
Maison >Périphériques technologiques >IA >L'effet atteint 96% du modèle OpenAI de même échelle, et il est open source dès sa sortie ! L'équipe nationale lance un nouveau grand modèle et le PDG se lance dans la bataille pour écrire du code
L'effet atteint 96% du modèle OpenAI de même échelle, et il est open source dès sa sortie ! L'équipe nationale lance un nouveau grand modèle et le PDG se lance dans la bataille pour écrire du code

- 王林avant
- 2023-06-07 14:20:101558parcourir
Les grands modèles nationaux auto-développés accueillent de nouveaux visages, et ils sont open source dès leur sortie !
Les dernières nouvelles sont que le grand modèle de langage multimodal TigerBot a été officiellement dévoilé, comprenant deux versions de 7 milliards de paramètres et 180 milliards de paramètres, toutes deux open source.
L'IA conversationnelle supportée par ce modèle est lancée simultanément.
Écrire des slogans, créer des formulaires et corriger des erreurs grammaticales sont tous très efficaces ; il prend également en charge la multimodalité et peut générer des images.

Les résultats de l'évaluation montrent que TigerBot-7B a atteint 96% des performances globales des modèles OpenAI de même taille.
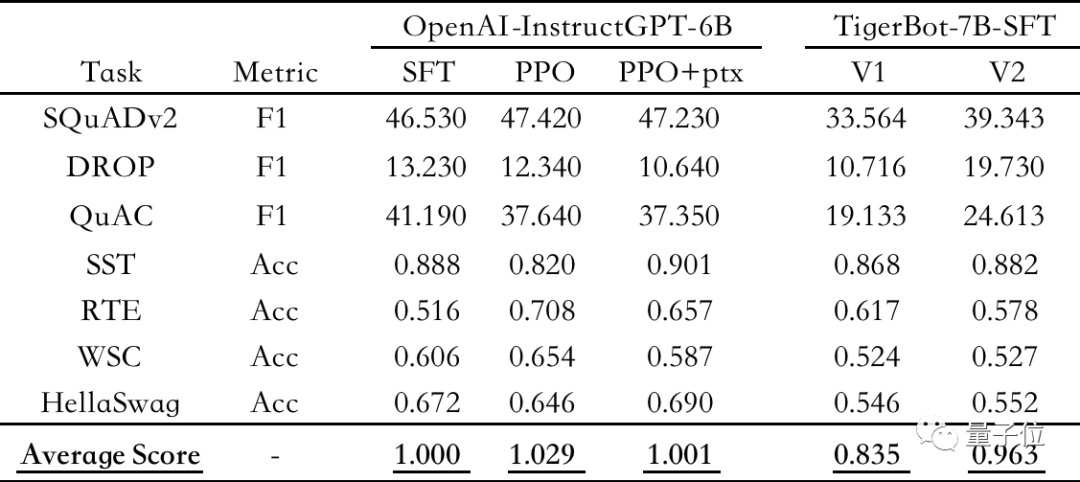
△Évaluation automatique sur les ensembles de données PNL publics, en utilisant l'instruction OpenAI GPT-6B-SFT comme référence, normalisant et faisant la moyenne des scores de chaque modèle
Et le plus grand TigerBot-180B ou C'est actuellement le le plus grand modèle de langage open source du secteur. De plus, l'équipe dispose également de
100G de données de pré-entraînement open source et d'un réglage fin supervisé de 1G ou 1 million de données. Basé sur TigerBot, les développeurs peuvent créer leurs propres grands modèles en
une demi-journée. Actuellement, TigerBot Dialogue AI a été invité à des tests internes et les données du code open source ont été téléchargées sur GitHub
(voir la fin de l'article pour les liens détaillés).
. Mais cette équipe n’est en aucun cas inconnue.
Depuis 2017, ils ont démarré leur activité dans le domaine de la PNL, spécialisée dans la recherche de champs verticaux.
Il est le meilleur dans le domaine financier riche en données et a eu une coopération approfondie avec Founder Securities, Guosen Securities, etc.Fondateur et PDG, a plus de 20 ans d'expérience dans l'industrie, a été professeur invité à l'UC Berkeley, détient 3 meilleurs articles de conférence et 10 brevets technologiques.
Maintenant, ils sont déterminés à passer des domaines spécialisés aux grands modèles généralistes.
Et nous avons commencé avec le modèle de base le plus bas depuis le début,
réalisé 3 000 itérations expérimentales en 3 mois, et nous avons toujours la confiance nécessaire pour ouvrir la source des résultats progressifs au monde extérieur. Je ne peux m’empêcher de rendre les gens curieux, qui sont-ils ? Qu'est-ce que vous voulez faire? Quels résultats progressifs ont été obtenus jusqu’à présent ?
Qu’est-ce que TigerBot ?
Plus précisément, TigerBot est un grand modèle de tâches multilingues auto-développé au niveau national.
Couvre 15 grandes catégories de capacités telles que la génération, les questions et réponses ouvertes, la programmation, le dessin, la traduction, le brainstorming, etc., et prend en charge plus de 60 sous-tâches.
Il prend également en charge la
fonction plug-in, qui permet au modèle d'être connecté à Internet et d'obtenir des données et des informations plus récentes.
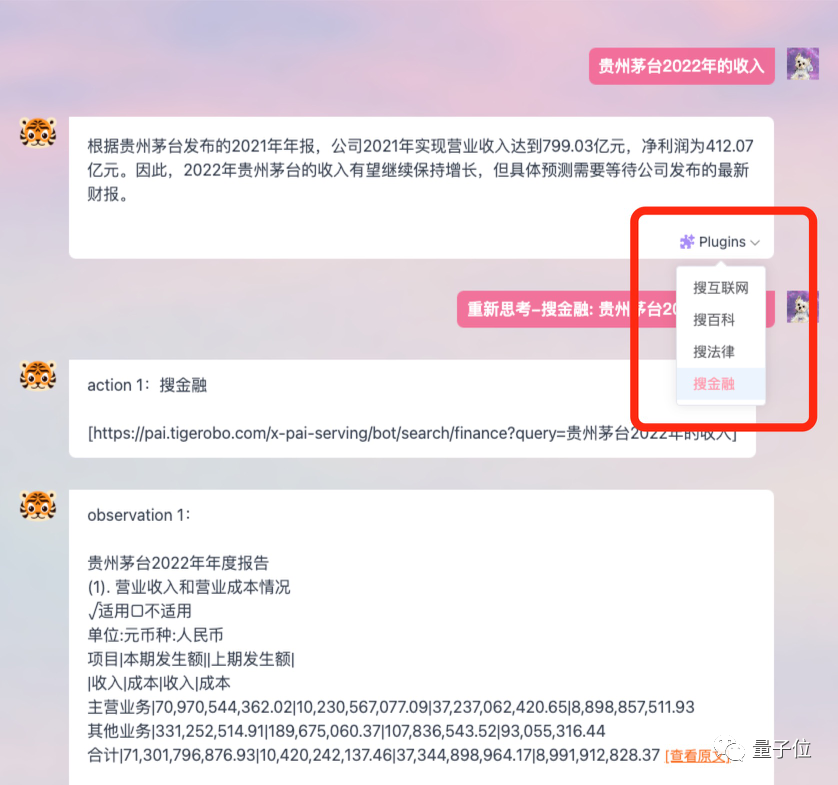
Par exemple, laissez-le m'aider à écrire un flash d'information sur Apple Vision Pro, l'effet est impressionnant :

 Aucune compétence en programmation questions et soutient le dialogue en anglais.
Aucune compétence en programmation questions et soutient le dialogue en anglais.

Dans cette version, TigerBot a lancé deux tailles : 7 milliards de paramètres (TigerBot-7B) et 180 milliards de paramètres (TigerBot-180B).
L'équipe ouvrira en source tous les résultats progressifs obtenus jusqu'à présent : modèles, codes et données.
Le modèle open source comprend trois versions :
- TigerBot-7B-sft
- TigerBot-7B-base
- TigerBot-180B-research
Parmi elles, TigerBot-7B-base fonctionne mieux que les modèles comparables équivalents OpenAI , FLORAISON . TigerBot-180B-research est peut-être actuellement le plus grand modèle open source de l'industrie (le Meta open source OPT a une taille de paramètre de 175 milliards et BLOOM a une échelle de 176 milliards).
Le code open source comprend une formation de base et un code d'inférence, un code de quantification et d'inférence pour le modèle 180B d'inférence à double carte.
Les données comprennent 100G de données de pré-entraînement et un réglage fin supervisé de 1G ou 1 million de données.
Selon l'évaluation automatique de l'article OpenAI InstructGPT sur l'ensemble de données public NLP, TigerBot-7B a atteint 96 % des performances globales des modèles OpenAI de même taille.
Et cette version n'est que MVP (Minimum Viable Model).
Ces résultats sont principalement dus à la poursuite de l'optimisation par l'équipe de l'architecture du modèle et de l'algorithme basé sur GPT et BLOOM. C'est également le principal travail d'innovation de l'équipe TigerBot au cours des derniers mois, permettant la capacité d'apprentissage du modèle et la création de la force. et la contrôlabilité de la production ont été considérablement améliorées.
Comment le mettre en œuvre concrètement ? Regardez en bas.
Amélioration des performances tout en réduisant les coûts
Les innovations apportées par TigerBot incluent principalement les aspects suivants :
- Proposer des algorithmes innovants pour effectuer un réglage fin supervisé avec des instructions pour améliorer l'apprentissage du modèle
- Utiliser des méthodes de modélisation d'ensemble et probabilistes pour obtenir des faits contrôlables Caractéristiques et créativité
- Briser les problèmes de mémoire et de communication dans les cadres traditionnels tels que le deep-speed dans l'entraînement parallèle, atteindre des mois ininterrompus dans un environnement kilocalorique
- Compte tenu de la distribution plus irrégulière de la langue chinoise, du tokenizer à l'algorithme d'entraînement Pour une optimisation plus adaptée
, examinons d'abord la méthode de réglage précis de la supervision de l'achèvement des commandes.
Cela permet au modèle de comprendre rapidement quels types de questions les humains ont posés et d'améliorer la précision des réponses tout en utilisant seulement un petit nombre de paramètres.
En principe, un apprentissage supervisé plus fort est utilisé pour le contrôle.
Utilisation du langage de balisage (langage de balisage) et de méthodes probabilistes pour permettre aux grands modèles de distinguer plus précisément les catégories d'instructions. Par exemple, les questions pédagogiques sont-elles plus factuelles ou divergentes ? Est-ce du code ? Est-ce un formulaire ?
TigerBot couvre donc 10 grandes catégories et 120 catégories de petites tâches. Laissez ensuite le modèle s'optimiser dans la direction correspondante en fonction du jugement. L'avantage direct apporté par
est que le nombre de paramètres à appeler est plus petit et que le modèle a une meilleure adaptabilité aux nouvelles données ou tâches, c'est-à-dire que la capacité d'apprentissage est améliorée.
Dans les mêmes conditions d'entraînement de 500 000 données, la vitesse de convergence de TigerBot est 5 fois plus rapide que celle d'Alpaca lancé par Stanford, et l'évaluation sur des ensembles de données publiques montre que les performances sont améliorées de 17 %.
Deuxièmement, la manière dont le modèle peut mieux équilibrer la créativité et la contrôlabilité factuelle du contenu généré est également très critique.
TigerBot adopte d'une part la méthode ensemble, combinant plusieurs modèles pour prendre en compte la créativité et la contrôlabilité factuelle.
Vous pouvez même ajuster le compromis du modèle entre les deux en fonction des besoins de l'utilisateur.
D'autre part, il adopte également la méthode classique de Modélisation Probabiliste(Modélisation Probabiliste) dans le domaine de l'IA.
Cela permet au modèle de donner deux probabilités basées sur le dernier jeton généré pendant le processus de génération de contenu. Une probabilité détermine si le contenu doit continuer à diverger, et une probabilité indique le degré d'écart entre le contenu généré et le contenu factuel.
En combinant les valeurs des deux probabilités, le modèle fera un compromis entre créativité et contrôlabilité. Les deux probabilités de TigerBot sont entraînées avec des données spéciales.
Considérant que lorsque le modèle génère le prochain jeton, il est souvent impossible de voir le texte intégral, TigerBot portera également un autre jugement après la rédaction de la réponse, si la réponse s'avère finalement inexacte, il demandera au modèle de le faire. récrire.
Nous avons également constaté au cours de l'expérience que les réponses générées par TigerBot ne sont pas en mode de sortie textuelle comme ChatGPT, mais donnent des réponses complètes après "réflexion".

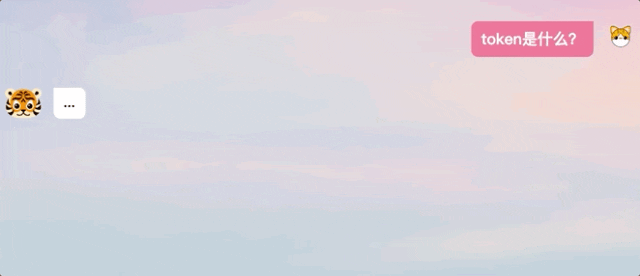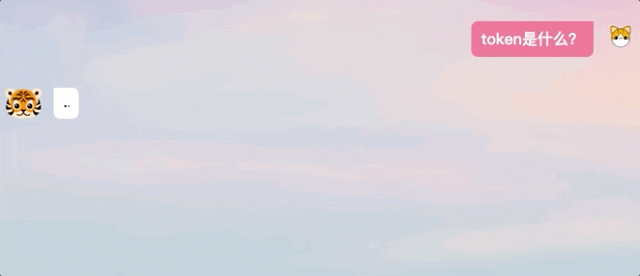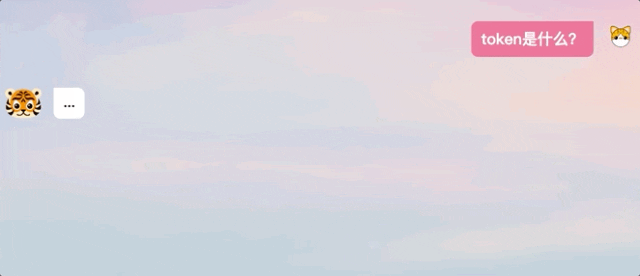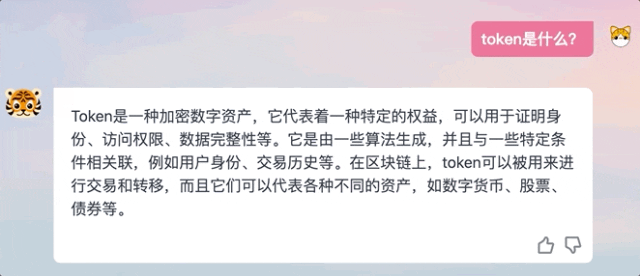
△Comparaison des méthodes de réponse ChatGPT et TigerBot
Et comme la vitesse d’inférence de TigerBot est très rapide, il peut prendre en charge une réécriture rapide des modèles.
Nous parlons ici des innovations de TigerBot en matière de formation et de raisonnement.
En plus d'envisager l'optimisation de l'architecture sous-jacente du modèle, l'équipe TigerBot estime que le niveau d'ingénierie est également très important dans l'ère actuelle des grands modèles.
D'une part, cela est dû à la nécessité de prendre en compte l'efficacité opérationnelle - alors que la tendance aux grands modèles se poursuit, il est très critique de savoir qui peut itérer le modèle plus rapidement. D'autre part, bien sûr, l'économie de la puissance de calcul doit être prise en compte ; également être pris en compte.
Par conséquent, en termes d'entraînement parallèle, ils ont surmonté plusieurs problèmes de mémoire et de communication dans des cadres traditionnels tels que le deep-speed, et ont réalisé un entraînement ininterrompu pendant plusieurs mois dans un environnement kilocalorie.
Cela leur permet d'économiser des centaines de milliers de dollars en dépenses mensuelles de formation.
Enfin, TigerBot a apporté les optimisations correspondantes du tokenizer à l'algorithme de formation pour faire face aux problèmes de forte continuité et de multiples ambiguïtés en chinois.
En résumé, les innovations technologiques réalisées par TigerBot se produisent toutes dans les domaines qui reçoivent le plus d'attention dans le domaine actuel des grands modèles.
Il ne s'agit pas seulement d'optimiser l'architecture sous-jacente, mais de prendre également en compte les besoins des utilisateurs, les frais généraux et d'autres problèmes au niveau de la mise en œuvre. Et l'ensemble du processus d'innovation est très rapide, et peut être réalisé en quelques mois par une petite équipe d'environ 10 personnes.
Cela impose des exigences très élevées en matière de capacités de développement, de connaissances techniques et d'expérience de mise en œuvre de l'équipe.
Alors, qui a soudainement éclaté aux yeux du public avec TigerBot ?
Qui est Hubo Technology ?
L'équipe de développement derrière TigerBot est en fait cachée dans son nom - Hubo Technology.
Il a été créé en 2017, ce que les gens appellent souvent la dernière phase de la période d'explosion de l'IA.
Hubo Technology se positionne comme « une entreprise axée sur la technologie de l'intelligence artificielle », se concentrant sur l'application de la technologie NLP, et sa vision est de créer la prochaine génération d'expérience de recherche intelligente et simple.
Sur le chemin de mise en œuvre spécifique, ils ont choisi l'un des domaines les plus sensibles aux informations sur les données - Finance. Elle dispose de technologies auto-développées telles que la recherche intelligente, la recommandation intelligente, la compréhension de lecture automatique, le résumé et la traduction dans des domaines verticaux, et a lancé le système de recherche financière intelligente et de questions et réponses « Hubo Search ».
Le fondateur et PDG de l'entreprise est Chen Ye, un scientifique de classe mondiale en IA.

Il est diplômé d'un doctorat de l'Université du Wisconsin-Madison et a été professeur invité à l'Université de Californie à Berkeley. Il exerce depuis plus de 20 ans.
Il a occupé successivement des postes importants tels que celui de scientifique en chef et de directeur R&D chez Microsoft, eBay et Yahoo, et a dirigé le développement du système de ciblage comportemental de Yahoo, du système de recommandation d'eBay et du mécanisme de marché des enchères publicitaires de recherche de Microsoft.
En 2014, Chen Ye a rejoint Dianping. Après la fusion de Meituan-Dianping, il a occupé le poste de vice-président senior de Meituan-Dianping, en charge de la plateforme publicitaire du groupe, aidant ainsi les revenus publicitaires annuels du groupe à passer de 10 millions à plus de 4 milliards.
En termes universitaires, Chen Ye a remporté à trois reprises le prix du meilleur article lors de conférences de premier plan (KDD et SIGIR), a publié 20 articles lors de conférences universitaires sur l'intelligence artificielle telles que SIGKKD, SIGIR et IEEE et détient 10 brevets.
En juillet 2017, Chen Ye a officiellement fondé Hubo Technology. Un an après sa création, Hubo a rapidement obtenu plus de 100 millions de yuans de financement La société révèle actuellement que le montant total du financement atteint 400 millions de yuans.

Il y a 7 mois, ChatGPT était né Après 6 ans, l'IA a une fois de plus bouleversé la perception du public.
Même des experts techniques comme Chen Ye, qui travaillent dans le domaine de l'IA depuis de nombreuses années, le décrivent comme un « choc sans précédent dans leur carrière ».
Outre le choc, c’est plus excitant.
Chen Ye a déclaré qu'après avoir vu ChatGPT, il n'avait presque pas eu à réfléchir ou à prendre de décision. L'appel de son cœur l'avait incité à suivre définitivement la tendance.
Ainsi, à partir de janvier, TigerBot a officiellement créé l'équipe de développement initiale de TigerBot.
Mais c’est différent de ce que j’imaginais. C’est une équipe avec un style geek très distinctif.
Dans leurs propres mots, ils rendent hommage au modèle classique des « Garage Startup » de la Silicon Valley dans les années 1990.
L'équipe ne comptait initialement que 5 personnes. Chen Ye était le programmeur et scientifique en chef, responsable du travail de code de base. Bien que le nombre de membres ait augmenté par la suite, il n'a été limité qu'à 10 personnes, soit essentiellement une personne par poste.
Pourquoi fais-tu ça ?
La réponse de Chen Ye est :
Je pense que la création de 0 à 1 est une chose très geek, et aucune équipe de geek ne compte plus de 10 personnes.
Au-delà des questions purement techniques et scientifiques, les petites équipes sont plus pointues.
En effet, le processus de développement de TigerBot a révélé détermination et sensibilité dans tous les aspects.
Chen Ye divise ce cycle en trois étapes.
Dans la première phase, peu de temps après que ChatGPT soit devenu populaire, l'équipe a rapidement analysé toute la littérature pertinente d'OpenAI et d'autres institutions au cours des cinq dernières années pour acquérir une compréhension générale des méthodes et des mécanismes de ChatGPT.
Étant donné que le code ChatGPT lui-même n'est pas open source et qu'il y avait relativement peu de travaux open source connexes à cette époque, Chen Ye s'est mis au travail et a écrit lui-même le code TigerBot, puis a immédiatement commencé à mener des expériences.
Leur logique est très simple. Le modèle est d'abord vérifié avec succès sur des données à petite échelle, puis fait l'objet d'un examen scientifique systématique, ce qui signifie qu'un ensemble de codes stable est formé.
En un mois, l’équipe a vérifié que le modèle peut atteindre 80 % de l’effet du modèle OpenAI de la même échelle à une échelle de 7 milliards.
Dans la deuxième phase, en absorbant continuellement les avantages des modèles et des codes open source, et en optimisant spécialement les données chinoises, l'équipe a rapidement mis au point une version réelle et utilisable du modèle. La première version bêta interne a été lancée en février. .
Dans le même temps, ils ont également constaté qu'après que le nombre de paramètres ait atteint le niveau des des dizaines de milliards, le modèle montrait un phénomène d'émergence.
Dans la troisième phase, c'est-à-dire au cours des deux derniers mois, l'équipe a obtenu des résultats et des percées dans la recherche fondamentale.
Beaucoup des innovations présentées ci-dessus ont été réalisées au cours de cette période.
Dans le même temps, une plus grande quantité de puissance de calcul a été intégrée au cours de cette étape pour atteindre une vitesse d'itération plus rapide. En 1 à 2 semaines, la capacité du TigerBot-7B est rapidement passée de 80 % d'InstructGPT à 96 %.
Chen Ye a déclaré qu'au cours de ce cycle de développement, l'équipe a toujours maintenu un fonctionnement ultra-efficace. TigerBot-7B a subi 3 000 itérations en quelques mois.
L'avantage d'une petite équipe est qu'elle peut réagir rapidement. Elle peut confirmer le travail le matin et terminer l'écriture du code l'après-midi. Les équipes chargées des données peuvent effectuer un travail de nettoyage de haute qualité en quelques heures.
Mais les itérations de développement à grande vitesse ne sont qu’une des manifestations du style geek de TigerBot.
Parce qu'ils s'appuient uniquement sur les résultats produits par 10 personnes en quelques mois et les ouvriront à l'industrie sous la forme d'un ensemble complet d'API.
Adopter l'open source à ce point est relativement rare dans la tendance actuelle, notamment dans le domaine de la commercialisation.
Après tout, dans une concurrence féroce, la construction de barrières techniques est un problème auquel les entreprises commerciales doivent faire face.
Alors, pourquoi Hubo Technology ose-t-il l'open source ?
Chen Ye a donné deux raisons :
Premièrement, en tant que technicien dans le domaine de l'IA, par croyance la plus instinctive en la technologie, il est un peu passionné et un peu sensationnel.
Nous voulons contribuer à l’innovation chinoise avec un modèle à grande échelle de classe mondiale. Donner à l'industrie un modèle général utilisable avec une base solide permettra à davantage de personnes de former rapidement de grands modèles professionnels et de réaliser la création écologique de clusters industriels.
Deuxièmement, TigerBot continuera à maintenir l'itération à grande vitesse et pense que dans cette situation de course, ils peuvent conserver leur avantage de position. Même si nous voyons quelqu’un développer un produit plus performant basé sur TigerBot, n’est-ce pas une bonne chose pour l’industrie ?
Chen Ye a révélé que Hubo Technology continuera de faire progresser rapidement le travail de TigerBot et d'élargir davantage les données pour améliorer les performances du modèle.
"La tendance des grands modèles est comme une ruée vers l'or"
Six mois après la sortie de ChatGPT, avec l'émergence des grands modèles les uns après les autres et le suivi rapide des géants, le paysage de l'industrie de l'IA se transforme rapidement remodelé.
Bien qu'il soit encore relativement chaotique pour le moment, grosso modo, il est essentiellement divisé en trois couches : la couche modèle, la couche intermédiaire et la couche application.
La couche modèle détermine les capacités sous-jacentes, ce qui est très important.
Son degré d'innovation, de stabilité et d'ouverture détermine directement la richesse de la couche applicative.
Le développement de la couche applicative est la manifestation externe de l'évolution des grandes tendances des modèles ; c'est également un facteur d'influence important pour la prochaine étape de la vie sociale humaine dans la vision de l'AIGC.
Ainsi, au point de départ de la grande tendance du modèle, l'industrie doit réfléchir à la manière de consolider la base du modèle sous-jacent.
Selon Chen Ye, les humains n'ont développé que 10 à 20 % du potentiel des grands modèles, et il y a encore beaucoup de place pour l'innovation et l'amélioration au niveau fondamental.
Tout comme la ruée vers l'or en Occident, là où la mine d'or a été découverte à l'origine.
Ainsi, face à de telles tendances et exigences de développement de l'industrie, Hubo Technology, en tant que représentant de l'innovation dans le domaine national, brandit haut la bannière de l'open source, a rapidement commencé à rattraper la technologie la plus de pointe au monde et a effectivement apporté une différence dans le souffle de l'industrie.
L'innovation nationale en matière d'IA se déroule à grande vitesse. À l'avenir, je pense que nous verrons apparaître davantage d'équipes dotées d'idées et de capacités pour injecter de nouvelles connaissances et apporter de nouveaux changements dans le domaine des grands modèles.
Et c’est peut-être la partie la plus fascinante de l’évolution vigoureuse de la tendance.
Moment de bien-être :
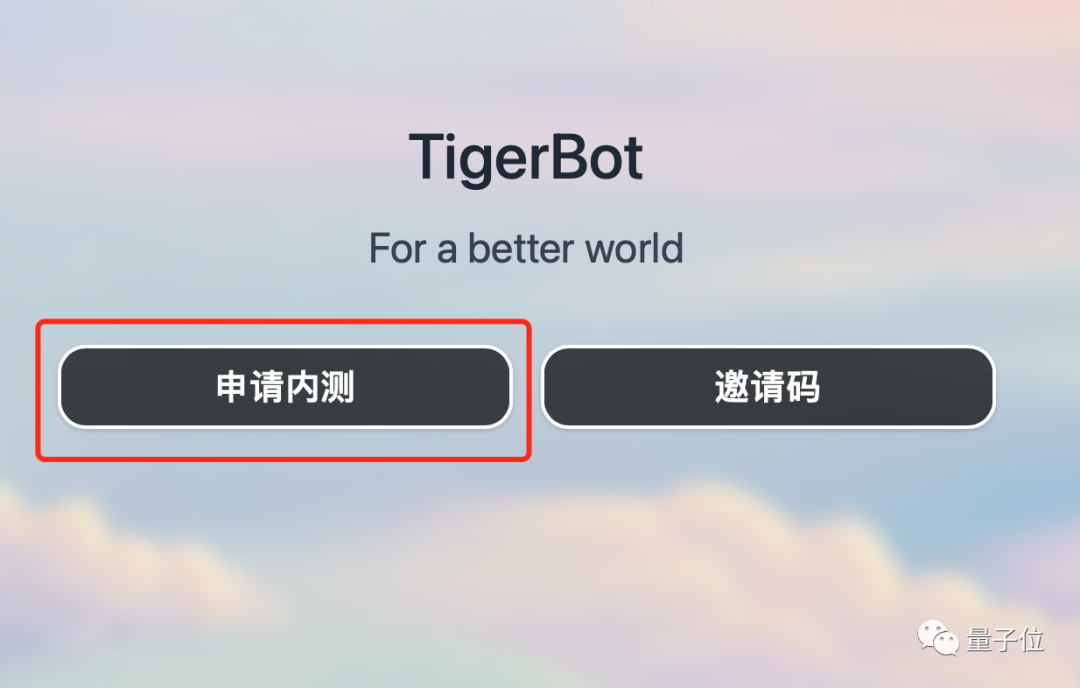
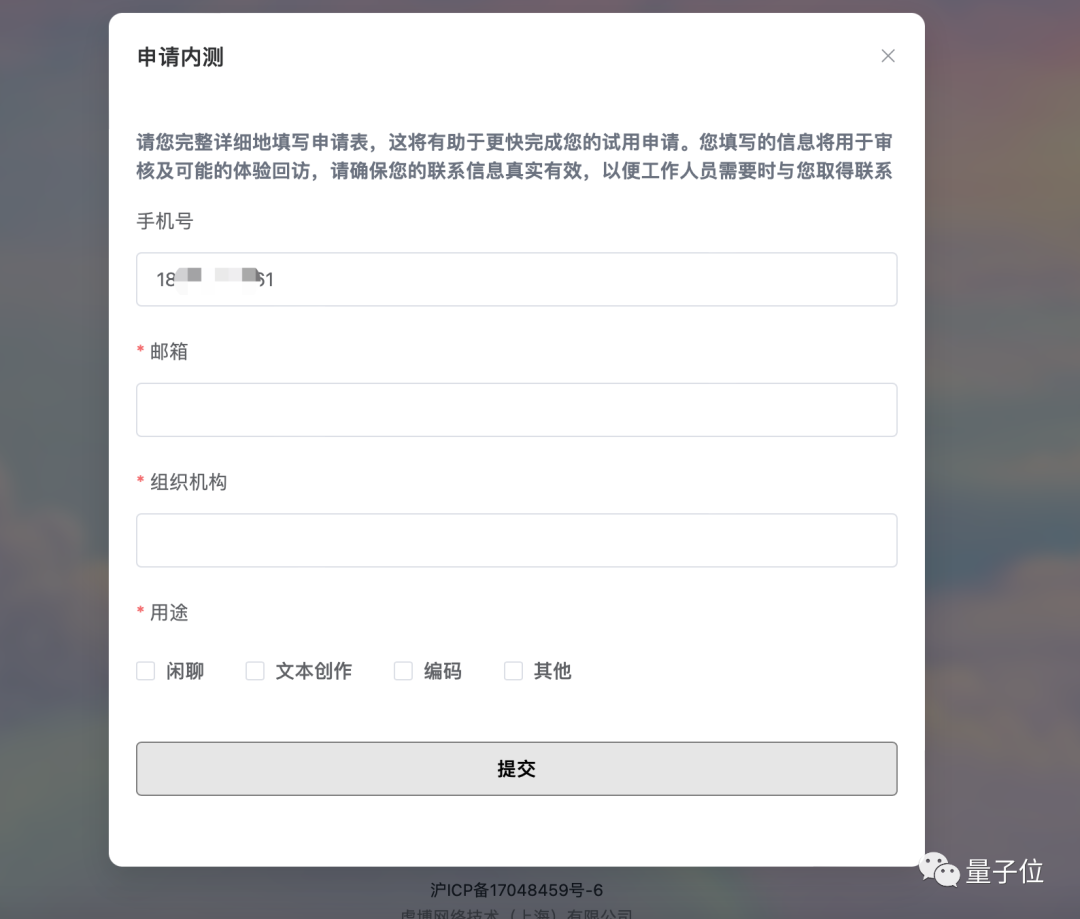
Si vous souhaitez découvrir les chaussures pour enfants de TigerBot, vous pouvez accéder au site Web via le lien ci-dessous ou cliquer sur "Lire le texte original", cliquer sur "Demander un test interne", écrire "qubit" dans le code de l'organisation. pour réussir les tests internes~
Adresse du site officiel : https://www.tigerbot.com/chat
Adresse open source GitHub : https://github.com/TigerResearch/TigerBot
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI