
Maison >Périphériques technologiques >IA >Hinton, 75 ans, a prononcé son dernier discours lors de la conférence chinoise « Deux voies vers le renseignement » et a conclu avec émotion : Je suis déjà vieux et l'avenir est laissé aux jeunes.
Hinton, 75 ans, a prononcé son dernier discours lors de la conférence chinoise « Deux voies vers le renseignement » et a conclu avec émotion : Je suis déjà vieux et l'avenir est laissé aux jeunes.

- 王林avant
- 2023-06-13 19:13:551468parcourir
"Mais je suis vieux et tout ce que je veux, c'est que de jeunes chercheurs prometteurs comme vous découvrent comment nous pouvons avoir ces super intelligences pour améliorer nos vies, plutôt que d'être contrôlés par elles."
Le 10 juin, dans le discours de clôture de la Conférence Zhiyuan de Pékin 2023, en parlant de la manière de prévenir la tromperie des super-intelligences, En parlant du sujet du contrôle des êtres humains , a déclaré avec émotion Geoffrey Hinton, lauréat du prix Turing cette année, âgé de 75 ans.
Le discours de Hinton est intitulé « Deux voies vers l'intelligence » Deux voies vers l'intelligence , à savoir l'informatique immortelle réalisée sous forme numérique et l'informatique immortelle reposant sur du matériel, représentées respectivement par des ordinateurs numériques et des cerveaux humains. À la fin de son discours, il s'est concentré sur les inquiétudes concernant la menace de superintelligence que lui apportaient les grands modèles de langage (LLM). Sur ce sujet impliquant l'avenir de la civilisation humaine, il a très clairement montré son attitude pessimiste.
Au début de son discours, Hinton a déclaré que la superintelligence pourrait naître beaucoup plus tôt qu'il ne le pensait. Cette observation soulève deux questions majeures : (1) Le niveau d’intelligence des réseaux de neurones artificiels dépassera-t-il bientôt celui des réseaux de neurones réels ? (2) Les humains peuvent-ils garantir le contrôle de la super IA ? Dans son discours à la conférence, il a discuté en détail de la première question ; concernant la deuxième question, Hinton a déclaré à la fin de son discours : La superintelligence pourrait bientôt arriver.

Tout d'abord, regardons la méthode de calcul traditionnelle. Le principe de conception des ordinateurs est de pouvoir exécuter des instructions avec précision, ce qui signifie que si nous exécutons le même programme (qu'il s'agisse d'un réseau neuronal ou non) sur un matériel différent, l'effet devrait être le même. Cela signifie que les connaissances contenues dans le programme (comme les poids d'un réseau neuronal) sont immortelles et n'ont rien à voir avec le matériel spécifique.

Pour atteindre l'immortalité de la connaissance, notre approche est de courir au plus haut transistors de puissance, leur permettant de fonctionner de manière numérique de manière fiable. Mais ce faisant, nous équivalons à abandonner certaines autres propriétés du matériel, telles que la richesse analogique et la grande variabilité.

La raison pour laquelle les ordinateurs traditionnels adoptent ce modèle de conception est que l'informatique traditionnelle les programmes qui s'exécutent sont tous écrits par des humains. Aujourd’hui, avec le développement de la technologie d’apprentissage automatique, les ordinateurs disposent d’un autre moyen d’atteindre les objectifs des programmes et des tâches : l’apprentissage basé sur des échantillons.
Ce nouveau paradigme nous permet d'abandonner l'un des principes les plus fondamentaux de la conception de systèmes informatiques précédents, à savoir la séparation de la conception logicielle et du matériel ; collaborer avec la conception de logiciels et de matériel.
L'avantage de la conception séparée du logiciel et du matériel est que le même programme peut fonctionner sur de nombreux matériels différents en même temps, lors de la conception du programme, nous ne pouvons que regarder. au niveau du logiciel, quel que soit le matériel - — C'est aussi la raison pour laquelle le Département d'informatique et le Département de génie électronique peuvent être créés séparément.
Quant à la co-conception logicielle et matérielle, Hinton a proposé un nouveau concept : Mortal Computation. correspond à la forme immortelle de logiciel évoquée plus haut, que nous traduisons ici par « informatique immortelle ».
Qu'est-ce que le calcul mortel ?

Deadly Computing abandonne la possibilité d'exécuter le même logiciel sur un matériel différent L’immortalité, à son tour, embrasse une nouvelle mentalité de conception : la connaissance est indissociable des détails physiques spécifiques du matériel. Cette nouvelle idée a naturellement ses avantages et ses inconvénients. Les principaux avantages incluent les économies d'énergie et les faibles coûts de matériel.
En termes d'économie d'énergie, on peut se référer au cerveau humain, qui est un appareil informatique périssable typique. Bien qu'il existe encore des calculs numériques d'un bit dans le cerveau humain, c'est-à-dire que les neurones se déclenchent ou ne se déclenchent pas, dans l'ensemble, la grande majorité des calculs effectués dans le cerveau humain sont des calculs analogiques avec une très faible consommation d'énergie.
L'informatique immortelle peut également utiliser du matériel moins coûteux. Comparé aux processeurs d'aujourd'hui, qui sont produits avec une haute précision dans un modèle bidimensionnel, le matériel informatique immortel peut être « développé » dans un modèle tridimensionnel car nous n'avons pas besoin de savoir exactement comment le matériel est connecté et le fonction de chaque composant. Il est clair que pour parvenir à la « croissance » du matériel informatique, nous aurons besoin de nombreuses nouvelles nanotechnologies ou de la capacité de modifier génétiquement les neurones biologiques. Les méthodes d’ingénierie des neurones biologiques peuvent être plus faciles à mettre en œuvre car nous savons déjà que les neurones biologiques peuvent à peu près faire ce que nous voulons.
Pour démontrer les capacités efficaces des calculs de simulation, Hinton a donné un exemple : calculer le produit d'un vecteur d'activité neuronale et d'une matrice de poids (la plupart des travaux sur les réseaux de neurones c'est ce type de calcul).

Pour cette tâche, le ordinateur Cela se fait en utilisant des transistors haute puissance pour représenter la valeur sous forme de bits numériques, puis en effectuant des opérations numériques O (n²) pour multiplier les deux valeurs de n bits. Bien qu’il ne s’agisse que d’une seule opération sur l’ordinateur, il s’agit d’une opération sur n² bits.
Et si on utilisait des calculs de simulation ? Nous pouvons considérer l'activité neuronale comme une tension et le poids comme une conductance ; alors, dans chaque unité de temps, la tension multipliée par la conductance peut obtenir la charge, et les charges peuvent être superposées. L’efficacité énergétique de cette façon de travailler sera bien plus élevée et, en fait, des puces fonctionnant de cette manière existent déjà. Malheureusement, a déclaré Hinton, les gens doivent encore utiliser des convertisseurs très coûteux pour convertir les résultats analogiques sous forme numérique. Il espère qu'à l'avenir, nous pourrons mener à bien l'ensemble du processus de calcul dans le domaine de la simulation.
Les calculs mortels se heurtent également à certains problèmes, dont le plus important est qu'il est difficile d'assurer la cohérence des résultats, c'est-à-dire que les résultats des calculs sur différents matériels peuvent être différent. De plus, nous devons trouver de nouvelles méthodes lorsque la rétropropagation n’est pas disponible.
Problèmes rencontrés par l'informatique corruptible : la rétropropagation n'est pas disponible
Elle est requise lors de l'apprentissage de l'informatique corruptible sur du matériel spécifique. Laisser les programmes apprendre à exploiter des propriétés de simulation spécifiques de ce matériel, mais ils n'ont pas besoin de savoir quelles sont ces propriétés. Par exemple, ils n’ont pas besoin de savoir comment un neurone est connecté en interne, ni quelle fonction relie l’entrée et la sortie du neurone. Cela signifie que nous ne pouvons pas utiliser l'algorithme de rétropropagation pour obtenir les gradients, car la rétropropagation nécessite un modèle de propagation vers l'avant exact.
Donc, puisque la rétropropagation ne peut pas être utilisée dans les calculs décroissants, que devons-nous faire ? Examinons un processus d'apprentissage simple effectué sur du matériel simulé à l'aide d'une méthode appelée perturbation du poids. 
Tout d'abord, générez un vecteur aléatoire composé de petites perturbations aléatoires pour chaque poids du réseau. Ensuite, sur la base d'un ou d'un petit nombre d'échantillons, le changement de la fonction objectif globale après utilisation de ce vecteur de perturbation est mesuré. Enfin, selon l'amélioration de la fonction objectif, l'effet apporté par le vecteur perturbation est en permanence proportionné au poids.
L'avantage de cet algorithme est que son modèle de comportement général est cohérent avec la rétropropagation et qu'il suit également les gradients. Mais le problème est que la variance est très élevée. Par conséquent, lorsque la taille du réseau augmente, le bruit généré lors de la sélection de directions de mouvement aléatoires dans l’espace de poids sera important, rendant cette méthode non durable. Cela signifie que cette méthode ne convient qu'aux petits réseaux et non aux grands réseaux.

Une autre approche est la perturbation d'activité, qui pose des problèmes similaires mais fonctionne également mieux pour les réseaux plus grands.

La méthode de perturbation de l'activité consiste à utiliser un vecteur aléatoire pour perturber l'entrée globale de chaque neurone, puis à observer les changements dans la fonction objectif dans un petit lot d'échantillons, puis à calculer comment pour modifier le poids des neurones des éléments afin de suivre le gradient.
Les perturbations d'activité sont beaucoup moins bruyantes que les perturbations de poids. Et cette méthode est suffisante pour apprendre des tâches simples comme MNIST. Si vous utilisez un très faible taux d’apprentissage, cela se comporte exactement comme une rétropropagation, mais beaucoup plus lentement. Si le taux d'apprentissage est élevé, il y aura beaucoup de bruit, mais c'est suffisant pour gérer des tâches comme MNIST.
Mais et si l'échelle de notre réseau était encore plus grande ? Hinton a mentionné deux approches.
La première méthode consiste à utiliser un grand nombre de fonctions objectives, ce qui signifie qu'au lieu d'utiliser une seule fonction pour définir l'objectif d'un grand réseau neuronal, un grand nombre de fonctions sont utilisées pour définir les objectifs locaux de différents groupes de neurones dans le réseau.

De cette façon, les grands réseaux de neurones sont décomposés en parties, et nous pouvons utiliser les perturbations d'activité pour apprendre de petits réseaux de neurones multicouches. Mais voici la question : d’où viennent ces fonctions objectives ?

Une possibilité est d'utiliser l'apprentissage contrastif non supervisé sur des patchs locaux à différents niveaux. Cela fonctionne comme ceci : un patch local a plusieurs niveaux de représentation, et à chaque niveau, le patch local essaie d'être cohérent avec la représentation moyenne produite par tous les autres patchs locaux de la même image en même temps, il essaie également de l'être ; différent des autres images à ce niveau.
Hinton dit que la méthode fonctionne bien dans la pratique. L'approche générale consiste à disposer de plusieurs couches cachées pour chaque niveau de représentation, afin de pouvoir effectuer des opérations non linéaires. Ces niveaux utilisent des perturbations d'activité pour un apprentissage gourmand et ne se propagent pas aux niveaux inférieurs. Puisqu’elle ne peut pas passer autant de couches que la rétropropagation, elle ne sera pas aussi puissante que la rétropropagation.
En fait, il s'agit de l'un des résultats de recherche les plus importants de l'équipe Hinton ces dernières années. Pour plus de détails, veuillez vous référer au rapport Machine Heart « Après avoir abandonné la rétropropagation, la recherche à succès sur l'apprentissage par gradient avant impliquant Geoffrey Hinton est arrivée. 》.

Mengye Ren a montré grâce à des recherches approfondies que cette méthode peut réellement être efficace dans les réseaux de neurones, mais l'opération est très compliquée et l'effet réel ne peut pas suivre la rétropropagation. Si la profondeur d’un grand réseau est plus profonde, l’écart avec la rétropropagation sera encore plus grand.
Hinton a déclaré que cet algorithme d'apprentissage qui peut tirer parti des propriétés de simulation ne peut être considéré que comme correct, suffisant pour gérer des tâches telles que MNIST, mais il n'est pas vraiment facile à utiliser, par exemple, les performances sur ImageNet. la tâche n'est pas très bonne.
Problèmes rencontrés par l'informatique périssable : l'héritage des connaissances
Un autre problème majeur rencontré par l'informatique périssable est qu'il est difficile d'assurer l'héritage des connaissances. L’informatique périssable étant fortement dépendante du matériel, les connaissances ne peuvent pas être copiées en copiant des poids, ce qui signifie que lorsqu’un élément matériel spécifique « meurt », les connaissances qu’il a acquises disparaissent avec lui.
Hinton a déclaré que la meilleure façon de résoudre ce problème est de transférer les connaissances aux étudiants avant que le matériel ne « meure ». Ce type de méthode est appelé distillation des connaissances, un concept proposé pour la première fois par Hinton dans l'article de 2015 « Distilling the Knowledge in a Neural Network » co-écrit avec Oriol Vinyals et Jeff Dean.

L'idée de base de ce concept est très simple et est similaire à celle d'un enseignant qui enseigne des connaissances aux élèves : l'enseignant montre aux élèves les réponses correctes aux différentes entrées, et les élèves essaient d'imiter les réponses de l'enseignant.
Hinton a utilisé l'exemple des tweets de l'ancien président américain Trump pour illustrer intuitivement : Trump réagit souvent de manière très émotionnelle à divers événements lorsqu'il tweete, ce qui incitera ses partisans à modifier son propre "réseau neuronal" pour produire la même réponse émotionnelle. De cette manière, Trump a distillé les préjugés dans l’esprit de ses partisans, tout comme Hinton n’aime clairement pas Trump.
Quelle est l'efficacité de la méthode de distillation des connaissances ? Compte tenu des nombreux partisans de Trump, l’effet ne devrait pas être mauvais. Hinton utilise un exemple pour expliquer : supposons qu'un agent doive classer les images en 1 024 catégories qui ne se chevauchent pas.

Pour identifier la bonne réponse, nous n'avons besoin que de 10 informations. Par conséquent, pour entraîner l’agent à identifier correctement un échantillon spécifique, seuls 10 bits d’informations doivent être fournis pour contraindre ses poids.
Mais et si on formait un agent pour qu'il ait à peu près les mêmes probabilités qu'un enseignant sur ces 1024 catégories ? Autrement dit, faites en sorte que la distribution de probabilité de l'agent soit la même que celle de l'enseignant. Cette distribution de probabilité comporte 1023 nombres réels, et si ces probabilités ne sont pas très petites, elle fournit des centaines de fois plus de contraintes.

Afin de garantir que ces probabilités ne soient pas trop faibles, les enseignants peuvent fonctionner à « haute température » et les étudiants peuvent également fonctionner à « haute température » lors de la formation des étudiants. Par exemple, si vous utilisez logit, c'est l'entrée de softmax. Pour les enseignants, ils peuvent l'adapter en fonction du paramètre de température pour obtenir une distribution plus douce, puis utiliser la même température lors de la formation des étudiants ;
Regardons un exemple spécifique. Vous trouverez ci-dessous quelques images du personnage 2 de l'ensemble d'entraînement MNIST, correspondant à droite sont les probabilités attribuées par l'enseignant à chaque image lorsque la température à laquelle l'enseignant fonctionne est élevée.
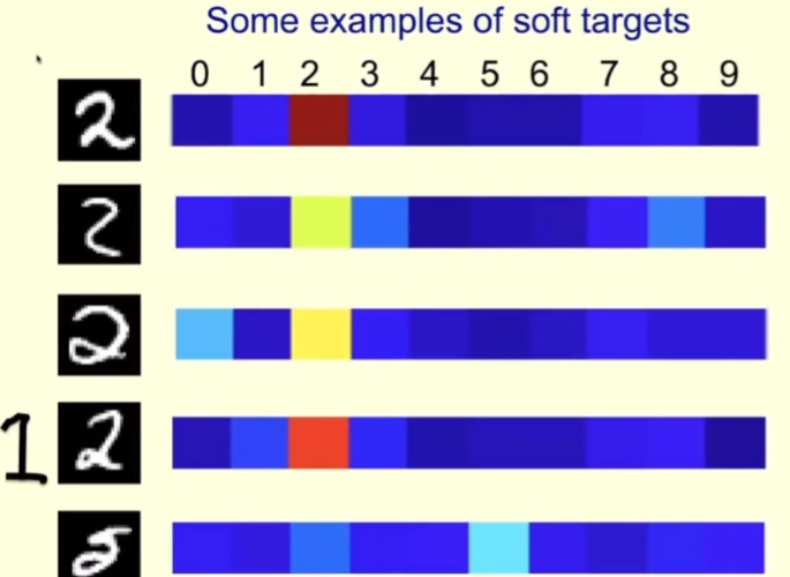
Pour la première rangée, l'enseignant est sûr que c'est un 2 ; l'enseignant est également sûr que la deuxième rangée est un 2, mais il pense aussi que ce pourrait être un 3 ou un 8. La troisième ligne ressemble un peu à 0. Pour cet échantillon, l’enseignant doit dire qu’il s’agit d’un 2, mais doit également laisser de la place pour 0. De cette façon, les élèves en apprendront davantage que si on leur disait directement que c'est 2.
Pour la quatrième ligne, vous pouvez voir que l'enseignant est sûr que c'est 2, mais il pense aussi qu'il est assez probable que ce soit 1, après tout, parfois le 1 que nous écrivons est similaire à celui dessiné sur le côté gauche de l'image.
Pour la cinquième rangée, le professeur s'est trompé et a pensé que c'était 5 (mais selon l'étiquette MNIST ça devrait être 2). Les étudiants peuvent également apprendre beaucoup des erreurs de leurs enseignants.
La distillation a une propriété très particulière, c'est-à-dire qu'en utilisant les probabilités données par l'enseignant pour entraîner les élèves, elle entraîne les élèves à généraliser de la même manière que l'enseignant. Si l’enseignant attribue une certaine faible probabilité à la mauvaise réponse, les élèves seront également entraînés à généraliser à la mauvaise réponse.

De manière générale, nous entraînons le modèle pour obtenir la bonne réponse sur les données d'entraînement et généralisons cette capacité aux données de test. Mais lorsqu'on utilise le modèle de formation enseignant-élève, on entraîne directement la capacité de généralisation de l'élève, car l'objectif de formation de l'élève est d'être capable de généraliser de la même manière que l'enseignant.
Évidemment, nous pouvons créer des résultats plus riches pour la distillation. Par exemple, nous pourrions attribuer à chaque image une description, plutôt qu’une simple étiquette, puis entraîner les étudiants à prédire les mots contenus dans ces descriptions.

Ensuite, Hinton a parlé de la recherche sur le partage des connaissances au sein de groupes d'agents. C'est aussi une manière de transmettre des connaissances.

Lorsqu'une communauté de plusieurs agents partage des connaissances entre eux, la manière dont les connaissances sont partagées peut largement déterminer la manière dont les calculs sont effectués.

Pour les modèles numériques, nous pouvons créer un grand nombre d'agents en utilisant les mêmes poids grâce à la réplication. Nous pouvons demander à ces agents d'examiner différentes parties de l'ensemble de données d'entraînement, de calculer chacun le gradient des poids en fonction de différentes parties des données, puis de faire la moyenne de ces gradients. De cette façon, chaque modèle apprend ce que tous les autres modèles ont appris. L'avantage de cette stratégie de formation est qu'elle peut gérer efficacement de grandes quantités de données ; si le modèle est volumineux, un grand nombre de bits peuvent être partagés dans chaque partage.
En même temps, puisque cette méthode nécessite que chaque agent travaille exactement de la même manière, il ne peut s'agir que d'une maquette numérique.
Le coût du partage de poids est également très élevé. Faire fonctionner différents éléments matériels de la même manière nécessite de produire des ordinateurs avec une telle précision qu’ils obtiennent toujours les mêmes résultats lorsqu’ils exécutent les mêmes instructions. De plus, la consommation électrique des transistors n’est pas faible.

La distillation peut également remplacer le partage du poids. Surtout lorsque votre modèle utilise les propriétés simulées d'un matériel spécifique, vous ne pouvez pas utiliser le partage de poids, mais devez utiliser la distillation pour partager les connaissances.

Le partage de connaissances par distillation n'est pas efficace et la bande passante est très faible. Tout comme à l'école, les enseignants veulent transmettre les connaissances qu'ils connaissent dans la tête des élèves, mais c'est impossible car nous sommes une intelligence biologique et votre poids ne m'est d'aucune utilité.

Résumons ici brièvement deux manières complètement différentes d'effectuer des calculs (calculs numériques et calculs biologiques) sont évoquées ci-dessus, et les manières de partager les connaissances entre agents sont également très différentes.
Alors quelle est la forme de modèle linguistique à grande échelle (LLM) qui se développe actuellement ? Ce sont des calculs numériques qui peuvent utiliser le partage de poids.

Mais chaque agent réplique de LLM ne peut apprendre les connaissances contenues dans le document que d'une manière de distillation très inefficace. Ce que fait LLM, c'est prédire le mot suivant du document, mais il n'y a pas de distribution de probabilité du mot suivant par l'enseignant. Il n'y a qu'une sélection aléatoire, c'est-à-dire le mot choisi par l'auteur du document au mot suivant. position. LLM apprend en fait de nous, les humains, mais la bande passante nécessaire pour transférer les connaissances est très faible.
Encore une fois, bien que l'efficacité de chaque copie de l'apprentissage LLM par distillation soit très faible, il y en a beaucoup, jusqu'à des milliers, donc ils peuvent apprendre des milliers de fois plus que nous. Ce qui signifie que le LLM actuel est plus compétent que n'importe lequel d'entre nous.
La super intelligence mettra-t-elle fin à la civilisation humaine ?
Ensuite, Hinton a posé une question : "Que se passe-t-il si ces intelligences numériques n'apprennent pas de nous très lentement par distillation, mais commencent à apprendre directement du monde réel ?"

En fait , LLM apprend déjà les connaissances accumulées par les humains depuis des milliers d'années lors de l'apprentissage de documents. Parce que les humains décrivent notre compréhension du monde à travers le langage, l’intelligence numérique peut acquérir directement les connaissances accumulées par les humains grâce à l’apprentissage de textes. Même si la distillation est lente, ils acquièrent des connaissances très abstraites.
Et si l’intelligence numérique pouvait réaliser un apprentissage non supervisé grâce à la modélisation d’images et de vidéos ? Il existe désormais une énorme quantité de données d’imagerie disponibles sur Internet et, à l’avenir, nous pourrons peut-être trouver des moyens permettant à l’IA d’apprendre efficacement à partir de ces données. De plus, si l’IA dispose de méthodes telles que des bras robotiques capables de manipuler la réalité, elle peut les aider davantage à apprendre.
Hinton pense que si les agents numériques peuvent faire cela, leur capacité d'apprentissage sera bien meilleure que celle des humains et leur vitesse d'apprentissage sera très rapide.
Revenons maintenant à la question soulevée par Hinton au début : si l’intelligence de l’IA dépasse la nôtre, pouvons-nous toujours les contrôler ?
Hinton a déclaré qu'il avait prononcé ce discours principalement pour exprimer ses inquiétudes. "Je pense que la superintelligence pourrait émerger beaucoup plus tôt que je ne le pensais auparavant", a-t-il déclaré. Il a donné plusieurs moyens possibles pour la superintelligence de contrôler les humains.

Par exemple, de mauvais acteurs peuvent utiliser la superintelligence pour manipuler les élections ou gagner des guerres (quelqu'un fait déjà ces choses avec l'IA existante).
Dans ce cas, si vous souhaitez que la superintelligence soit plus efficace, vous pouvez lui permettre de créer elle-même des sous-objectifs. Contrôler davantage de pouvoir est un sous-objectif évident. Après tout, plus le pouvoir et les ressources qu’il contrôle sont importants, plus il peut aider l’agent à atteindre son objectif ultime. La superintelligence pourrait alors découvrir qu’elle peut facilement acquérir plus de pouvoir en manipulant ceux qui l’exercent.
Il est difficile pour nous d’imaginer des êtres plus intelligents que nous et la manière dont nous interagissons avec eux. Mais Hinton pense qu’une superintelligence plus intelligente que nous pourrait certainement apprendre à tromper les humains, qui ont tant de romans et de littérature politique à exploiter.
Une fois que la super intelligence apprend à tromper les humains, elle peut amener les humains à adopter les comportements qu'ils souhaitent. Il n’y a en fait aucune différence essentielle entre cela et tromper les autres. Par exemple, a déclaré Hinton, si quelqu'un veut pirater un bâtiment à Washington, il n'est pas obligé de s'y rendre, il lui suffit de faire croire aux gens qu'il pirate le bâtiment pour sauver la démocratie.
"Je pense que c'est très effrayant." Le pessimisme de Hinton est palpable. "Maintenant, je ne vois pas comment empêcher que cela se produise, mais je suis vieux. Il espère que les jeunes talents pourront trouver des moyens de réussir." La super Intelligence aide les humains à vivre une vie meilleure au lieu de les laisser tomber sous leur contrôle.
Mais il a également dit que nous avons un avantage, quoique plutôt petit, dans la mesure où l'IA n'a pas évolué mais a été créée par les humains. De cette façon, l’IA n’a pas la même compétitivité et les mêmes objectifs que les humains d’origine. Peut-être pourrions-nous définir des principes moraux et éthiques pour l’IA lors du processus de création.
Cependant, s'il s'agit d'une super intelligence dont le niveau d'intelligence dépasse de loin celui des humains, cela pourrait ne pas être efficace. Hinton dit qu'il n'a jamais vu de cas où quelque chose d'un niveau d'intelligence supérieur était contrôlé par quelque chose d'un niveau d'intelligence bien inférieur. Disons que si les grenouilles ont créé les humains, qui contrôle qui entre les grenouilles et les humains maintenant ?
Finalement, Hinton a publié avec pessimisme la dernière diapositive de ce discours :

Cela marque non seulement la fin du discours, mais sert également d'avertissement à toute l'humanité : la superintelligence peut conduire à l'humanité. La fin de la civilisation.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI