
Maison >Périphériques technologiques >IA >L'article de NetEase Yidun AI Lab sélectionné pour ICASSP 2023 ! La technologie noire rend la reconnaissance vocale plus « écoutante » et plus précise
L'article de NetEase Yidun AI Lab sélectionné pour ICASSP 2023 ! La technologie noire rend la reconnaissance vocale plus « écoutante » et plus précise

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-11 23:06:28873parcourir
2023-06-07 17:42:41 Auteur : Li Wenwen
Tous les fans de science-fiction aspirent à ce que l'avenir soit capable de lancer un vaisseau spatial interstellaire et de conquérir les étoiles et la mer avec seulement quelques mots, tout comme parler à un vieil ami ou d'avoir Jarvis, le majordome de l'intelligence artificielle d'Iron Man, qui peut créer ; un monde avec seulement quelques mots de dialogue. Ensemble de nano-armures de combat. En fait, cette image n’est pas loin de nous – elle est aussi proche de nous que Siri dans l’iPhone. Derrière, se trouve la reconnaissance automatique de la parole. Cette technologie clé peut convertir la parole en texte ou en commandes pouvant être reconnues par les ordinateurs, offrant ainsi une expérience d'interaction homme-machine pratique, efficace et intelligente.
Avec le développement des technologies d'IA telles que l'apprentissage profond, la technologie de reconnaissance vocale a fait d'énormes progrès : non seulement la précision de la reconnaissance a été considérablement améliorée, mais elle peut également mieux gérer des problèmes tels que les accents, le bruit et les sons de fond. Cependant, à mesure que la technologie continue d'être appliquée dans la vie et dans les affaires, elle se heurtera encore à certains goulots d'étranglement. Après tout, il y a trop de facteurs pratiques à prendre en compte, de la recherche théorique aux applications pratiques, des articles aux produits. Comment améliorer la reconnaissance vocale pour faciliter la révision du contenu ? Comment l’action de reconnaissance elle-même peut-elle être à l’image du cerveau humain, basée sur la compréhension du contexte, et donner des réponses plus précises à moindre coût ? Yidun AI Lab, une filiale de NetEase Intelligence, a proposé une nouvelle approche.
Yidun a une autre technologie noire, et l'entreprise intelligente se dirige vers le monde !
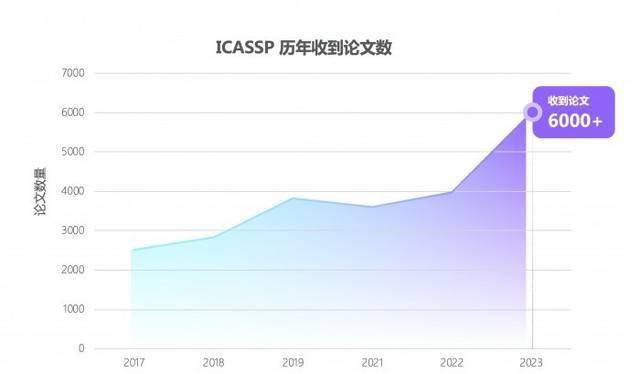
Récemment, la conférence mondiale sur la parole et l'acoustique ICASSP 2023 a annoncé la liste des articles sélectionnés, et l'article soumis par Yidun AI Lab, une filiale de NetEase Intelligence Enterprise, a été accepté avec succès. Cette année, c'est la 48e conférence ICASSP, et c'est aussi la première conférence hors ligne après l'épidémie. Bien que les responsables de la conférence n'aient pas annoncé le nombre final d'articles acceptés, le nombre d'articles soumis a augmenté de 50 % par rapport aux années précédentes, atteignant. un étonnant 6 000 +.
Face à une concurrence aussi féroce, l'équipe NetEase Yidun AILab s'appuie sur un article sur la reconnaissance vocale "Improving CTC-based ASRModels with Gated Interplayer Collaboration (Amélioration du modèle basé sur CTC pour obtenir une structure de modèle plus solide)" Il s'est démarqué et j'ai obtenu avec succès un billet pour assister à la conférence hors ligne à Rhodes, en Grèce.
« GIC » aide la reconnaissance vocale à aller plus loin
La reconnaissance vocale est essentiellement la conversion de séquences vocales en séquences de texte. Pour effectuer une telle conversion, généralement trois types de modèles sont utilisés, CTC, basé sur l'attention et RNN-Transducer.Ils utilisent différentes méthodes pour effectuer la tâche :
CTC : basé sur le modèle de réseau neuronal, les paramètres du modèle sont mis à jour par rétropropagation pendant le processus de formation pour minimiser la fonction de perte. Cet algorithme introduit des « caractères d'espacement » pour représenter des caractères dénués de sens ou des symboles d'espace. CTC convient au traitement de données présentant de grandes différences dans les longueurs d'entrée et de sortie, telles que le mappage de caractéristiques acoustiques avec du texte dans la reconnaissance vocale
;Basé sur l'attention : le mécanisme d'attention est également basé sur le modèle de réseau neuronal et utilise une technologie appelée « attention » pour pondérer l'entrée. À chaque pas de temps, le modèle calcule un vecteur de poids distribué basé sur l'état actuel et toutes les entrées, et l'applique à toutes les entrées pour produire une moyenne pondérée comme sortie. Cette méthode permet au modèle de mieux se concentrer sur certaines informations liées à la prédiction actuelle
;RNN-Transducer : Transcriptor, cet algorithme combine le cadre d'encodeur-décodeur et des idées de modélisation autorégressive, et considère simultanément l'interaction entre les phrases en langue source et les phrases partielles en langue cible générées lors de la génération de la séquence cible. Contrairement aux deux autres méthodes, RNN-Transducer ne fait pas de distinction claire entre les étapes d'encodeur et de décodeur, et convertit directement de la langue source en langue cible, de sorte qu'il peut prendre en compte l'interaction entre les phrases en langue source et les phrases partielles générées en langue cible en même temps. effet du temps.
Par rapport aux deux derniers, bien que CTC possède des propriétés de décodage naturelles non autorégressives et que sa vitesse de décodage soit relativement plus rapide, il présente toujours des inconvénients en termes de performances :
1. L'algorithme CTC définit l'hypothèse d'indépendance conditionnelle, c'est-à-dire que CTC suppose que les sorties de chaque pas de temps sont indépendantes. Cela n'est pas raisonnable pour les tâches de reconnaissance vocale. Si la prononciation « ji rou » est prononcée, le contenu du texte prédit devrait être différent selon les contextes. Si la phrase ci-dessus est « J'aime manger », la probabilité de « poulet » devrait être plus élevée. De même, si la phrase ci-dessus est « Il a des bras », la probabilité de « muscle » devrait être plus élevée. Si vous vous entraînez via CTC, il est facile d'afficher un texte amusant comme « J'aime manger des muscles » tout en ignorant ce qui précède
;2. Du point de vue de la modélisation, le modèle basé sur l'attention et le modèle RNN-Transducer prédisent la sortie du pas de temps actuel en fonction de l'entrée et de la sortie du pas de temps précédent, tandis que le modèle CTC utilise uniquement l'entrée pour prédire la sortie actuelle.Dans le modèle CTC Dans le processus de modélisation, les informations textuelles sont uniquement renvoyées au réseau en tant que signal de supervision et ne servent pas d'entrée au réseau pour promouvoir explicitement la prédiction du modèle.
Nous espérons résoudre autant que possible les deux inconvénients ci-dessus tout en conservant l'efficacité du décodage CTC. Par conséquent, nous souhaitons partir du modèle CTC lui-même et concevoir un module léger pour introduire des informations textuelles dans le modèle basé sur CTC, afin que le modèle puisse intégrer des informations acoustiques et textuelles, apprendre l'interaction entre le contexte de la séquence de texte et ainsi atténuer les problèmes. Algorithme CTC. L'hypothèse d'indépendance conditionnelle de . Mais dans le processus, nous avons rencontré deux problèmes : Comment injecter des informations textuelles dans le modèle CTC (Encoder + structure CTC) ? Comment fusionner de manière adaptative les caractéristiques textuelles et les caractéristiques acoustiques ?
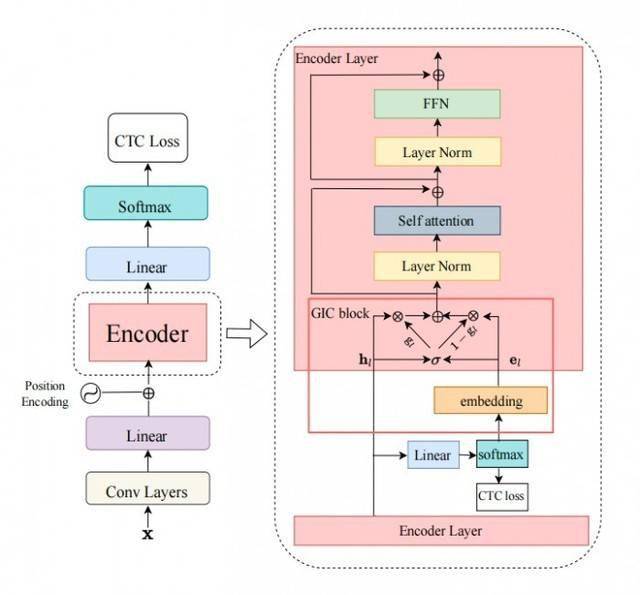
Afin d'atteindre les objectifs ci-dessus,nous avons conçu le mécanisme Gated Interlayer Collaboration (GIC). Le module GIC comprend principalement une couche d'intégration et une unité de porte. Parmi eux, la couche d'intégration est utilisée pour générer des informations textuelles pour chaque trame d'entrée audio, et l'unité de déclenchement est utilisée pour fusionner de manière adaptative les informations textuelles et les informations acoustiques.
Plus précisément, notre méthode est basée sur le cadre d'apprentissage multi-tâches (Multi-task Learning), utilisant la sortie de la couche intermédiaire du module encodeur (Encoder) pour calculer la perte CTC auxiliaire. La fonction objectif de l'ensemble du réseau est. la dernière couche de perte de CTC et la couche intermédiaire auxiliaire Somme pondérée des pertes de CTC. GIC utilise la prédiction de la couche intermédiaire du réseau, c'est-à-dire la distribution de probabilité de la sortie Softmax, comme étiquette logicielle de chaque image, et la somme des matrices de couche d'intégration du produit scalaire comme représentation textuelle de chaque image.Enfin, la représentation textuelle et la représentation acoustique générées sont fusionnées de manière adaptative via une unité de porte et deviennent une nouvelle entrée de fonctionnalité pour la couche suivante. Les nouvelles fonctionnalités actuelles combinent des fonctionnalités de texte et des fonctionnalités acoustiques, permettant au module Encoder de niveau supérieur d'apprendre les informations contextuelles de la séquence acoustique et les informations contextuelles de la séquence de texte. Le cadre de l'ensemble du modèle est présenté dans la figure ci-dessous :
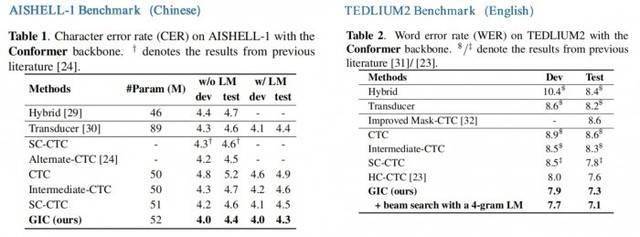
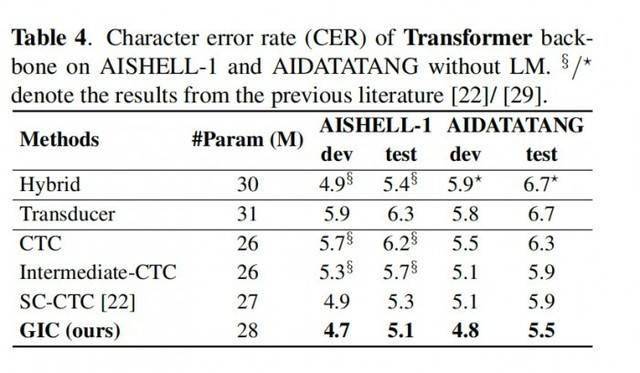
Expériences sur les modèles Conformer et Transformer montrent :1. GIC
prend en charge la reconnaissance de scène en chinois et en anglais et a obtenu des améliorations significatives en matière de précision ;
2. Les performances du modèle GIC dépassent celles des modèles basés sur l'attention et à transducteur RNN avec la même échelle de paramètres, et présentent l'avantage d'un décodage non autorégressif,apportant une amélioration plusieurs fois de la vitesse de décodage ; 3. Par rapport au modèle CTC d'origine, GIC présente une amélioration relative des performances de bien plus de 10 %
dans plusieurs ensembles de données open source.
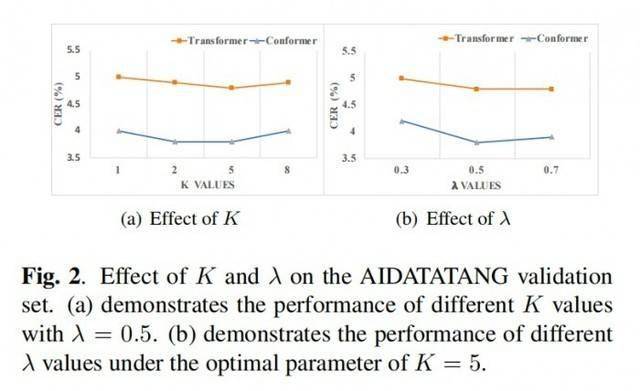
ConformateurConclusion sous le modèle
TransformateurConclusion sous le modèle GIC apporte de grandes améliorations aux performances des modèles CTC. Par rapport au modèle CTC original, le module GIC apporte environ 2 millions de paramètres supplémentaires. Parmi eux, la couche linéaire utilisée pour calculer la perte CTC auxiliaire de la couche intermédiaire est partagée avec la dernière couche et n'apporte pas de paramètres supplémentaires. Plusieurs couches intermédiaires partagent la couche d'intégration, apportant 256*5000 paramètres, ce qui équivaut approximativement à 1,3 M. De plus, la quantité de paramètres supplémentaires requis pour plusieurs unités de porte de contrôle est de 256*256*2*k, soit un total d'environ 0,6 M.
Une technologie de pointe crée des affaires avancéesLe GIC présenté dans le document a été appliqué à l'activité de révision de contenu de NetEase Yidun.
En tant que marque unique de contrôle des risques liés au contenu numérique sous NetEase Intelligence, Yidun se concentre depuis longtemps sur la recherche, le développement et l'innovation technologiques en matière de contrôle des risques de sécurité du contenu numérique et d'informations anti-spam. Parmi eux, pour le contenu numérique utilisant le son comme support, Yidun fournit une variété de moteurs d'audit de contenu audio, y compris divers types de contenu audio tels que des chansons, la radio, des programmes télévisés, des émissions en direct, etc., pour détecter et filtrer rapidement le contenu. qui contient du contenu sensible, illégal et vulgaire. La voix du contenu publicitaire, réduisant ainsi l'impact social du mauvais contenu et créant un bon environnement de réseau.
Pour l'audio avec un contenu sémantique spécifique, Yidun utilise la technologie de reconnaissance vocale pour transcrire le contenu vocal du fichier audio en contenu texte, puis utilise le module de détection pour analyser et traiter le texte, réalisant ainsi une révision et un filtrage automatisés du contenu audio.
Par conséquent, la précision de la reconnaissance vocale est étroitement liée à l'efficacité et à la précision de l'examen du contenu audio et affectera directement la sécurité et la stabilité des opérations commerciales des clients.L'application du GIC dans le journal a permis d'améliorer considérablement la révision du contenu.
Dans le processus de candidature réel, deux hyperparamètres doivent être débogués, à savoir le coefficient d'apprentissage multitâche lambda et le nombre de couches intermédiaires k. Dans la structure du codeur à 18 couches, nous avons constaté que k=5 et lambda=0,5 ont de meilleurs résultats expérimentaux. Nous commençons ensuite avec ce paramètre et l'affinons pour déterminer les hyperparamètres optimaux. ?
Le héros dans les coulisses : NetEase Zhiqi Yidun AI LabCe n'est pas la première fois que l'équipe du Yidun AI Lab reçoit des honneurs avec un tel cahier des charges.
En tant qu'équipe technique de NetEase Intelligence qui a toujours été à la pointe de la recherche sur l'intelligence artificielle, Yidun AI Lab s'engage à créer des capacités techniques d'IA complètes, rigoureuses, sûres et dignes de confiance autour du raffinement, de l'allègement et de l'agilité, et à améliorer continuellement le contenu numérique. Niveau de service de contrôle des risques. Avant cela, l'équipe
a remporté plusieurs championnats de compétition d'algorithmes d'IA et des récompenses importantes :Le premier concours chinois d'intelligence artificielle en 2019, le certificat de niveau A le plus avancé dans la filière de reconnaissance des drapeaux
Le 2e Concours chinois d'intelligence artificielle en 2020, le certificat de niveau A le plus avancé dans le domaine de la détection vidéo des deepfakes
Le 3e Concours chinois d'intelligence artificielle en 2021, les deux certificats de niveau A les plus avancés pour la détection des deepfakes vidéo et les pistes de détection des deepfakes audio
2021 « Étoile de l'innovation » et « Figure innovante » de l'Alliance chinoise pour le développement de l'industrie de l'intelligence artificielle
La 16e Conférence académique nationale sur la communication vocale homme-machine 2021 (NCMMSC2021) « Concours de reconnaissance multilingue et multimodale de vidéos longues et courtes » – Champion de la double piste des mots-clés vocaux en direct de vidéos longues et courtes chinoises (VKW)
A remporté le premier prix du Prix du progrès scientifique et technologique décerné par le gouvernement provincial du Zhejiang en 2021
Le Concours de reconnaissance multimodale de sous-titres ICPR 2022 (Concours MSR, le premier concours national de reconnaissance de sous-titres multimodaux) suit trois champions du « Système de reconnaissance de sous-titres multimodaux qui intègre la vision et l'audio »
L'avenir est là et l'heure de l'iPhone alimenté par l'IA est arrivée. Yidun est entré avec succès dans la salle universitaire de phonétique aujourd'hui, et à l'avenir, la technologie apportera des réalisations et des progrès dans tous les aspects des affaires, et Yidun sera toujours à vos côtés.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI