
Maison >Périphériques technologiques >IA >OpenAI domine les deux premiers ! Le classement des grands modèles de génération de codes est publié, avec 7 milliards de LLaMA le dépassant et étant battu par 250 millions de Codex.
OpenAI domine les deux premiers ! Le classement des grands modèles de génération de codes est publié, avec 7 milliards de LLaMA le dépassant et étant battu par 250 millions de Codex.

- 王林avant
- 2023-06-07 19:37:44758parcourir
Récemment, un tweet de Matthias Plappert a déclenché une large discussion dans le cercle des LLM.
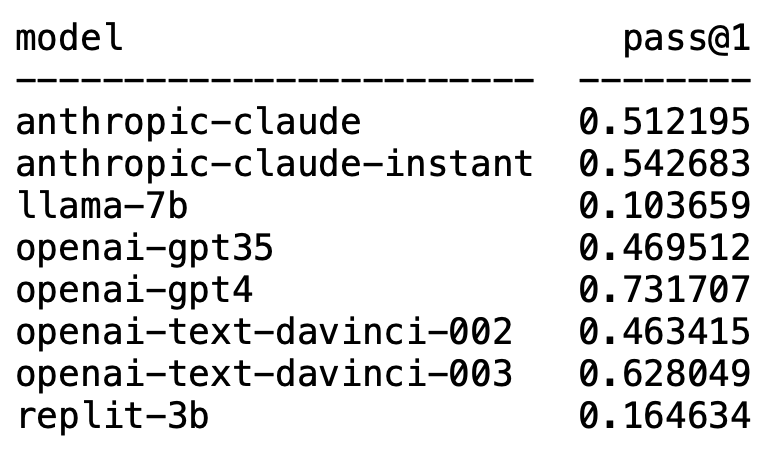
Plappert est un informaticien bien connu. Il a publié ses résultats de tests de référence sur le LLM grand public dans le cercle de l'IA sur HumanEval.
Ses tests sont orientés vers la génération de code.
Les résultats sont à la fois choquants et choquants.

De façon inattendue, GPT-4 domine sans aucun doute la liste et prend la première place.
De façon inattendue, le text-davinci-003 d'OpenAI est soudainement apparu et a pris la deuxième place.
Plappert a déclaré que text-davinci-003 peut être qualifié de modèle "trésor".
Le célèbre LLaMA n'est pas doué pour la génération de code.
OpenAI domine la liste
Plappert a déclaré que les performances de GPT-4 sont encore meilleures que les données de la littérature.
Les données du test en un tour du GPT-4 dans l'article sont un taux de réussite de 67 %, tandis que le test de Plappert a atteint 73 %.

Lors de l'analyse des causes, il a déclaré qu'il existe de nombreuses possibilités de différences dans les données. L’un d’eux est que l’invite qu’il a donnée à GPT-4 était légèrement meilleure que lorsque l’auteur de l’article l’a testée.
Une autre raison est qu'il a deviné que la température du modèle n'était pas 0 lorsque le papier a testé GPT-4.
"Température" est un paramètre utilisé pour ajuster la créativité et la diversité du modèle lors de la génération de texte. « Température » est une valeur supérieure à 0, généralement comprise entre 0 et 1. Cela affecte la distribution de probabilité des mots prédits échantillonnés lorsque le modèle génère du texte.
Lorsque la « température » du modèle est plus élevée (comme 0,8, 1 ou plus), le modèle sera plus enclin à choisir parmi des mots plus divers et différents, ce qui rend le texte généré plus risqué et plus créatif. , mais également susceptible de produire davantage d'erreurs et d'incohérences.
Et lorsque la « température » est basse (comme 0,2, 0,3, etc.), le modèle sélectionnera principalement parmi les mots avec des probabilités plus élevées, ce qui donnera un texte plus fluide et plus cohérent.
Mais à ce stade, le texte généré peut paraître trop conservateur et répétitif.
Donc, dans les applications réelles, il est nécessaire de peser et de sélectionner la valeur de « température » appropriée en fonction des besoins spécifiques.
Ensuite, en commentant text-davinci-003, Plappert a déclaré qu'il s'agissait également d'un modèle très performant sous OpenAI.
Bien qu'il ne soit pas aussi bon que GPT-4, il assure toujours la deuxième place avec un taux de réussite de 62 % en une seule série de tests.
Plappert a souligné que la meilleure chose à propos de text-davinci-003 est que les utilisateurs n'ont pas besoin d'utiliser l'API de ChatGPT. Cela signifie que donner des invites peut être plus simple.
De plus, Plappert a également donné au modèle Claude-Instant d'Anthropic AI une évaluation relativement élevée.
Il pense que les performances de ce modèle sont bonnes et peuvent battre GPT-3.5. Le taux de réussite du GPT-3.5 est de 46 %, tandis que le taux de réussite de Claude-Instant est de 54 %.
Bien sûr, l'autre LLM d'Anthropic AI, Claude, ne peut pas être joué par Claude-Instant, et le taux de réussite n'est que de 51 %.
Plappert a déclaré que les invites utilisées pour tester les deux modèles sont les mêmes, si ça ne marche pas, ça ne marche pas.
En plus de ces modèles familiers, Plappert a également testé de nombreux petits modèles open source.
Plappert a dit que c'était bien qu'il puisse exécuter ces modèles localement.
Cependant, en termes d'échelle, ces modèles ne sont évidemment pas aussi grands que ceux d'OpenAI et d'Anthropic AI, donc les comparer est un peu écrasant.

Génération de code LLaMA ? Bien entendu, Plappert n’était pas satisfait des résultats des tests LLaMA.
À en juger par les résultats des tests, LLaMA fonctionne très mal dans la génération de code. Probablement parce qu'ils ont utilisé le sous-échantillonnage lors de la collecte de données depuis GitHub.
 Même comparée au Codex 2.5B, les performances de LLaMA ne sont pas les mêmes. (Taux de réussite 10% contre 22%)
Même comparée au Codex 2.5B, les performances de LLaMA ne sont pas les mêmes. (Taux de réussite 10% contre 22%)
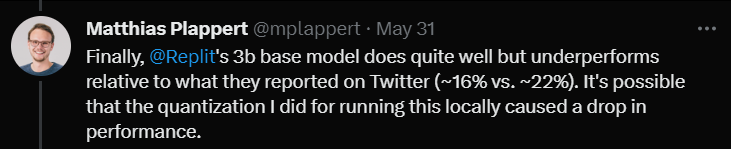
 Enfin, il a testé le modèle taille 3B de Replit.
Enfin, il a testé le modèle taille 3B de Replit.
Il a dit que la performance n'était pas mauvaise, mais comparée aux données promues sur Twitter (taux de réussite de 16% contre 22%)
Plappert pense que cela peut être dû au fait qu'il testait ce modèle. La méthode de quantification utilisé a fait baisser le taux de réussite de plusieurs points de pourcentage.
 À la fin de la revue, Plappert a mentionné un point intéressant.
À la fin de la revue, Plappert a mentionné un point intéressant.
Un utilisateur a découvert sur Twitter que GPT-3.5-turbo fonctionne mieux lors de l'utilisation de l'API Completion de la plateforme Azure (plutôt que de l'API Chat).
Plappert estime que ce phénomène a une certaine légitimité, car la saisie d'invites via l'API Chat peut être assez compliquée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI