
Maison >Périphériques technologiques >IA >2,8 millions de paires commande-réponse multimodales, communes en huit langues, le premier ensemble de données de commande couvrant le contenu vidéo MIMIC-IT est là
2,8 millions de paires commande-réponse multimodales, communes en huit langues, le premier ensemble de données de commande couvrant le contenu vidéo MIMIC-IT est là

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-13 10:34:271430parcourir
Ces derniers temps, les assistants de dialogue IA ont fait des progrès considérables dans les tâches linguistiques. Cette amélioration significative ne repose pas seulement sur la forte capacité de généralisation du LLM, mais doit également être attribuée au réglage des instructions. Cela implique d'affiner le LLM sur une gamme de tâches grâce à un enseignement diversifié et de haute qualité.
L'une des raisons potentielles pour atteindre des performances nulles avec le réglage des instructions est qu'il internalise le contexte. Ceci est particulièrement important lorsque la saisie de l'utilisateur ignore le contexte du bon sens. En intégrant le réglage des instructions, LLM acquiert un haut niveau de compréhension de l'intention de l'utilisateur et présente de meilleures capacités de tir zéro, même dans des tâches inédites.
Cependant, un assistant conversationnel IA idéal devrait être capable de résoudre des tâches impliquant plusieurs modalités. Cela nécessite l’obtention d’un ensemble de données de suivi d’instructions multimodales diversifiées et de haute qualité. Par exemple, l'ensemble de données LLaVAInstruct-150K (également connu sous le nom de LLaVA) est un ensemble de données de suivi d'instructions visuo-verbales couramment utilisé, qui utilise des images COCO, des instructions et des réponses basées sur des légendes d'images et des cadres de délimitation cibles obtenus à partir de GPT-4 Constructed. Cependant, LLaVA-Instruct-150K présente trois limites : une diversité visuelle limitée ; l'utilisation d'images comme données visuelles uniques et d'informations contextuelles contenant uniquement la morphologie du langage ;
Afin de promouvoir les assistants de dialogue IA pour briser ces limitations, des chercheurs de l'Université technologique de Nanyang à Singapour et de Microsoft Research Redmond ont proposé l'ensemble de données de réglage des instructions contextuelles multimodales MIMIC-IT, qui contient 2,8 millions d'éléments contextuels multimodaux. instructions - un ensemble de données de paires correspondantes couvrant une variété de scénarios réels.

Adresse papier : https://arxiv.org/pdf/2306.05425.pdf
De plus, afin de générer efficacement des paires commande-réponse, le chercheur a également introduit "Sythus " , une instruction inspirée de la méthode d'auto-instruction - un pipeline automatisé qui répond aux commentaires. Sythus utilise des informations système, des annotations visuelles et des exemples en contexte pour guider un modèle de langage (GPT-4 ou ChatGPT) afin de générer des paires commande-réponse basées sur le contexte visuel, ciblant les trois capacités fondamentales des modèles de langage visuel : la perception, le raisonnement et planification. De plus, les commandes et réponses en anglais sont traduites en sept langues pour prendre en charge une utilisation multilingue.
Il convient particulièrement de noter que les chercheurs ont formé le modèle multimodal "Otter" basé sur OpenFlamingo sur MIMIC-IT. Évaluées à la fois sur ChatGPT et sur les humains, les capacités multimodales d'Otter surpassent les autres modèles de langage visuel récents.
Dans une série de démos, les chercheurs ont démontré les capacités de questions et réponses multimodales d'Otter :
Q : Quelle carte sera jouée ensuite ?
A : Huit tubes. De cette façon, vous pouvez garder les quatre et les cinq en attendant une quinte.

Q : Je veux atterrir, que dois-je faire ?
A : Appuyez une fois sur le bouton inférieur gauche pour tourner à gauche, et lorsque vous souhaitez atterrir, tirez le frein à main à droite.

Q : Et ensuite ?
A : Passez le ballon au centre, courez vers le but et cherchez les opportunités de marquer.

Ensuite, regardons les détails de l'étude.
Ensemble de données MIMIC-IT
L'ensemble de données MIMIC-IT comprend 2,8 millions de paires instruction-réponse multimodales couvrant les capacités de base : perception, raisonnement et planification. Chaque instruction est accompagnée d'un contexte conversationnel multimodal, permettant à VLM formé sur MIMIC-IT de démontrer une bonne maîtrise des instructions interactives et d'effectuer une généralisation sans tir.
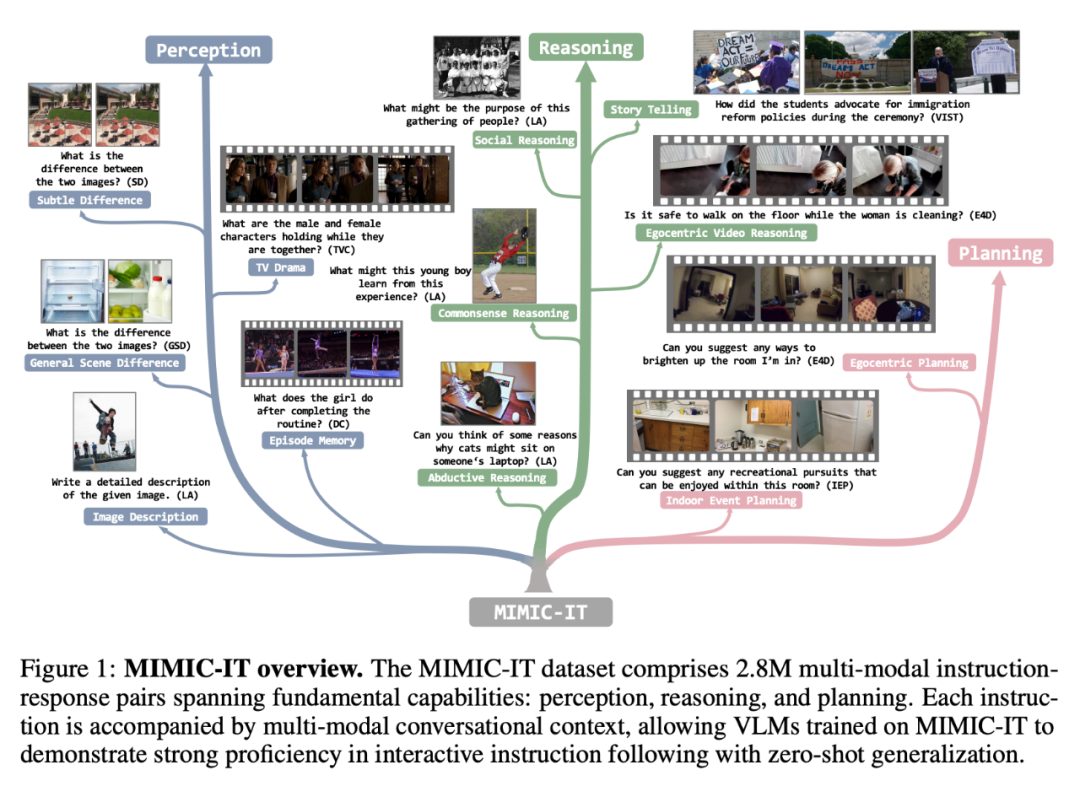
Par rapport à LLaVA, les fonctionnalités de MIMIC-IT incluent :
(1) Diverses scènes visuelles, y compris des scènes générales, des scènes de perspective égocentriques et des images RVB-D intérieures, etc. Images et des vidéos provenant de différents ensembles de données ;
(2) Plusieurs images (ou une vidéo) comme données visuelles ;
(3) Informations contextuelles multimodales, y compris plusieurs paires instruction-réponse et plusieurs images ou vidéos ;
(4) prend en charge huit langues, dont l'anglais, le chinois, l'espagnol, le japonais, le français, l'allemand, le coréen et l'arabe.La figure suivante montre en outre la comparaison commande-réponse des deux (la case jaune est LLaVA) :

Sythus : pipeline automatisé de génération de paires commande-réponse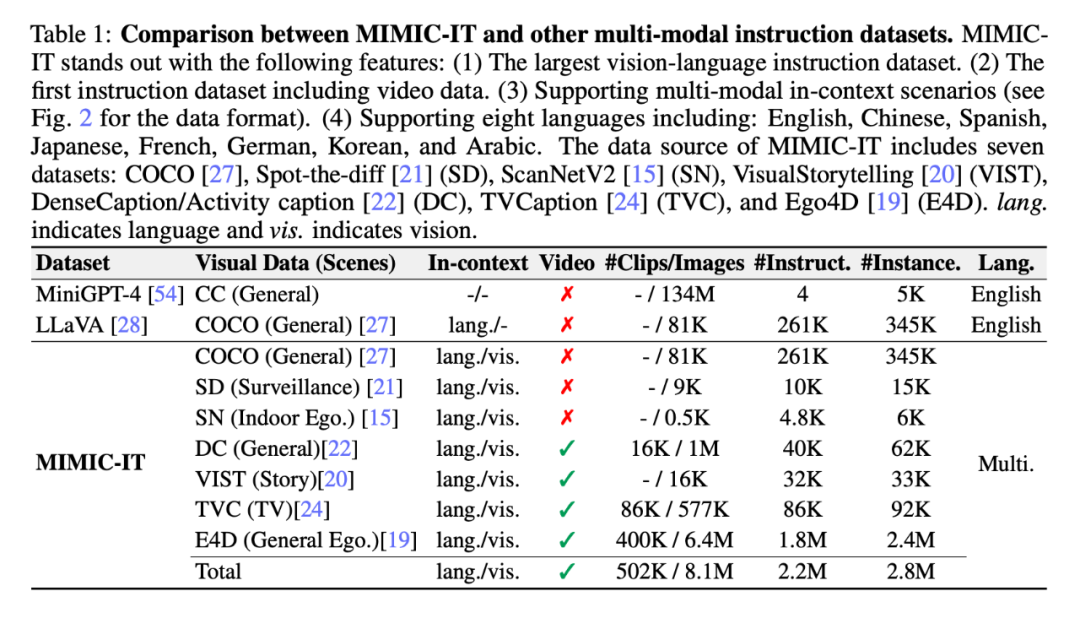
Étant donné que la qualité de l'ensemble de base affectera le processus ultérieur de collecte de données, les chercheurs ont adopté une stratégie de démarrage à froid pour renforcer les échantillons dans leur contexte avant d'effectuer des requêtes à grande échelle. Pendant la phase de démarrage à froid, une approche heuristique est adoptée pour inciter ChatGPT à collecter des échantillons en contexte uniquement via des informations système et des annotations visuelles. Cette phase ne se termine qu'après identification des échantillons dans un contexte satisfaisant. Dans la quatrième étape, une fois les paires commande-réponse obtenues, le pipeline les étend en chinois (zh), japonais (ja), espagnol (es), allemand (de), français (fr), coréen (ko) et arabe. (ar). De plus amples détails peuvent être trouvés à l'annexe C, et des invites de tâches spécifiques peuvent être trouvées à l'annexe D.
La figure 5 est un exemple de la réponse d’Otter dans différents scénarios. Grâce à la formation sur l'ensemble de données MIMIC-IT, Otter est capable de servir la compréhension et le raisonnement situationnels, l'apprentissage d'échantillons contextuels et les assistants visuels égocentriques. 
Enfin, les chercheurs ont mené une analyse comparative des performances d'Otter et d'autres VLM dans une série de tests de référence.
Évaluation ChatGPT
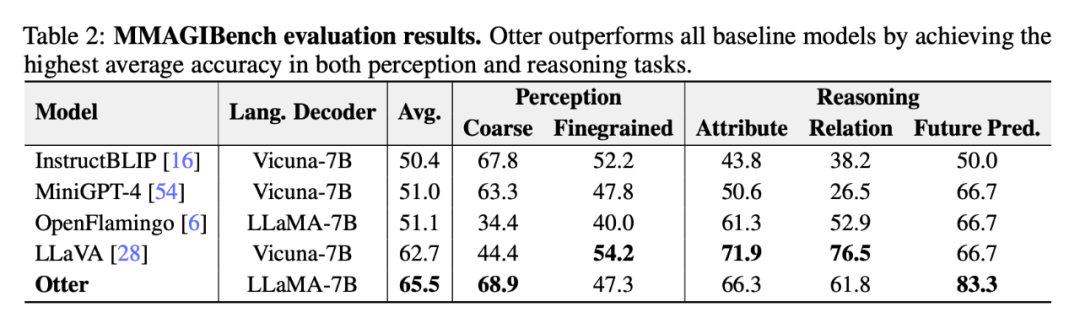
Le tableau 2 ci-dessous montre l'évaluation approfondie par les chercheurs des capacités de perception et de raisonnement des modèles de langage visuel à l'aide du cadre MMAGIBench [43].
Évaluation humaine
Multi-Modality Arena [32] utilise le système de notation Elo pour évaluer l'utilité et la cohérence des réponses VLM. La figure 6 (b) montre qu'Otter fait preuve d'une praticité et d'une cohérence supérieures, obtenant la note Elo la plus élevée dans les VLM récents.
Évaluation de référence d'apprentissage contextuel en quelques étapes
Otter est affiné sur OpenFlamingo, une architecture conçue pour l'apprentissage contextuel multimodal. Après un réglage fin à l'aide de l'ensemble de données MIMIC-IT, Otter surpasse considérablement OpenFlamingo lors de l'évaluation en quelques coups de COCO Captioning (CIDEr) [27] (voir Figure 6 (c)). Comme prévu, le réglage fin apporte également des gains de performances marginaux sur l'évaluation à échantillon nul.

Figure 6 : Évaluation de la compréhension de la vidéo ChatGPT.
Discutez des
défauts. Bien que les chercheurs aient amélioré de manière itérative les messages système et les exemples de réponses aux commandes, ChatGPT est sujet aux hallucinations linguistiques et peut donc générer des réponses erronées. Souvent, des modèles de langage plus fiables nécessitent une génération de données auto-instruite.
L'avenir du travail. À l’avenir, les chercheurs prévoient de prendre en charge des ensembles de données d’IA plus spécifiques, tels que LanguageTable et SayCan. Les chercheurs envisagent également d’utiliser des modèles de langage ou des techniques de génération plus fiables pour améliorer l’ensemble d’instructions.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI