les calculs du score d'attention dû à l'expansion de la fenêtre contextuelle est atténué, ce qui facilite l'adaptation du modèle.
Il convient de noter que la méthode de redimensionnement de l'indice de position n'introduit pas de poids supplémentaires et ne modifie en aucune façon l'architecture du modèle.
Expériences
Cette étude démontre que l'interpolation positionnelle peut effectivement étendre la fenêtre contextuelle jusqu'à 32 fois la taille d'origine, et que cette expansion peut être réalisée en seulement quelques centaines d'étapes de formation.
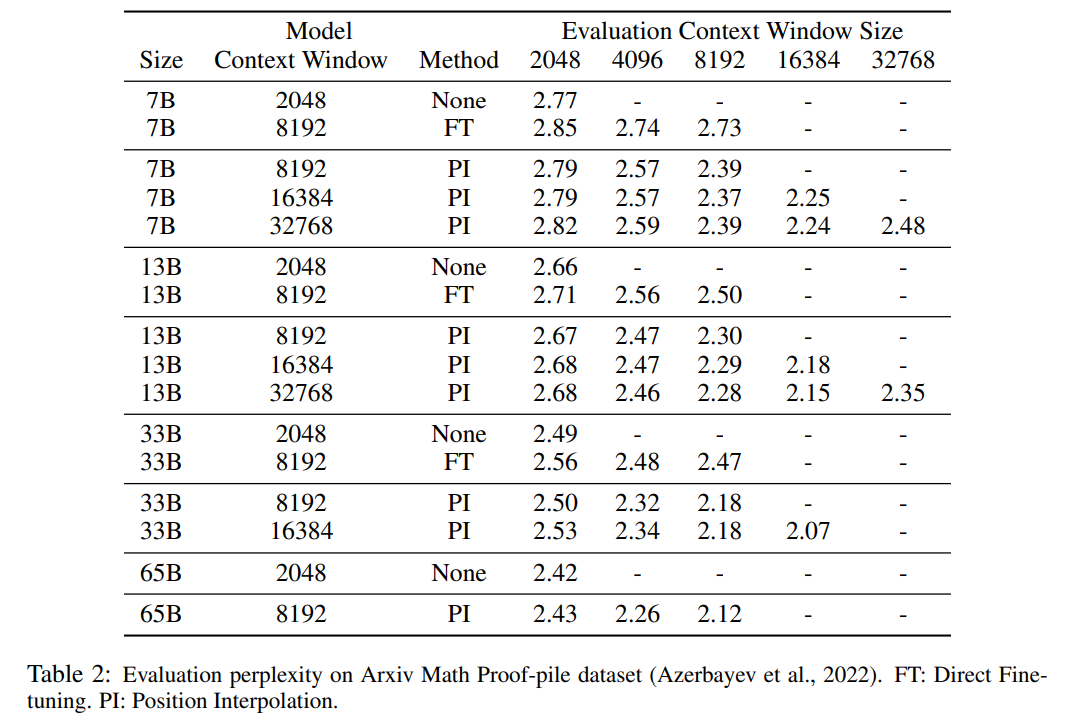
Le Tableau 1 et le Tableau 2 rendent compte de la perplexité du modèle PI et du modèle de base sur les ensembles de données PG-19 et Arxiv Math Proof-pile. Les résultats montrent que le modèle étendu à l’aide de la méthode PI améliore considérablement la perplexité pour des fenêtres contextuelles de plus grande taille.
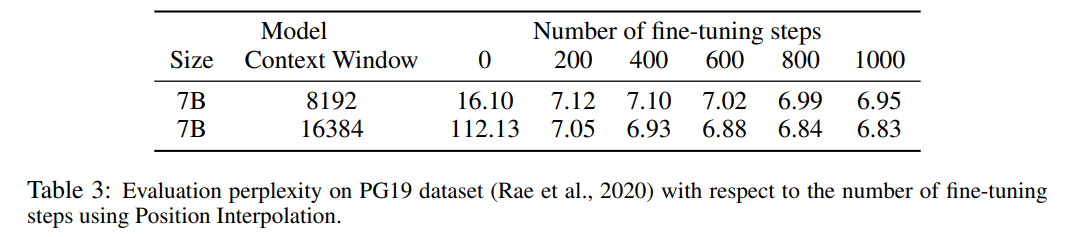
Le Tableau 3 rapporte la relation entre la perplexité et le nombre d'étapes de réglage fin lors de l'extension du modèle LLaMA 7B à 8 192 et 16 384 tailles de fenêtre contextuelle à l'aide de la méthode PI sur l'ensemble de données PG19.
Les résultats montrent que sans réglage fin (le nombre d'étapes est de 0), le modèle peut démontrer certaines capacités de modélisation du langage. Par exemple, lorsque la fenêtre contextuelle est étendue à 8192, la perplexité est moindre. supérieur à 20 (par rapport à Ci-dessous, la perplexité de la méthode d'extrapolation directe est supérieure à 10^3). À 200 étapes, la perplexité du modèle dépasse celle du modèle d'origine avec une taille de fenêtre contextuelle de 2 048, ce qui indique que le modèle est capable d'utiliser efficacement des séquences plus longues pour la modélisation du langage que le paramètre pré-entraîné. À 1000 pas, on peut constater une amélioration constante du modèle et atteindre une meilleure perplexité.
 Photos
Photos
Le tableau ci-dessous montre que le modèle étendu par PI atteint avec succès l'objectif de mise à l'échelle en termes de taille efficace de la fenêtre contextuelle, c'est-à-dire qu'après seulement 200 étapes de réglage fin, la taille effective de la fenêtre contextuelle atteint la valeur maximale, cohérente sur les tailles de modèle 7B et 33B et jusqu'à 32 768 fenêtres contextuelles. En revanche, la taille effective de la fenêtre de contexte du modèle LLaMA étendue uniquement par un réglage fin direct n'a augmenté que de 2 048 à 2 560, sans aucun signe d'augmentation accélérée significative de la taille de la fenêtre, même après plus de 10 000 étapes de réglage fin.
 Photos
Photos
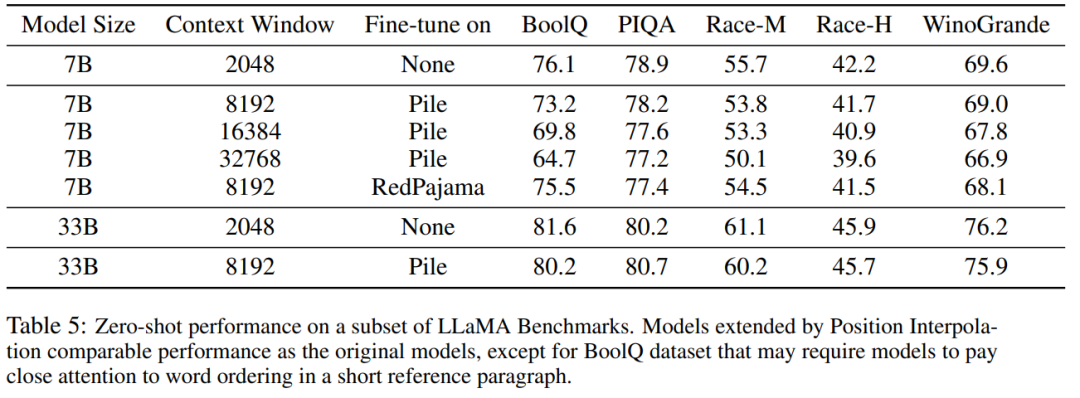
Le tableau 5 montre que le modèle étendu à 8192 produit des résultats comparables sur la tâche de référence originale, qui a été conçue pour des fenêtres de contexte plus petites, pour les tailles de modèle 7B et 33B, la dégradation dans la tâche de référence atteint jusqu'à 2%.
 Images
Images
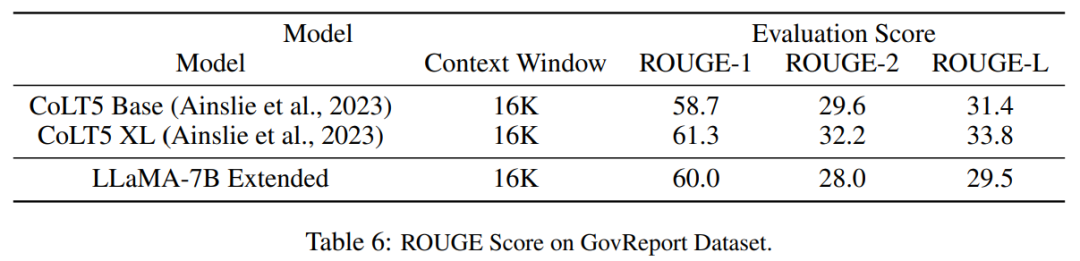
Le tableau 6 montre que le modèle PI avec 16384 fenêtres contextuelles peut gérer efficacement les tâches de résumé de texte long.
 photos
photos
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI