
Maison >Périphériques technologiques >IA >Stratégie d'équilibrage de charge Dubbo, hachage cohérent
Stratégie d'équilibrage de charge Dubbo, hachage cohérent

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-26 15:39:181839parcourir
Cet article explique principalement le principe de l'algorithme de hachage cohérent et son problème d'asymétrie des données existant, puis présente des méthodes pour résoudre le problème d'asymétrie des données et enfin analyse l'utilisation de l'algorithme de hachage cohérent dans Dubbo. Cet article présente le fonctionnement de l'algorithme de hachage cohérent, ainsi que les problèmes et solutions rencontrés par l'algorithme.
1. Load Balancing
Voici une citation du site officiel de Dubbo -
LoadBalance signifie équilibrage de charge en chinois. Sa responsabilité est de "répartir équitablement" les requêtes réseau ou d'autres formes de charge sur différentes machines. Évitez les situations dans lesquelles certains serveurs du cluster subissent une pression excessive tandis que d'autres serveurs sont relativement inactifs. Grâce à l'équilibrage de charge, chaque serveur peut obtenir une charge adaptée à ses propres capacités de traitement. En déchargeant les serveurs à forte charge, vous pouvez également éviter de gaspiller des ressources et faire d'une pierre deux coups. L'équilibrage de charge peut être divisé en équilibrage de charge logicielle et en équilibrage de charge matérielle. Dans notre développement quotidien, il est généralement difficile d’accéder à l’équilibrage de charge matérielle. Mais l'équilibrage de charge logiciel est toujours disponible, comme Nginx. Dans Dubbo, il existe également le concept d'équilibrage de charge et la mise en œuvre correspondante.
Afin d'éviter une charge excessive sur certains fournisseurs de services, Dubbo doit attribuer les demandes d'appel des consommateurs de services. La charge du fournisseur de services est trop importante, ce qui peut entraîner l'expiration de certaines requêtes. Il est donc indispensable d’équilibrer la charge de chaque prestataire de services. Dubbo fournit 4 implémentations d'équilibrage de charge, à savoir RandomLoadBalance basée sur un algorithme aléatoire pondéré, LeastActiveLoadBalance basée sur l'algorithme de comptage d'appels le moins actif, ConsistentHashLoadBalance basée sur la cohérence du hachage et RoundRobinLoadBalance basée sur un algorithme d'interrogation pondéré. Bien que les codes de ces algorithmes d’équilibrage de charge ne soient pas très longs, la compréhension de leurs principes nécessite certaines connaissances et compréhensions professionnelles.
2. Algorithme de hachage
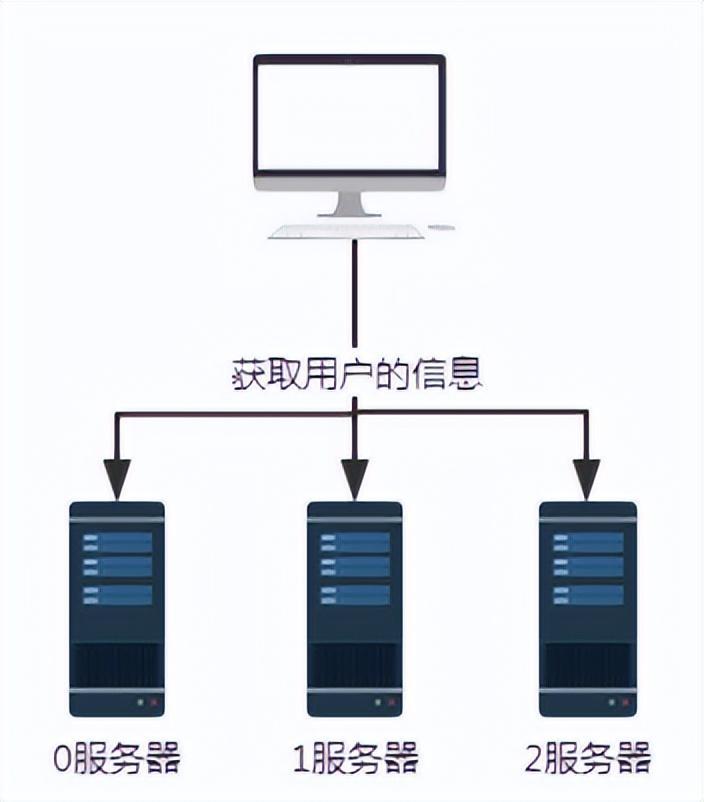
Figure 1 Requête sans algorithme de hachage
Comme indiqué ci-dessus, en supposant que les serveurs 0, 1 et 2 stockent tous les informations utilisateur, alors lorsque nous devons obtenir certaines informations utilisateur, parce que nous Si nous ne savons pas sur quel serveur les informations utilisateur sont stockées, nous devons interroger respectivement les serveurs 0, 1 et 2. L'efficacité de l'obtention de données de cette manière est extrêmement faible.
Pour un tel scénario, nous pouvons introduire un algorithme de hachage.
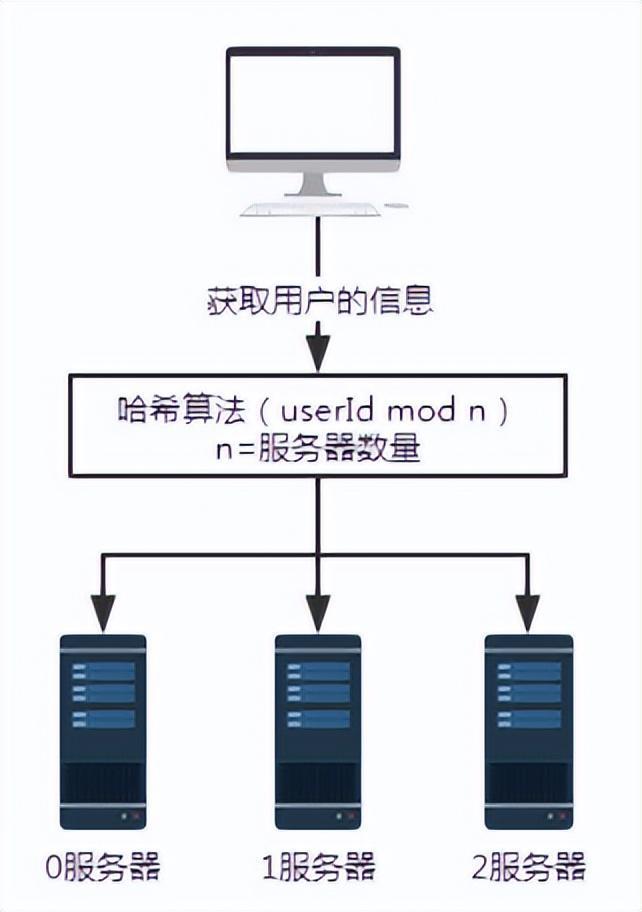
Figure 2 Requête après introduction de l'algorithme de hachage
Dans le scénario ci-dessus, il est supposé que chaque serveur utilise le même algorithme de hachage pour stocker les informations utilisateur. Par conséquent, lors de l’obtention d’informations sur l’utilisateur, suivez simplement le même algorithme de hachage.
Supposons que nous souhaitions interroger les informations de l'utilisateur avec le numéro d'utilisateur 100. Après un certain algorithme de hachage, tel que userId mod n ici, c'est-à-dire 100 mod 3, le résultat est 1. Ainsi, la demande de l'utilisateur numéro 100 sera finalement reçue et traitée par le serveur numéro 1.
Cela résout le problème des requêtes invalides.
Mais quels problèmes une telle solution apportera-t-elle ?
Lors de l'expansion ou de la réduction, une grande quantité de données sera migrée. Au moins 50 % des données seront concernées.
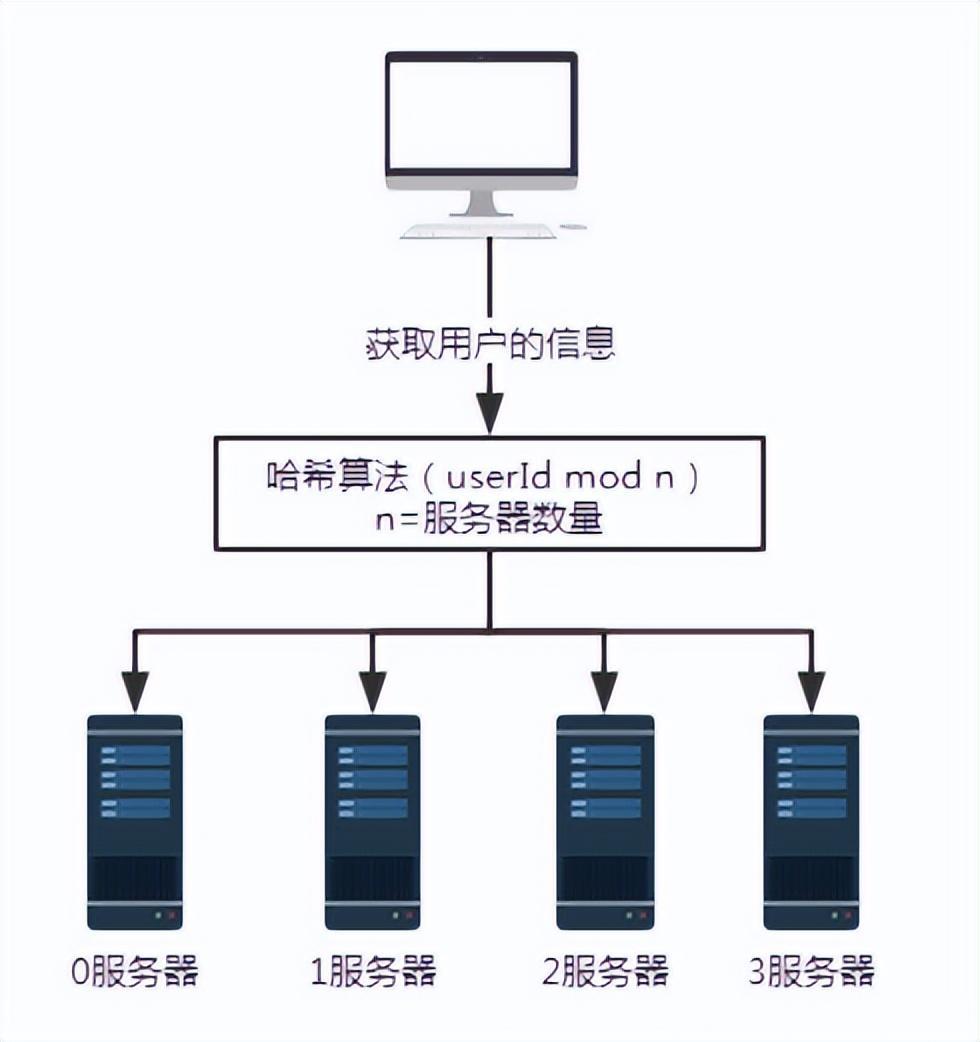
Figure 3 Ajout d'un serveur
Pour illustrer le problème, ajoutez un serveur 3. Le nombre de serveurs n passe de 3 à 4. Lors de l'interrogation des informations utilisateur portant le numéro d'utilisateur 100, le reste après la division de 100 par 4 est 0. A ce moment, la requête est reçue par le serveur 0.
- Lorsque le nombre de serveurs est de 3, la requête avec le numéro d'utilisateur 100 sera traitée par le serveur n°1.
- Lorsque le nombre de serveurs est de 4, la requête avec le numéro d'utilisateur 100 sera traitée par le serveur 0.
Ainsi, lorsque le nombre de serveurs augmente ou diminue, une grande quantité de migration de données sera certainement impliquée.
L'avantage de cet algorithme de hachage est sa simplicité et sa facilité d'utilisation, c'est pourquoi la plupart des règles de sharding l'adoptent. Généralement, le nombre de partitions est estimé à l'avance en fonction de la quantité de données.
L'inconvénient de cette technologie est qu'une fois que le nombre de nœuds dans le réseau augmente ou diminue, la relation de mappage des nœuds doit être recalculée, ce qui nécessite une migration des données. Par conséquent, le doublement de la capacité est généralement utilisé lors de l'extension de la capacité pour éviter que tout le mappage des données ne soit perturbé et provoque une migration complète. Dans ce cas, seulement 50 % des données seront migrées.
3. Algorithme de hachage cohérent
** L'algorithme de hachage cohérent a été proposé par Karger et ses collaborateurs du MIT en 1997. L'algorithme a été initialement proposé pour l'équilibrage de charge des systèmes de cache à grande échelle. ** Son processus de fonctionnement est le suivant. Tout d'abord, un hachage est généré pour le nœud de cache sur la base de l'IP ou d'autres informations, et ce hachage est projeté sur l'anneau de [0, 232 - 1]. Chaque fois qu'il y a une requête ou une demande d'écriture, une valeur de hachage est générée pour la clé de l'élément de cache. Ensuite, vous devez trouver le premier nœud du nœud de cache avec une valeur de hachage supérieure ou égale à la valeur donnée, et effectuer une requête de cache ou une opération d'écriture sur ce nœud. Lorsque le nœud actuel expire, la prochaine requête ou écriture de cache peut rechercher un autre nœud de cache avec un hachage supérieur à l'entrée de cache actuelle. L'effet général est celui illustré dans la figure ci-dessous. Chaque nœud de cache occupe une position sur l'anneau. Lorsque la valeur de hachage de la clé de l'élément de cache est inférieure à la valeur de hachage du nœud de cache, l'élément de cache sera stocké ou lu à partir du nœud de cache. L'élément de cache correspondant à la marque verte ci-dessous sera stocké dans le node cache-2. Les éléments du cache étaient initialement censés être stockés dans le nœud cache-3, mais en raison du temps d'arrêt de ce nœud, ils ont finalement été stockés dans le nœud cache-4.
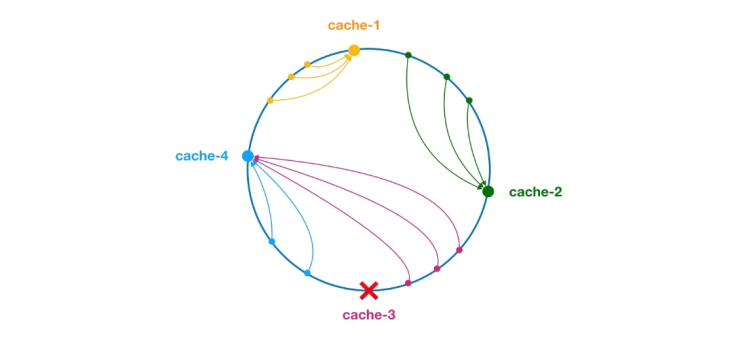
Figure 4 Algorithme de hachage cohérent
Dans l'algorithme de hachage cohérent, que les nœuds soient ajoutés ou supprimés, la plage affectée est uniquement l'augmentation ou le temps d'arrêt du serveur dans l'espace de l'anneau de hachage. dans le sens inverse des aiguilles d’une montre, les autres intervalles ne seront pas affectés.
Mais le hachage cohérent pose également des problèmes :
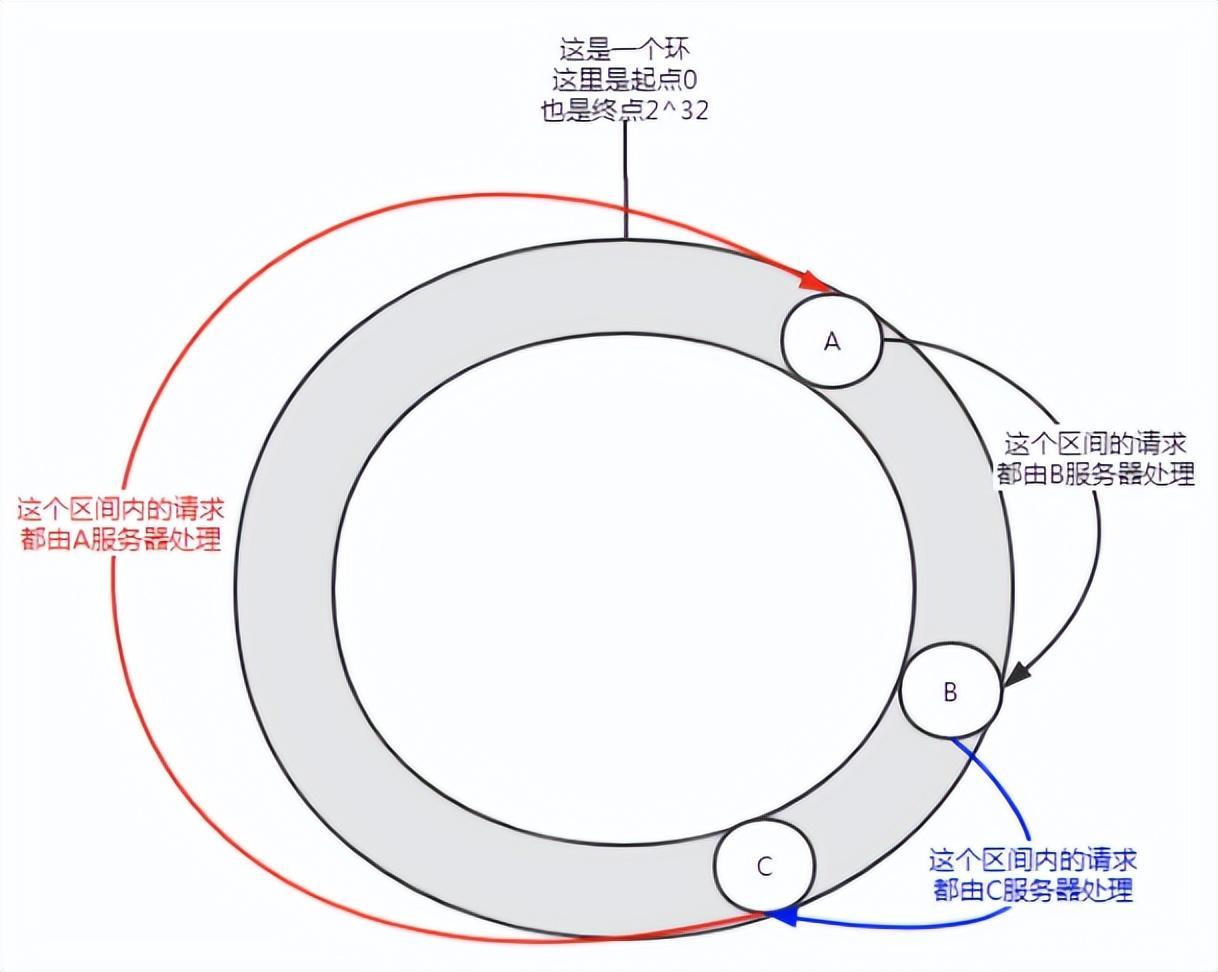
Figure 5 Asymétrie des données
Lorsqu'il y a peu de nœuds, une telle distribution peut se produire et le service A prendra en charge la plupart des requêtes. Cette situation est appelée biais de données.
Alors, comment résoudre le problème du biais des données ?
Rejoignez les nœuds virtuels.
Tout d'abord, un serveur peut avoir plusieurs nœuds virtuels selon les besoins. Supposons qu'un serveur ait n nœuds virtuels. Dans un calcul de hachage, une combinaison d'adresse IP, de numéro de port et de numéro peut être utilisée pour calculer la valeur de hachage. Le nombre est un nombre de 0 à n. Ces n nœuds pointent tous vers la même machine car ils partagent la même adresse IP et le même numéro de port.
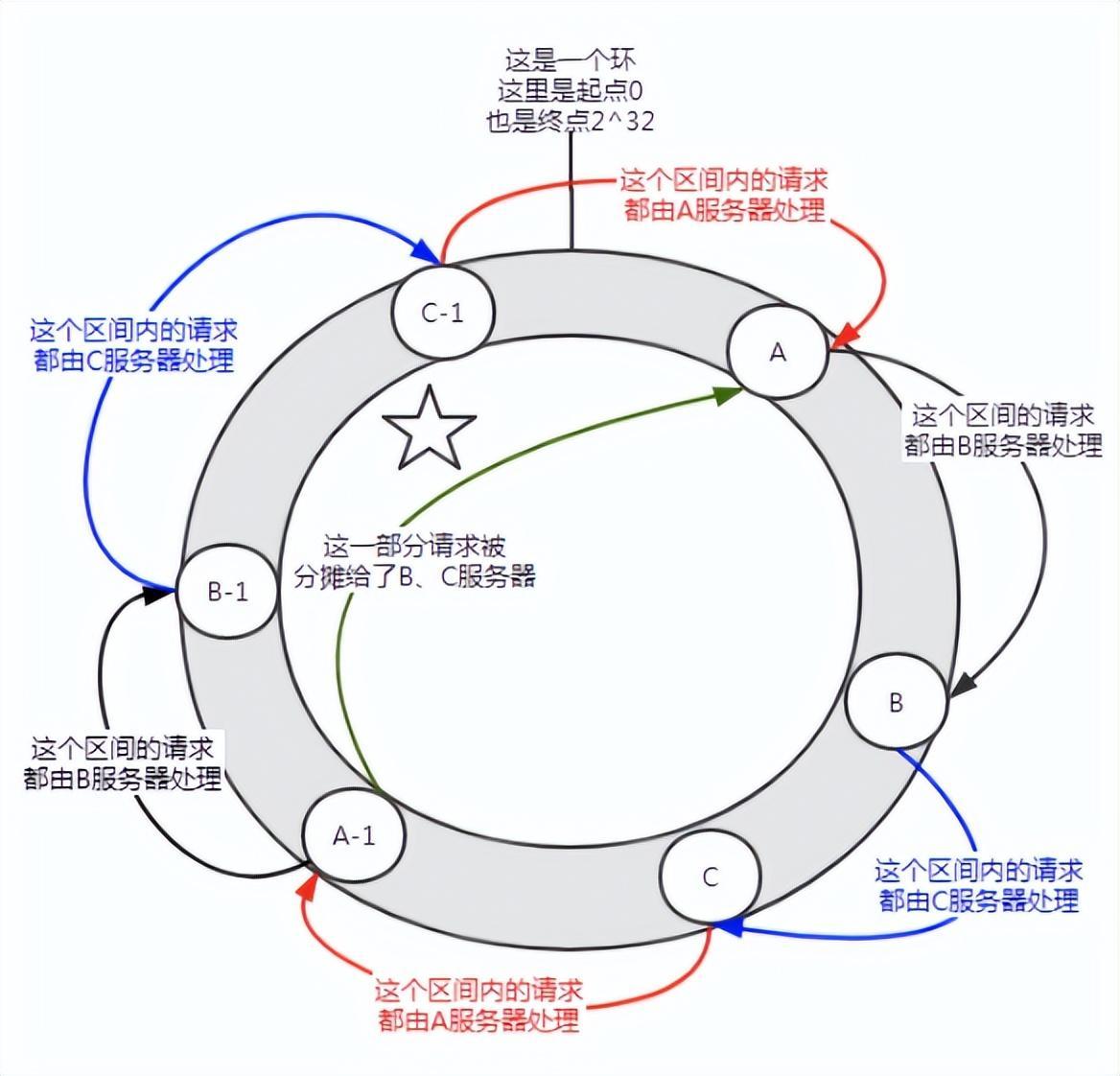
Figure 6 Présentation des nœuds virtuels
Avant d'ajouter des nœuds virtuels, le serveur A traitait la grande majorité des requêtes. Si chaque serveur possède un nœud virtuel (A-1, B-1, C-1) et est attribué à l'emplacement indiqué dans la figure ci-dessus via le calcul de hachage. Ensuite, les requêtes entreprises par le serveur A sont allouées dans une certaine mesure aux nœuds virtuels B-1 et C-1 (la partie marquée d'une étoile à cinq branches sur la figure), qui est en réalité allouée aux serveurs B et C.
Dans l'algorithme de hachage cohérent, l'ajout de nœuds virtuels peut résoudre le problème de la distorsion des données.
4. Application du hachage cohérent dans DUBBO
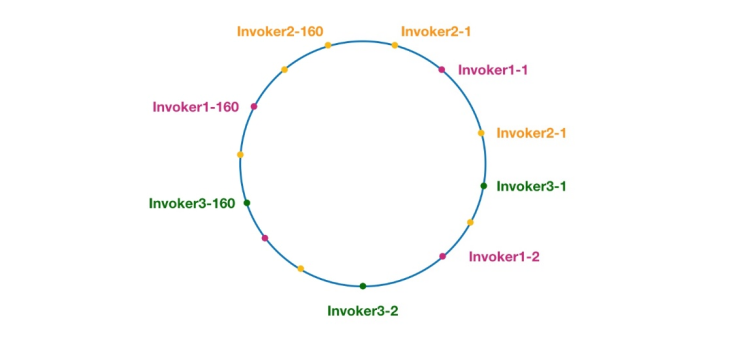
Figure 7 Anneau de hachage cohérent dans Dubbo
Les nœuds de la même couleur ici appartiennent tous au même fournisseur de services, tels que Invoker1-1, Invoker1-2,…, Invocateur1-160. En ajoutant des nœuds virtuels, nous pouvons répartir l'Invoker sur l'anneau de hachage, évitant ainsi le problème de biais des données. Ce que l'on appelle le biais de données fait référence à la situation dans laquelle un grand nombre de requêtes tombent sur le même nœud car les nœuds ne sont pas suffisamment dispersés, tandis que les autres nœuds ne reçoivent qu'un petit nombre de requêtes. Par exemple :
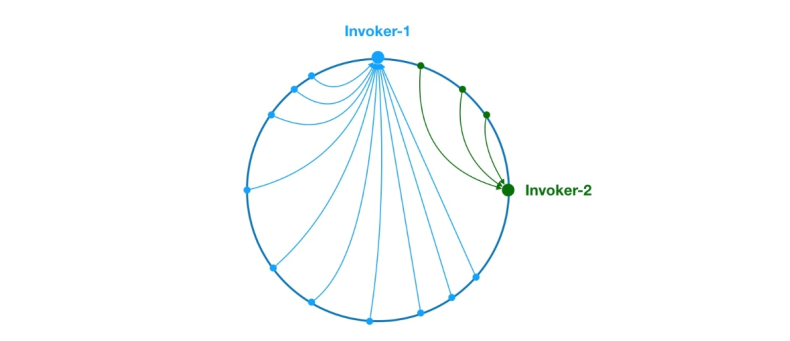
Figure 8 Problème de biais de données
Comme ci-dessus, en raison de la répartition inégale de Invoker-1 et Invoker-2 sur l'anneau, 75 % des requêtes dans le système tomberont sur Invoker-1, et seulement 25% La demande tombera sur Invoker-2. Afin de résoudre ce problème, des nœuds virtuels peuvent être introduits pour équilibrer le volume de requêtes de chaque nœud.
Maintenant que les connaissances de base ont été vulgarisées, commençons à analyser le code source. Commençons par la méthode doSelect de ConsistentHashLoadBalance, comme suit :
public class ConsistentHashLoadBalance extends AbstractLoadBalance {private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {String methodName = RpcUtils.getMethodName(invocation);String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;// 获取 invokers 原始的 hashcodeint identityHashCode = System.identityHashCode(invokers);ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);// 如果 invokers 是一个新的 List 对象,意味着服务提供者数量发生了变化,可能新增也可能减少了。// 此时 selector.identityHashCode != identityHashCode 条件成立if (selector == null || selector.identityHashCode != identityHashCode) {// 创建新的 ConsistentHashSelectorselectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));selector = (ConsistentHashSelector<T>) selectors.get(key);}// 调用 ConsistentHashSelector 的 select 方法选择 Invokerreturn selector.select(invocation);}private static final class ConsistentHashSelector<T> {...}}
Comme ci-dessus, la méthode doSelect effectue principalement un travail préparatoire, comme détecter si la liste des invocateurs a changé et créer un ConsistentHashSelector. Une fois ces tâches terminées, la méthode select de ConsistentHashSelector est appelée pour exécuter la logique d'équilibrage de charge. Avant d'analyser la méthode select, examinons d'abord le processus d'initialisation du sélecteur de hachage cohérent ConsistentHashSelector, comme suit :
private static final class ConsistentHashSelector<T> {// 使用 TreeMap 存储 Invoker 虚拟节点private final TreeMap<Long, Invoker<T>> virtualInvokers;private final int replicaNumber;private final int identityHashCode;private final int[] argumentIndex;ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {this.virtualInvokers = new TreeMap<Long, Invoker<T>>();this.identityHashCode = identityHashCode;URL url = invokers.get(0).getUrl();// 获取虚拟节点数,默认为160this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);// 获取参与 hash 计算的参数下标值,默认对第一个参数进行 hash 运算String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0"));argumentIndex = new int[index.length];for (int i = 0; i < index.length; i++) {argumentIndex[i] = Integer.parseInt(index[i]);}for (Invoker<T> invoker : invokers) {String address = invoker.getUrl().getAddress();for (int i = 0; i < replicaNumber / 4; i++) {// 对 address + i 进行 md5 运算,得到一个长度为16的字节数组byte[] digest = md5(address + i);// 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数for (int h = 0; h < 4; h++) {// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算// h = 2, h = 3 时过程同上long m = hash(digest, h);// 将 hash 到 invoker 的映射关系存储到 virtualInvokers 中,// virtualInvokers 需要提供高效的查询操作,因此选用 TreeMap 作为存储结构virtualInvokers.put(m, invoker);}}}}}
ConsistentHashSelector 的构造方法执行了一系列的初始化逻辑,比如从配置中获取虚拟节点数以及参与 hash 计算的参数下标,默认情况下只使用第一个参数进行 hash。需要特别说明的是,ConsistentHashLoadBalance 的负载均衡逻辑只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。注意到 ConsistentHashLoadBalance 无需考虑权重的影响。
在获取虚拟节点数和参数下标配置后,接下来要做的事情是计算虚拟节点 hash 值,并将虚拟节点存储到 TreeMap 中。ConsistentHashSelector的初始化工作在此完成。接下来,我们来看看 select 方法的逻辑。
public Invoker<T> select(Invocation invocation) {// 将参数转为 keyString key = toKey(invocation.getArguments());// 对参数 key 进行 md5 运算byte[] digest = md5(key);// 取 digest 数组的前四个字节进行 hash 运算,再将 hash 值传给 selectForKey 方法,// 寻找合适的 Invokerreturn selectForKey(hash(digest, 0));}private Invoker<T> selectForKey(long hash) {// 到 TreeMap 中查找第一个节点值大于或等于当前 hash 的 InvokerMap.Entry<Long, Invoker<T>> entry = virtualInvokers.tailMap(hash, true).firstEntry();// 如果 hash 大于 Invoker 在圆环上最大的位置,此时 entry = null,// 需要将 TreeMap 的头节点赋值给 entryif (entry == null) {entry = virtualInvokers.firstEntry();}// 返回 Invokerreturn entry.getValue();}
如上,选择的过程相对比较简单了。首先,需要对参数进行 md5 和 hash 运算,以生成一个哈希值。接着使用这个值去 TreeMap 中查找需要的 Invoker。
到此关于 ConsistentHashLoadBalance 就分析完了。
在阅读 ConsistentHashLoadBalance 源码之前,建议读者先补充背景知识,不然看懂代码逻辑会有很大难度。
五、应用场景
- DNS 负载均衡最早的负载均衡技术是通过 DNS 来实现的,在 DNS 中为多个地址配置同一个名字,因而查询这个名字的客户机将得到其中一个地址,从而使得不同的客户访问不同的服务器,达到负载均衡的目的。DNS 负载均衡是一种简单而有效的方法,但是它不能区分服务器的差异,也不能反映服务器的当前运行状态。
- 代理服务器负载均衡使用代理服务器,可以将请求转发给内部的服务器,使用这种加速模式显然可以提升静态网页的访问速度。然而,也可以考虑这样一种技术,使用代理服务器将请求均匀转发给多台服务器,从而达到负载均衡的目的。
- 地址转换网关负载均衡支持负载均衡的地址转换网关,可以将一个外部 IP 地址映射为多个内部 IP 地址,对每次 TCP 连接请求动态使用其中一个内部地址,达到负载均衡的目的。
- 协议内部支持负载均衡除了这三种负载均衡方式之外,有的协议内部支持与负载均衡相关的功能,例如 HTTP 协议中的重定向能力等,HTTP 运行于 TCP 连接的最高层。
- NAT 负载均衡 NAT(Network Address Translation 网络地址转换)简单地说就是将一个 IP 地址转换为另一个 IP 地址,一般用于未经注册的内部地址与合法的、已获注册的 Internet IP 地址间进行转换。适用于解决 Internet IP 地址紧张、不想让网络外部知道内部网络结构等的场合下。
- 反向代理负载均衡普通代理方式是代理内部网络用户访问 internet 上服务器的连接请求,客户端必须指定代理服务器,并将本来要直接发送到 internet 上服务器的连接请求发送给代理服务器处理。反向代理(Reverse Proxy)方式是指以代理服务器来接受 internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 internet 上请求连接的客户端,此时代理服务器对外就表现为一个服务器。反向代理负载均衡技术是把将来自 internet 上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
- 混合型负载均衡在有些大型网络,由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。将这种方式称之为混合型负载均衡。此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。
作者:京东物流 乔杰
来源:京东云开发者社区
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI