
Maison >Périphériques technologiques >IA >L'iPhone prend deux secondes pour produire une image, et le modèle mobile à diffusion stable le plus rapide connu est ici.
L'iPhone prend deux secondes pour produire une image, et le modèle mobile à diffusion stable le plus rapide connu est ici.

- 王林avant
- 2023-06-12 11:15:481410parcourir
La diffusion stable (SD) est actuellement le modèle de diffusion de génération de texte en image le plus populaire. Bien que ses puissantes capacités de génération d'images soient choquantes, un inconvénient évident est qu'il nécessite d'énormes ressources informatiques et que la vitesse d'inférence est très lente : en prenant le SD-v1.5 comme exemple, même en utilisant un stockage demi-précision, sa taille de modèle est de 1,7 Go. Avec 1 milliard de paramètres, le temps d'inférence sur l'appareil est souvent proche de 2 minutes.
Afin de résoudre le problème de la vitesse d'inférence, le monde universitaire et l'industrie ont commencé des recherches sur l'accélération SD, en se concentrant principalement sur deux voies : (1) Réduire le nombre d'étapes d'inférence. Cette voie peut être divisée en deux sous-routes. L'un est de réduire le nombre d'étapes en proposant un meilleur ordonnanceur de bruit, les travaux représentatifs sont DDIM [1], PNDM [2], DPM [3], etc. ; Distillation Progressive), le travail représentatif est la Distillation Progressive [4] et le conditionnement en w [5] etc. (2) Optimisation des compétences en ingénierie. Le travail représentatif est que Qualcomm utilise la quantification int8 + l'optimisation full-stack pour atteindre SD-v1.5 sur les téléphones Android en 15 secondes [6]. .4 sur les téléphones Samsung, accélération à 12s [7].
Même si ces efforts ont parcouru un long chemin, ils ne sont toujours pas assez rapides.
Récemment, Snap Research Institute a lancé le dernier modèle de diffusion stable hautes performances Grâce à une optimisation complète de la structure du réseau, du processus de formation et de la fonction de perte, il peut atteindre 2 secondes de sortie d'image (512 x 512) sur l'iPhone 14 Pro, et est plus rapide que SD-v1.5 et obtient un meilleur score CLIP. Il s’agit du modèle de diffusion stable de bout en bout connu le plus rapide !

- Adresse papier : https://arxiv.org/pdf/2306.00980.pdf
- Page Web : https://snap-research.github.io/SnapFusion
Méthode de base
Le modèle de diffusion stable est divisé en trois parties : encodeur/décodeur VAE, encodeur de texte, UNet, parmi lesquelles UNet représente la majorité absolue en termes de quantité de paramètres et de quantité de calcul, donc SnapFusion optimise principalement UNet. Il est divisé en deux parties : (1) Optimisation de la structure UNet : En analysant le goulot d'étranglement de vitesse de l'UNet original, cet article propose un ensemble de processus automatiques d'évaluation et d'évolution de la structure UNet, et obtient une structure UNet plus efficace (appelée UNet efficace). (2) Optimisation du nombre d'étapes d'inférence : Comme nous le savons tous, le modèle de diffusion est un processus de débruitage itératif lors de l'inférence. Plus il y a d'étapes d'itération, plus la qualité des images générées est élevée, mais le coût en temps augmente également linéairement avec le nombre d'étapes d'inférence. nombre d'étapes d'itération. Afin de réduire le nombre d'étapes et de maintenir la qualité de l'image, nous proposons une fonction de perte de distillation prenant en compte le CFG qui considère explicitement le rôle du CFG (Classifier-Free Guidance) pendant le processus de formation. Cette fonction de perte s'est avérée être la clé. amélioration du score CLIP !
Le tableau suivant est une comparaison générale entre les modèles SD-v1.5 et SnapFusion. On peut voir que l'amélioration de la vitesse provient des deux parties du décodeur UNet et VAE, et la partie UNet est la plus importante. L'amélioration de la partie UNet comporte deux aspects. L'un est la réduction de la latence unique (1 700 ms -> 230 ms, accélération 7,4x), obtenue grâce à la structure Efficient UNet proposée. L'autre est la réduction des étapes d'inférence ( 50 -> 8, 6,25 x accélération), obtenue grâce à la distillation compatible CFG proposée. Le décodeur VAE est accéléré grâce à un élagage structuré.

Ce qui suit se concentre sur la conception d'Efficient UNet et la conception de la fonction de perte de distillation compatible CFG.
(1) UNet efficace
En analysant les modules Cross-Attention et ResNet dans UNet, nous avons déterminé que le goulot d'étranglement de vitesse réside dans le module Cross-Attention (en particulier la Cross-Attention dans le premier sous-échantillonnage étape). Comme indiqué ci-dessous. La cause fondamentale de ce problème est que la complexité du module d'attention a une relation carrée avec la taille spatiale de la carte de caractéristiques. Dans la première étape de sous-échantillonnage, la taille spatiale de la carte de caractéristiques est toujours grande, ce qui entraîne une complexité de calcul élevée.
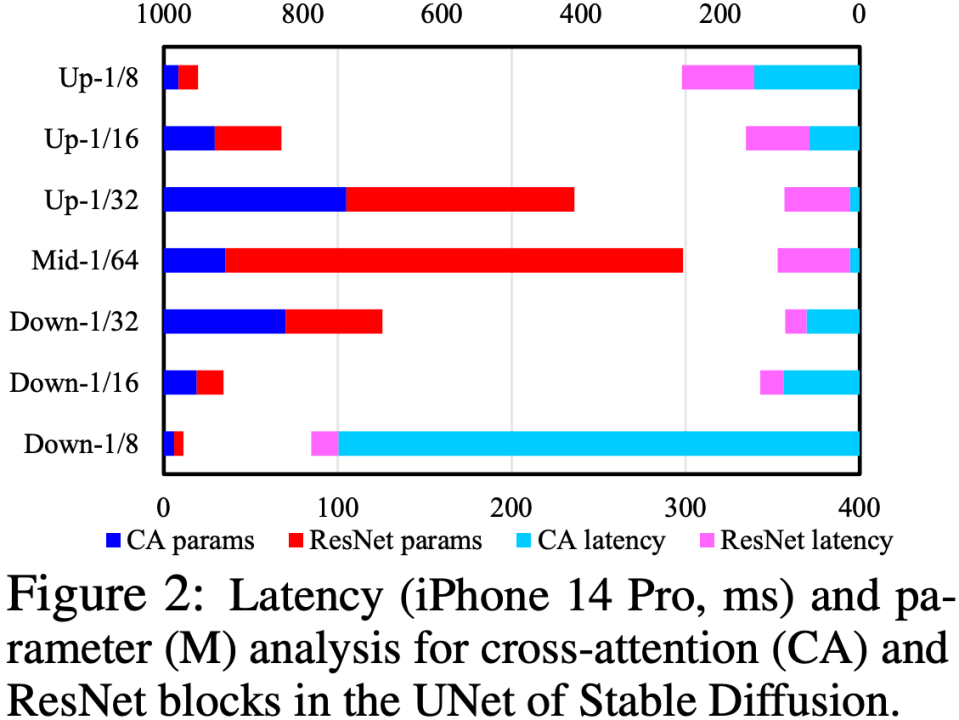
Afin d'optimiser la structure UNet, nous proposons un ensemble de processus automatiques d'évaluation et d'évolution de la structure UNet : effectuez d'abord une formation robuste (Robust Training) sur UNet, et abandonnez aléatoirement certains modules pendant la formation pour tester les performances de chaque module. L'impact réel sur le score CLIP est construit pour construire une table de recherche de « l'impact sur le score CLIP par rapport à la latence », puis sur la base de la table de recherche, les modules qui ont peu d'impact sur le score CLIP et qui prennent beaucoup de temps sont supprimés en premier ; Cet ensemble de processus est effectué automatiquement en ligne. Une fois terminé, nous obtiendrons une toute nouvelle structure UNet appelée Efficient UNet. Par rapport à l'UNet d'origine, il atteint une accélération de 7,4x sans dégradation des performances.
(2) La distillation par étapes compatible CFG
CFG (Classifier-Free Guidance) est une compétence essentielle dans l'étape d'inférence SD. Elle peut grandement améliorer la qualité de l'image, ce qui est très critique ! Bien qu'il y ait eu des travaux sur le modèle de diffusion utilisant la distillation par étapes pour accélérer [4], ils n'ont pas inclus le CFG comme objectif d'optimisation dans la formation à la distillation. C'est-à-dire que la fonction de perte de distillation ne sait pas que le CFG sera utilisé plus tard. Selon notre observation, cela affectera sérieusement le score CLIP lorsque le nombre de pas est faible.
Afin de résoudre ce problème, nous proposons de laisser les modèles enseignant et étudiant effectuer le CFG avant de calculer la fonction de perte de distillation, de sorte que la fonction de perte soit calculée sur les caractéristiques après CFG, considérant ainsi explicitement l'influence des différentes échelles CFG. . Dans l'expérience, nous avons constaté que même si le score CLIP peut être amélioré en utilisant entièrement la distillation compatible CFG, le FID devient également nettement pire. Nous avons ensuite proposé un schéma d'échantillonnage aléatoire pour mélanger la fonction de perte de distillation par étapes d'origine et la fonction de perte de distillation compatible CFG, obtenant ainsi la coexistence des avantages des deux, ce qui a non seulement amélioré de manière significative le score CLIP, mais n'a pas non plus aggravé le FID. . Cette étape permet d'obtenir une accélération de 6,25 fois dans l'étape d'inférence ultérieure, ce qui donne une accélération totale d'environ 46 fois.
En plus des deux contributions principales ci-dessus, l'article inclut également l'accélération de l'élagage du décodeur VAE et la conception soignée du processus de distillation. Veuillez vous référer à l'article pour un contenu spécifique.
Résultats expérimentaux
SnapFusion teste la fonction texte en image du SD-v1.5. L'objectif est de réduire considérablement le temps d'inférence et de maintenir la qualité de l'image. La meilleure illustration en est l'image suivante :
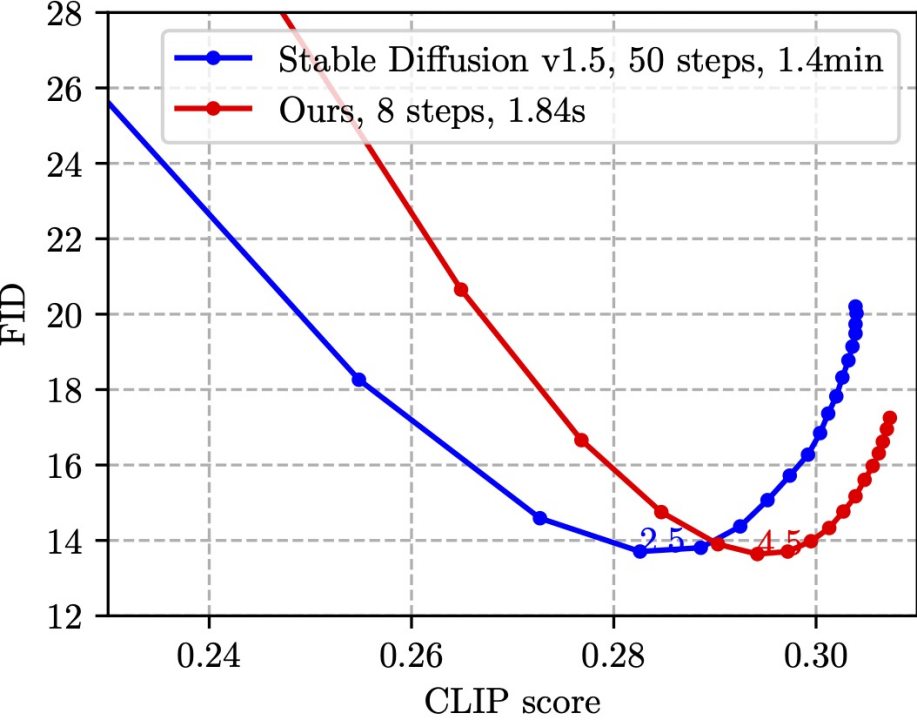 .
.
Cette image est basée sur la sélection aléatoire de 30 000 paires légende-image sur l'ensemble de vérification MS COCO'14 pour mesurer le score CLIP et le FID. Le score CLIP mesure la cohérence sémantique entre les images et le texte, plus c'est grand, mieux c'est ; FID mesure la distance de distribution entre les images générées et les images réelles (généralement considérée comme une mesure de la diversité des images générées), plus c'est petit, mieux c'est. Différents points du graphique sont obtenus en utilisant différentes échelles CFG, et chaque échelle CFG correspond à un point de données. Comme le montre la figure, notre méthode (ligne rouge) peut atteindre le même FID le plus bas que SD-v1.5 (ligne bleue), et en même temps, le score CLIP de notre méthode est meilleur. Il convient de noter que SD-v1.5 prend 1,4 min pour générer une image, tandis que SnapFusion ne prend que 1,84 s. Il s'agit également du modèle de diffusion stable mobile le plus rapide que nous connaissons !
Voici quelques exemples générés par SnapFusion :

Veuillez vous référer à l'annexe de l'article pour plus d'échantillons.
En plus de ces principaux résultats, l'article présente également de nombreuses expériences d'analyse d'ablation (Ablation Study), dans l'espoir de fournir une expérience de référence pour le développement de modèles SD efficaces :
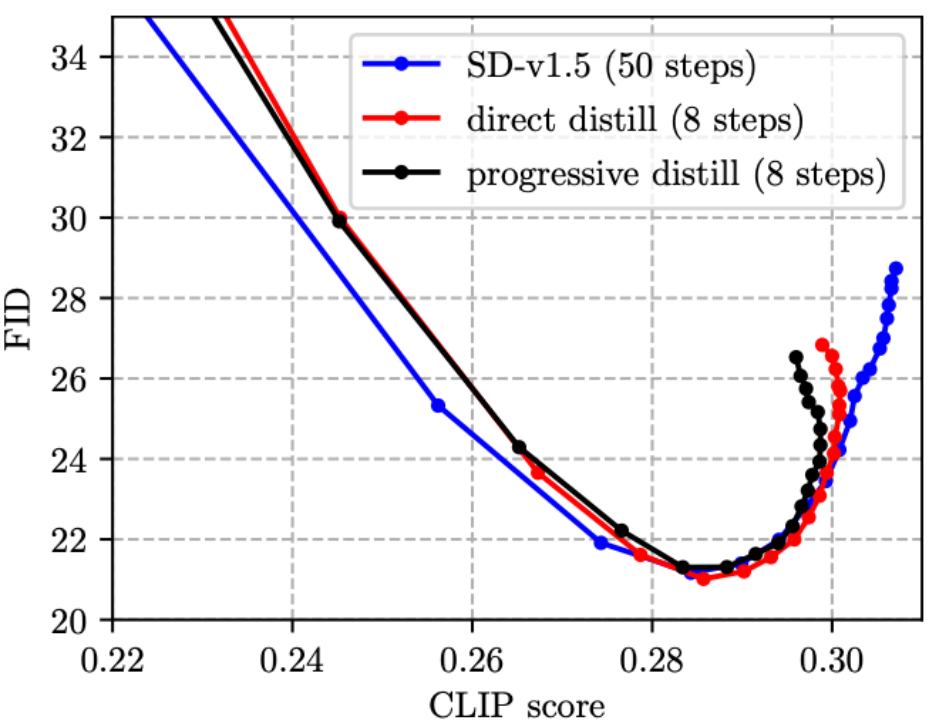
(1) Les travaux antérieurs sur la distillation par étapes sont généralement Nous avons utilisé le schéma de formule progressive [4, 5], mais nous avons constaté que la distillation progressive n'a aucun avantage par rapport à la distillation directe sur le modèle SD et que le processus est fastidieux, nous adoptons donc le schéma de distillation directe dans cet article.
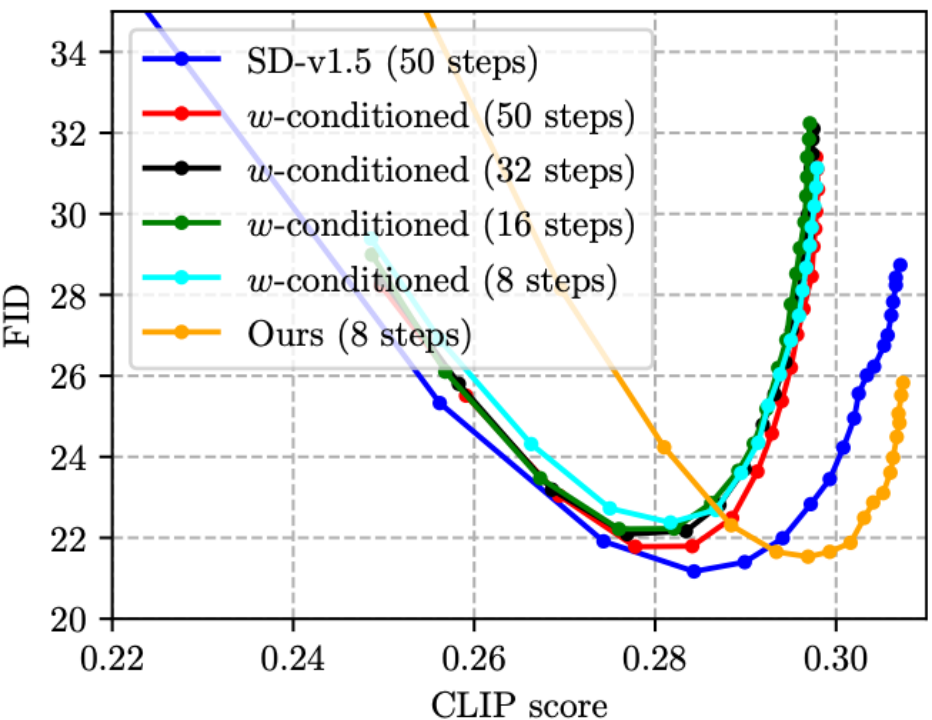
(2) Bien que CFG puisse améliorer considérablement la qualité de l'image, le prix double le coût d'inférence. L'article sur la distillation du candidat au prix CVPR'23 de cette année [5] proposait le conditionnement en w, qui utilise les paramètres CFG comme entrée dans UNet pour la distillation (le modèle résultant est appelé UNet w-conditionné), éliminant ainsi l'étape CFG pendant le raisonnement et réalisant le raisonnement. coûts réduits de moitié. Cependant, nous avons constaté que cela entraînerait en fait une diminution de la qualité de l'image et du score CLIP (comme le montre la figure ci-dessous, le score CLIP des quatre lignes conditionnées en w ne dépasse pas 0,30, ce qui est pire que SD- v1.5). Notre méthode peut réduire le nombre d'étapes et améliorer le score CLIP en même temps, grâce à la fonction de perte de distillation proposée par CFG ! Ce qui est particulièrement remarquable, c'est que les coûts d'inférence de la ligne verte (w-conditionné, 16 étapes) et de la ligne orange (la nôtre, 8 étapes) dans la figure ci-dessous sont les mêmes, mais la ligne orange est évidemment meilleure, indiquant que notre La voie technique est meilleure que le conditionnement w-conditionné [5] est plus efficace sur le modèle SD guidé par CFG distillé.
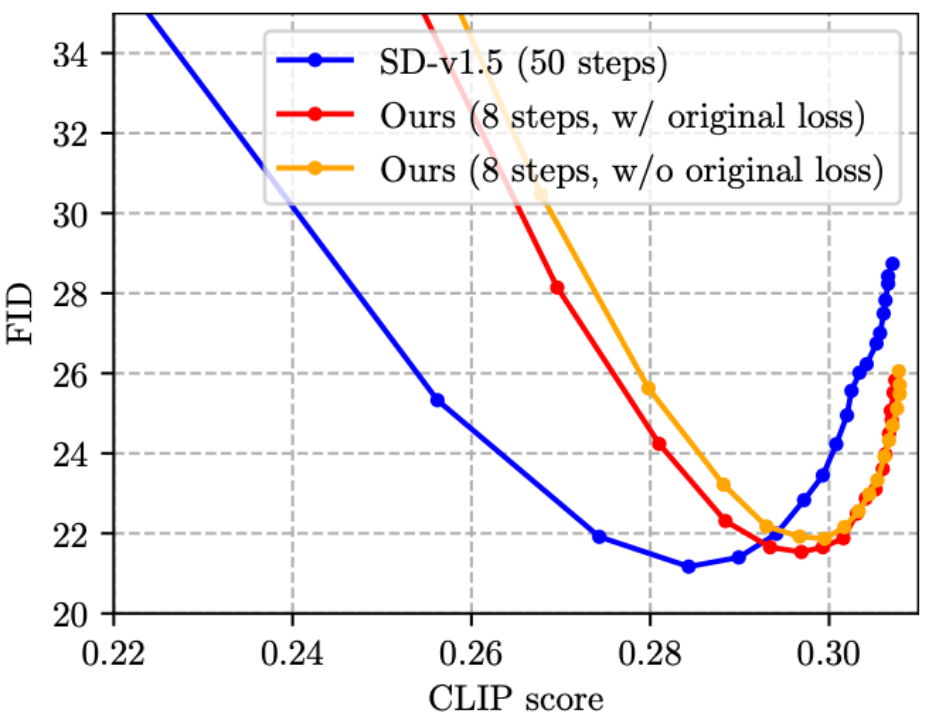
(3) Étape existante Travaux de distillation[4, 5] Sans ajout la fonction de perte d'origine et la fonction de perte de distillation fonctionnent ensemble, les amis qui connaissent la distillation des connaissances en classification d'images doivent savoir que cette conception est intuitivement sous-optimale. Nous avons donc proposé d'ajouter la fonction de perte d'origine à la formation, comme le montre la figure ci-dessous, qui est effectivement efficace (réduisant légèrement le FID).
Résumé et travaux futurs
Cet article propose SnapFusion, un modèle de diffusion stable haute performance pour mobile. SnapFusion a deux contributions principales : (1) Grâce à une analyse couche par couche de l'UNet existant, il localise le goulot d'étranglement en termes de vitesse et propose une nouvelle structure UNet efficace (Efficient UNet), qui peut de manière équivalente remplacer l'UNet dans la diffusion stable d'origine pour atteindre une accélération de 7,4 x ; (2) optimiser le nombre d'étapes d'itération dans la phase d'inférence et proposer un nouveau schéma de distillation par étapes (distillation par étapes compatible CFG), qui peut améliorer considérablement le score CLIP tout en réduisant le nombre d'étapes, atteignant 6,25x ; accélération. Dans l’ensemble, SnapFusion permet d’obtenir une sortie d’image en 2 secondes sur l’iPhone 14 Pro, qui est actuellement le modèle de diffusion stable mobile connu le plus rapide.
Futurs travaux :
1.Les modèles SD sont disponibles en une variété de Il peut être utilisé dans des scénarios de génération d'images. Cet article est limité dans le temps et se concentre actuellement uniquement sur la tâche principale du texte en image. D'autres tâches (telles que l'inpainting, ControlNet, etc.) seront suivies plus tard.
2. Cet article se concentre principalement sur l'amélioration de la vitesse et n'optimise pas le stockage des modèles. Nous pensons que l'Efficient UNet proposé a encore de la place pour la compression, combiné à d'autres méthodes d'optimisation hautes performances (telles que l'élagage, la quantification), il devrait réduire le stockage et réduire le temps à moins d'une seconde, créant ainsi une SD en temps réel. à la fin, un pas plus loin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI