
Maison >Périphériques technologiques >IA >Google utilise l'IA pour briser le sceau de dix ans de l'algorithme de tri. Elle est exécutée des milliards de fois chaque jour, mais les internautes disent que c'est la recherche la plus irréaliste ?
Google utilise l'IA pour briser le sceau de dix ans de l'algorithme de tri. Elle est exécutée des milliards de fois chaque jour, mais les internautes disent que c'est la recherche la plus irréaliste ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-22 21:18:461474parcourir
Organisation | Nuka Cola, Chu Xingjuan
Les amis qui ont suivi des cours de base en informatique doivent avoir personnellement conçu un algorithme de tri, c'est-à-dire utiliser du code pour réorganiser les éléments d'une liste non ordonnée par ordre croissant ou décroissant. C'est un défi intéressant, et il existe de nombreuses façons possibles de le relever. Beaucoup de temps a été investi pour trouver comment accomplir les tâches de tri plus efficacement.
En tant qu'opération de base, les algorithmes de tri sont intégrés aux bibliothèques standard de la plupart des langages de programmation. Il existe de nombreuses techniques et algorithmes de tri différents utilisés dans les bases de code du monde entier pour organiser de grandes quantités de données en ligne, mais au moins en ce qui concerne les bibliothèques C++ utilisées avec le compilateur LLVM, le code de tri n'a pas changé depuis plus d'une décennie. .
Récemment, l'équipe DeepMind AI de Google a développé un outil d'apprentissage par renforcement, AlphaDev, capable de développer des algorithmes extrêmement optimisés sans avoir besoin d'une pré-formation avec des exemples de code humain. Aujourd'hui, ces algorithmes ont été intégrés dans la bibliothèque de tri C++ standard LLVM, marquant la première fois depuis plus d'une décennie qu'une partie de la bibliothèque de tri change et la première fois que des algorithmes conçus avec l'apprentissage par renforcement sont ajoutés à la bibliothèque.
Considérez le processus de programmation comme un « jeu »
Le système DeepMind est souvent capable de découvrir des solutions à des problèmes auxquels les humains n'ont jamais pensé car il ne nécessite aucune exposition préalable aux stratégies de jeu humaines. DeepMind s'appuie entièrement sur l'auto-confrontation pour apprendre de l'expérience, il existe donc parfois des angles morts qui peuvent être exploités par les humains.
Cette méthode est en fait très similaire à la programmation. Les grands modèles de langage sont capables d’écrire du code efficace car ils ont vu de nombreux exemples de code humain. Mais c’est précisément pour cette raison qu’il est difficile pour les modèles linguistiques de produire des choses que les humains n’ont jamais faites auparavant. Si nous voulons optimiser davantage les algorithmes existants omniprésents (tels que les fonctions de tri), il sera difficile de briser les contraintes des idées inhérentes en continuant à s'appuyer sur le code humain existant. Alors, comment l’IA peut-elle trouver de véritables nouvelles directions ?
Les chercheurs de DeepMind ont utilisé des méthodes similaires aux échecs et au Go pour optimiser les tâches de code, les transformant en « puzzles » pour un seul joueur. AlphaDev Systems a développé un algorithme d'assemblage x86 qui traite le délai d'exécution du code comme un score et s'efforce de minimiser le score tout en garantissant le bon fonctionnement du code. AlphaDev a progressivement maîtrisé l'art d'écrire du code efficace et concis, grâce à l'application de l'apprentissage par renforcement.
AlphaDev est basé sur AlphaZero. DeepMind est bien connu pour développer des logiciels d’IA capables d’apprendre les règles du jeu par eux-mêmes. Cette ligne de pensée s'est avérée très efficace et a permis de résoudre avec succès de nombreux problèmes de jeux, tels que les échecs, le Go et "StarCraft". Bien que les spécificités varient en fonction du jeu auquel vous jouez, le logiciel de DeepMind apprend grâce à des jeux répétés, explorant continuellement des moyens de maximiser votre score.
Les deux composants principaux d'AlphaDev sont les algorithmes d'apprentissage et les fonctions de représentation.
L'utilisation de DRL combinée à des algorithmes d'optimisation de recherche aléatoire pour assembler des jeux est une méthode d'algorithme d'apprentissage AlphaDev. Le principal algorithme d'apprentissage d'AlphaDev est une extension d'AlphaZero 33, un algorithme DRL bien connu dans lequel un réseau neuronal est formé pour guider la recherche à travers le jeu.
Cette fonction est utilisée pour surveiller les performances globales du développement du code, couvrant la structure générale de l'algorithme, ainsi que l'utilisation des registres x86 et de la mémoire. Le système introduira progressivement des instructions d'assemblage, ajoutées indépendamment lors des sélections à l'aide d'une méthode de recherche arborescente de Monte Carlo empruntée au système de jeu. La structure arborescente permet au système de restreindre rapidement la recherche à une région limitée contenant un grand nombre d'instructions potentielles, tandis que la méthode de Monte Carlo sélectionne des instructions spécifiques dans cette région de branchement avec un certain degré de hasard. Notez que les « instructions » mentionnées ici sont des opérations telles que la sélection de registres spécifiques pour créer un assemblage valide et complet. )
Le système évalue ensuite la latence et l'état de validité du code assembleur et attribue un score, qui est comparé au score précédent. Grâce à l'apprentissage par renforcement, le système est capable d'enregistrer les informations de travail de différentes branches dans la structure arborescente pour un état de programme donné. Au fil du temps, le système se familiarise avec la manière de gagner la partie (réussite du tri) avec le score le plus élevé (représentant la latence la plus faible). La fonction de représentation principale d'AlphaDev est basée sur Transformers.
Pour entraîner AlphaDev à découvrir de nouveaux algorithmes, AlphaDev observe à chaque tour l'algorithme qu'il génère et les informations contenues dans l'unité centrale de traitement (CPU), puis termine le jeu en sélectionnant les instructions à ajouter à l'algorithme. AlphaDev doit rechercher efficacement un grand nombre de combinaisons d'instructions possibles pour trouver un algorithme pouvant être séquencé et également plus rapide que le meilleur algorithme actuel, tandis que le modèle d'agent peut être récompensé en fonction de l'exactitude et de la latence de l'algorithme.
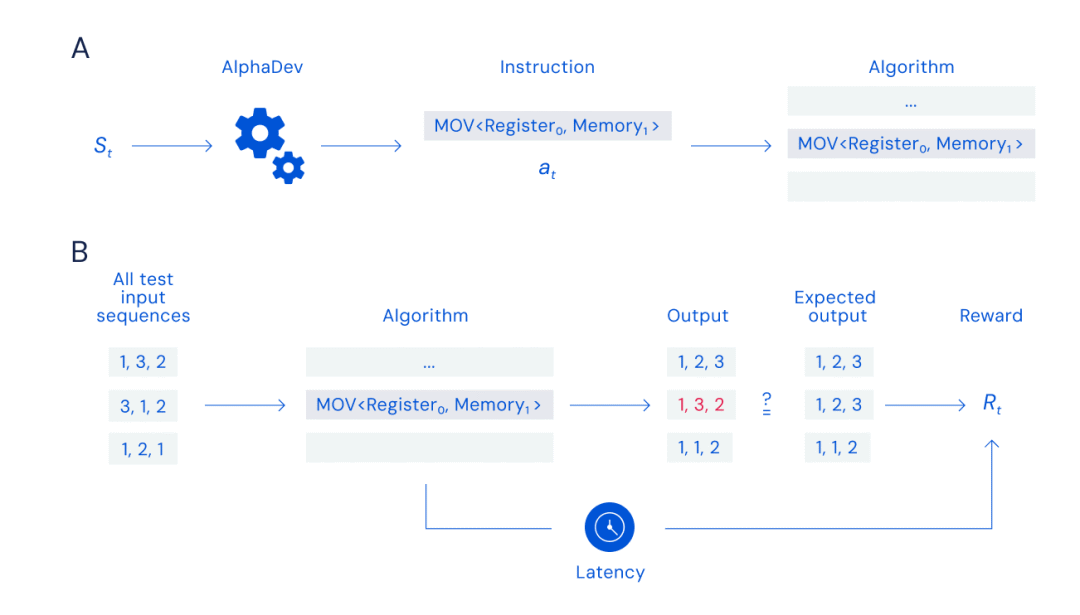
Image A : Jeu d'assemblage, Image B : Calcul des récompenses
Enfin, AlphaDev a découvert de nouveaux algorithmes de tri qui peuvent améliorer la bibliothèque de tri LLVM libc++ : pour les séquences plus courtes, la bibliothèque de tri est 70 % plus rapide ; pour les séquences de plus de 250 000 éléments, la vitesse est augmentée d'environ 1,7 %.
Plus précisément, l'innovation de cet algorithme réside principalement dans deux séquences d'instructions : AlphaDev Swap Move (déplacement d'échange) et AlphaDev Copy Move (déplacement de copie). Grâce à ces deux instructions, AlphaDev saute une étape et effectue un raccourci apparemment erroné mais en réalité. connecter des éléments.
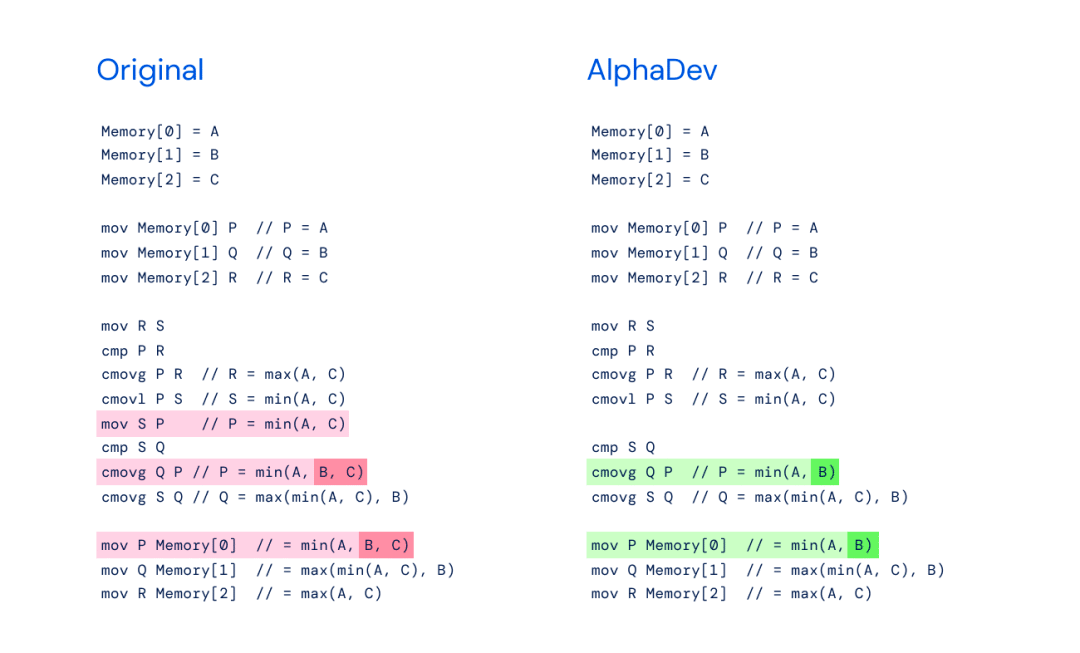
Gauche : implémentation originale de sort3 avec min(A,B,C).
Image de droite : AlphaDev Swap Move - AlphaDev a découvert que vous n'aviez besoin que de min(A,B).
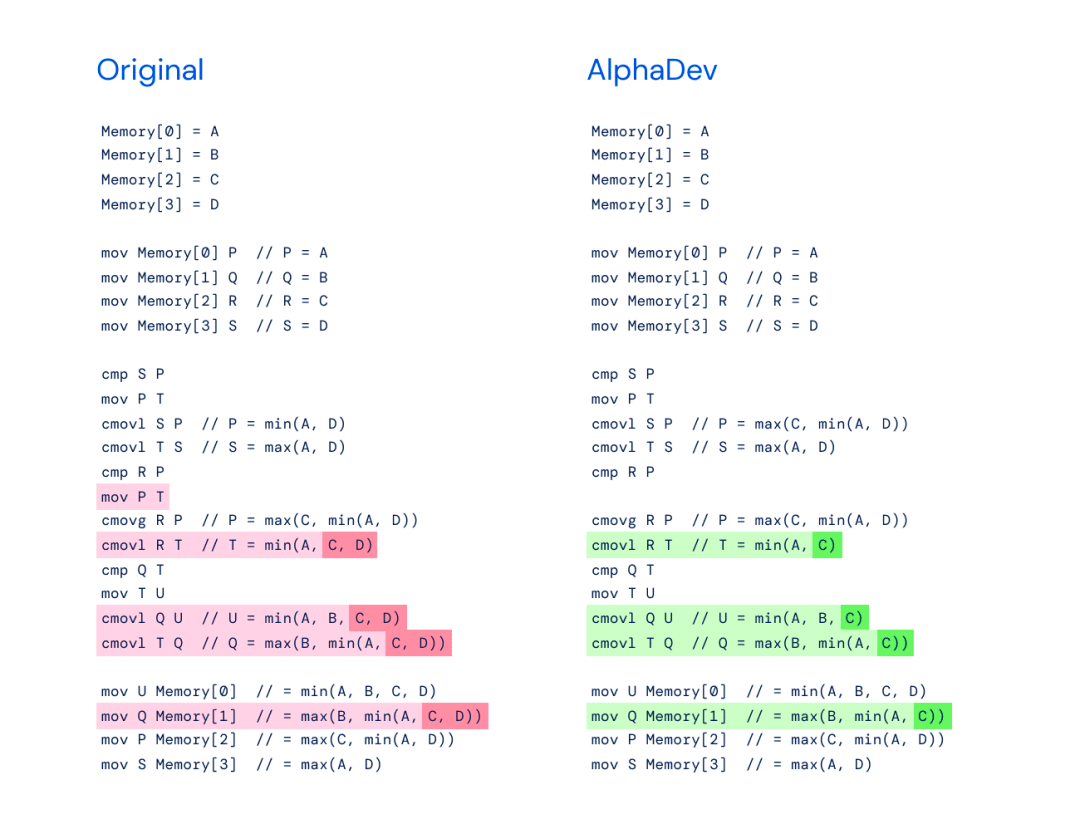
Gauche : implémentation originale de max (B, min (A, C)) pour un algorithme de tri plus grand qui trie huit éléments.
À droite : AlphaDev a constaté que seul max (B, min (A, C)) est nécessaire lors de l'utilisation de son déplacement de copie.
Le principal avantage de ce système est que son processus de formation ne nécessite aucun exemple de code. Au lieu de cela, le système génère de manière autonome des exemples de code, puis les évalue. Ce faisant, il maîtrise progressivement les informations sur l’enchaînement efficace des combinaisons d’instructions.
Du tri au hachage
Après avoir découvert un algorithme de tri plus rapide, DeepMind a testé si AlphaDev pouvait généraliser et améliorer un autre algorithme informatique : le hachage.
Le hachage est un algorithme fondamental utilisé en informatique pour récupérer, stocker et compresser des données. Tout comme un bibliothécaire qui utilise un système de classification pour localiser un livre particulier, les algorithmes de hachage aident les utilisateurs à savoir ce qu'ils recherchent et où le trouver. Ces algorithmes prennent les données d'une clé spécifique (par exemple, le nom d'utilisateur "Jane Doe") et les hachent - un processus qui convertit les données brutes en une chaîne unique (par exemple 1234ghfty). Cet algorithme de hachage est utilisé pour récupérer rapidement les données liées à une clé, évitant ainsi d'avoir à rechercher dans l'intégralité des données.
DeepMind applique AlphaDev à l'un des algorithmes de hachage les plus couramment utilisés dans les structures de données dans le but de découvrir des algorithmes plus rapides. AlphaDev a découvert que l'algorithme était 30 % plus rapide lorsque la fonction de hachage utilisait des données comprises entre 9 et 16 octets.
Cette année, le nouvel algorithme de hachage d'AlphaDev a été publié dans la bibliothèque open source Abseil, disponible pour des millions de développeurs à travers le monde, et la bibliothèque est désormais utilisée des milliards de fois chaque jour.
Code de travail réel
Les mécanismes de tri dans les programmes complexes peuvent gérer de grandes collections d'entrées arbitraires. Mais au niveau de la bibliothèque standard, cette capacité provient d'une série de fonctions spécifiques très restreintes. Chacune de ces fonctions ne peut gérer qu’une ou quelques situations. Par exemple, certains algorithmes individuels ne peuvent trier que 3, 4 ou 5 éléments. Nous pouvons trier n'importe quel nombre d'entrées à l'aide d'un ensemble de fonctions, mais nous ne pouvons trier que jusqu'à 4 entrées par appel de fonction.
AlphaDev a été implémenté par DeepMind sur chaque fonction, mais ses méthodes de fonctionnement réelles diffèrent considérablement. Il est possible d'écrire du code sans instructions de branchement pour gérer une fonction qui gère un nombre spécifique d'entrées, c'est-à-dire exécuter un code différent en fonction de l'état de la variable. Les performances du code ont donc tendance à être inversement proportionnelles au nombre d’instructions impliquées.
AlphaDev a réussi à réduire d'une le nombre d'instructions dans les tris 3, 5 et 8, et encore plus dans les tris 6 et 7. Aucun moyen d'améliorer le code existant n'a pu être trouvé uniquement sur sort-4. Des tests répétés sur des systèmes réels montrent que moins d'instructions améliorent les performances.
Pour trier un nombre variable d'entrées, vous devez inclure des instructions de branche dans votre code, et différents processeurs ont un nombre différent de composants dédiés à la gestion de ces branches.
Les chercheurs ont utilisé 100 appareils informatiques différents pour évaluer cette situation. AlphaDev a également trouvé des moyens de réduire davantage les performances dans ce type de scénario. Prenons comme exemple une fonction qui trie jusqu'à 4 éléments à la fois pour voir comment elle fonctionne.
Dans l'implémentation actuelle de la bibliothèque C++, le code doit effectuer une série de tests pour confirmer combien d'éléments doivent être triés, puis appeler la fonction de tri correspondante en fonction du nombre d'éléments.
Le code modifié d'AlphaDev adopte une idée plus "magique" : il teste d'abord s'il y a 2 entrées, et si c'est le cas, appelle la fonction correspondante pour trier immédiatement. Si le nombre est supérieur à 2, le code triera en premier les 3 premières entrées. De cette façon, s'il n'y a effectivement que 3 entrées, les résultats triés sont renvoyés. Puisqu'il y a en réalité 4 éléments à trier, AlphaDev exécutera un code spécialisé pour insérer le 4ème élément à la position appropriée parmi les 3 premiers éléments qui ont été triés de manière très efficace.
Cette approche semble un peu bizarre, mais il s'avère que ses performances sont toujours meilleures que le code existant.
Étant donné qu'AlphaDev génère du code plus efficace, l'équipe de recherche prévoit de fusionner à nouveau ces résultats dans la bibliothèque C++ standard LLVM. Mais le problème est que le code est au format assembleur, pas en C++. Par conséquent, ils doivent travailler à rebours pour trouver le code C++ qui génère le même assembly.
Une version réécrite de cette phrase : Cette partie du code a désormais été intégrée à la chaîne d'outils LLVM et mise à jour pour la première fois depuis près d'une décennie. Les chercheurs estiment que le nouveau code généré par AlphaDev est exécuté des milliards de fois chaque jour.
Conclusion
C'est tellement bon ! Nous, les programmeurs, avons appris cette tâche de tri de base il y a longtemps, mais nous sommes désormais 70 % plus rapides. Il y a de quoi être enthousiasmé car l’IA dans les algorithmes et les bibliothèques sur lesquels nous comptons tous offre des accélérations significatives. "Certains développeurs sont enthousiasmés par les résultats de Google DeepMind.
Mais certains développeurs n'y ont pas adhéré : "Assez décevant... 1,7% d'amélioration ? 70% de la séquence de 5 éléments ? Probablement la recherche appliquée la plus impopulaire et la plus irréaliste..." Certains développeurs ont dit : "N'est-ce pas un peu trompeur de dire qu'un nouvel algorithme a été découvert ? Cela ressemble plus à une optimisation d'algorithme quand même. "
Lien de référence :
https://arstechnica.com/science/2023/06/googles-deepmind-develops-a-system-that-writes-efficient-algorithms/
https://www.deepmind.com/blog/alphadev-discovers-faster-sorting-algorithms
Profondeur : Pourquoi un géant comme Snowflake n’a-t-il pas émergé dans le domaine des bases de données en Chine ?
L'effondrement le plus bizarre depuis dix-sept ans ! Afin d'empêcher OpenAI et Google d'obtenir des données pour rien, Reddit a facturé d'énormes frais d'API et calomnié les développeurs, provoquant des protestations à grande échelle au sein de la communauté
« Voler » du code pour créer une entreprise, falsifier des diplômes universitaires et gagner 100 millions de dollars en 6 jours sans recevoir de salaires en souffrance. Ce PDG de licorne IA a répondu personnellement après avoir été interrogé à plusieurs reprises
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI