
Maison >Opération et maintenance >Sécurité >Du point de vue du CTO : Comment développer les capacités d'exploitation et de maintenance/SRE
Du point de vue du CTO : Comment développer les capacités d'exploitation et de maintenance/SRE

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-09 12:37:08937parcourir

Récemment, de nombreux articles ont abordé la question de savoir s'il fallait ou non conserver les postes d'exploitation et de maintenance. Le compte officiel SRETalk que j'ai hébergé a également publié les opinions de nombreux directeurs d'exploitation et de maintenance que j'ai personnellement. J'ai également discuté avec de nombreuses personnes de l'industrie. Après quelques échanges, j'ai quelques petites réflexions et je les ai enregistrées pour référence par les CTO/CIO. En tant qu'opération et maintenance/SRE, si vous vous sentez confus, je vous recommande également de lire attentivement cet article. .
Je pense que c'est une réflexion en profondeur, c'est peut-être ennuyeux, mais cela sera utile pour le choix de carrière et la constitution d'une équipe. Cet article accueille des discussions fondées, mais n'accepte pas l'arrogance. De plus, beaucoup de choses ne sont pas noires et blanches. C'est formidable si le contenu de l'article peut vous inspirer et apporter une nouvelle réflexion à la prise de décision des CXO.
De plus, l'entretien de SRETalk avec le directeur des opérations et de la maintenance se poursuivra, et d'autres opinions différentes continueront d'être émises pour votre référence. Mon opinion n'est pas nécessairement correcte et est à titre de référence uniquement.
À propos du titre
Tout d'abord, permettez-moi de parler du titre, "Comment créer des capacités d'exploitation et de maintenance/SRE". Ici, je n'écris pas sur la constitution d'une équipe, mais sur le renforcement des capacités, car la réalisation de certains. Les objectifs ne nécessitent pas nécessairement la constitution d'une équipe auto-construite. Du point de vue des coûts et des résultats. Du point de vue de la prévisibilité et de l'investissement à long terme dans la maintenance, une prise de décision prudente est nécessaire. Si la décision est mauvaise, l'avenir sera un désastre. désordre. Cela sera discuté plus tard.
À propos de l'équipe d'exploitation et de maintenance/SRE
Un autre point doit être clarifié à l'avance. L'équipe d'exploitation et de maintenance/SRE mentionnée dans l'article est toutes au service de l'entreprise, et le succès de l'entreprise est la première priorité. Certaines équipes d'exploitation et de maintenance ont fabriqué certains produits et les ont exportés pour une commercialisation externe, ce qui est devenu une entreprise en soi. D'ailleurs, d'après mon expérience chez mon ancien employeur, l'approche de l'équipe d'exploitation et de maintenance (externe). sortie de commercialisation) n'est pas conseillé, en particulier dans une entreprise qui ne possède pas de gènes ToB et n'a pas de construction d'organisation ToB correspondante.
Où obtenir des capacités d'exploitation et de maintenance/SRE
Puisque tout est pour le succès de l'entreprise (quelle que soit l'entreprise, seulement si vous pouvez être promu ou si vous pouvez tromper votre patron est une autre affaire), concentrons-nous sur ce que sont l'exploitation et la maintenance. nécessaires à l'entreprise Capacités (expliquées en détail plus tard), où avez-vous besoin d'obtenir ces capacités d'exploitation et de maintenance. Il existe trois méthodes d'acquisition typiques ?
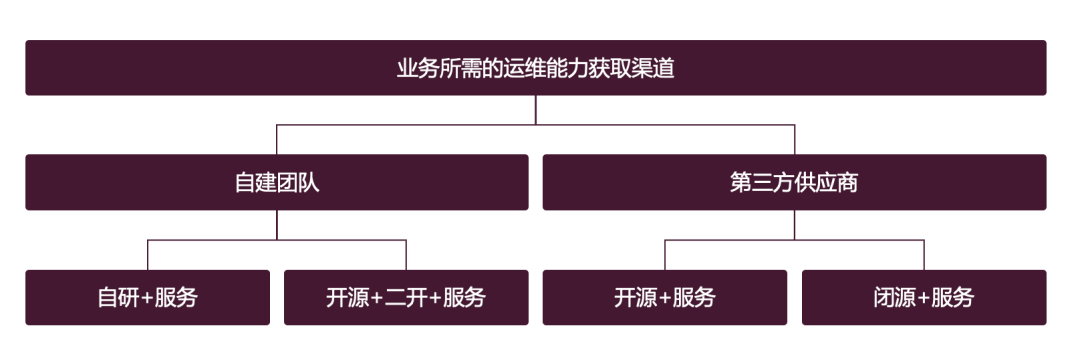
Équipe auto-construite
La première consiste à fournir des capacités pertinentes grâce à une équipe auto-construite. Cette méthode est la plus familière à tout le monde. Les livrables commerciaux de l'équipe auto-construite comprennent généralement deux parties : produits +. services. Parlons d'abord du produit :
- Si les besoins du produit sont des besoins généraux, le produit est très probablement un projet open source qui peut être utilisé directement. Il est nécessaire de prendre en compte la durabilité du projet open source (si les développeurs du projet open source bénéficient d'une aide aux revenus de sociétés commerciales, la plupart des projets open source personnels mourront sans revenus), l'activité (le projet n'a-t-il pas été mis à jour depuis de nombreuses années ? Les problèmes et les PR soulevés ? Traitement dans les délais ? Généralement, le traitement dans un délai d'une semaine peut être considéré comme actif), la prospérité écologique (y a-t-il beaucoup de personnes qui participent aux contributions ? De nombreuses entreprises l'utilisent ?) ? Si le code de développement secondaire peut être fusionné avec le tronc principal, cela signifie généralement que le code de développement secondaire est universel et a été reconnu par l'équipe du projet open source. S'il ne peut pas être fusionné avec le tronc principal, la maintenance ultérieure sera difficile, surtout après le changement de talent. Il est généralement possible de créer du code colle basé sur l'API du projet open source et de l'intégrer au système interne. Après tout, le code open source n'a pas été modifié et les mises à niveau ultérieures du projet open source peuvent toujours être conservées. Bien sûr, il existe également des bibliothèques entièrement auto-développées qui n'utilisent pas l'open source (utilisez simplement certaines bibliothèques de bibliothèques open source, la logique de base du produit est auto-développée), vous devez être prudent à ce sujet si la communauté open source. n'a pas de produits associés, vous ne pouvez le développer que par vous-même. Cependant, après une auto-recherche, vous devez considérer la question de la maintenance à long terme. Le personnel de R&D aime généralement le faire à partir de zéro. alors les avantages seront faibles et les promotions et les augmentations de salaire ne seront pas possibles, il sera donc facile de changer. En ce qui concerne l'exploitation et la maintenance, la communauté open source propose une gamme éblouissante de produits, et il se peut qu'il n'y ait qu'une poignée de produits qui nécessitent un auto-développement, alors réfléchissez-y à deux fois.
- Le deuxième est le service. Le soi-disant service fait ici référence à l'expérience experte exportée vers le côté commercial. Par exemple, si une équipe auto-construite crée un produit de surveillance, cette équipe doit transmettre les meilleures pratiques de surveillance aux « clients » internes de l'entreprise. Lorsque des problèmes surviennent avec le produit de surveillance, cette équipe doit les résoudre rapidement. En effet, les équipes middle et back-end au sein de l’entreprise doivent avoir un sens aigu du service et comprendre les meilleures pratiques du secteur, sinon elles se laisseront facilement guider par le business et iront dans la direction opposée aux meilleures pratiques. dans l’industrie, tout est un problème.
-
Le cœur du service repose sur les personnes (bien sûr, c'est formidable si vous pouvez consolider les meilleures pratiques dans les produits). En tant que manager, si vous voulez que cette équipe fournisse de bons services, vous devez prendre en compte les problèmes de nombreuses personnes. tels que : si les talents pertinents peuvent être recrutés, si les talents pertinents peuvent être retenus (espace de développement, salaire, etc.), au moins deux personnes dans chaque direction de l'équipe auto-construite peuvent se compléter, et si le coût peut être offert.
Fournisseurs tiers
Obtenir des capacités d'exploitation et de maintenance auprès de fournisseurs tiers est une autre manière. Les livrables du fournisseur comprennent évidemment deux parties : produits + services. Les produits sont divisés en deux types : open source et fermé. Quelles sont les considérations ?
- Les produits open source ont généralement plus d'utilisateurs et plus de scénarios à peaufiner, mais certaines exigences à longue traîne ne sont généralement pas open source. Quant à la raison, soit l'équipe open source traite ces exigences à longue traîne comme des éléments de facturation, soit l'équipe open source traite ces exigences à longue traîne comme des éléments de facturation. L'équipe open source estime que ces exigences à longue traîne ne sont pas assez générales et ne valent pas la peine d'être intégrées au produit.
- Les produits fermés ont généralement un petit public, et il n'y a pas beaucoup d'utilisateurs open source pour aider à peaufiner les produits, ils doivent donc être peaufinés par des clients commerciaux pendant une longue période, ou les fournisseurs de produits fermés ont un très fort système de gestion de la qualité, ce qui n'est pas bon pour eux. Si le produit est entièrement testé, vous devez trouver des fournisseurs auprès de grandes entreprises. De plus, les testeurs et les utilisateurs finaux sont après tout deux groupes de personnes. si le fournisseur dispose d'une équipe d'assurance qualité solide, ce processus de polissage sera plus court.
- Qu'il soit open source ou fermé, le fournisseur est livré avec le produit. En tant que partie A, vous pouvez le tester directement pour voir comment le produit correspond et obtenir rapidement des commentaires. Cependant, si vous constituez une équipe auto-construite, cela est possible. peut prendre plusieurs personnes, le développement prend des mois, voire un ou deux ans, et l'entreprise peut ne pas être en mesure d'attendre. La question de savoir si le produit répond réellement aux attentes après le développement est déterminée par de nombreux facteurs, et les résultats sont imprévisibles.
Le deuxième est le service. Les fournisseurs ont généralement des avantages par rapport aux équipes auto-construites. Les raisons sont les suivantes :
- Parce que les fournisseurs ont vu davantage de scénarios de clients et que la société ToB, l'accumulation à long terme de savoir-faire dans l'industrie est au cœur de la compétitivité de cette entreprise. Les fournisseurs continueront à apprendre l'expérience d'excellents clients et à se nourrir. Pour les clients les moins avancés, un cercle vertueux et une situation gagnant-gagnant pour toutes les parties.
- C'est aussi parce que les fournisseurs ont vu plus de scénarios et peuvent faire de meilleures abstractions pour les produits, rendant les produits plus polyvalents et ressemblant davantage à un produit. Les produits fabriqués par des équipes auto-construites sont généralement plus orientés vers les outils. généralement.
- La raison pour laquelle les fournisseurs créent des entreprises dans le domaine de l'exploitation et de la maintenance est probablement parce qu'ils ont réalisé des progrès dans ce domaine. Par rapport aux équipes auto-construites, les fournisseurs ont généralement de meilleures connaissances de haut niveau lorsque vous recrutez réellement des personnes. découvrira que le groupe de personnes le plus puissant a soit lancé une entreprise, soit que celle-ci coûte trop cher, soit qu'ils ne veulent pas venir.
Parlons également de la question des coûts. Les tarifs du fournisseur sont probablement plus rentables que le recrutement soi-même (à condition de recruter les bonnes personnes). Sinon, la logique business ne tiendra pas. Ce principe est évident et ne sera plus répété.
Obtenir des capacités d'exploitation et de maintenance auprès de fournisseurs tiers semble être un défi pour les équipes auto-construites, alors avez-vous quand même besoin de lire les articles suivants ? En fait, ce n'est pas nécessairement le cas. Pour une certaine capacité d'exploitation et de maintenance, ce qui est plus important, c'est la capacité du produit ou la capacité de service. Ce dont vous avez le plus besoin, c'est de la capacité du produit ou de la capacité de service. Plus tard, je l'examinerai du point de vue commercial. Tous les aspects des capacités d'exploitation et de maintenance sont démantelés séparément.
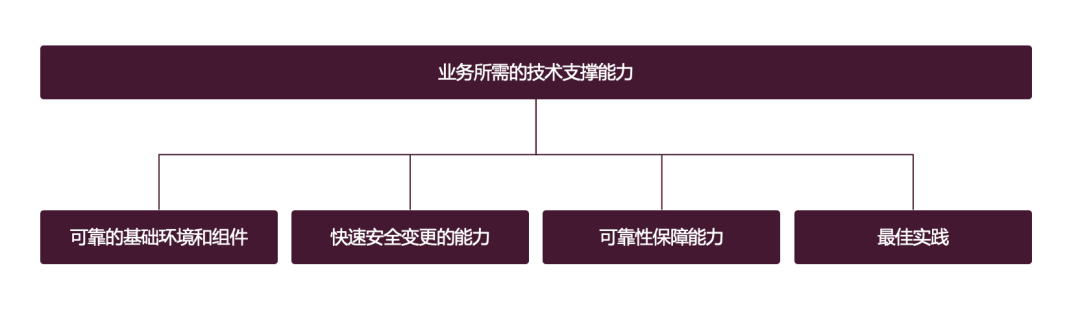
Quelles capacités de support technique sont nécessaires pour l'entreprise ?
L'exploitation et la maintenance sont essentiellement un type de capacités de support technique, qui est très similaire à l'équipe d'infrastructure. Certaines d'entre elles peuvent être intégrées à l'équipe d'exploitation et de maintenance, et cela. ce n'est pas un gros problème de les mettre dans l'équipe d'infrastructure. Certains même L'entreprise place directement ces personnes dans l'équipe R&D de l'entreprise. Ignorons la division du travail pour le moment et déterminons d'abord quels types de capacités de support technique l'entreprise. exige.

Cette image explique en fait très bien le problème. Laissez-moi développer un peu plus :
- Environnement et composants de base fiables : Pour exécuter des programmes d'entreprise, vous avez besoin de réseaux, de matériel, de systèmes d'exploitation, de bases de données, de middleware, etc. de base. Ces environnements et composants doivent être stables et fiables
- La capacité de changer rapidement et en toute sécurité : Le capacité à changer rapidement, tout le monde C'est facile à comprendre. En tant que développeur, lorsque vous écrivez une fonctionnalité ou corrigez un bug, vous voulez absolument la livrer rapidement, mais les changements peuvent facilement conduire à des échecs, les changements doivent être contrôlés et des besoins de sécurité sont nécessaires. être assuré autant que possible
- Capacités d'assurance de fiabilité : déploiement de logiciels vers Après l'environnement de production, vous pouvez rencontrer divers problèmes Comment quantifier les risques à l'avance, comment découvrir rapidement les problèmes, localiser les problèmes et arrêter les pertes rapidement. être la demande la plus importante du côté commercial vers le côté exploitation et maintenance
- La meilleure pratique la plus importante : l'entreprise s'appuie sur de nombreuses capacités de support de base. Comment ces capacités sont-elles utilisées ? Est-ce une bonne pratique de l’industrie ? Est-ce une bonne pratique pour la plupart des autres opérations au sein de l’entreprise ? Une équipe de support de base est nécessaire pour donner un retour à l'entreprise
Comment obtenir chaque capacité
Comment obtenir les quatre capacités mentionnées ci-dessus ? Maintenant, décomposons-le, décomposons-le et parlons-en.
Environnement et composants de base fiables
Tout d'abord, parlons de l'environnement matériel de base. Évidemment, il existe deux options, cloud ou auto-construit. Si la politique exige que vous deviez le faire vous-même, il n'y a aucun moyen. La politique prévaudra. Si vous pouvez choisir vous-même, à cette époque, il est plus probable qu'il soit plus approprié d'aller vers le cloud. À moins que l'entreprise ne soit très grande et dispose de beaucoup de machines, la construire vous-même peut avoir un avantage. Notez que ce que je dis ici est possible Lors du calcul des coûts, n'oubliez pas d'inclure les coûts de main-d'œuvre, pas seulement les coûts de matériel.
À propos du choix de carrière : Cela ne semble pas être une bonne nouvelle pour les ingénieurs d'exploitation et de maintenance de systèmes et les ingénieurs d'exploitation et de maintenance de réseaux. L'émergence du cloud a en effet pris de la place pour certains de ces postes. Les roues du temps avancent, tout le monde C'est toute la poussière de l'histoire.
Parlons de composants, tels que MySQL, Redis, MongoDB, Kafka, ElasticSearch, Nginx, Kubernetes, etc. Il existe évidemment trois options, utiliser des produits cloud PaaS ou le faire vous-même ou fournir votre propre matériel + fournisseurs à fournir solutions et services. Pour chaque choix, nous ferons respectivement un examen :
- Produits Cloud PaaS : Si l'échelle est petite et qu'il n'y a pas de réserve de talents pertinente, il est plus approprié d'utiliser les produits Cloud PaaS. Vous pouvez rapidement développer des capacités et choisir d'utiliser. La partie cloud A qui achète des produits PaaS utilise généralement déjà des machines virtuelles sur le cloud et des environnements d'exécution de type Kubernetes. Il est également relativement simple d'acheter des produits PaaS et il n'est pas nécessaire de se connecter à de nouveaux fournisseurs.
- Faites-le vous-même : Si un certain composant est très volumineux, il peut être nécessaire de le construire vous-même, comme Kafka, embauchez 2 personnes, un maître et une sauvegarde. Le niveau n'est pas mauvais, et vous pouvez. soyez sûr de tout si quelque chose ne va pas. Si vous êtes à Pékin Le coût annuel est d'environ 1 million. À quelle échelle pouvons-nous économiser cet argent sur le matériel et les composants ? Bien sûr, vous pouvez également recruter des ingénieurs d'exploitation et de maintenance à faible coût (c'est moi qui souligne, des ingénieurs d'exploitation et de maintenance peuvent être nécessaires ici, mais le rang n'est pas élevé), qui peuvent résoudre les problèmes quotidiens, mais ne peuvent pas résoudre des problèmes élevés. Problèmes de haut niveau. Pour les problèmes de haut niveau, vous pouvez demander une aide externe au service expert des fournisseurs.
- Produisez votre propre matériel + les fournisseurs fournissent des solutions et des services : par rapport aux produits PaaS des fournisseurs de cloud, les fournisseurs tiers sont généralement plus rentables et répondent plus rapidement. Cependant, il y a tellement de composants que chaque fournisseur ne peut gérer qu'un seul. nombre limité de produits. Pour plusieurs modèles, en tant que partie A, vous devrez peut-être traiter avec plusieurs fournisseurs en même temps, ce qui est un peu gênant. Pour les produits qui nécessitent une collaboration entre cloud, tels que la surveillance unifiée, la localisation des pannes et les produits liés au FinOps, si l'entreprise utilise plusieurs cloud ou une architecture de cloud hybride, il est fort probable qu'un fournisseur tiers soit plus approprié.
À propos du choix de carrière : pour les experts seniors dans divers composants, le premier choix est de travailler pour un fabricant de cloud ou de démarrer une entreprise pour exporter l'expérience, et le deuxième choix est d'aller dans une grande usine qui construit ses propres composants . Dans les petites et moyennes usines ordinaires, il est difficile d'obtenir des salaires élevés, après tout, les services d'experts tiers sont très rentables.
La capacité de changer rapidement et en toute sécurité
Les modifications les plus courantes apportées par la R&D en entreprise sont les modifications binaires et de configuration, et bien sûr, il existe également des modifications de l'environnement et des composants de base.
Parlons d'abord des changements binaires et de configuration. Comment pouvons-nous itérer rapidement et en toute sécurité ? Cela peut se faire par étapes. Lorsque l’entreprise est encore relativement petite, il n’est pas nécessaire de prêter trop d’attention à la construction des outils. Il suffit de définir les spécifications et les processus. Aspects standards tels que : sous quel compte est déployé, sous quel répertoire, comment placer les journaux, comment héberger le processus, toutes les modifications doivent pouvoir être déployées, etc. Aspects de processus tels que : mécanisme de notification de modification, mécanisme de collaboration en ligne multi-modules et non-rollback Il doit y avoir un mécanisme d'approbation et ainsi de suite.
Ensuite, vous devez disposer de données quantitatives sur les changements historiques, telles que le nombre de changements qu'une certaine équipe a apportés au cours du dernier trimestre, quel est le taux de restauration et quel est le taux d'échec de chaque équipe. ne faites pas bien échouera au prochain trimestre. Bien amélioré.
Lorsque l'entreprise continue de croître, elle peut investir de la main-d'œuvre pour construire une plate-forme de changement, mettre en œuvre des systèmes standardisés sur la plate-forme et produire des données quantitatives, car différentes entreprises ont des situations différentes à l'ère des machines physiques traditionnelles et des machines virtuelles. , Il est rare de voir un système de changement commercial. Bien entendu, après l’essor de Kubernetes, de nombreuses différences sous-jacentes ont été masquées. La plate-forme permettant d’effectuer des modifications basée sur Kubernetes est devenue beaucoup plus polyvalente et des produits associés ont commencé à apparaître.
Les modifications apportées à l'environnement de production ne sont pas les mêmes que les modifications apportées à l'environnement de test et à l'environnement de débogage conjoint. L'environnement de production a des exigences de stabilité plus strictes, tandis que l'environnement de test et l'environnement de débogage conjoint ont des exigences relativement faibles. Les systèmes dits CI/CD sont principalement conçus pour les environnements de test et les environnements de débogage communs. Seule une poignée d'entreprises peuvent implémenter le CD pour les environnements de production.
Focus sur : le système CI/CD pour les environnements de test et de débogage conjoints vise davantage à accélérer l'efficacité de la R&D, le système de changement pour l'environnement de production vise davantage à assurer la stabilité ; et la mise en œuvre de systèmes standardisés. L'entreprise est petite au début, il suffit donc de s'appuyer sur des règles et des réglementations. Plus tard, elle aura besoin de règles et de réglementations + d'une plateforme de changement pour travailler ensemble.
Qui déterminera ce système de régulation ? Qui développera la plateforme de changement ?
La formulation des spécifications en est en fait à ses débuts. Peut-être que les spécifications sont déjà en place avant que l'équipe d'exploitation et de maintenance n'existe. Il est donc très probable que le CTO et le subordonné. L'équipe de base les formulera. S'il n'a pas été formulé auparavant, le Directeur des Opérations et de la Maintenance (Le Directeur des Opérations et de la Maintenance arrive ) peut prendre les devants dans sa formulation, et l'équipe Core sous le CTO l'examinera (tout le monde a la participation), et enfin le CTO prend la décision (de haut en bas) et la publie, et tout le monde l'exécute.
Il est relativement approprié que le développement de la plateforme de changement soit développé par l'équipe d'exploitation et de maintenance. Plus tard, nous introduirons d'autres plateformes et mettrons en place une équipe d'exploitation et de maintenance dédiée (l'exploitation et la maintenance). la maintenance et le SRE dont je parle ici ne sont pas la différence, vous pouvez aussi appeler cette équipe l'équipe SRE) est appropriée. Changer de plate-forme nécessite la mise en œuvre des spécifications de l'entreprise, de sorte qu'il y a relativement peu de cas d'externalisation une fois que l'entreprise a atteint une certaine échelle, l'auto-recherche et l'accumulation basées sur des éléments open source sont un choix très probable.
À propos de la sélection de carrière : La gestion du changement est une partie importante de l'entreprise et sert également le système de stabilité. Il s'agit d'un poste DevOps typique, et le plafond est probablement au niveau P7+ (une opinion purement personnelle, à titre de référence uniquement).
L'autre est le changement des composants de base et de l'environnement, généralement tels que la structure des tables MySQL, la configuration Nginx, DNS, VIP, etc. De tels changements peuvent être internalisés dans le composant gestion et contrôle Dans la plate-forme, laissez les fournisseurs de capacités de composants fournir des entrées de changement ainsi que des capacités de gestion et de contrôle.
Capacité de garantie de fiabilité
Cette capacité est très importante SRE est l'abréviation de Site Reliability Engineering, c'est-à-dire ingénierie de fiabilité du site. Du point de vue du CTO, lorsque le logiciel est déployé dans l'environnement de production, divers problèmes peuvent survenir à l'avenir. Nous espérons disposer d'un système d'ingénierie pour garantir la fiabilité. Il s’agit d’un sujet énorme, et cet article n’entrera pas dans les détails, il se contentera de clarifier ce que c’est et qui en est responsable.
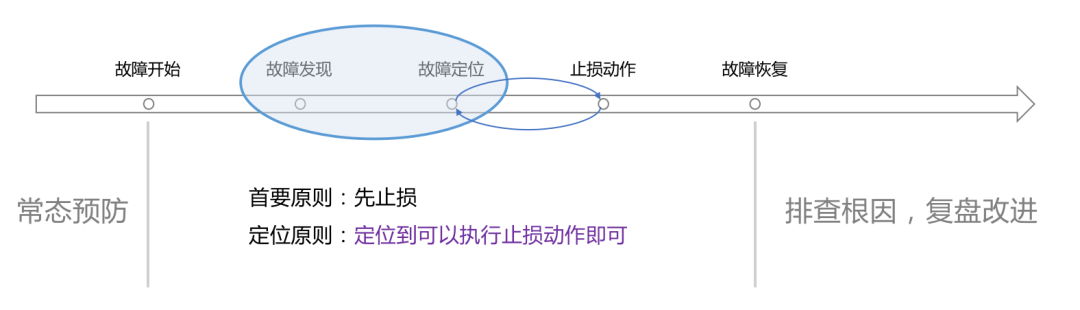
La soi-disant fiabilité est le processus de lutte contre les pannes. Par conséquent, nous regardons toujours le cycle de vie des pannes, en commençant par chaque maillon du cycle de vie, pour vaincre la panne, ou même directement. éliminez-le Étouffé dans le berceau.
La panne commence avant que la chute ne se produise
#🎜🎜 #avantIl y a beaucoup de travail à faire en matière de prévention et de maîtrise des risques. Par exemple : formuler des normes d'exhaustivité des alarmes et effectuer des évaluations quantitatives de chaque secteur d'activité ; formuler des principes et des processus de positionnement ainsi que des normes de classification des défauts et de responsabilité ; trier à l'avance la correspondance entre les fonctions principales et les modules de service de chaque entreprise, et établir une vue globale de la stabilité ou la salle de guerre est utilisée pour identifier rapidement les modules ou interfaces défectueux ; Il y a ici certaines choses qui nécessitent de la recherche et du développement commercial, comme l'optimisation de l'architecture. Pour le reste, ma suggestion est la suivante :Laissez l'équipe d'exploitation et de maintenance prendre les devants. , et la R&D coopère. Par exemple, l'équipe principale relevant du CTO aura très probablement à la fois un poste d'exploitation et de maintenance et un poste technique pour chaque entreprise. En nom, le CTO prendra la décision, autorisant le poste d'exploitation et de maintenance à prendre la direction, et le CTO. Poste de R&D permettant à chaque entreprise de coopérer. Bien entendu, lorsqu'il s'agit d'opérations réelles, le poste n°1 d'exploitation et de maintenance peut trouver une personne compétente pour effectuer l'opération réelle à l'avenir, et chaque secteur d'activité peut également avoir des personnes qui comptent. sur le poste technique n°1 pour assurer le support d’interface.
À l'exception de l'optimisation de l'architecture, ces autres choses sont toutes des questions horizontales. Il peut y avoir des méthodologies et des bonnes pratiques pour rassembler tout le monde et faciliter le partage. . Bien sûr, certaines personnes se poseront des questions : pouvons-nous trouver directement quelqu'un de l'équipe R&D pour former une organisation virtuelle aussi stable et promouvoir conjointement ce sujet ? En fait, vous pouvez l'essayer. Mais il y aura quelques problèmes :- Chaque secteur d'activité ne compte généralement qu'une ou deux personnes d'interface. Avec moins de personnes et plus de travail, cette personne aura probablement du mal à équilibrer le développement du code métier et le travail de stabilité. Si cette personne fait de la stabilité à temps plein, elle est en fait équivalente à. un SRE
- S'il s'agit de SRE, le système d'évaluation est en réalité différent de celui du personnel R&D de l'entreprise. Comment déterminer les KPI ? Et cette personne n'a peut-être pas un bon sentiment d'appartenance
- Si cette personne s'occupe de deux choses en même temps : la stabilité et la recherche et le développement des entreprises, cela peut provoquer l'inertie des gens. Lorsque le travail de stabilité rencontre des problèmes, ils voudront naturellement le faire. Allez faire des travaux de recherche et développement en entreprise. Lorsque la recherche et développement en entreprise rencontre des problèmes, vous voulez être paresseux et faire un travail de stabilité
Focus : prévention et contrôle des risques au préalable, veuillez trouver le directeur d'exploitation et de maintenance à obtenir. les résultats, mais il faut faire preuve d'une grande coopération et pousser de haut en bas. Pour que le rôle d'ingénieur SRE résolve ce problème, il semble qu'une personne de haut niveau très professionnelle soit nécessaire. Il y a une forte probabilité que les compétences cognitives ne puissent pas suivre dans les 5 ans de travail. Peut-être en recrutant SRE dans l'équipe senior de R&D. est un bon choix. Les CXO peuvent essayer.
Réduire l'impact après le début de l'échec
Une fois qu'un échec survient, notre objectif principal devient de réduire l'impact. Les équipes concernées ont immédiatement collaboré pour localiser rapidement la cause directe, arrêter rapidement le sinistre, puis enquêter lentement sur la cause profonde. Le contenu de travail suivant sera impliqué ici :
- Définir les défauts : Habituellement, des problèmes avec les indicateurs commerciaux signifient que des défauts ont commencé, comme une baisse du volume de commandes, une baisse du volume d'appels de covoiturage et une baisse du volume de paiement. Le patron accordera une attention particulière à ces indicateurs ; cependant, si le processeur d'une certaine machine est si élevé ou si le disque est plein, il peut s'agir simplement d'un problème digéré en interne par l'équipe. Même les systèmes de type K8 peuvent résoudre automatiquement la dérive. des problèmes qui n'ont généralement aucun impact sur le processus principal du client et dont le patron n'y prête pas attention. Afin de ne pas se tromper, il faut distinguer la définition des défauts et des problèmes. Les différents métiers ont des indicateurs différents, mais la méthodologie globale est la même.
- Réponse aux pannes : le destinataire de l'alarme de panne est-il destiné à la recherche et au développement d'une entreprise ? Ou SRE ? Ou un centre OnCall ? Différentes entreprises ont d'énormes différences dans leurs pratiques. Mon idée personnelle est : envoyez-le directement à ceux qui sont capables de le gérer ! Il n'y a pas de noir et blanc. Différentes alarmes ont des mécanismes de traitement différents. Par exemple, s'il y a un problème avec le réseau de base, il sera évidemment envoyé à l'ingénieur réseau. S'il y a un problème avec une certaine entreprise, ce sera le cas. envoyé à l'exploitation, à la maintenance et à la R&D correspondantes. Essayez de ne pas le transférer à nouveau au milieu, envoyez-le à Zhang San et contactez Li Si. Ce serait une perte de temps. être fait contre la montre.
- Localisation rapide : un système de localisation de pannes efficace est une tuerie. Les systèmes de localisation de défauts sont généralement construits sur la base de données d'observabilité et peuvent être considérés comme des produits au niveau du cockpit. Les données d’observabilité sont massives. Sans tri et utilisation, ces données massives ne peuvent pas être transformées en informations précieuses. Du point de vue du positionnement, ce qui est généralement requis est : un système d'observabilité + une localisation des défauts + un fonctionnement continu. Il y a trop de contenu pour développer ici. Si vous souhaitez en discuter en détail, vous pouvez me contacter. Vous ne savez pas comment me contacter ? Compte officiel SRETalk, en savoir plus.
- Stop loss rapide : Pour arrêter les pertes rapidement, vous devez disposer d'un plan complet lors de l'examen de chaque panne, il est recommandé que le CTO et le directeur de l'exploitation et de la maintenance prêtent attention à l'efficacité du plan, c'est-à-dire si la panne est réelle. un plan existant Pour stopper les pertes, cela reste une solution pour économiser de l’argent. S'il est enregistré maintenant, cela signifie que votre plan n'est pas suffisamment complet.
OK, ce qui précède est plein d'enthousiasme, mais revenons à la question, pour ce travail, à qui le CTO devrait-il demander les résultats ? Ma suggestion est la suivante : équipe SRE (les mots exploitation et maintenance et SRE apparaissent plusieurs fois dans cet article, et ils signifient fondamentalement la même chose dans cet article. Ici, l'exploitation et la maintenance ne sont pas seulement des opérations). Évidemment, SRE ne peut pas résoudre tous les défauts. Il faut dire que la plupart des défauts doivent reposer sur des personnes d'autres équipes, mais le CTO ne peut pas toujours s'adresser à l'équipe A et à l'équipe B. Par conséquent, SRE doit porter l'épée de Shang Fang du CTO et prendre la tête de la construction globale de la stabilité. Chaque entreprise a besoin de la meilleure coopération de l'interface d'exportation. La soi-disant construction de stabilité comprend un contrôle préventif des risques et une coordination globale lors de l'incident. , et la reprise post-événement. L'avancement du marché est également la plus grande valeur du SRE pour l'entreprise.
Bonnes pratiques
Il existe de nombreux contenus, tels que le modèle de package le plus approprié, la méthode de mise en réseau la plus adaptée et les composants sur lesquels l'entreprise a un meilleur contrôle et peut obtenir un meilleur support (qu'il s'agisse d'un support interne). équipes ou fournisseurs tiers), quels sont les langages et frameworks de programmation recommandés voire exigés par l'entreprise, et quelles sont les solutions de couche d'accès recommandées par l'industrie ? Quel est le projet de changement ? Comment faire de l'observabilité ? Attends, attends.
Il est indéniable que ces méthodes pratiques d'une équipe R&D d'une grande entreprise sont bien comprises, mais il est également indéniable qu'une fois qu'il y aura plus de métiers, le niveau variera entre le bon et le mauvais. Une équipe avec un faible niveau aura forcément besoin de quelqu'un. avec un rôle de coaching, et rien ne se passera. Allez trouver le CTO En tant qu'équipe technique horizontale, l'équipe SRE est particulièrement adaptée pour prendre en charge ce dossier. Mais évidemment, il s'agit d'un poste haut de gamme qui ne peut pas être pourvu par de nouveaux arrivants. Recruter des personnes de haut niveau pour faire des affaires avec BP est un moyen efficace de promouvoir l'unification de la pile technologique si le CTO n'utilise pas ce point de départ. eh bien, le système technologique va prospérer. Derrière se cachent divers dilemmes de gouvernance.
Les quatre capacités de support ci-dessus, comment le côté commercial doit-il les obtenir, comment le CTO doit-il se coordonner, comment les différentes équipes doivent coopérer, c'est tout. Faisons deux autres résumés ci-dessous.
Résumé 1 : Comment le CTO peut-il aider le métier à obtenir ces capacités d'accompagnement ?
Évidemment, le CTO n'a pas besoin de tout faire lui-même, mais le CTO doit faire un bon travail de vérification des choses. Le CTO doit émettre des politiques et être le commandant en chef de toute l'armée. Le travail horizontal est laissé à l'équipe SRE et le personnel d'interface de chaque équipe travaille dur pour coopérer. Il s'agit très probablement d'une bonne pratique. Si les objectifs de travail horizontaux sont complètement dispersés dans la boucle auto-fermée de l'équipe commerciale, vous ne pourrez pas profiter de la capacité de diffusion de l'expérience apportée par l'équipe horizontale. De plus, la crosse détermine la tête, et si vous n'êtes pas dans la bonne position, vous ne pourrez pas faire ce que vous voulez. Chaque entreprise a tendance à avoir son propre petit quatre-vingt-dix-neuf. L'organisation horizontale du centre l'est également. un mécanisme pour abattre les vassaux Désolé d'utiliser ce mot trop fortement, l'intention est bonne, vous devez en faire l'expérience par vous-même.
De plus, je voudrais ajouter un peu plus sur le sujet du FinOps, c'est aussi une capacité horizontale. Doit-il également être laissé au SRE ? Ce n'est pas nécessairement le cas. Je pense qu'il est bon de laisser l'entreprise boucler la boucle. L'entreprise elle-même est responsable des profits et des pertes. Les dépenses informatiques représentent l'essentiel des dépenses. Le PDG de l'entreprise devrait s'en préoccuper. bénéfice net pour le directeur général de l'entreprise. Le directeur général de l'entreprise peut faire un bon travail de compromis.
Résumé 2 : Suggestions de choix de carrière en opérations/SRE
Si vous n'avez pas de niveau d'emploi et d'attentes salariales trop élevés, vous pouvez effectuer des travaux relativement basiques en opérations. Il y a de fortes chances que ce poste ne disparaisse pas. 10 ans. Si vous avez des attentes plus élevées en matière de rang et de salaire, c'est un moyen efficace d'approfondir un certain créneau et de devenir un expert du secteur. Après cela, il se concentrera sur l'intégration de plusieurs directions techniques et se développera en termes d'ampleur. Après cela, démarrez une entreprise ou devenez cadre supérieur.
L'auteur de cet article
Qin Xiaohui, R&D entrepreneurial d'Open-Falcon et Nightingale, auteur de "Operation and Maintenance Monitoring System Practical Notes" de Geek Time, responsable du compte public SRETalk et partenaire entrepreneurial de Kuaimao Nebula, La direction de l'entrepreneuriat est d'assurer la stabilité. Si vous avez des besoins, n'hésitez pas à me contacter pour communiquer.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!