
Maison >Périphériques technologiques >IA >Le nouveau travail de Tian Yuandong : en ouvrant la première couche de la boîte noire du Transformer, le mécanisme d'attention n'est pas si mystérieux
Le nouveau travail de Tian Yuandong : en ouvrant la première couche de la boîte noire du Transformer, le mécanisme d'attention n'est pas si mystérieux

- 王林avant
- 2023-06-12 13:56:091461parcourir
L'architecture Transformer a balayé de nombreux domaines, notamment le traitement du langage naturel, la vision par ordinateur, la parole, la multimodalité, etc. Cependant, les résultats expérimentaux sont actuellement très impressionnants et les recherches pertinentes sur le principe de fonctionnement de Transformer sont encore très limitées. .
Le plus grand mystère est de savoir pourquoi Transformer peut émerger des représentations efficaces de la dynamique d'entraînement par gradient en s'appuyant uniquement sur une « simple perte de prédiction » ?
Récemment, le Dr Tian Yuandong a annoncé les derniers résultats de recherche de son équipe. De manière mathématiquement rigoureuse, il a analysé la dynamique d'entraînement SGD d'un transformateur à 1 couche (une couche d'auto-attention plus une couche de décodeur) sur le réseau. prochaine tâche de prédiction de jeton.

Lien papier : https://arxiv.org/abs/2305.16380
Cet article ouvre la boîte noire de la façon dont la couche d'auto-attention combine le processus dynamique des jetons d'entrée, et révèle la nature du biais inductif potentiel.
Plus précisément, en supposant qu'il n'y a pas de codage de position, une longue séquence d'entrée et que la couche de décodeur apprend plus rapidement que la couche d'auto-attention, les chercheurs ont prouvé que l'auto-attention est un algorithme d'analyse discriminante) :
En partant d'une attention uniforme, pour qu'un prochain jeton spécifique soit prédit, le modèle se concentre progressivement sur différents jetons clés et accorde moins d'attention à ceux qui apparaissent dans plusieurs fenêtres de prochains jetons. Jetons communs
Pour différents jetons, le Le modèle réduira progressivement le poids de l'attention, en suivant l'ordre de cooccurrence faible à élevée entre les jetons clés et les jetons de requête dans l'ensemble d'entraînement.
Fait intéressant, ce processus ne conduit pas à un gagnant-gagnant, mais est ralenti par une transition de phase contrôlée par le taux d'apprentissage à deux couches, et devient finalement une combinaison de jetons (presque) fixe, à la fois synthétique et des données du monde réel. Cette dynamique est également vérifiée.
Le Dr Tian Yuandong est chercheur et directeur de recherche au Meta Artificial Intelligence Research Institute et chef du projet Go AI. Ses axes de recherche sont l'apprentissage par renforcement profond et son application dans les jeux, ainsi que l'analyse théorique de l'apprentissage par renforcement profond. modèles d’apprentissage profond. Il a obtenu sa licence et sa maîtrise à l'Université Jiao Tong de Shanghai en 2005 et 2008, et son doctorat à l'Institut de robotique de l'Université Carnegie Mellon aux États-Unis en 2013.
A remporté les mentions honorables du prix Marr de la Conférence internationale sur la vision par ordinateur (ICCV) 2013 (mentions honorables du prix Marr) et le prix de mention honorable de l'article exceptionnel ICML2021.
Après avoir obtenu son doctorat, il a publié une série de « Cinq années de doctorat. Résumé », qui résume les pensées et les expériences de la carrière du doctorat sous des aspects tels que la sélection des orientations de recherche, accumulation de lecture, gestion du temps, attitude au travail, revenus et développement de carrière durable.
Révéler le Transformer à 1 couche
Les modèles de pré-formation basés sur l'architecture Transformer n'incluent généralement que des tâches de supervision très simples, comme prédire le mot suivant, remplir les blancs, etc., mais ils peuvent fournir des représentations pour les tâches en aval, ce qui est vraiment impressionnant. Les gens sont confus.
Bien que des travaux antérieurs aient prouvé que Transformer est essentiellement un approximateur universel, les modèles d'apprentissage automatique précédemment couramment utilisés, tels que kNN, kernel SVM, perceptron multicouche, etc., sont en fait des approximateurs universels. Cette théorie ne peut pas expliquer le. énorme écart de performances entre ces deux types de modèles.
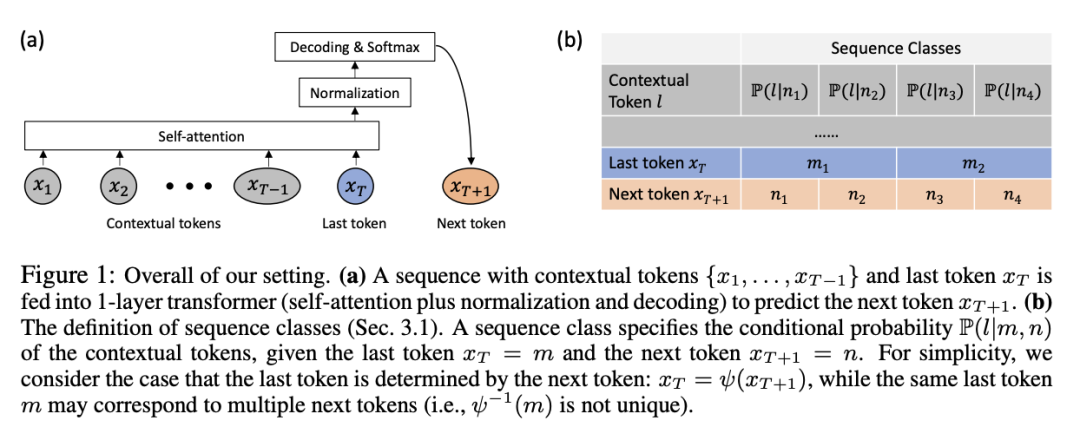
Les chercheurs estiment qu'il est important de comprendre la dynamique de formation de Transformer, c'est-à-dire comment les paramètres apprenables changent au fil du temps au cours du processus de formation.
L'article utilise d'abord une définition mathématique rigoureuse pour décrire formellement la dynamique de formation de SGD d'un transformateur de codage positionnel sans couche sur la prochaine prédiction de jeton (un paradigme de formation couramment utilisé pour les modèles de la série GPT).
Le transformateur de la couche 1 contient une couche d'auto-attention softmax et une couche de décodeur qui prédit le prochain jeton.
En supposant que la séquence est longue et que le décodeur apprend plus rapidement que la couche d'auto-attention, le comportement dynamique de l'auto-attention pendant l'entraînement est démontré :
1. Biais
Le modèle accordera progressivement une attention aux jetons clés qui coexistent en grand nombre avec le jeton de requête, et réduira l'attention aux jetons qui coapparaissent moins.
2. Biais discriminatoire
Le modèle accorde plus d'attention aux jetons uniques qui n'apparaissent que dans le prochain jeton à prédire, et perd sur les jetons communs qui apparaissent dans plusieurs prochains jetons d'intérêt.
Ces deux caractéristiques indiquent que l'attention personnelle exécute implicitement un algorithme d'analyse discriminant et a un biais inductif, c'est-à-dire qu'elle est orientée vers des fonctionnalités uniques qui apparaissent souvent avec des jetons de requête
De plus. , bien que la couche d'auto-attention ait tendance à devenir plus clairsemée pendant l'entraînement, comme l'indique l'écart de fréquence, le modèle ne s'effondre pas en raison des transitions de phase dans la dynamique d'entraînement pour un chaud.

L'étape finale de l'apprentissage ne converge vers aucun point de selle où le gradient est nul, mais entre dans une région où l'attention change lentement (c'est-à-dire de manière logarithmique au fil du temps) et les paramètres se figent et sont appris.
Les résultats de la recherche montrent en outre que le début de la transition de phase est contrôlé par le taux d'apprentissage : un taux d'apprentissage élevé produira des modèles d'attention clairsemés, tandis qu'à un taux d'apprentissage d'auto-attention fixe, un taux d'apprentissage élevé du décodeur entraînera des transitions de phase plus rapides et des schémas d'attention intensifs.
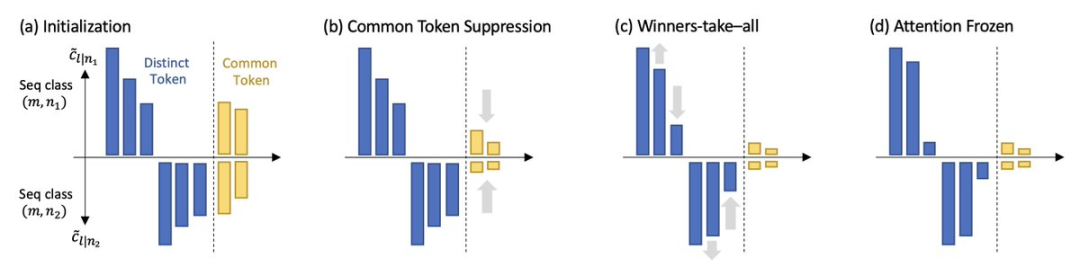
Les chercheurs ont nommé la dynamique SGD découverte dans leur travail scan and snap :
Phase de scan : L'auto-attention est concentrée sur les jetons clés, c'est-à-dire différents et souvent liés au prochain jeton de prédiction. apparaissent en même temps ; tous les autres jetons perdent leur attention.
étape instantanée : L'attention est presque figée et la combinaison de jetons est corrigée.

Ce phénomène a également été vérifié dans de simples expériences de données réelles en utilisant SGD pour observer la couche d'auto-attention la plus basse des transformateurs à 1 couche et 3 couches formés sur WikiText, cela peut être. a constaté que même dans Le taux d'apprentissage reste constant tout au long de la formation, et l'attention se fige et devient clairsemée à un moment donné au cours de la formation.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI