
Maison >Périphériques technologiques >IA >65 milliards de paramètres, 8 GPU peuvent affiner tous les paramètres : l'équipe de Qiu Xipeng a abaissé le seuil pour les grands modèles
65 milliards de paramètres, 8 GPU peuvent affiner tous les paramètres : l'équipe de Qiu Xipeng a abaissé le seuil pour les grands modèles

- 王林avant
- 2023-06-20 15:57:581538parcourir
En direction des grands modèles, les géants de la technologie forment des modèles plus grands, tandis que le monde universitaire réfléchit aux moyens de les optimiser. Récemment, la méthode d'optimisation de la puissance de calcul a atteint un nouveau niveau.
Les modèles linguistiques à grande échelle (LLM) ont révolutionné le domaine du traitement du langage naturel (NLP), démontrant des capacités extraordinaires telles que l'émergence et l'épiphanie. Cependant, si vous souhaitez construire un modèle doté de certaines capacités générales, des milliards de paramètres sont nécessaires, ce qui élève considérablement le seuil de recherche en PNL. Le processus de réglage du modèle LLM nécessite généralement des ressources GPU coûteuses, telles qu'un périphérique GPU de 8 × 80 Go, ce qui rend difficile la participation des petits laboratoires et entreprises à la recherche dans ce domaine.
Récemment, les gens étudient les techniques de réglage fin efficaces des paramètres (PEFT), telles que LoRA et Prefix-tuning, qui fournissent des solutions pour régler le LLM avec des ressources limitées. Cependant, ces méthodes ne fournissent pas de solutions pratiques pour le réglage fin de tous les paramètres, qui a été reconnu comme une méthode plus puissante que le réglage fin efficace des paramètres.
Dans l'article « Full Parameter Fine-tuning for Large Language Models with Limited Resources » soumis la semaine dernière par l'équipe Qiu Xipeng de l'université de Fudan, les chercheurs ont proposé un nouvel optimiseur LOw-Memory Optimization (LOMO).
En intégrant LOMO aux techniques d'économie de mémoire existantes, la nouvelle approche réduit l'utilisation de la mémoire à 10,8% par rapport à l'approche standard (solution DeepSpeed). En conséquence, la nouvelle approche permet un réglage précis des paramètres complets d’un modèle 65B sur une machine équipée de 8 × RTX 3090, chacun doté de 24 Go de mémoire.

Lien papier : https://arxiv.org/abs/2306.09782
Dans ce travail, l'auteur a analysé quatre aspects de l'utilisation de la mémoire dans LLM : activation, état de l'optimiseur, gradient tenseur et paramètres, et optimisé le processus de formation sous trois aspects :
- a repensé la fonction de l'optimiseur d'un point de vue algorithmique et a découvert que SGD est un bon moyen d'affiner les paramètres complets de LLM Substitute. Cela permet aux auteurs de supprimer des parties entières de l'état de l'optimiseur, puisque SGD ne stocke aucun état intermédiaire.
- L'optimiseur LOMO nouvellement proposé réduit l'utilisation de la mémoire des tenseurs de gradient à O(1), ce qui équivaut à l'utilisation de la mémoire du plus grand tenseur de gradient.
- Pour stabiliser l'entraînement de précision mixte à l'aide de LOMO, les auteurs intègrent la normalisation du gradient, la mise à l'échelle des pertes et convertissent certains calculs en pleine précision pendant l'entraînement.
La nouvelle technologie rend l'utilisation de la mémoire égale à l'utilisation des paramètres plus l'activation et les tenseurs de gradient maximum. L'utilisation de la mémoire pour le réglage fin complet des paramètres est poussée à l'extrême, ce qui n'équivaut qu'à l'utilisation de l'inférence. En effet, l'empreinte mémoire du processus forward+backward ne doit pas être inférieure à celle du processus forward seul. Il convient de noter que lors de l'utilisation de LOMO pour économiser de la mémoire, la nouvelle méthode garantit que le processus de réglage fin n'est pas affecté, car le processus de mise à jour des paramètres est toujours équivalent à SGD.
Cette étude évalue les performances de mémoire et de débit de LOMO et montre qu'avec LOMO, les chercheurs peuvent entraîner un modèle de paramètres 65B sur 8 GPU RTX 3090. De plus, pour vérifier les performances de LOMO sur les tâches en aval, ils ont appliqué LOMO pour régler tous les paramètres de LLM sur la collection de jeux de données SuperGLUE. Les résultats démontrent l'efficacité de LOMO pour optimiser les LLM avec des milliards de paramètres.
Introduction à la méthode
Dans la section méthode, cet article présente LOMO (LOW-MEMORY OPTIMIZATION) en détail. De manière générale, le tenseur de gradient représente le gradient d'un tenseur de paramètres et sa taille est la même que celle des paramètres, ce qui entraîne une surcharge de mémoire plus importante. Les frameworks d'apprentissage en profondeur existants tels que PyTorch stockent des tenseurs de gradient pour tous les paramètres. Actuellement, il existe deux raisons de stocker les tenseurs de gradient : le calcul de l'état de l'optimiseur et la normalisation des gradients.
Depuis que cette étude adopte SGD comme optimiseur, il n'y a pas d'état d'optimiseur dépendant du gradient, et ils ont des alternatives à la normalisation du gradient.
Ils ont proposé LOMO, comme le montre l'algorithme 1, LOMO intègre le calcul du gradient et la mise à jour des paramètres en une seule étape, évitant ainsi le stockage des tenseurs de gradient.
La figure suivante montre la comparaison entre SGD et LOMO dans les étapes de rétropropagation et de mise à jour des paramètres. Pi est le paramètre du modèle et Gi est le gradient correspondant à Pi. LOMO intègre le calcul du gradient et la mise à jour des paramètres en une seule étape pour minimiser le tenseur du gradient.
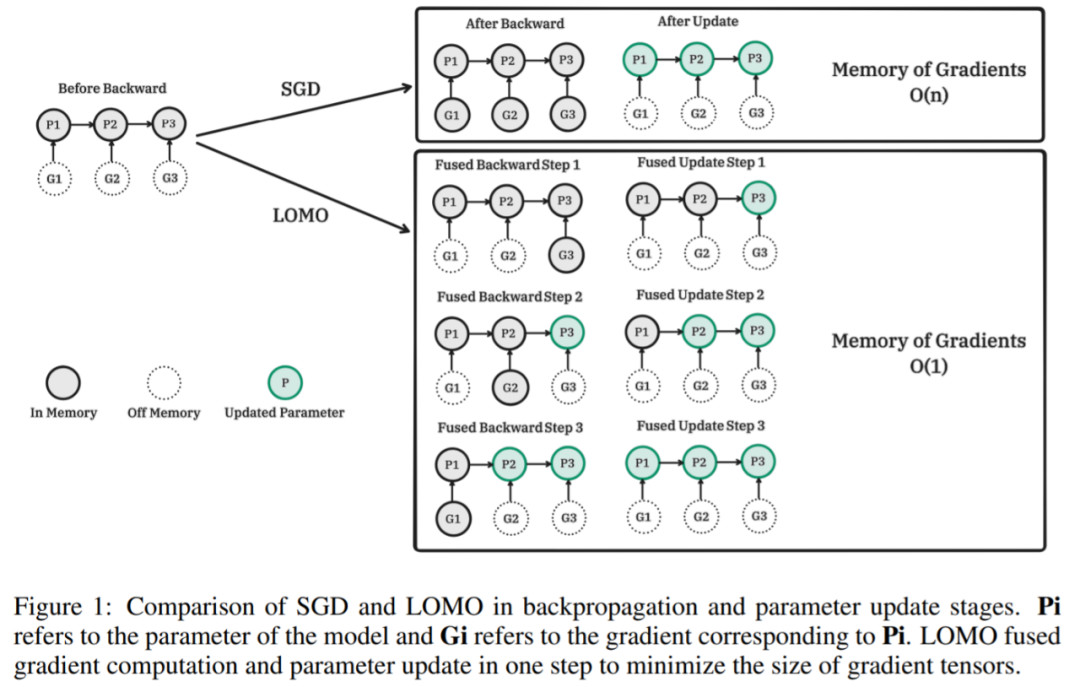
Pseudo-code de l'algorithme correspondant LOMO :

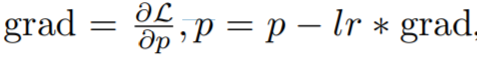
, qui est un deux -processus par étapes dimensionnelles, d'abord calculez le dégradé, puis mettez à jour les paramètres. La version fusionnée est
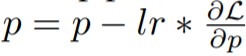
L'idée clé de cette recherche est de mettre à jour les paramètres immédiatement lors du calcul du gradient, afin que le tenseur du gradient ne soit pas stocké en mémoire. Cette étape peut être réalisée en injectant des fonctions de hook dans la rétropropagation. PyTorch fournit des API associées pour l'injection de fonctions de hook, mais il est impossible d'obtenir des mises à jour instantanées précises avec l'API actuelle. Au lieu de cela, cette étude stocke le gradient d’au plus un paramètre en mémoire et met à jour chaque paramètre un par un avec rétropropagation. Cette méthode réduit l'utilisation de la mémoire des dégradés du stockage des dégradés de tous les paramètres aux dégradés d'un seul paramètre.
La majeure partie de l'utilisation de la mémoire LOMO est cohérente avec l'utilisation de la mémoire des méthodes de réglage fin efficaces en termes de paramètres, ce qui indique que la combinaison de LOMO avec ces méthodes n'entraîne qu'une légère augmentation de la mémoire occupée par le dégradé. Cela permet d'ajuster davantage de paramètres pour la méthode PEFT.
Résultats expérimentaux
Dans la partie expérimentale, les chercheurs ont évalué la méthode proposée sous trois aspects, à savoir l'utilisation de la mémoire, le débit et les performances en aval. Sans autre explication, toutes les expériences ont été réalisées en utilisant les modèles LLaMA 7B à 65B.
Utilisation de la mémoire
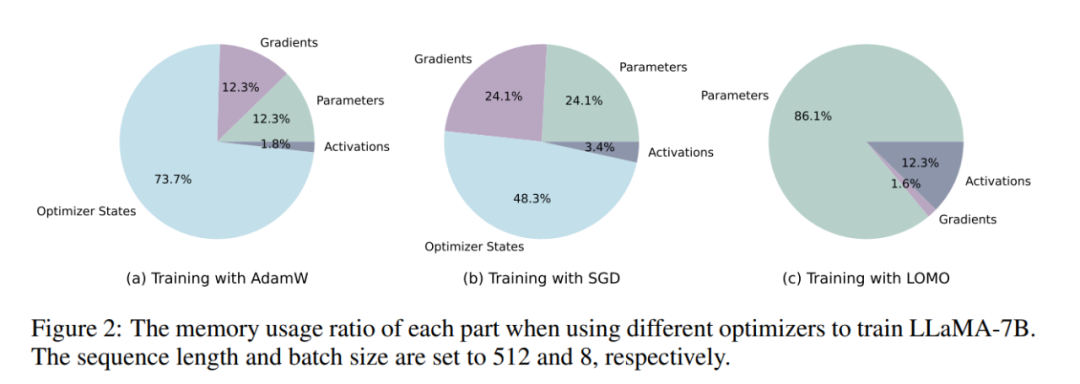
Les chercheurs ont d'abord analysé l'état du modèle et activé l'utilisation de la mémoire pendant l'entraînement dans différents paramètres. Comme le montre le tableau 1, par rapport à l'optimiseur AdamW, l'utilisation de l'optimiseur LOMO entraîne une réduction significative de l'utilisation de la mémoire, de 102,20 Go à 14,58 Go par rapport à SGD, lors de la formation du modèle LLaMA-7B, l'utilisation de la mémoire diminue ; de 51,99 Go réduit à 14,58 Go. La réduction significative de l'utilisation de la mémoire est principalement due à la réduction des besoins en mémoire pour les gradients et les états de l'optimiseur. Par conséquent, pendant le processus de formation, la mémoire est principalement occupée par des paramètres, ce qui équivaut à l’utilisation de la mémoire lors de l’inférence.
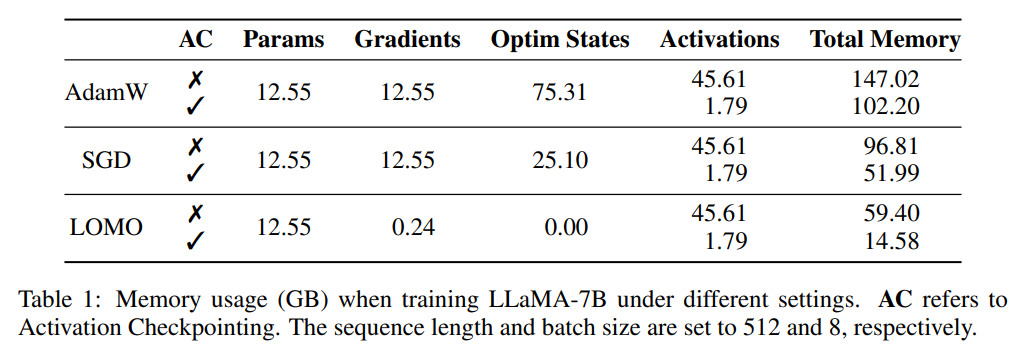
Comme le montre la figure 2, si l'optimiseur AdamW est utilisé pour la formation LLaMA-7B, une proportion considérable de mémoire (73,7 %) est allouée à l'état de l'optimiseur. Le remplacement de l'optimiseur AdamW par l'optimiseur SGD réduit efficacement le pourcentage de mémoire occupé par l'état de l'optimiseur, réduisant ainsi l'utilisation de la mémoire GPU (de 102,20 Go à 51,99 Go). Si LOMO est utilisé, les mises à jour des paramètres et les retours en arrière sont fusionnés en une seule étape, éliminant ainsi les besoins en mémoire pour l'état de l'optimiseur.
Débit
Les chercheurs ont comparé les performances de débit de LOMO, AdamW et SGD. Les expériences ont été menées sur un serveur équipé de 8 GPU RTX 3090.
Pour le modèle 7B, le débit de LOMO présente un avantage significatif, dépassant AdamW et SGD d'environ 11 fois. Cette amélioration significative peut être attribuée à la capacité de LOMO à entraîner le modèle 7B sur un seul GPU, ce qui réduit la surcharge de communication inter-GPU. Le débit légèrement supérieur de SGD par rapport à AdamW peut être attribué au fait que SGD exclut le calcul de la quantité de mouvement et de la variance.
Quant au modèle 13B, en raison de limitations de mémoire, il ne peut pas être entraîné avec AdamW sur les 8 GPU RTX 3090 existants. Dans ce cas, le parallélisme des modèles est nécessaire pour LOMO, qui surpasse toujours SGD en termes de débit. Cet avantage est attribué à la nature économe en mémoire de LOMO et au fait que seuls deux GPU sont nécessaires pour entraîner le modèle avec les mêmes paramètres, réduisant ainsi les coûts de communication et améliorant le débit. De plus, SGD a rencontré des problèmes de manque de mémoire (MOO) sur 8 GPU RTX 3090 lors de la formation du modèle 30B, tandis que LOMO a bien fonctionné avec seulement 4 GPU.
Enfin, le chercheur a réussi à entraîner le modèle 65B à l'aide de 8 GPU RTX 3090, atteignant un débit de 4,93 TGS. Avec cette configuration de serveur et LOMO, le processus de formation du modèle sur 1000 échantillons (chaque échantillon contient 512 tokens) prend environ 3,6 heures.
Performance aval
Afin d'évaluer LOMO in fine- réglage de grands modèles de langage Pour déterminer son efficacité, les chercheurs ont mené une vaste série d'expériences. Ils ont comparé LOMO à deux autres méthodes, l'une est Zero-shot, qui ne nécessite pas de réglage fin, et l'autre est LoRA, une technique de réglage fin populaire et efficace en termes de paramètres.
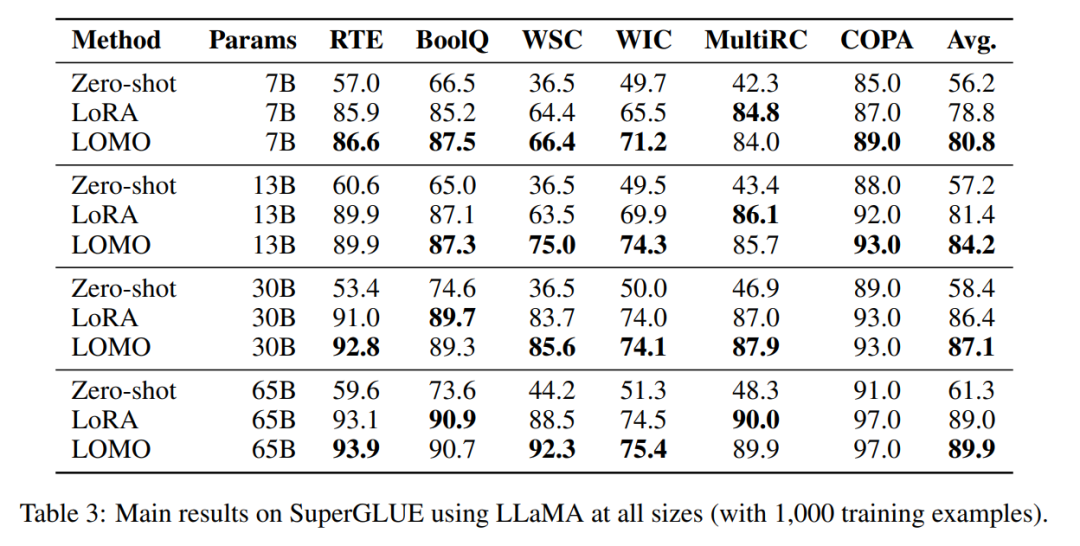
- # 🎜🎜#LOMO fonctionne nettement mieux que Zero-shot ;
- Dans la plupart des expériences, LOMO surpasse généralement LoRA ;# 🎜🎜## 🎜🎜#LOMO peut s'adapter efficacement à des modèles comportant 65 milliards de paramètres.
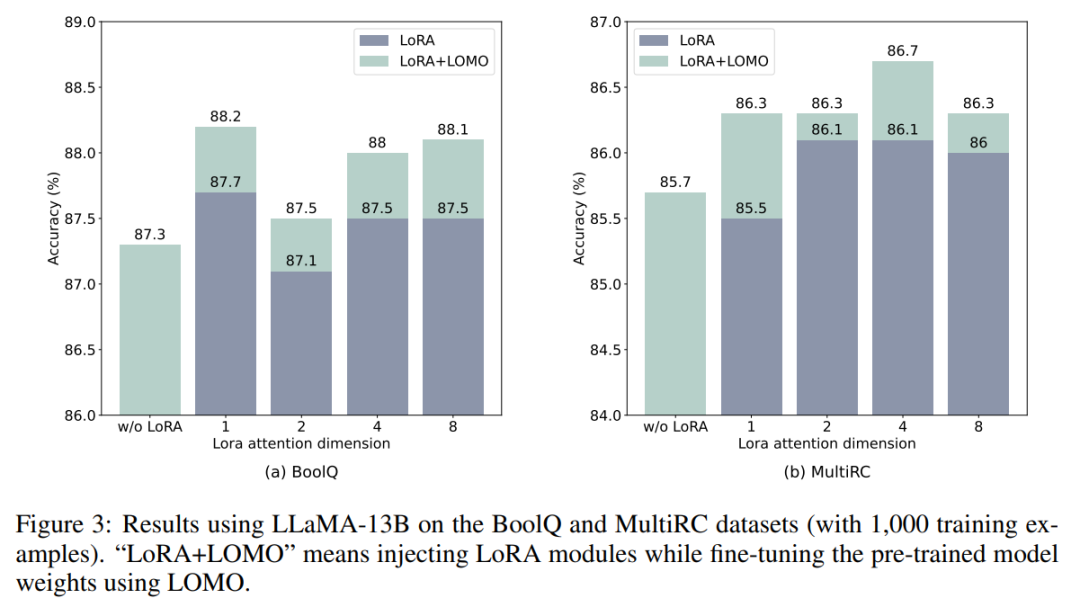
- LOMO et LoRA sont essentiellement indépendants l'un de l'autre. Pour vérifier cette affirmation, les chercheurs ont mené des expériences sur les ensembles de données BoolQ et MultiRC à l'aide de LLaMA-13B. Les résultats sont présentés dans la figure 3.
Ils ont constaté que LOMO continuait d'améliorer les performances de LoRA, quel que soit le niveau des résultats obtenus par LoRA. Cela montre que les différentes méthodes de réglage fin employées par LOMO et LoRA sont complémentaires. Plus précisément, LOMO se concentre sur le réglage fin des poids du modèle pré-entraîné, tandis que LoRA ajuste d'autres modules. Par conséquent, LOMO n’affecte pas les performances de LoRA, mais facilite un meilleur réglage du modèle pour les tâches en aval ;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI