
Maison >Périphériques technologiques >IA >Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.

- 王林avant
- 2023-06-14 13:43:171615parcourir
Il y a quelque temps, un tweet soulignant l'incohérence entre le schéma d'architecture du Transformer et le code de l'article de l'équipe Google Brain "L'attention est tout ce dont vous avez besoin" a déclenché de nombreuses discussions.
Certaines personnes pensent que la découverte de Sebastian était une erreur honnête, mais elle est aussi étrange en même temps. Après tout, étant donné la popularité de l’article de Transformer, cette incohérence aurait dû être mentionnée mille fois.
Sebastian Raschka a déclaré en réponse aux commentaires des internautes que le code "le plus original" est effectivement cohérent avec le schéma d'architecture, mais que la version du code soumise en 2017 a été modifiée, mais que le schéma d'architecture n'a pas été mis à jour en même temps. C’est aussi la cause profonde des discussions « incohérentes ».
Par la suite, Sebastian a publié un article sur Ahead of AI décrivant spécifiquement pourquoi le diagramme d'architecture original de Transformer était incohérent avec le code, et a cité plusieurs articles pour expliquer brièvement le développement et les modifications de Transformer.
Ce qui suit est le texte original de l'article, jetons un coup d'œil à de quoi parle l'article :
Il y a quelques mois, j'ai partagé "Comprendre les grands modèles de langage : une approche croisée -Section de la « Littérature la plus pertinente pour se mettre au courant », les retours positifs sont très encourageants ! Par conséquent, j'ai ajouté quelques articles pour garder la liste à jour et pertinente.
En même temps, il est crucial de garder la liste concise et concise afin que chacun puisse se mettre au courant dans un délai raisonnable. Certains documents contiennent également de nombreuses informations et devraient probablement être inclus.
Je souhaite partager quatre articles utiles pour comprendre Transformer d'un point de vue historique. Bien que je les ajoute simplement directement à l'article Comprendre les grands modèles linguistiques, je les partage également séparément dans cet article afin qu'ils puissent être plus facilement trouvés par ceux qui ont déjà lu Comprendre les grands modèles linguistiques.
Sur la normalisation des couches dans l'architecture du transformateur (2020)
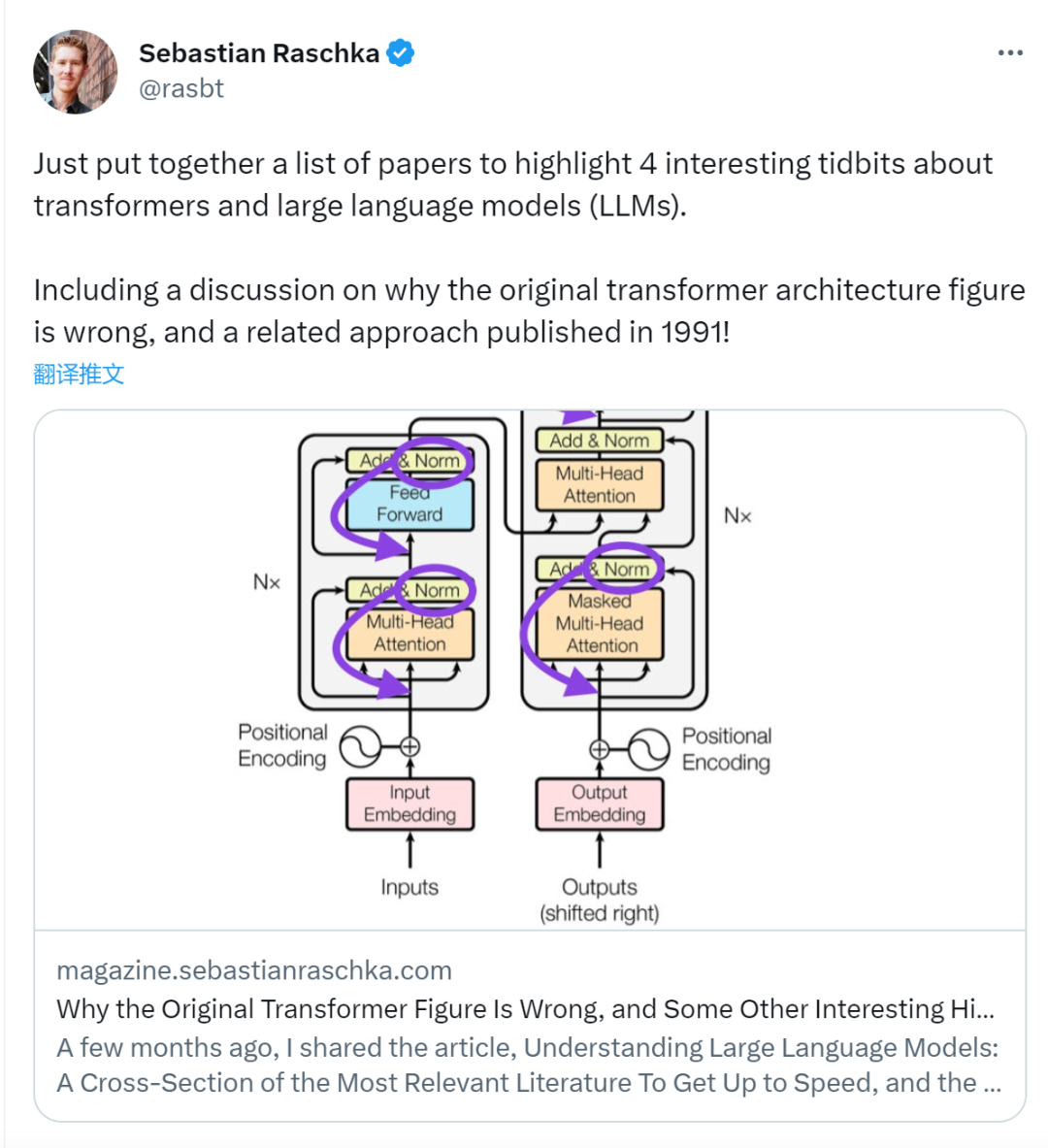
Bien que l'image originale du transformateur (https://arxiv.org/abs/1706.03762) ci-dessous (à gauche) soit l'encodeur-décodage original Un utile résumé de l'architecture du serveur, mais il y a une petite différence dans le diagramme. Par exemple, il effectue une normalisation des couches entre les blocs résiduels, ce qui ne correspond pas à l'implémentation du code officiel (mis à jour) incluse dans le document Transformer d'origine. La variante présentée ci-dessous (au milieu) s'appelle le transformateur Post-LN. La normalisation des couches dans le document sur l'architecture
Transformer montre que Pre-LN fonctionne mieux et peut résoudre le problème du dégradé comme indiqué ci-dessous. De nombreuses architectures adoptent cette approche dans la pratique, mais cela peut conduire à un effondrement de la représentation.
Ainsi, même s'il y a encore des discussions sur l'utilisation du Post-LN ou du Pre-LN, il existe également un nouvel article qui propose d'appliquer les deux ensemble : "ResiDual : Transformer with Dual Residual Connections" (https://arxiv .org /abs/2304.14802), mais reste à savoir si cela sera utile en pratique.
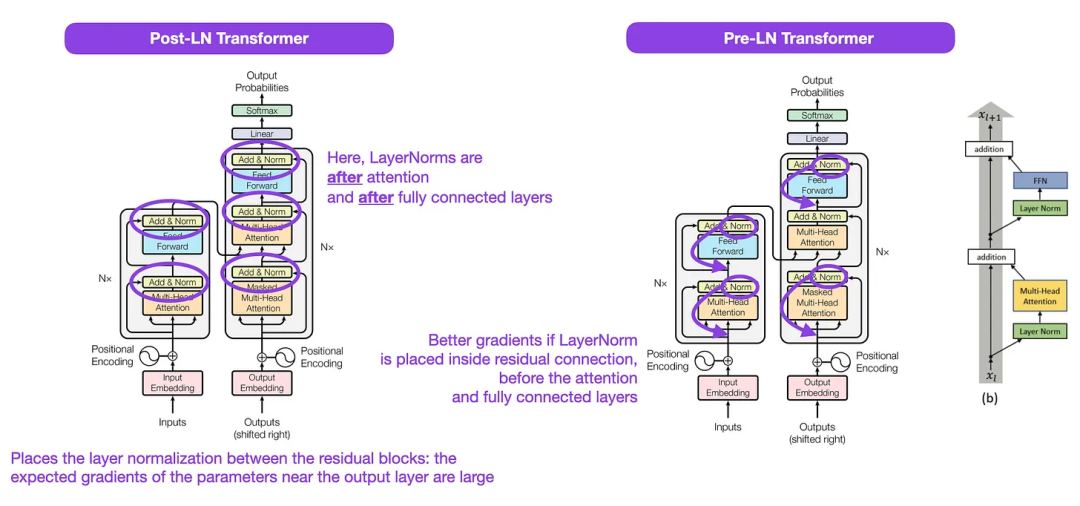
Légende : Source de l'image https://arxiv.org/abs/1706.03762 (gauche et centre) et https://arxiv.org/abs/2002.04745 (droite)
Apprendre à contrôler les mémoires à poids rapide : une alternative aux réseaux de neurones dynamiques récurrents (1991)
Cet article est recommandé à ceux qui s'intéressent aux informations historiques et aux premières méthodes qui sont fondamentalement similaires au Transformer moderne.
Par exemple, en 1991, 25 ans avant l'article Transformer, Juergen Schmidhuber a proposé une alternative aux réseaux de neurones récurrents (https://www.semanticscholar.org/paper/Learning-to-Control-Fast-Weight-Memories%3A -An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922), appelés Fast Weight Programmers (FWP). Un autre réseau neuronal qui permet d'obtenir des changements de poids rapides est le réseau neuronal feedforward impliqué dans la méthode FWP qui apprend lentement à l'aide de l'algorithme de descente de gradient.
Ce blog (https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2) le compare au Transformer moderne comme suit :
Dans le Transformer d'aujourd'hui terminologie, FROM et TO sont appelés respectivement clé et valeur. L’entrée à laquelle le réseau rapide est appliqué est appelée une requête. Essentiellement, les requêtes sont traitées par une matrice de poids rapide, qui est la somme des produits externes des clés et des valeurs (en ignorant la normalisation et la projection). Nous pouvons utiliser des produits externes additifs ou des produits tensoriels de second ordre pour obtenir un contrôle actif différenciable de bout en bout des changements de poids rapides, car toutes les opérations des deux réseaux prennent en charge la différenciation. Pendant le traitement de séquence, la descente de gradient peut être utilisée pour ajuster rapidement les réseaux rapides afin de faire face aux problèmes des réseaux lents. Ceci est mathématiquement équivalent (à l'exception de la normalisation) à ce que l'on appelle désormais un transformateur avec une attention personnelle linéarisée (ou transformateur linéaire).
Comme mentionné dans l'extrait ci-dessus, cette approche est désormais connue sous le nom de Transformateur linéaire ou Transformateur avec auto-attention linéarisée. Ils proviennent des articles « Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention » (https://arxiv.org/abs/2006.16236) et « Rethinking Attention with Performers » (https://arxiv.org/abs/2009.14794). .
En 2021, l'article « Les transformateurs linéaires sont des programmeurs de poids secrètement rapides » (https://arxiv.org/abs/2102.11174) montre clairement la différence entre l'auto-attention linéarisée et les programmeurs de poids rapides de l'équivalence des années 1990.
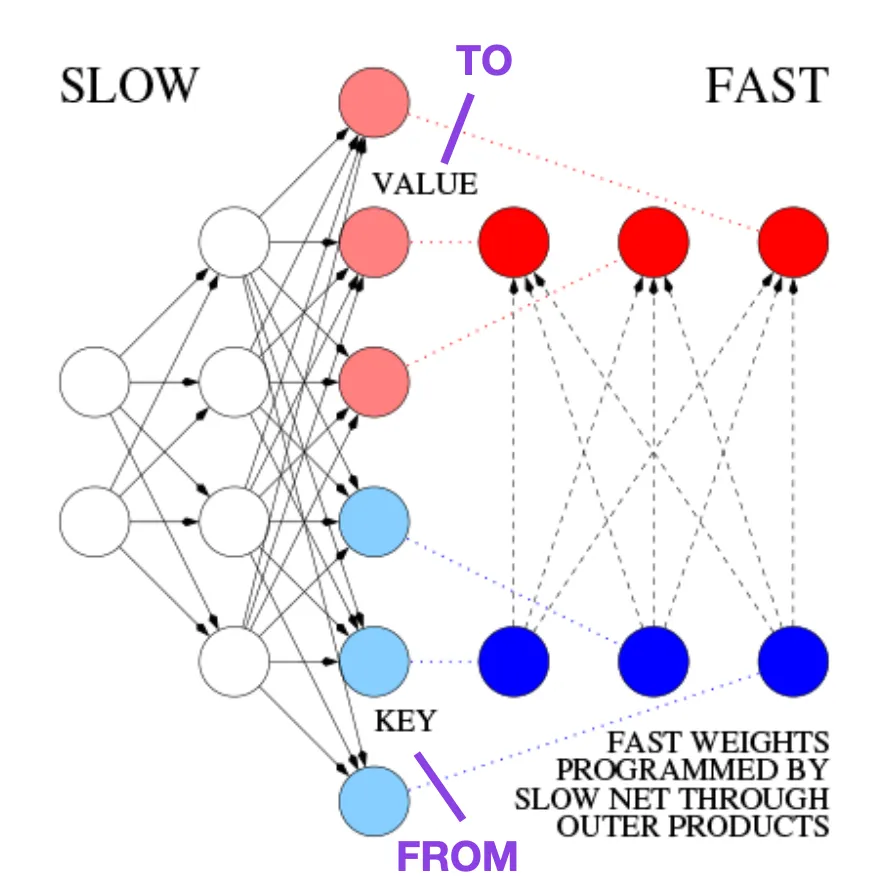
Source de l'image : https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2
Universel Affinement du modèle linguistique pour la classification de texte (2018)
C'est un autre article très intéressant d'un point de vue historique. Il a été écrit un an après la sortie de l'original Attention Is All You Need et n'implique pas de transformateurs, se concentrant plutôt sur les réseaux neuronaux récurrents, mais cela vaut toujours la peine d'être regardé. Parce qu'il propose efficacement des modèles linguistiques pré-entraînés et des tâches en aval d'apprentissage par transfert. Bien que l’apprentissage par transfert soit bien établi en vision par ordinateur, il n’est pas encore devenu populaire dans le domaine du traitement du langage naturel (NLP). ULMFit (https://arxiv.org/abs/1801.06146) est l'un des premiers articles à montrer que les modèles de langage pré-entraînés peuvent produire des résultats SOTA sur de nombreuses tâches PNL lorsqu'ils sont affinés sur une tâche spécifique.
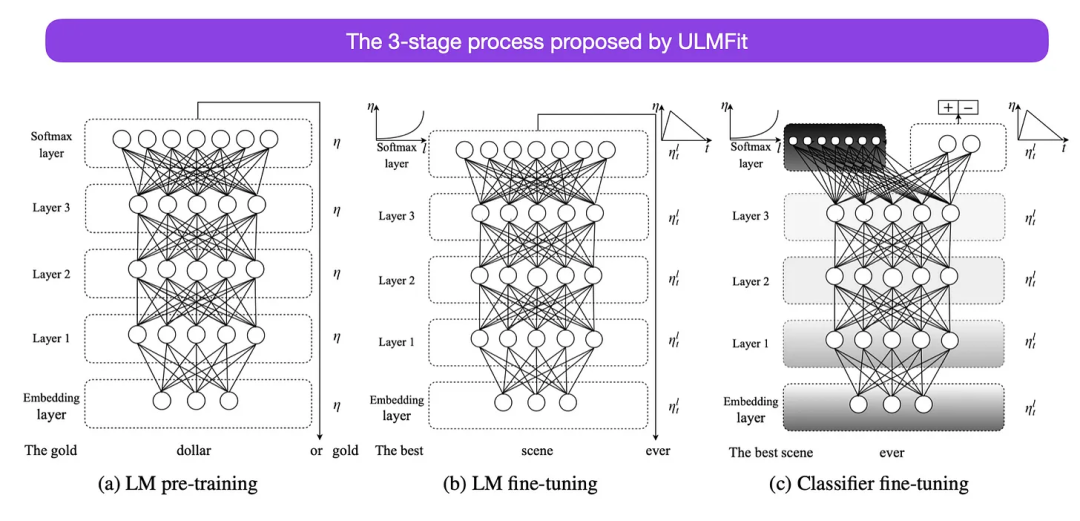
Le processus de réglage fin du modèle de langage proposé par ULMFit est divisé en trois étapes :
- 1. Entraînement du modèle de langage sur un grand corpus de texte
- 2. -données spécifiques Le modèle est affiné pour s'adapter au style et au vocabulaire spécifiques du texte
- 3 Affiner le classificateur sur les données spécifiques à la tâche pour éviter des oublis catastrophiques en dégelant progressivement les calques.
Cette méthode de formation d'un modèle de langage sur un grand corpus puis de l'affiner sur des tâches en aval est basée sur les modèles Transformer et les modèles de base (tels que BERT, GPT-2/3/4, RoBERTa, etc. ) méthodes de base utilisées.
Cependant, en tant qu'élément clé d'ULMFiT, le dégel progressif n'est généralement pas effectué dans la pratique car l'architecture Transformer ajuste généralement toutes les couches en même temps.
Gopher est un article particulièrement bon (https://arxiv.org/abs/2112.11446) qui comprend une analyse approfondie pour comprendre la formation LLM. Les chercheurs ont formé un modèle à 80 couches et 280 milliards de paramètres sur 300 milliards de jetons. Cela inclut quelques modifications architecturales intéressantes, telles que l'utilisation de RMSNorm (normalisation quadratique moyenne) au lieu de LayerNorm (normalisation de couche). LayerNorm et RMSNorm sont tous deux meilleurs que BatchNorm car ils ne sont pas limités à la taille des lots et ne nécessitent pas de synchronisation, ce qui constitue un avantage dans les environnements distribués avec des tailles de lots plus petites. RMSNorm est généralement considéré comme stabilisant la formation dans des architectures plus profondes.
Outre les informations intéressantes ci-dessus, l'objectif principal de cet article est d'analyser l'analyse des performances des tâches à différentes échelles. L'évaluation de 152 tâches différentes montre que l'augmentation de la taille du modèle est plus bénéfique pour les tâches telles que la compréhension, la vérification des faits et l'identification du langage toxique, tandis que l'expansion de l'architecture est moins bénéfique pour les tâches liées au raisonnement logique et mathématique.
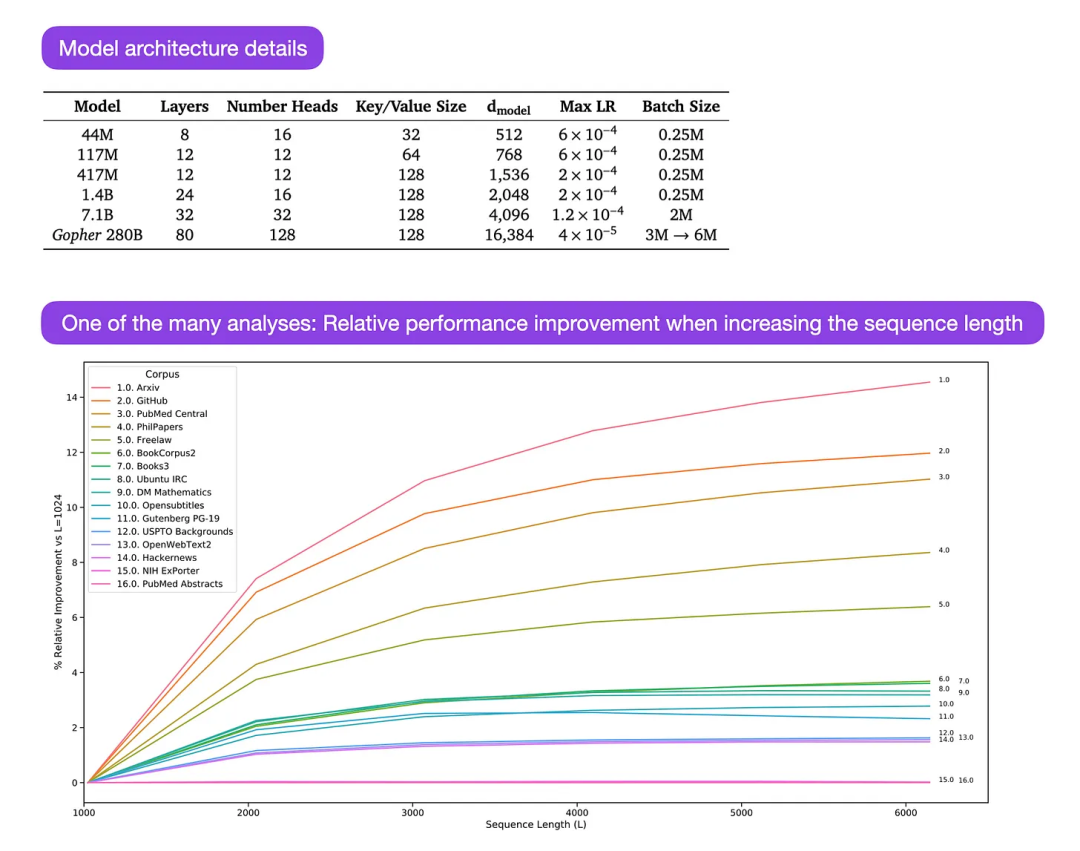
Légende : Source https://arxiv.org/abs/2112.11446
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI