
Maison >Périphériques technologiques >IA >« Mettre » un grand modèle de 33 milliards de paramètres dans un seul GPU grand public, accélérant 15 % sans sacrifier les performances
« Mettre » un grand modèle de 33 milliards de paramètres dans un seul GPU grand public, accélérant 15 % sans sacrifier les performances

- PHPzavant
- 2023-06-07 22:33:211415parcourir
Les performances des grands modèles de langage (LLM) pré-entraînés sur des tâches spécifiques continuent de s'améliorer. Par la suite, si les instructions rapides sont appropriées, elles peuvent être mieux généralisées à davantage de tâches. De nombreuses personnes attribuent ce phénomène à l'augmentation du nombre de tâches. En ce qui concerne la formation des données et des paramètres, les tendances récentes montrent que les chercheurs se concentrent davantage sur des modèles plus petits, mais ces modèles sont formés sur plus de données et sont donc plus faciles à utiliser lors de l'inférence.
Par exemple, LLaMA avec une taille de paramètre de 7B a été formé sur des jetons 1T Bien que les performances moyennes soient légèrement inférieures à GPT-3, la taille du paramètre est de 1/25 de cette dernière. De plus, la technologie de compression actuelle peut compresser davantage ces modèles, réduisant ainsi considérablement les besoins en mémoire tout en maintenant les performances. Grâce à de telles améliorations, des modèles performants peuvent être déployés sur les appareils des utilisateurs finaux tels que les ordinateurs portables.
Cependant, cela se heurte à un autre défi, celui de savoir comment compresser ces modèles dans une taille suffisamment petite pour s'adapter à ces appareils, tout en tenant compte de la qualité de génération. La recherche montre que même si les modèles compressés génèrent des réponses avec une précision acceptable, les techniques de quantification 3 à 4 bits existantes dégradent toujours la précision. Étant donné que la génération LLM est effectuée de manière séquentielle et repose sur des jetons générés précédemment, de petites erreurs relatives s'accumulent et conduisent à une grave corruption de sortie. Pour garantir une qualité fiable, il est essentiel de concevoir des méthodes de quantification à faible largeur de bits qui ne dégradent pas les performances de prédiction par rapport aux modèles 16 bits.
Cependant, la quantification de chaque paramètre sur 3-4 bits entraîne souvent des pertes de précision modérées, voire élevées, en particulier pour les modèles plus petits dans la plage de paramètres 1-10B qui sont idéaux pour le déploiement en périphérie.
Afin de résoudre le problème de précision, des chercheurs de l'Université de Washington, de l'ETH Zurich et d'autres institutions ont proposé un nouveau format de compression et une technologie de quantification SpQR (Sparse-Quantized Representation, représentation clairsemée-quantifiée), qui a été mis en œuvre pour le pour la première fois, LLM fournit une compression quasiment sans perte à toutes les échelles du modèle tout en atteignant des niveaux de compression similaires à ceux des méthodes précédentes.
SpQR fonctionne en identifiant et en isolant les poids anormaux qui provoquent des erreurs de quantification particulièrement importantes, en les stockant avec une plus grande précision tout en compressant tous les autres poids à 3-4 bits, dans LLaMA. Une perte de précision relative de moins de 1 % de perplexité a été obtenue dans et les LLM Falcon. Cela permet d'exécuter un LLM de paramètre 33B sur un seul GPU grand public de 24 Go sans aucune dégradation des performances tout en étant 15 % plus rapide.
L'algorithme SpQR est efficace et peut à la fois encoder les poids dans d'autres formats et les décoder efficacement au moment de l'exécution. Plus précisément, cette recherche fournit à SpQR un algorithme d'inférence GPU efficace qui permet une inférence plus rapide que les modèles de base 16 bits tout en atteignant des gains de compression de mémoire plus de 4 fois.

- Adresse papier : https://arxiv.org/pdf/2306.03078.pdf
- Adresse du projet : https://github.com/Vahe1994/SpQR
Méthode
Cette étude propose un nouveau format pour la quantification clairsemée hybride - Sparse Quantization Representation (SpQR), qui peut compresser avec précision le LLM pré-entraîné à 3-4 bits par paramètre tout en restant presque sans perte.
Plus précisément, l'étude a divisé l'ensemble du processus en deux étapes. La première étape est la détection des valeurs aberrantes : l'étude isole d'abord les poids aberrants et démontre que leur quantification entraîne des erreurs élevées : les poids aberrants sont conservés avec une haute précision, tandis que les autres poids sont stockés avec une faible précision (par exemple dans un format 3 bits). L'étude met ensuite en œuvre une variante de quantification groupée avec des groupes de très petite taille et montre que l'échelle de quantification elle-même peut être quantifiée dans une représentation à 3 bits.
SpQR réduit considérablement l'empreinte mémoire du LLM sans compromettre la précision, tout en produisant un LLM 20 à 30 % plus rapide que l'inférence 16 bits.
De plus, l'étude a révélé que les positions des poids sensibles dans la matrice de poids ne sont pas aléatoires mais ont une structure spécifique. Pour mettre en évidence sa structure lors de la quantification, l'étude a calculé la sensibilité de chaque poids et visualisé ces sensibilités au poids pour le modèle LLaMA-65B. La figure 2 ci-dessous représente la projection de sortie de la dernière couche d'auto-attention de LLaMA-65B. L'étude a apporté deux modifications au processus de quantification : l'une pour capturer les petits groupes de poids sensibles et l'autre pour capturer les valeurs aberrantes individuelles. La figure 3 ci-dessous montre la structure globale de SpQR : la quantification de l'algorithme SpQR, le fragment de code à gauche décrit l'ensemble du processus et le fragment de code à droite contient des sous-programmes pour la quantification secondaire et la recherche de valeurs aberrantes :
# 🎜🎜##🎜 🎜#EXPERIMENT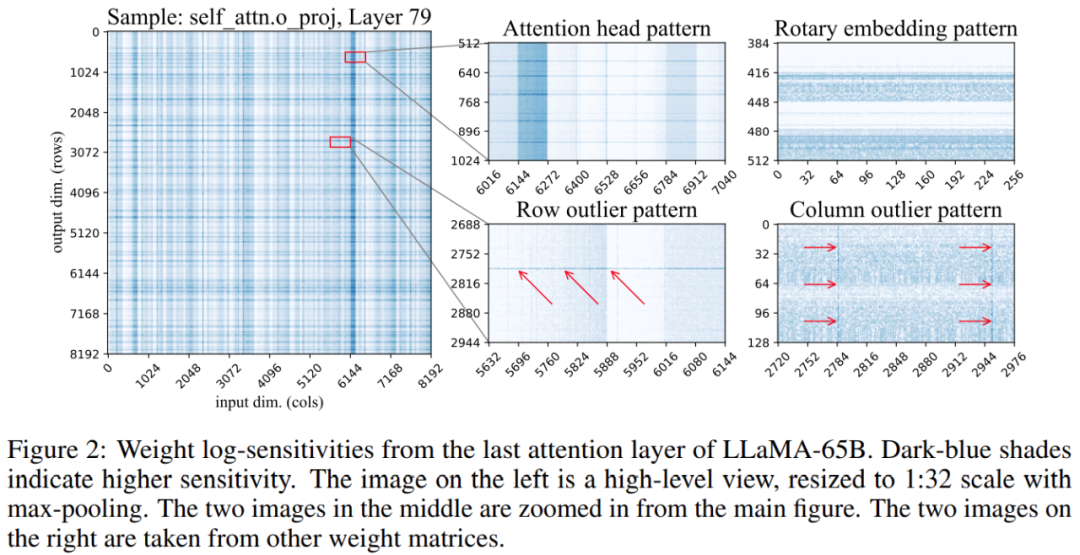
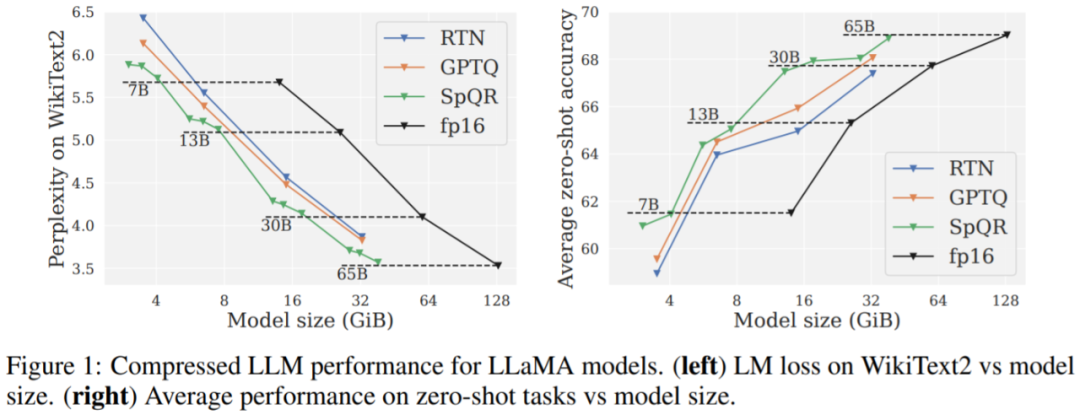
Principaux résultats. Les résultats de la figure 1 montrent qu'à des tailles de modèle similaires, SpQR fonctionne nettement mieux que GPTQ (et le RTN correspondant), en particulier sur les modèles plus petits. Cette amélioration est due au fait que SpQR atteint plus de compression tout en réduisant également la dégradation des pertes.
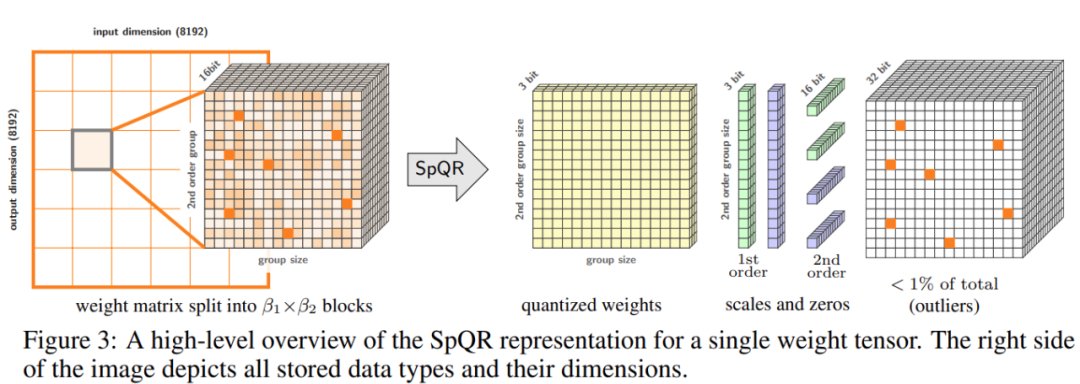
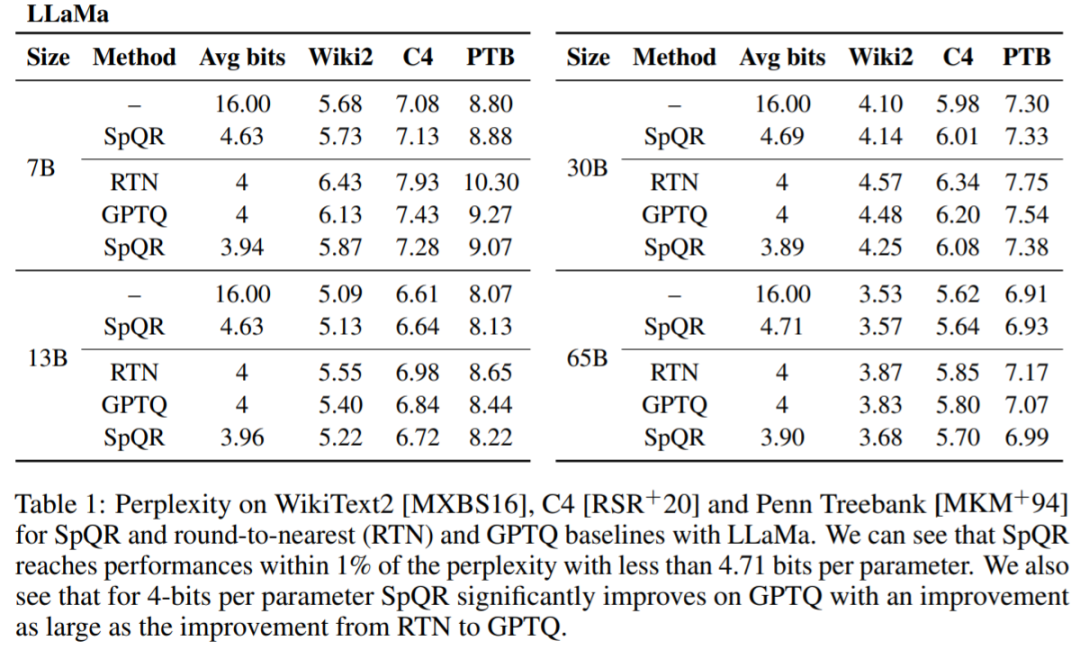
Tableau 1, Tableau 2 Les résultats montrent que pour une quantification 4 bits, SpQR est meilleur que GPTQ avec respect à 16 L'erreur dans la ligne de base des bits est réduite de moitié.

# 🎜 🎜#Le Tableau 3 rapporte les résultats de perplexité du modèle LLaMA-65B sur différents ensembles de données.
Enfin, l'étude évalue la vitesse d'inférence SpQR. Cette étude compare un algorithme de multiplication matricielle clairsemée spécialement conçu avec l'algorithme implémenté dans PyTorch (cuSPARSE), et les résultats sont présentés dans le tableau 4. Comme vous pouvez le voir, bien que la multiplication matricielle clairsemée standard dans PyTorch ne soit pas plus rapide que l'inférence 16 bits, l'algorithme de multiplication matricielle clairsemée spécialement conçu dans cet article peut améliorer la vitesse d'environ 20 à 30 %.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI