
Maison >Périphériques technologiques >IA >Le méta texte open source génère un grand modèle musical. Nous l'avons essayé avec les paroles de 'Qilixiang'.
Le méta texte open source génère un grand modèle musical. Nous l'avons essayé avec les paroles de 'Qilixiang'.

- 王林avant
- 2023-06-13 21:16:172020parcourir
Avant d'entrer dans le texte principal, écoutons deux morceaux de musique générés par MusicGen. Nous entrons dans la description textuelle "un homme marche sous la pluie, croise une belle fille et ils dansent joyeusement"
puis essayons d'entrer la première partie du paroles de "Qili Xiang" de Jay Chou Deux phrases "Les moineaux devant la fenêtre sont bavards sur les poteaux téléphoniques. Vous avez dit que cette phrase avait un sentiment d'été" (chinois soutenu)
#🎜 🎜#Adresse d'essai : https://huggingface.co/spaces/facebook/MusicGen
Text-to-music fait référence au génération d'œuvres musicales dotées d'une description textuelle Tâches telles que "Chanson rock riff de guitare des années 90". Générer de la musique implique de modéliser de longues séquences comme une tâche difficile. Contrairement à la parole, la musique nécessite l'utilisation du spectre complet, ce qui signifie que le signal est échantillonné à une fréquence plus élevée, c'est-à-dire que la fréquence d'échantillonnage standard pour les enregistrements musicaux est de 44,1 kHz ou 48 kHz, tandis que la parole est échantillonnée à 16 kHz.
De plus, la musique contient l'harmonie et la mélodie de différents instruments, ce qui donne à la musique une structure complexe. Mais parce que les auditeurs humains sont très sensibles aux dissonances, ils n’ont pas beaucoup de tolérance pour les mélodies de la musique générée. Bien entendu, la capacité de contrôler le processus de génération de plusieurs manières est essentielle pour les créateurs de musique, comme les tonalités, les instruments, les mélodies, les genres, etc.
Les progrès récents dans l'apprentissage auto-supervisé de la représentation audio, la modélisation de séquences et la synthèse audio fournissent les conditions nécessaires au développement de tels modèles. Pour faciliter la modélisation audio, des recherches récentes proposent de représenter les signaux audio comme un flux de jetons discrets qui « représentent le même signal ». Cela permet une génération audio de haute qualité et une modélisation audio efficace. Cependant cela nécessite une modélisation conjointe de plusieurs flux de dépendances parallèles.
Kharitonov et al. [2022], Kreuk et al. [2022] ont proposé d'utiliser une méthode de retard pour modéliser plusieurs flux de jetons vocaux en parallèle, c'est-à-dire introduire un biais entre les différents flux. Agostinelli et al. [2023] ont proposé d'utiliser plusieurs séquences de jetons discrets de différentes granularités pour représenter des fragments musicaux et de les modéliser à l'aide d'une hiérarchie de modèles autorégressifs. Pendant ce temps, Donahue et al. [2023] ont adopté une approche similaire mais ont ciblé la tâche du chant sur la génération d'accompagnement. Récemment, Wang et al. [2023] ont proposé de résoudre ce problème en deux étapes : restreindre la modélisation au premier flux de jetons. Un post-réseau est ensuite appliqué pour modéliser conjointement les flux restants de manière non autorégressive.
Dans cet article, des chercheurs de Meta AI ont proposé MUSICGEN, un modèle de génération de musique simple et contrôlable qui peut générer de la musique basée sur une description textuelle donnée. Générez de la musique de haute qualité. .

# 🎜 Le chercheur a proposé un cadre général pour la modélisation de plusieurs flux parallèles de jetons acoustiques, comme généralisation des recherches antérieures (voir Figure 1 ci-dessous). Afin d'améliorer la contrôlabilité des échantillons générés, cet article introduit également des conditions mélodiques non supervisées, permettant au modèle de générer une musique structurellement adaptée, basée sur une harmonie et une mélodie données. Cet article effectue une évaluation approfondie de MUSICGEN, et la méthode proposée surpasse largement les lignes de base de l'évaluation : MUSICGEN reçoit un score subjectif de 84,8 sur 100, contre 80,5 pour la meilleure base de référence. De plus, cet article fournit une étude d’ablation qui illustre l’importance de chaque composant pour les performances globales du modèle.
Enfin, une évaluation humaine a montré que MUSICGEN produisait des échantillons de haute qualité qui correspondaient à la description textuelle et mélodiquement mieux harmonisés avec l'alignement structurel donné. Les principales contributions de cet article sont les suivantes : #🎜🎜 A quelle heure :
- propose un modèle simple et efficace : il peut produire une musique de haute qualité à 32khz. MUSICGEN peut générer une musique cohérente avec un modèle de langage en une seule étape grâce à une stratégie efficace d'entrelacement de livres de codes
- propose un modèle unique pour la génération conditionnelle du texte et de la mélodie, qui génère l'audio généré ; est cohérent avec la mélodie fournie et est conforme aux informations sur la condition du texte
- Une évaluation objective et manuelle approfondie des choix de conception clés de l'approche proposée a été réalisée.
Présentation de la méthode
MUSICGEN contient un décodeur basé sur un transformateur autorégressif et est conditionné par une représentation de texte ou de mélodie. Le modèle (de langage) est basé sur l'unité de quantification du tokenizer audio EnCodec, qui fournit une reconstruction haute fidélité à partir de représentations discrètes à faible trame. De plus, les modèles de compression déployant la quantification vectorielle résiduelle (RVQ) généreront plusieurs flux parallèles. Dans ce contexte, chaque flux est constitué de jetons discrets provenant de différents livres de codes appris.
Des travaux antérieurs ont proposé quelques stratégies de modélisation pour résoudre ce problème. Les chercheurs ont proposé un nouveau cadre de modélisation qui peut être généralisé à divers modes d'entrelacement de livres de codes. Il existe également plusieurs variantes de ce cadre. Basés sur des modèles, ils peuvent tirer parti de la structure interne des jetons audio quantifiés. Enfin MUSICGEN prend en charge la génération conditionnelle basée sur le texte ou la mélodie.
Audio tokenization
Le chercheur a utilisé EnCodec, qui est A auto-encodeur convolutif avec espace latent et perte de reconstruction contradictoire utilisant la quantification RVQ. Étant donné une variable aléatoire audio de référence X ∈ R^d·f_s, où d représente la durée audio et f_s représente la fréquence d'échantillonnage. EnCodec code cette variable dans un tenseur continu avec une fréquence d'images f_r ≪ f_s, puis la représentation est quantifiée comme Q ∈ {1, , N}^K×d・f_r, où K représente le livre de codes utilisé dans RVQ Quantity,. N représente la taille du livre de codes.
Codebook mode entrelacé
Décomposition autorégressive aplatie exacte. Le modèle autorégressif nécessite une séquence aléatoire discrète U ∈ {1, , N}^S et une longueur de séquence S. Par convention, les chercheurs utiliseront U_0 = 0, qui est un jeton spécial déterministe qui représente le début de la séquence. Ils peuvent ensuite modéliser la distribution.
Décomposition autorégressive inexacte. Une autre possibilité consiste à envisager une décomposition autorégressive, dans laquelle certains manuels de codage nécessitent des prédictions parallèles. Par exemple, définissez une autre séquence, V_0 = 0, et t∈ {1, , N}, k ∈ {1, , K . Lorsque l'index du livre de codes k est supprimé (par exemple V_t), cela représente la concaténation de tous les livres de codes au temps t.
Tout mode d'entrelacement de livre de codes. Pour expérimenter de telles décompositions et mesurer avec précision l’impact de l’utilisation de décompositions imprécises, les chercheurs ont introduit un mode d’entrelacement de manuels de codes. Considérons d'abord Ω = {(t, k) : {1, . Le modèle de livre de codes est la séquence P=(P_0, P_1, P_2, . . . , P_S), où P_0 = ∅, et 0
Conditionalisation du modèle
Conditionalisation du texte. Étant donné une description textuelle correspondant à un audio d'entrée
Mélodie conditionnée. Alors que le texte constitue aujourd’hui l’approche dominante des modèles génératifs conditionnels, une approche plus naturelle de la musique consiste à conditionner la structure mélodique d’une autre piste audio ou même d’un sifflement ou d’un bourdonnement. Cette approche permet également une optimisation itérative des sorties du modèle. Pour soutenir cela, nous avons tenté de contrôler la structure mélodique en modulant conjointement le chromatogramme d'entrée et la description textuelle. Lors des premières expériences, ils ont observé que le conditionnement sur le chromatogramme original reconstruisait souvent l'échantillon original, conduisant à un surajustement. À cette fin, les chercheurs sélectionnent les principales tranches temps-fréquence à chaque pas de temps afin d’introduire des goulots d’étranglement en matière d’informations.
Architecture du modèle
Projection de codebook et intégration de position. Étant donné un modèle de livre de codes, seuls quelques livres de codes existent dans chaque étape de modèle P_s. Le chercheur récupère la valeur de Q correspondant à l'index dans P_s. Chaque livre de codes apparaît dans P_s au plus une fois ou pas du tout.
Décodeur transformateur. L'entrée est introduite dans un transformateur avec des couches L et des dimensions D, chaque couche étant constituée d'un bloc causal d'auto-attention. Un bloc d’attention croisée est alors utilisé, qui est fourni par le signal de conditionnement C. Lorsqu’il utilise le conditionnement mélodique, le chercheur préfixe le tenseur conditionnel C à l’entrée du transformateur.
Logits prédictions. Au pas de modèle P_s, la sortie du décodeur de transformateur est convertie en une prédiction logits des valeurs Q. Chaque livre de codes apparaît au plus une fois dans P_s+1. Si le livre de codes existe, une couche linéaire spécifique au livre de codes est appliquée du canal D à N pour obtenir la prédiction logits.
Résultats expérimentaux
Modèle de tokenisation audio. L'étude utilise un modèle EnCodec non causal à cinq couches pour un son mono de 32 kHz avec une foulée de 640, une fréquence d'images de 50 Hz et une taille cachée initiale de 64 qui est doublée dans chacune des cinq couches du modèle.
Modèle de transformateur, L'étude a formé des modèles de transformateur autorégressifs de différentes tailles : paramètres 300M, 1,5B, 3,3B.
Ensemble de données d'entraînement. Étudiez en utilisant 20 000 heures de musique sous licence pour former MUSICGEN. Dans le détail, l'étude a utilisé un ensemble de données internes contenant 10 000 pistes de haute qualité, ainsi que les ensembles de données musicales ShutterStock et Pond5 contenant respectivement 25 000 et 365 000 pistes uniquement instrumentales.
Ensemble de données d'évaluation. L'étude évalue la méthode proposée sur le benchmark MusicCaps et la compare aux travaux antérieurs. Les MusicCaps sont composés de 5,5 000 échantillons (d'une durée de 10 secondes) préparés par des musiciens experts et de 1 000 sous-ensembles répartis entre les genres.
Le tableau 1 ci-dessous donne la comparaison de la méthode proposée avec Mousai, Riffusion, MusicLM et Noise2Music. Les résultats montrent que MUSICGEN surpasse les références évaluées par des auditeurs humains en termes de qualité audio et de cohérence avec la description textuelle fournie. Noise2Music fonctionne mieux sur FAD sur MusicCaps, suivi de MUSICGEN formé avec des conditions de texte. Il est intéressant de noter que l’ajout de la condition mélodique a dégradé les mesures objectives, mais n’a pas affecté de manière significative les notes humaines et était toujours meilleur que la référence évaluée.
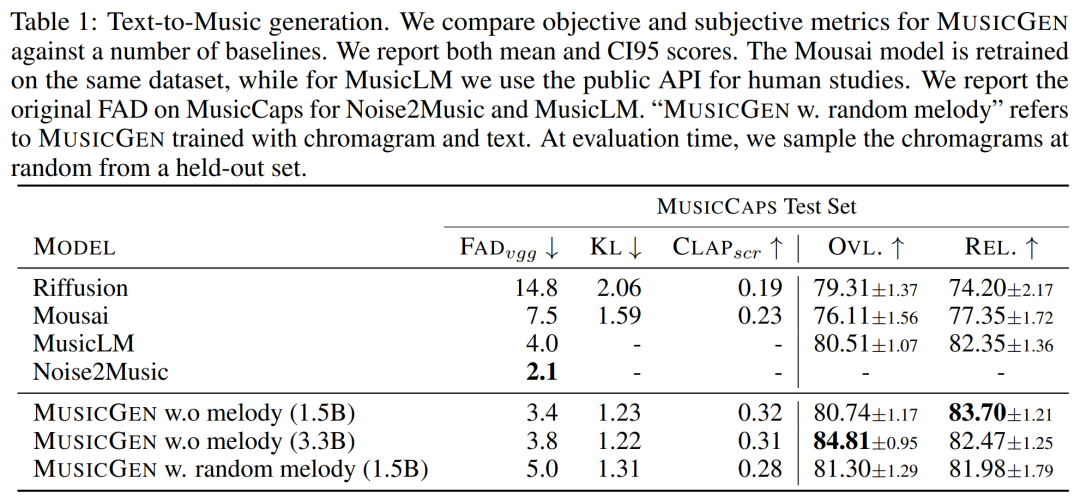
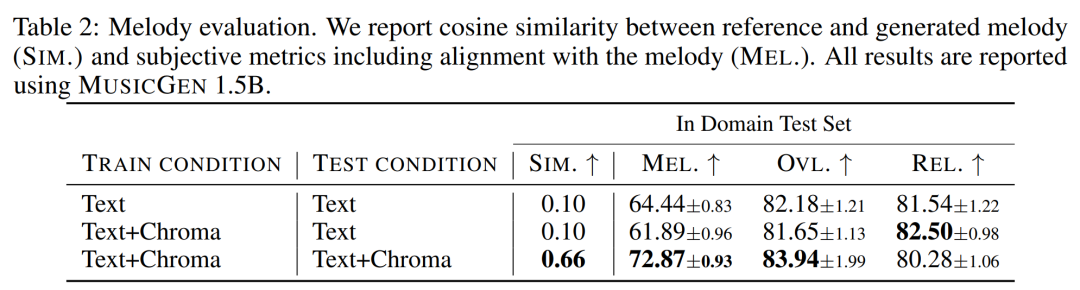
Le chercheur donne l'objectif d'utilisation et des métriques subjectives sur l'ensemble d'évaluation, MUSICGEN est évalué dans les conditions courantes de représentation du texte et de la mélodie. Les résultats sont présentés dans le tableau 2 ci-dessous. Les résultats montrent que MUSICGEN entraîné avec la conditionnalisation des chromatogrammes génère avec succès une musique qui suit une mélodie donnée, permettant un meilleur contrôle sur la sortie générée. MUSICGEN est robuste à la suppression de la chrominance au moment de l'inférence à l'aide d'OVL et REL.
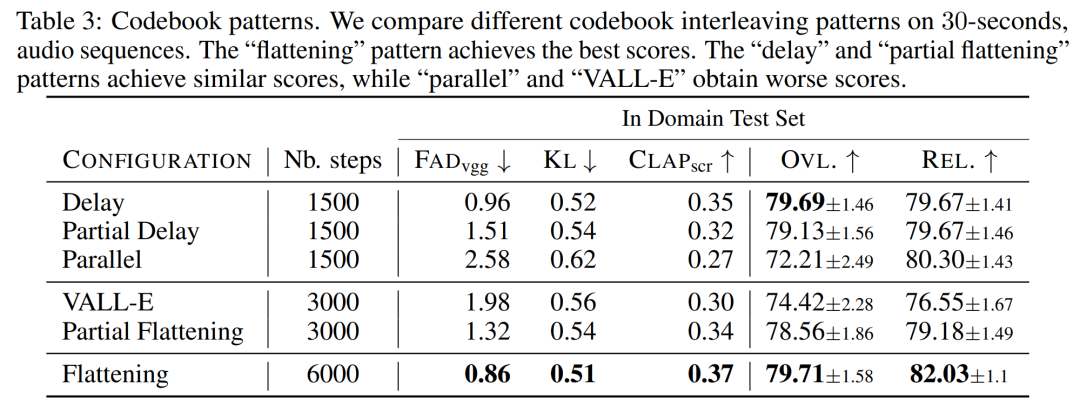
L'impact du mode d'entrelacement du livre de codes . Nous avons évalué divers modèles de livre de codes en utilisant le cadre de la section 2.2, K = 4, donné par le modèle de tokenisation audio. Cet article rapporte des évaluations objectives et subjectives dans le tableau 3 ci-dessous. Bien que l’aplatissement améliore la génération, il est coûteux en calcul. Des performances similaires peuvent être obtenues à une fraction du coût en utilisant de simples méthodes de report. Influence de la taille du modèle. Le tableau 4 ci-dessous présente les résultats pour différentes tailles de modèles, à savoir les modèles paramétriques 300M, 1,5B et 3,3B. Comme prévu, l’augmentation de la taille du modèle entraîne de meilleurs scores, mais uniquement au prix de temps de formation et d’inférence plus longs. En termes d'évaluation subjective, la qualité globale est optimale à 1,5B, mais les modèles plus grands peuvent mieux comprendre les invites textuelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI