
Maison >Périphériques technologiques >IA >Le chien robot de Tencent évolue : maîtriser les capacités de prise de décision autonome grâce au deep learning
Le chien robot de Tencent évolue : maîtriser les capacités de prise de décision autonome grâce au deep learning

- 王林avant
- 2023-06-16 17:01:40893parcourir
Le 14 juin, Tencent Robotics a été grandement amélioré.
Rendre les chiens robots aussi flexibles et stables que les humains et les animaux est un objectif à long terme dans le domaine de la recherche en robotique. Les progrès continus de la technologie d'apprentissage profond permettent aux machines de maîtriser des capacités pertinentes grâce à « l'apprentissage » et d'apprendre à faire face à des situations complexes et changeantes. environnements deviennent réalisables.
Présentation du pré-entraînement et de l'apprentissage par renforcement : rendre le chien robot plus agile
Tencent Robotics Il n'est pas nécessaire de réapprendre, mais vous pouvez réutiliser les connaissances à plusieurs niveaux de la posture, de la perception de l'environnement et de la planification stratégique que vous avez déjà apprises, et tirer des conclusions à partir d'un exemple pour faire face avec flexibilité à des environnements complexes


Cette série d'apprentissage est divisée en trois étapes :
Dans un premier temps, grâce au système de capture de mouvement souvent utilisé dans la technologie des jeux, le chercheur a collecté les données de posture de mouvement de vrais chiens, notamment la marche, la course, le saut, la position debout et d'autres actions, et a utilisé ces données pour construire une tâche d'apprentissage d'imitation. dans le simulateur, puis les informations contenues dans ces données sont extraites et compressées dans des modèles de réseaux neuronaux profonds. Ces modèles peuvent non seulement couvrir avec précision les informations collectées sur la posture des mouvements des animaux, mais également avoir une grande interprétabilité.
Tencent Robotique Ces technologies et données jouent un certain rôle auxiliaire dans la formation des agents basée sur la simulation physique et dans le déploiement de stratégies de robots dans le monde réel.
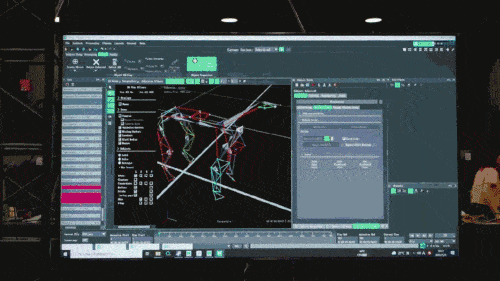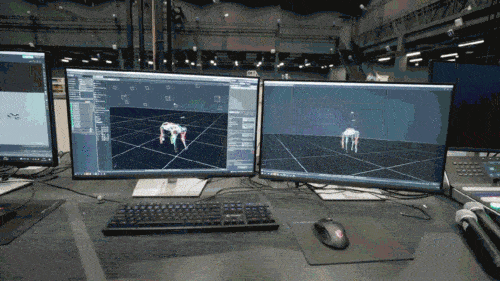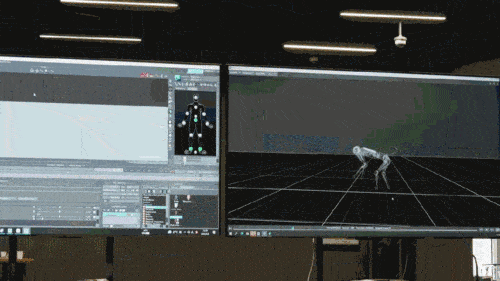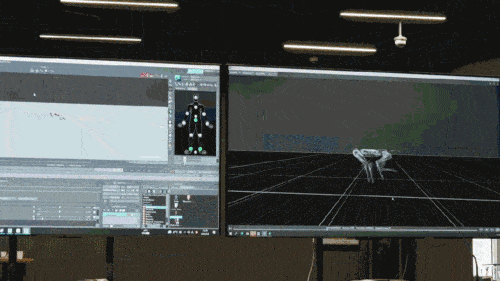

Le modèle de réseau neuronal n'accepte que les informations proprioceptives du chien robot (telles que l'état du moteur) en entrée et est entraîné selon une méthode d'apprentissage par imitation. Dans l'étape suivante, le modèle intègre des données sensorielles de l'environnement, par exemple en utilisant d'autres capteurs pour détecter les obstacles sous les pieds.
Dans la deuxième étape, des paramètres de réseau supplémentaires sont utilisés pour connecter la posture intelligente du chien robot maîtrisée dans la première étape avec la perception externe, afin que le chien robot puisse réagir à l'environnement externe grâce à la posture intelligente qu'il a apprise. Lorsque le chien robot s’adaptera à une variété d’environnements complexes, les connaissances qui relient les postures intelligentes à la perception externe seront également solidifiées et stockées dans la structure du réseau neuronal.



Dans la troisième étape, en utilisant le réseau neuronal obtenu au cours des deux étapes de pré-formation ci-dessus, le chien robot a la condition préalable et l'opportunité de se concentrer sur la résolution du problème d'apprentissage politique de haut niveau, et a enfin la capacité de résoudre des tâches complexes. -à la fin. Dans la troisième phase, des réseaux supplémentaires seront ajoutés pour collecter des données liées à des tâches complexes, telles que l'obtention d'informations sur les adversaires et les drapeaux du jeu. De plus, en analysant de manière exhaustive toutes les informations, le réseau neuronal responsable de l'apprentissage stratégique apprendra des stratégies de haut niveau pour la tâche, telles que la direction dans laquelle courir, prédire le comportement de l'adversaire pour décider de continuer à courir, etc.
Les connaissances acquises à chaque étape ci-dessus peuvent être élargies et ajustées sans réapprentissage, de sorte qu'elles puissent être continuellement accumulées et apprises en continu.
Concours de poursuite d'obstacles avec des chiens robots : possédant des capacités de prise de décision et de contrôle autonomes
Afin de tester ces nouvelles compétences maîtrisées par Max, le chercheur s'est inspiré du jeu de poursuite d'obstacles "World Chase Tag" et a conçu un jeu de poursuite d'obstacles à deux chiens. World Chase Tag est une organisation compétitive de chasse à obstacles fondée au Royaume-Uni en 2014. Elle est standardisée à partir des jeux de chasse folkloriques pour enfants. De manière générale, chaque tour de compétition de chasse à obstacles implique deux athlètes qui s'affrontent. L'un est le poursuivant (appelé l'attaquant) et l'autre est l'esquive (appelé le défenseur). Lorsqu'un athlète concourt tout au long de l'équipe, il recevra. un point lorsqu'ils réussissent à échapper à leur adversaire (c'est-à-dire qu'aucun contact ne se produit) pendant le tour de poursuite (c'est-à-dire 20 secondes). L'équipe qui marque le plus de points dans le nombre prédéterminé de tours de poursuite remporte la partie.
La taille du terrain de la compétition de chasse aux obstacles du chien robot est de 4,5 mètres x 4,5 mètres, avec quelques obstacles dispersés dessus. Au début du jeu, deux chiens robots MAX seront placés à des endroits aléatoires sur le terrain, et un chien robot se verra attribuer au hasard le rôle de poursuivant et l'autre d'évadé. En même temps, un drapeau sera placé. à un endroit aléatoire sur le terrain.
Le but du cagnard est de se rapprocher le plus possible du drapeau sans se faire rattraper par le poursuivant. La tâche du poursuivant est d'attraper l'évadé. Si l'esquive réussit à toucher le drapeau avant d'être attrapé, les rôles des deux chiens robots changeront instantanément et le drapeau réapparaîtra dans un autre endroit aléatoire. Le jeu se termine lorsque le esquive est rattrapé par le poursuivant actuel et que le chien robot jouant le rôle du poursuivant gagne. Dans tous les jeux, la vitesse d'avancement moyenne des deux chiens robots est limitée à 0,5 m/s.
Il ressort de ce jeu que, sur la base du modèle pré-entraîné, le chien robot possède déjà certaines capacités de raisonnement et de prise de décision grâce à un apprentissage par renforcement profond :
Par exemple, lorsque le poursuivant se rend compte qu'il ne peut plus rattraper le esquive avant qu'il ne touche le drapeau, il abandonnera la poursuite et s'éloignera du esquive afin d'attendre la prochaine réinitialisation. Le drapeau apparaît. .
De plus, lorsque le poursuivant est sur le point d'attraper le roublard au dernier moment, il aime sauter et faire une action de "bondir" vers le roublard, ce qui est très similaire au comportement des animaux lorsqu'ils attrapent une proie, ou lorsque le le Dodger est sur le point de toucher le drapeau aura le même comportement. Ce sont autant de mesures d’accélération proactives prises par le chien robot pour assurer sa victoire.
Selon les rapports, toutes les stratégies de contrôle des chiens robots du jeu sont des stratégies de réseau neuronal. Elles sont apprises par simulation et par transfert zéro-coup (transfert d'ajustement zéro), permettant au réseau neuronal de simuler les méthodes de raisonnement humain pour identifier. des choses qui n'ont jamais été vues auparavant et déployer ces connaissances sur de vrais chiens robots. Par exemple, comme le montre la figure ci-dessous, la connaissance de la manière d'éviter les obstacles que le chien robot a apprise dans le modèle de pré-entraînement est utilisée dans le jeu, même si les scènes avec des obstacles ne sont pas entraînées dans le monde virtuel de Chase Tag Game ( uniquement dans le monde virtuel Après s'être entraîné dans des scènes de jeu sur terrain plat), le chien robot peut également accomplir la tâche avec succès.
Tencent Robotics Son introduction dans le domaine des robots améliore les capacités de contrôle des robots et les rend plus flexibles. Cela jette également une base solide pour que les robots entrent dans la vie réelle et servent les êtres humains.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI