
Maison >Périphériques technologiques >IA >Prompt débloque les capacités de génération de modèles de langage vocal et SpeechGen implémente la traduction vocale et l'application de correctifs à plusieurs tâches.
Prompt débloque les capacités de génération de modèles de langage vocal et SpeechGen implémente la traduction vocale et l'application de correctifs à plusieurs tâches.

- 王林avant
- 2023-06-14 20:25:461452parcourir
H Lien de thèse : https://arxiv.org/pdf/2306.02207.pdf

- page de démonstration : https://ga642381.github.io/speeeeeeeeeeeechgen.html
- Code : https:/ /github.com/ga642381/SpeechGen
- Introduction et motivationLes grands modèles de langage (LLM) ont attiré une attention considérable dans le domaine du contenu généré par l'intelligence artificielle (AIGC), en particulier avec l'émergence de ChatGPT.
Cependant, comment traiter la parole continue avec de grands modèles de langage reste un défi non résolu, qui entrave l'application de grands modèles de langage dans la génération de parole. Étant donné que les signaux vocaux contiennent des informations riches, telles que le locuteur et les émotions, au-delà des données textuelles simples, des modèles de langage basés sur la parole (Speech LM) continuent d'émerger.
Bien que les modèles de langage vocal en soient encore à leurs débuts par rapport aux modèles de langage basés sur du texte, étant donné que les données vocales contiennent des informations plus riches que le texte, elles ont un potentiel énorme et sont pleines d'attentes.
Les chercheurs explorent activement le potentiel du paradigme d'invite pour libérer la puissance des modèles linguistiques pré-entraînés. Cette invite guide le modèle de langage pré-entraîné pour effectuer des tâches spécifiques en aval en ajustant un petit nombre de paramètres. Cette technique est populaire dans le domaine de la PNL en raison de son efficacité et de son efficacité. Dans le domaine du traitement de la parole, SpeechPrompt a démontré des améliorations significatives de l'efficacité des paramètres et atteint des performances compétitives dans diverses tâches de classification de la parole.
Cependant, la question de savoir si les indices peuvent aider les modèles de langage vocal à accomplir la tâche de génération reste une question ouverte. Dans cet article, nous proposons un cadre unifié innovant : SpeechGen, visant à libérer le potentiel des modèles de langage vocal pour les tâches de génération. Comme le montre la figure ci-dessous, un morceau de discours et une invite spécifique (invite) sont transmis au LM vocal en entrée, et le LM vocal peut effectuer des tâches spécifiques. Par exemple, si l'invite rouge est utilisée comme entrée, Speech LM peut effectuer la tâche de traduction vocale.
Le framework que nous proposons présente les avantages suivants :
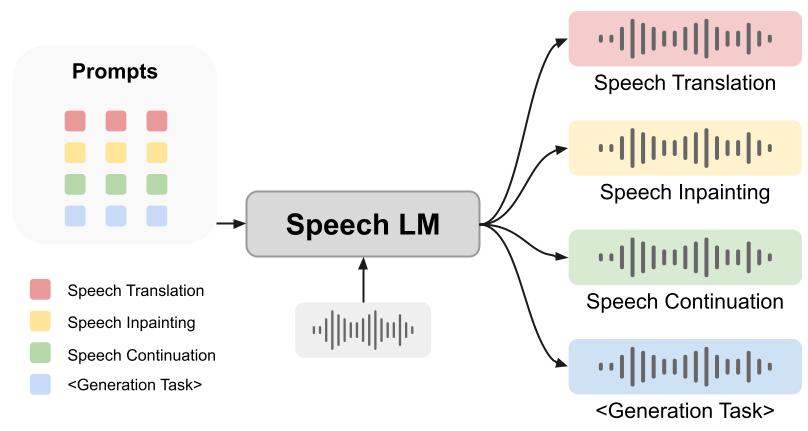 1 : Notre framework et le modèle de langage vocal sur lequel il s'appuie sont indépendants des données textuelles et ont une valeur incommensurable. Après tout, le processus d'obtention de paires texte-parole balisées prend du temps et est fastidieux, et dans certaines langues, le bon texte peut même ne pas être trouvé. La fonctionnalité sans texte permet à nos puissantes capacités de génération vocale de couvrir divers besoins linguistiques, au bénéfice de toute l'humanité.
1 : Notre framework et le modèle de langage vocal sur lequel il s'appuie sont indépendants des données textuelles et ont une valeur incommensurable. Après tout, le processus d'obtention de paires texte-parole balisées prend du temps et est fastidieux, et dans certaines langues, le bon texte peut même ne pas être trouvé. La fonctionnalité sans texte permet à nos puissantes capacités de génération vocale de couvrir divers besoins linguistiques, au bénéfice de toute l'humanité.
2. Polyvalence : Le cadre que nous avons développé est extrêmement polyvalent et peut être appliqué à une variété de tâches de génération de parole. Dans l'article, la traduction de la parole, la restauration de la parole et la continuité de la parole sont utilisées comme exemples dans les expériences.
3. Facile à suivre : notre cadre proposé fournit une solution générale pour diverses tâches de génération de parole, facilitant la conception de modèles en aval et de fonctions de perte.
4. Transférabilité : Notre cadre est non seulement facilement adaptable à des modèles de langage vocal plus avancés à l'avenir, mais contient également un énorme potentiel pour améliorer encore l'efficience et l'efficacité. Ce qui est particulièrement intéressant, c’est qu’avec l’avènement de modèles avancés de langage vocal, notre cadre ouvrira la voie à des développements encore plus puissants.
5. Abordabilité : notre framework est soigneusement conçu pour n'avoir besoin de former qu'un petit nombre de paramètres au lieu d'un énorme modèle de langage. Cela réduit considérablement la charge de calcul et permet d'effectuer le processus de formation sur un GPU GTX 2080. Les laboratoires universitaires peuvent également se permettre de tels frais de calcul.
Introduction à SpeechGen
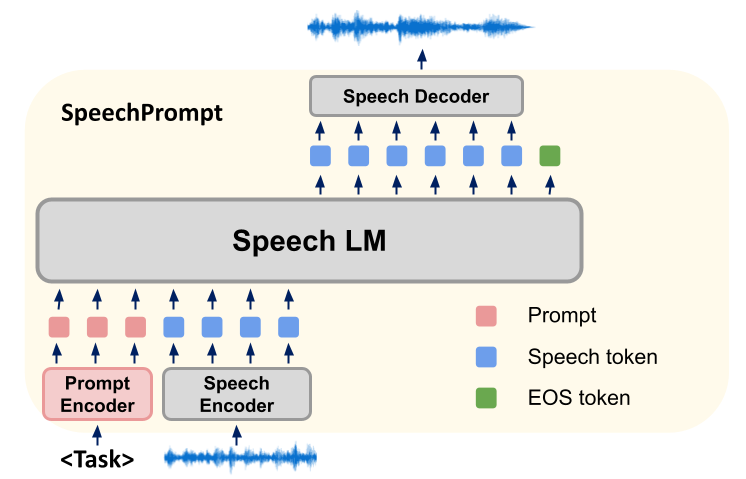
Notre méthode de recherche consiste à construire un nouveau framework SpeechGen, qui utilise principalement un modèle de langage vocal (Spoken Language Models, SLM) pour affiner diverses tâches de génération de parole en aval. Pendant la formation, les paramètres des SLM restent constants et notre méthode se concentre sur l'apprentissage de vecteurs d'invite spécifiques à une tâche. Les SLM génèrent efficacement la sortie requise pour une tâche de génération vocale spécifique en conditionnant simultanément des vecteurs de repères et des unités d'entrée. Ces sorties d'unités discrètes sont ensuite entrées dans un synthétiseur vocal basé sur des unités, qui génère les formes d'onde correspondantes.
Notre framework SpeechGen se compose de trois éléments : Speech Encoder, SLM et Speech Decoder.
Tout d'abord, l'encodeur vocal prend une forme d'onde en entrée et la convertit en une séquence d'unités dérivées d'un vocabulaire limité. Pour raccourcir la longueur de la séquence, les unités consécutives répétées sont supprimées pour produire une séquence compressée d'unités. Le SLM agit alors comme un modèle de langage pour la séquence d'unités, optimisant la probabilité en prédisant l'unité précédente et les unités suivantes de la séquence d'unités. Nous apportons des ajustements rapides au SLM pour le guider afin de générer des unités appropriées pour la tâche. Enfin, les jetons générés par le SLM sont traités par un décodeur vocal, les reconvertissant en formes d'onde. Dans notre stratégie de réglage des repères, les vecteurs de repères sont insérés au début de la séquence d'entrée, ce qui guide la direction des SLM pendant la génération. Le nombre exact d'indices insérés dépend de l'architecture des SLM. Dans un modèle séquence à séquence, les signaux sont ajoutés à la fois à l'entrée du codeur et à l'entrée du décodeur, mais dans une architecture à codeur uniquement ou à décodeur uniquement, seul un indice est ajouté devant la séquence d'entrée.
Dans les SLM séquence à séquence (comme mBART), nous utilisons des modèles d'apprentissage auto-supervisés (comme HuBERT) pour traiter l'entrée et le discours cible. Cela génère des unités discrètes pour l'entrée et des unités discrètes correspondantes pour la cible. Nous ajoutons des vecteurs d'indices devant les entrées du codeur et du décodeur pour construire la séquence d'entrée. De plus, nous améliorons encore la capacité de guidage des indices en remplaçant les paires clé-valeur dans le mécanisme d'attention.
Dans la formation du modèle, nous utilisons la perte d'entropie croisée comme fonction objectif pour toutes les tâches de génération et calculons la perte en comparant les résultats de prédiction du modèle et l'unité discrète cible étiquettes. Dans ce processus, le vecteur de repères est le seul paramètre du modèle qui doit être entraîné, tandis que les paramètres des SLM restent inchangés pendant le processus d'entraînement, ce qui garantit la cohérence du comportement du modèle. En insérant des vecteurs de repères, nous guidons les SLM pour extraire des informations spécifiques à une tâche de l'entrée et augmenter la probabilité de produire une sortie cohérente avec une tâche de génération de parole spécifique. Cette approche nous permet d'affiner et d'ajuster le comportement des SLM sans modifier leurs paramètres sous-jacents.
En général, notre méthode de recherche est basée sur un nouveau framework SpeechGen, qui guide le processus de génération du modèle en entraînant des vecteurs d'invite et lui permet de produire efficacement une sortie cohérente avec une tâche de génération de parole spécifique.
Experiment
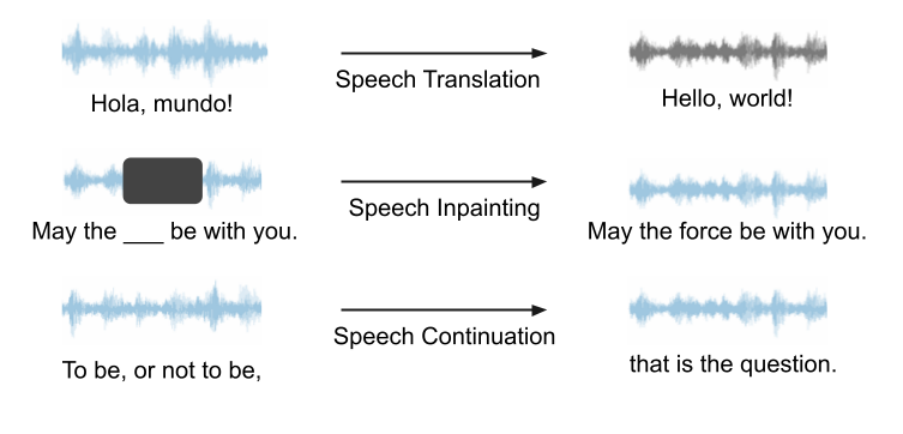
Notre framework peut être utilisé pour n'importe quel discours LM et diverses tâches de génération, et a un grand potentiel. Dans nos expériences, puisque VALL-E et AudioLM ne sont pas open source, nous choisissons d'utiliser l'Unité mBART comme LM vocal pour l'étude de cas. Nous utilisons la traduction vocale, l'inpainting vocal et la continuation de la parole comme exemples pour démontrer les capacités de notre framework. Un diagramme schématique de ces trois tâches est présenté ci-dessous. Toutes les tâches sont une saisie vocale, une sortie vocale, aucune aide textuelle n'est requise. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # Traduction vocale # 🎜🎜 ## 🎜🎜 # #
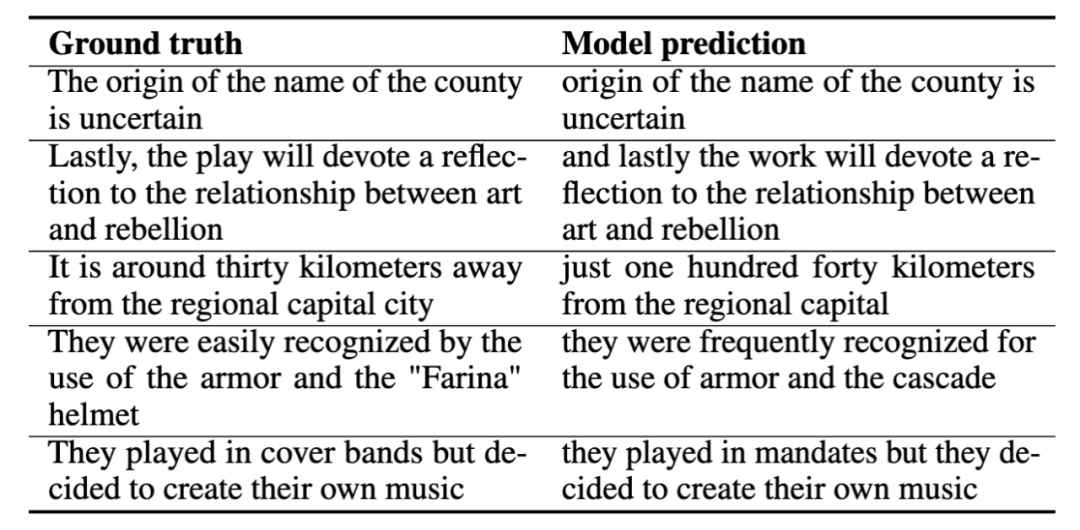
Lorsque nous formons la traduction vocale (traduction vocale), nous utilisons la tâche de convertir l'espagnol vers l'anglais. Nous introduisons le discours espagnol dans le modèle et espérons que le modèle produira un discours anglais sans l'aide de texte dans l'ensemble du processus. Vous trouverez ci-dessous plusieurs exemples de traduction vocale, dans lesquels nous montrons la bonne réponse (vérité terrain) et la prédiction du modèle (prédiction du modèle). Ces exemples de démonstration montrent que les prédictions du modèle capturent la signification fondamentale de la bonne réponse.
Voice patch
Voice in us In Lors de l'expérience d'inpainting vocal, nous avons spécifiquement sélectionné des clips audio de plus de 2,5 secondes comme parole cible pour un traitement ultérieur, et avons sélectionné un clip vocal compris entre 0,8 et 1,2 seconde grâce à un processus de sélection aléatoire. Nous masquons ensuite les segments sélectionnés pour simuler les parties manquantes ou endommagées dans une tâche d'inpainting vocal. Nous avons utilisé le taux d'erreur sur les mots (WER) et le taux d'erreur sur les caractères (CER) comme mesures pour évaluer le degré de réparation des segments endommagés.
Analyse comparative du résultat généré par SpeechGen et de la parole endommagée, notre modèle peut reconstruire de manière significative le vocabulaire parlé, réduisant le WER de 41,68 % à 28,61 %, réduisant ainsi le CER de 25,10% à 10,75%, comme indiqué dans le tableau ci-dessous. Cela signifie que la méthode proposée peut améliorer considérablement la capacité de reconstruction de la parole, favorisant ainsi l’exactitude et la compréhensibilité de la sortie vocale.

L'image ci-dessous est un exemple d'affichage, et la sous-image ci-dessus est un sujet Discours endommagé. La sous-image ci-dessous est le discours généré par SpeechGen. On peut voir que SpeechGen répare très bien le discours endommagé.
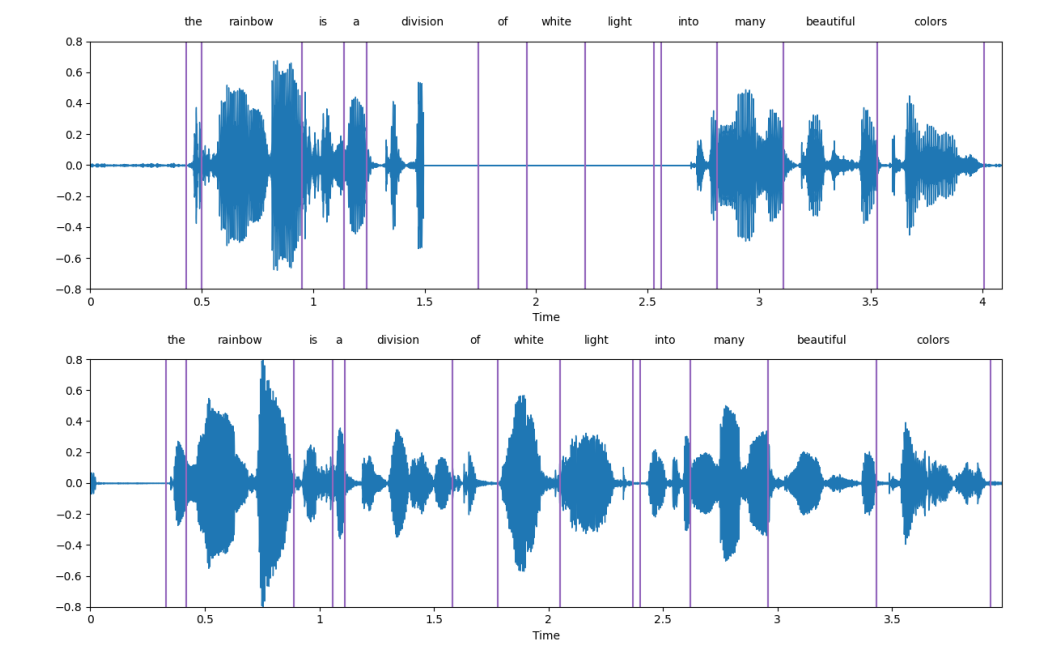
voicecontinuous#🎜🎜 # # 🎜🎜#
Nous démontrerons l'application pratique des tâches vocales continues via LJSpeech. Pendant l'invite de formation (invite), notre stratégie consiste à laisser le modèle voir uniquement le segment de départ du segment. Ce segment de départ occupe une proportion de la longueur totale du discours. Nous appelons cela le rapport de condition (r). Le modèle continue de générer un discours ultérieur.Voici quelques exemples. Le texte noir représente le segment de départ, et le texte rouge est la phrase générée par SpeechGen (le texte ici est d'abord obtenu par reconnaissance vocale Résultats Pendant la formation et l'inférence, le modèle effectue entièrement des tâches de synthèse vocale et ne reçoit aucune information textuelle. Différents ratios de conditions permettent à SpeechGen de générer des phrases de différentes longueurs pour assurer la cohérence et compléter une phrase complète. Du point de vue de la qualité, les phrases générées sont fondamentalement cohérentes syntaxiquement avec les fragments de départ et sont sémantiquement liées. Cependant, le discours généré ne peut toujours pas transmettre parfaitement une signification complète. Nous prévoyons que ce problème sera résolu dans le futur dans des modèles de parole plus puissants.
Insuffisances et orientations futures
Les modèles de langage vocal et la génération vocale sont dans une phase en plein essor, et notre cadre offre la possibilité d'exploiter intelligemment modèles de langage puissants pour la génération de parole. Cependant, ce cadre peut encore être amélioré et de nombreuses questions méritent une étude plus approfondie.1. Comparés aux modèles de langage basés sur du texte, les modèles de langage vocal en sont encore au stade initial de développement. Bien que le cadre de repérage que nous avons proposé puisse inspirer le modèle de langage vocal à effectuer des tâches de génération de parole, il ne peut pas atteindre d'excellentes performances. Cependant, avec l'évolution continue des modèles de langage vocal, comme le grand passage du GSLM à l'Unité mBART, les performances des invites ont été considérablement améliorées. En particulier, les tâches qui étaient auparavant difficiles pour GSLM affichent désormais de meilleures performances sous l'unité mBART. Nous nous attendons à ce que des modèles de langage vocal plus avancés émergent à l’avenir.
2. Au-delà des informations sur le contenu : les modèles de langage vocal actuels ne peuvent pas capturer pleinement les informations sur le locuteur et ses émotions, ce qui rend le cadre d'invite vocale actuel incapable de traiter efficacement ces informations. . Pour surmonter cette limitation, nous introduisons des modules plug-and-play qui injectent spécifiquement des informations sur le locuteur et ses émotions dans le cadre. À l’avenir, nous prévoyons que les futurs modèles de langage vocal intégreront et exploiteront des informations au-delà de celles-ci pour améliorer les performances et mieux gérer les aspects liés au locuteur et aux émotions des tâches de génération de parole.
3. Possibilité de génération d'invites : Pour la génération d'invites, nous disposons d'options flexibles et pouvons intégrer différents types d'instructions, notamment des instructions sous forme de texte et d'images. Imaginez que nous puissions entraîner un réseau de neurones à prendre des images ou du texte en entrée, au lieu d'utiliser des intégrations entraînées comme indices comme dans cet article. Ce réseau formé deviendra le générateur d’indices, ajoutant de la variété au cadre. Cette approche rendra la génération d'invites plus intéressante et colorée. Dans cet article, nous avons exploré l'utilisation d'indices pour débloquer les performances des modèles de langage vocal dans une variété de tâches génératives. Nous proposons un framework unifié appelé SpeechGen qui ne comporte qu'environ 10 millions de paramètres entraînables. Le cadre que nous proposons présente plusieurs propriétés majeures, notamment l'absence de texte, la polyvalence, l'efficacité, la transférabilité et l'abordabilité. Pour démontrer les capacités du framework SpeechGen, nous utilisons l'unité mBART comme étude de cas et menons des expériences sur trois tâches de génération de parole différentes : traduction de la parole, réparation de la parole et continuation de la parole. Lorsque cet article a été soumis à arXiv, Google a proposé un modèle de langage vocal plus avancé - SPECTRON, qui nous a montré la possibilité des modèles de langage vocal dans la modélisation d'informations telles que les locuteurs et les émotions. Il s’agit sans aucun doute d’une nouvelle passionnante. Alors que des modèles avancés de langage vocal continuent d’être proposés, notre cadre unifié présente un grand potentiel. Conclusion
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI