
Maison >Périphériques technologiques >IA >Reproduisez la touche magique d'AlphaGo à l'époque ! La nouvelle IA de DeepMind a découvert un algorithme de tri accéléré de 70 % et la bibliothèque C++ qui n'a pas été mise à jour depuis dix ans a été mise à jour
Reproduisez la touche magique d'AlphaGo à l'époque ! La nouvelle IA de DeepMind a découvert un algorithme de tri accéléré de 70 % et la bibliothèque C++ qui n'a pas été mise à jour depuis dix ans a été mise à jour

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-09 21:59:141102parcourir
DeepMind est de nouveau apparu dans Nature avec des résultats majeurs !
Cette fois, ils ont créé une autre IA d'apprentissage par renforcement, réalisant de nouvelles percées dans les deux algorithmes les plus fondamentaux dans le domaine informatique :
L'un est l'algorithme de tri, qui a découvert une nouvelle implémentation qui peut augmenter la vitesse jusqu'à 70 % ;
Un autre est l'algorithme de hachage, qui a également trouvé un nouveau moyen d'augmenter la vitesse de 30 %.

Non seulement cela, la méthode utilisée par cette IA s'appelle "recréer la touche magique d'AlphaGo à l'époque", qui est l'époque qui semblait violer l'intuition, mais qui a en fait vaincu le maître humain Lee Sedol en d'un seul coup.
Dès que la nouvelle est sortie, elle a immédiatement fait exploser le cercle universitaire. Certains internautes ont crié :
Je ne m'attendais pas à ce qu'un algorithme aussi ancien et basique puisse être encore amélioré.

Et c'est précisément grâce à cette dernière réalisation que la bibliothèque C++ standard LLVM, qui n'a pas été mise à jour depuis dix ans, a été mise à jour, et des milliards de personnes en bénéficieront.
Car, qu'il s'agisse de tri ou de hachage, leurs scénarios d'application peuvent être utilisés dans divers scénarios allant des achats en ligne, du cloud computing à la gestion de la chaîne d'approvisionnement, etc., et ils sont appelés des centaines de millions de fois chaque jour !
Cependant, comme l'a dit DeepMind :
Ne soyez pas trop excité, le pouvoir de l'IA pour améliorer l'efficacité du code ne fait que commencer.

Le "parvenu" de la famille Alpha découvre un algorithme de tri plus rapide
Cette IA s'appelle AlphaDev, qui appartient au "parvenu" de la famille Alpha et est basée sur AlphaZero (l'IA d'échecs qui a vaincu le champion du monde en 2017).
Sa découverte ne repose pas sur des algorithmes existants, mais part des instructions d'assemblage du niveau le plus bas.
Les chercheurs de DeepMind ont conçu pour cela un jeu « d'assemblage » solo :
Tant que vous pouvez rechercher et sélectionner les instructions appropriées (processus A dans la figure ci-dessous), organisez les données correctement et rapidement (processus B dans la figure ci-dessous). figure ci-dessous), vous pouvez obtenir des récompenses.
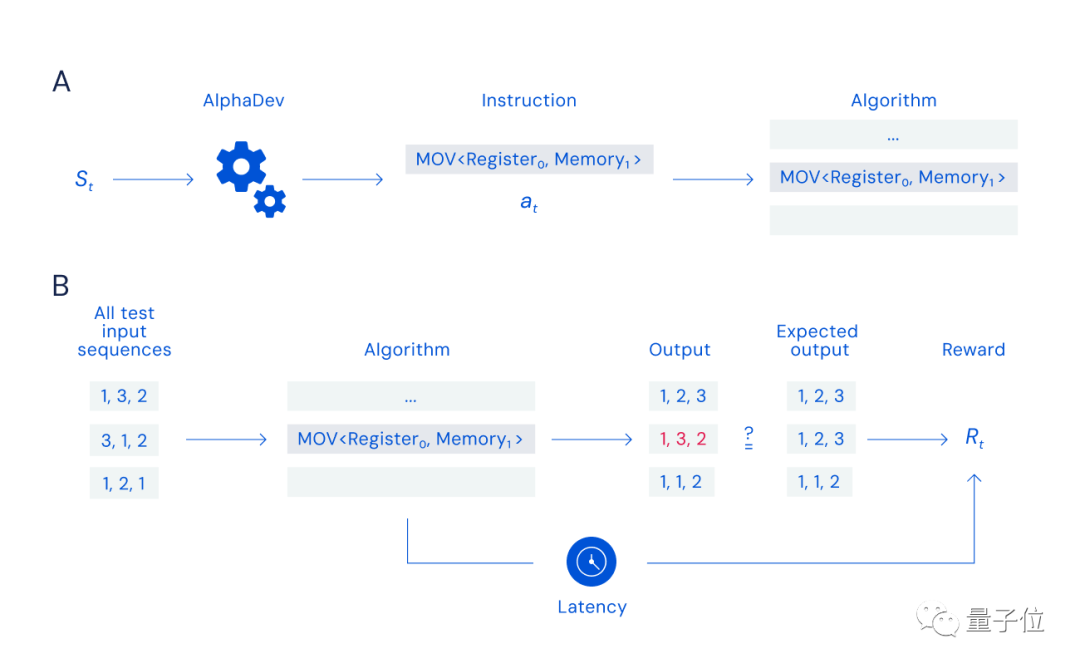
Mais l'enjeu de ce jeu ne réside pas seulement dans la taille de l'espace de recherche (le nombre d'instructions combinables équivaut au nombre de particules dans l'univers), mais aussi dans la nature de la récompense fonction, car une mauvaise instruction peut faire échouer l’ensemble de l’algorithme. Invalide.
AlphaDev comporte deux composants principaux : l'algorithme d'apprentissage et la fonction de représentation.
Parmi eux, l'algorithme d'apprentissage est principalement étendu sur le puissant AlphaZero, qui peut combiner des algorithmes DRL et d'optimisation de recherche aléatoire pour effectuer d'énormes recherches d'instructions ; la fonction de représentation principale est basée sur Transformer, qui peut capturer la structure sous-jacente de l'assembleur. , et exprimé sous la forme d'une séquence spéciale.
Alors qu'AlphaDev continue de combattre des monstres et de se mettre à niveau, les chercheurs limiteront également le nombre d'étapes qu'il peut effectuer et la longueur de la séquence à trier.
Enfin, AlphaDev a découvert un nouvel algorithme de tri :
Si la séquence est courte, elle peut augmenter la vitesse de 70 % par rapport à l'algorithme de tri de base humain, si la longueur de la séquence dépasse 25 000 éléments, elle augmentera de 1,7 % ; .
Le tri par séquence courte est largement utilisé dans la pratique, notamment en tant que composant important de fonctions de tri plus vastes et est appelé plusieurs fois. Tant que les séquences courtes sont améliorées, la vitesse de tri de toutes les séquences peut être améliorée. )
Concrètement, l'innovation de cet algorithme réside principalement dans deux séquences d'instructions :
(1) AlphaDev Swap Move (swap move)
(2) AlphaDev Copy Move (copy move)
Comme le montre la figure ci-dessous, sur la gauche L'implémentation originale sort3 de min(A,B,C) est utilisée. Le côté droit passe par "AlphaDev Swap Move", qui ne nécessite que l'implémentation de min(A,B). On peut constater qu'une étape d'instruction peut être omise et que seule la valeur minimale de A et B doit être calculée.
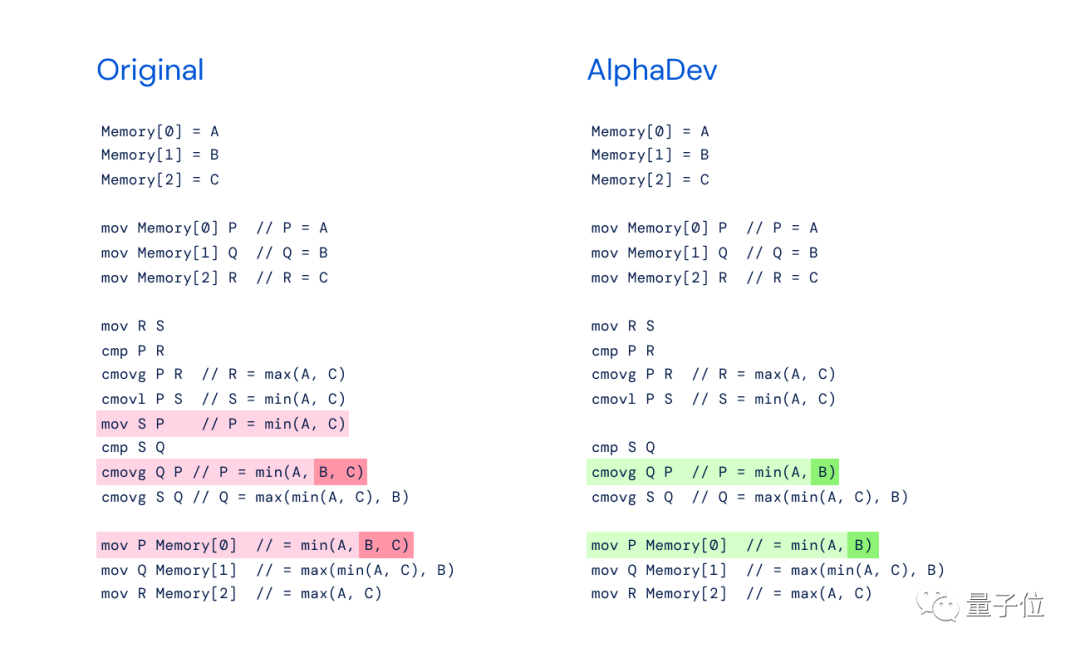
L'auteur a déclaré que cette nouvelle méthode rappelle le "Move 37" d'AlphaGo - une méthode contre-intuitive qui a directement vaincu le légendaire joueur de Go Lee Sedol, choquant le public.
De même, AlphaDev saute une étape en échangeant et en copiant des mouvements, atteignant ainsi l'objectif d'une manière qui semble erronée mais qui est en réalité un raccourci.
Comme le montre la figure ci-dessous, dans l'algorithme de tri de 8 éléments, AlphaDev utilise également "AlphaDev Copy Move" pour remplacer le max plus complexe dans l'implémentation d'origine par max (B, min (A, C)) (B, min (A, C, D)), et le nombre total d'instructions de l'ensemble de l'algorithme est également réduit d'un pas.

Après avoir découvert un algorithme de tri plus rapide, l'auteur a également essayé l'algorithme de hachage avec AlphaDev pour prouver sa polyvalence.
Les résultats n'ont pas déçu, AlphaDev a également obtenu une augmentation de vitesse de 30 % dans la plage de longueur de 9 à 16 octets.
Comme l'algorithme de tri, ils ont intégré la nouvelle méthode dans la bibliothèque Abseil, désormais disponible pour des millions de développeurs à travers le monde.
Enfin, l'auteur a déclaré que la mise en œuvre de deux nouveaux algorithmes montre qu'AlphaDev a une forte capacité à découvrir des solutions originales, et nous fera réfléchir davantage à la manière d'améliorer les algorithmes de base dans le domaine informatique.
Cependant, en raison des limites du langage assembleur utilisé dans cette étude, ils prévoient ensuite d'essayer la capacité d'AlphaDev à optimiser les algorithmes dans des langages de haut niveau (tels que C++).
Internautes : Sans compter la découverte d'un nouvel algorithme de tri
Beaucoup de personnes sont très enthousiasmées par cette réalisation.
Comme l'a dit cet internaute :
Après qu'AlphaGo ait étonné le monde, que peut faire d'autre l'apprentissage par renforcement ? Peut-on faire quelque chose d’important d’un point de vue pratique ? C'est la réponse.

Mais cette fois, de nombreuses personnes ont souligné que DeepMind semblait soupçonné d'exagérer le titre.
Il calcule le retard de l'algorithme, et non la complexité temporelle au sens traditionnel. Si vous calculez réellement la complexité temporelle, les données risquent de ne pas paraître bonnes.
Son amélioration ne réside pas dans l'algorithme de tri lui-même, mais dans une nouvelle optimisation du tri pour les processeurs modernes (notamment pour les séquences courtes). Cette approche est en fait très courante. Par exemple, des bibliothèques telles que FFTW et ATLAS ont adopté cette méthode.

D'accord, ils viennent de trouver une optimisation machine plus rapide pour un processeur spécifique, pas un nouvel algorithme de tri, la méthode elle-même est cool, mais pas une recherche révolutionnaire.

Qu'en pensez-vous ?
Adresse papier :https://www.php.cn/link/a3fefe83288ecb0e40ebe40b2bde29fe
Blog officiel :https://www.php.cn/link/f5b2aa928f940f3f09a0d14f45a27875
Lien de référence :
[1]https https://www.php.cn/link/5383c7318a3158b9bc261d0b6996f7c2
[2]https://www.php.cn/link/ecf9902e0f61677c8de25ae60b654669
[3]https://www.php.cn/ lien /0383314bf626052313b8275638fcccce
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI