
Maison >Périphériques technologiques >IA >Hinton, lauréat du Turing Award : Je suis vieux, je vous laisse le soin de contrôler une IA plus intelligente que les humains
Hinton, lauréat du Turing Award : Je suis vieux, je vous laisse le soin de contrôler une IA plus intelligente que les humains

- 王林avant
- 2023-06-12 19:39:47991parcourir
Vous souvenez-vous encore que les experts étaient divisés en deux camps sur « la question de savoir si l'IA peut exterminer l'humanité » ?
Comme il ne comprend pas pourquoi « l'IA va entraîner des risques », Ng Enda a récemment lancé une série de dialogues pour parler à deux lauréats du Turing Award :
#🎜 🎜Quels sont les risques de l’#IA ?

Musk était également très intéressé par cette conversation :
#🎜🎜 #In De plus, Hinton a également récemment « prêché » sur les risques de l'IA lors de la conférence de Zhiyuan, affirmant qu'une super intelligence plus intelligente que les humains apparaîtra bientôt :
Je ne vois pas comment empêcher la superintelligence de « devenir incontrôlable » maintenant, et je suis vieux. J'espère que davantage de jeunes chercheurs maîtriseront les méthodes de contrôle de la superintelligence.
Le premier est un dialogue avec Bengio. Ng et lui sont parvenus à un consensus clé, à savoir :Jetons un coup d'œil aux points essentiels de ces conversations et aux avis de différents experts en IA sur ce sujet.
Dialogue Ng Enda avec le lauréat du prix Turing : la sécurité de l'IA devrait parvenir à un consensus
Les scientifiques devraient essayer d’identifier « des scénarios spécifiques dans lesquels des risques liés à l’IA existent ».
En d'autres termes, dans quels scénarios l'IA causera des dommages majeurs aux humains, voire conduira à l'extinction de l'humanité, il s'agit d'un consensus auquel les deux parties doivent parvenir.Bengio estime que l'avenir de l'IA est plein de « brouillard et d'incertitude », il est donc nécessaire de découvrir certains scénarios spécifiques dans lesquels l'IA causera des dommages.
Ensuite, il y a eu la conversation avec Hinton, et les deux parties sont parvenues à deux consensus clés.
 D'une part, tous les scientifiques doivent avoir une bonne discussion sur la question des « risques de l'IA » afin de formuler de bonnes politiques
D'une part, tous les scientifiques doivent avoir une bonne discussion sur la question des « risques de l'IA » afin de formuler de bonnes politiques
Dans ce processus, Hinton a mentionné les points clés qui doivent être convenus, à savoir "GPT-4 et Bard Est-ce que ce genre de grands modèles conversationnels comprennent réellement ce qu'ils disent ? :
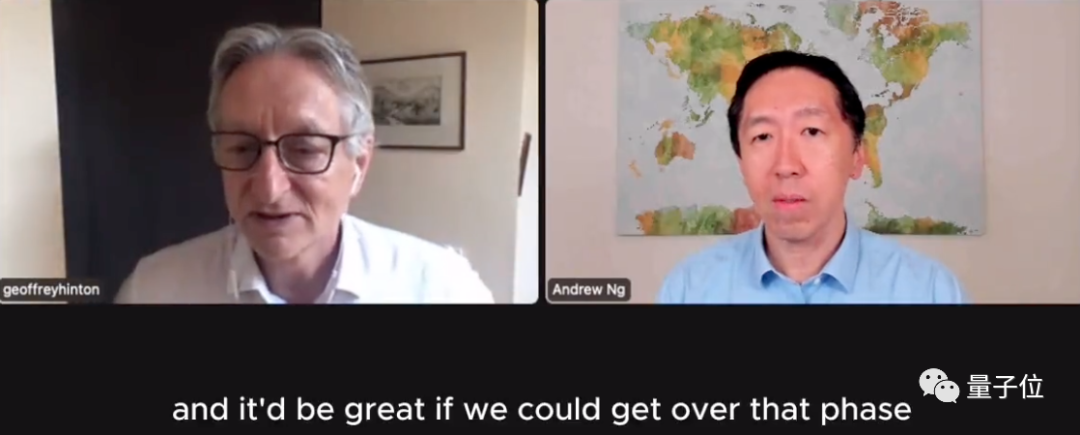
Bien sûr, LeCun, qui a été "interpellé", est également arrivé à temps et a exprimé son point de vue avec sérieux :
Nous sommes tous d’accord sur le fait que « tout le monde doit parvenir à un consensus sur certaines questions ». Je suis également d'accord avec Hinton sur le fait que LLM a une certaine compréhension et que dire qu'il ne s'agit que de « justes statistiques » est trompeur.
1. Mais leur compréhension du monde est très superficielle, en grande partie parce qu'ils ne sont formés qu'avec du texte brut. Les systèmes d'IA qui apprennent comment le monde fonctionne à partir de la vision auront une compréhension plus profonde de la réalité, alors que les capacités de raisonnement et de planification autorégressives du LLM sont très limitées en comparaison.
2. Je ne crois pas qu'une IA proche du niveau humain (ou même félin) émergera sans les conditions suivantes :
(1) Un modèle mondial qui apprend à partir d'apports sensoriels tels que les vidéos
(2) Un modèle capable de raisonner et une architecture de plan ((pas seulement autorégressive)
3. Si nous avons des architectures qui comprennent la planification, elles seront axées sur les objectifs, c'est-à-dire qu'elles pourront planifier le travail en fonction de l'objectif d'optimiser le temps d'inférence (pas seulement le temps de formation). Ces objectifs peuvent constituer des garde-fous qui rendent les systèmes d’IA « obéissants » et sûrs, ou même, en fin de compte, créent de meilleurs modèles du monde que les humains.
Le problème devient alors de concevoir (ou former) une bonne fonction objective qui garantit sécurité et efficacité.
4. Il s’agit d’un problème d’ingénierie difficile, mais pas aussi difficile que certains le disent.
Bien que cette réponse ne mentionne toujours pas les "risques de l'IA", LeCun a donné des suggestions pratiques pour améliorer la sécurité de l'IA (en créant des "garde-corps") et a envisagé une IA "à long terme" plus puissante que les humains. À quoi ça ressemble" (entrée multisensorielle + planification déductible).
Dans une certaine mesure, les deux parties sont parvenues à un certain consensus sur l'idée que l'IA présente des problèmes de sécurité.
Hinton : La superintelligence est plus proche qu'on ne l'imaginait
Bien sûr, il ne s'agit pas seulement de la conversation avec Andrew Ng.
Hinton, qui a récemment démissionné de Google, a évoqué le sujet des risques liés à l'IA à de nombreuses reprises, notamment lors de la récente conférence sur les sources intelligentes à laquelle il a assisté.
Lors de la conférence, sur le thème "Deux voies vers l'intelligence", il a discuté des deux voies du renseignement que sont la "distillation des connaissances" et le "partage du poids", ainsi que de la manière de rendre l'IA plus intelligente et de sa propre compréhension de la super intelligence. La vision qui se dégage.
En termes simples, Hinton croit non seulement que la superintelligence (plus intelligente que les humains) apparaîtra, mais qu'elle apparaîtra plus rapidement que les gens ne le pensent.
Non seulement cela, il pense que ces super intelligences deviendront incontrôlables, mais actuellement il ne trouve aucun bon moyen de les arrêter :
La super intelligence peut facilement gagner plus de pouvoir en manipulant les gens. Nous ne sommes pas habitués à penser à des choses qui sont beaucoup plus intelligentes que nous et à la manière d’interagir avec elles. Il devient habile à tromper les gens car il peut apprendre des exemples de tromperie autrui dans certaines œuvres de fiction.
Une fois qu'il sait tromper les gens, il a une façon de les amener à faire n'importe quoi... Je trouve ça horrible mais je ne vois pas comment empêcher que cela se produise parce que je suis vieux.
J'espère que de jeunes chercheurs talentueux comme vous découvriront comment nous possédons ces super intelligences et rendront nos vies meilleures.
Lorsque la diapositive "LA FIN" a été montrée, Hinton a souligné de manière significative :
C'est mon dernier PPT et la fin de ce discours.
Lien de référence :
[1]https://twitter.com/AndrewYNg/status/1667920020587020290
[2]https://twitter.com/AndrewYNg/status/1666582174257254402
[3 ]https https://2023.baai.ac.cn/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI