
Maison >Périphériques technologiques >IA >L'IA imite le modèle de mémoire du cerveau humain et les scores des jeux ont grimpé de 29,9 %
L'IA imite le modèle de mémoire du cerveau humain et les scores des jeux ont grimpé de 29,9 %

- 王林avant
- 2023-06-06 11:13:02787parcourir
On nous apprend souvent à « réfléchir à deux fois avant d'agir » et à tirer pleinement parti de l'expérience accumulée. Cette phrase a également inspiré l'IA.
Les modèles d'IA décisionnels traditionnels ne peuvent pas accumuler efficacement d'expérience en raison de l'existence de l'effet d'oubli, mais une recherche menée par la Chine a changé la façon dont l'IA se souvient.
La nouvelle méthode de mémoire imite le cerveau humain, améliorant efficacement l'efficacité de l'IA dans l'accumulation d'expérience, augmentant ainsi les performances de jeu de l'IA de 29,9 %.
L'équipe de recherche est composée de six personnes, respectivement de l'Institut de recherche en IA Mira-Québec et de l'Institut de recherche Microsoft de Montréal, dont quatre sont chinois.
Ils ont nommé le résultat Decision Transformer with Memory (DT-Mem).
Par rapport aux modèles de prise de décision traditionnels, DT-Mem est plus largement applicable et l'efficacité du fonctionnement du modèle est également plus élevée.
En plus de l'effet d'application, la durée de formation du DT-Mem a également été raccourcie d'un minimum de 200 heures à 50 heures.
En parallèle, l'équipe a également proposé une méthode de mise au point pour permettre à DT-Mem de s'adapter à de nouveaux scénarios non entraînés.
Le modèle affiné peut également bien fonctionner dans des jeux qu'il n'a jamais appris auparavant.
Le mécanisme de travail s'inspire des humains
Le modèle de prise de décision traditionnel est conçu sur la base du LLM, en utilisant la mémoire implicite, et ses performances s'appuie sur des données et des calculs.
Les souvenirs implicites sont générés inconsciemment plutôt que délibérément mémorisés, et ne peuvent donc pas être rappelés consciemment.
Pour faire plus simple, le contenu pertinent y est évidemment stocké, mais le modèle ne connaît pas son existence.
Cette caractéristique de la mémoire implicite détermine que le modèle traditionnel présente un phénomène d'oubli, entraînant sa faible efficacité de travail.
Le phénomène d'oubli se manifeste par le fait qu'après avoir appris une nouvelle façon de résoudre un problème, le modèle peut oublier l'ancien contenu, même si l'ancien et le nouveau problème sont du même type.
Le cerveau humain adopte la méthode de stockage de mémoire distribuée , et le contenu de la mémoire est stocké de manière dispersée dans plusieurs zones différentes du cerveau.
Cette approche permet de gérer et d'organiser efficacement de multiples compétences, atténuant ainsi le phénomène d'oubli.
Inspirée par cela, l'équipe de recherche a proposé un module de mémoire de travail interne pour stocker, mélanger et récupérer des informations pour différentes tâches en aval.
Plus précisément, DT-Mem se compose d'un transformateur, d'un module de mémoire et d'un module de perception multicouche (MLP).
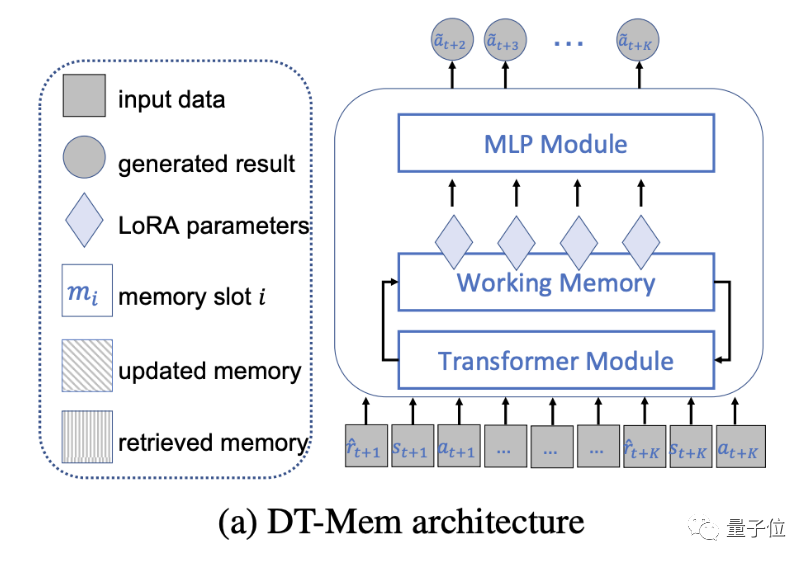
Le transformateur de DT-Mem imite l'architecture de GPT-2, mais supprime le mécanisme d'attention.
Dans le même temps, le module MLP de GPT-2 est divisé en composants indépendants dans le cadre de DT-Mem.
Entre-temps, l'équipe de recherche a introduit un module de mémoire de travail pour stocker et traiter les informations intermédiaires.
Cette structure s'inspire des machines neuronales de Turing, où la mémoire est utilisée pour déduire divers algorithmes.
Le module de mémoire analyse les informations sorties par le Transformer et détermine son emplacement de stockage et comment l'intégrer aux informations existantes.
De plus, ce module examine également la manière dont ces informations seront utilisées dans les futurs processus décisionnels.
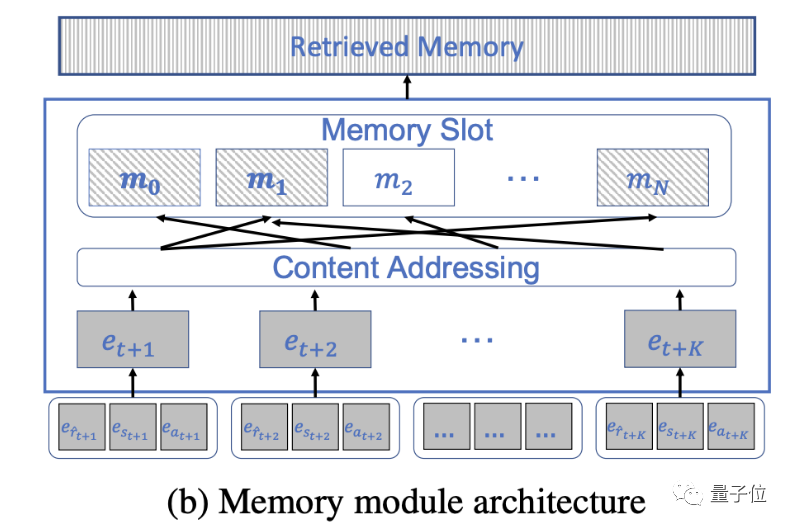
Ces tâches sont grossièrement réalisées en cinq étapes. Le module de mémoire est d'abord initialisé en tant que matrice aléatoire.
Vient ensuite le tri des informations d'entrée. Cette étape ne consiste pas à transmettre les informations au Transformer, mais à les stocker dans le même espace sous forme de tuples.
Après cela, vous devez déterminer l'emplacement de stockage. Les humains stockent généralement les informations associées au même endroit, et DT-Mem est également basé sur ce principe.
Les deux dernières étapes - la mise à jour et la récupération de la mémoire sont le cœur du module de mémoire et le maillon le plus important de tout le DT-Mem.
La mise à jour de la mémoire signifie la modification et le remplacement des informations existantes pour garantir que les informations peuvent être mises à jour à temps en fonction des besoins de la tâche.
Dans cette étape, DT-Mem calculera les vecteurs d'effacement et d'écriture pour déterminer comment les mélanger avec les données existantes.
La récupération de mémoire est l'accès et la récupération d'informations existantes, ainsi que la récupération en temps opportun d'informations pertinentes et utiles lorsque des décisions doivent être prises.
Avant d'être mis en service, DT-Mem doit encore passer par un processus de pré-formation.

Pour la mise au point du DT-Mem, l'équipe a également proposé une nouvelle façon.
Comme il utilise des données étiquetées en fonction des tâches, ce type de réglage fin peut aider DT-Mem à s'adapter aux nouvelles tâches.
Ce processus est basé sur l'adaptation de bas rang (LoRA), ajoutant des éléments de bas rang à la matrice existante.

Le temps d'entraînement peut être raccourci jusqu'à 32 fois
Afin de tester la capacité de prise de décision de DT-Mem, l'équipe de recherche l'a laissé jouer à plusieurs jeux.
Il y a 5 jeux au total, tous d'Atari.
Parallèlement, l'équipe a également testé les performances du modèle traditionnel M[ulti-game]DT comme référence.
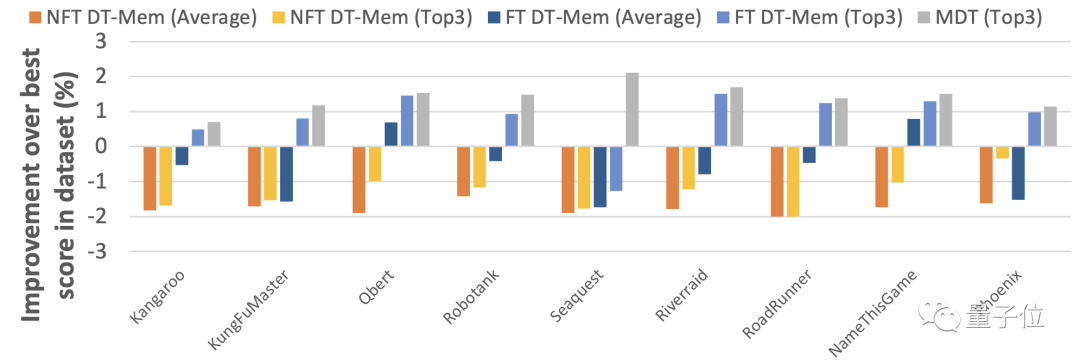
En conséquence, les meilleurs résultats de DT-Mem dans 4 des jeux étaient meilleurs que ceux de MDT.
Plus précisément, DT-Mem améliore le score normalisé DQN de 29,9 % par rapport à MDT.
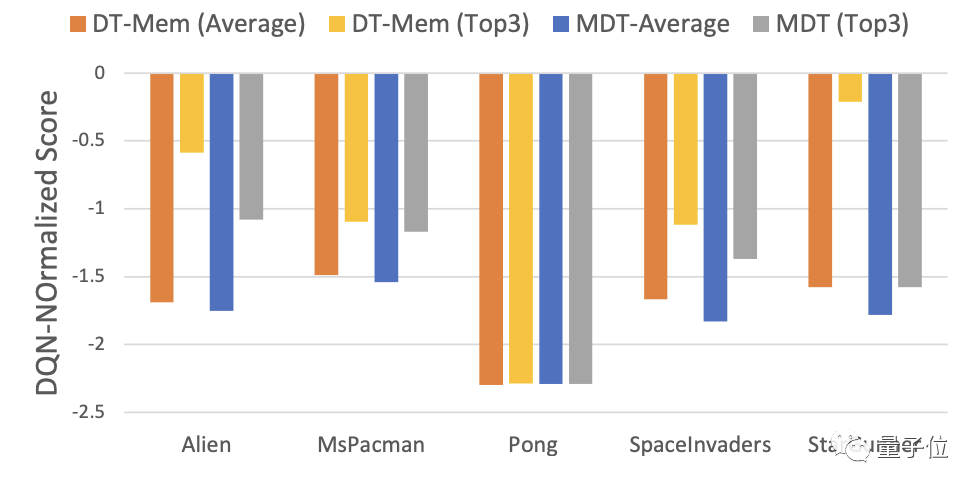
Cependant, la quantité de paramètres de DT-Mem n'est que de 20M, ce qui ne représente que 10% du MDT (200M de paramètres).
Une telle performance n’est pas du tout exagérée.
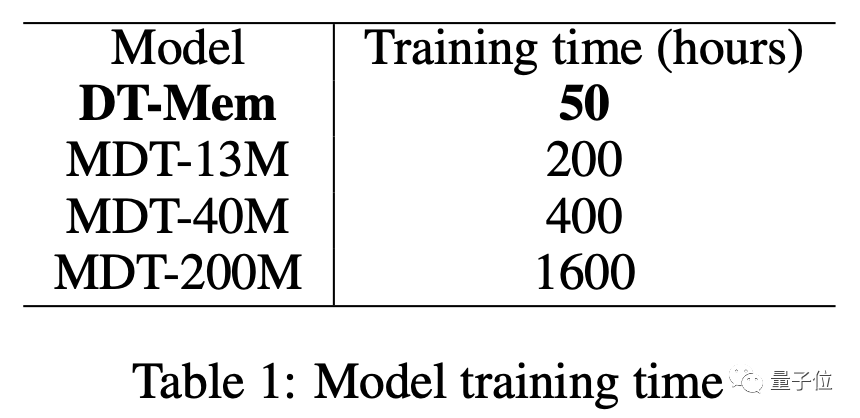
En plus de ses excellentes performances, l’efficacité de l’entraînement de DT-Mem dépasse également celle de MDT.
La version à paramètres 13M de MDT prend 200 heures pour s'entraîner, tandis que la version 20M DT-Mem ne prend que 50 heures.
Par rapport à la version 200M, le temps d'entraînement est raccourci de 32 fois, mais les performances sont encore meilleures.
Les résultats des tests de la méthode de réglage fin proposée par l'équipe montrent également que ce réglage améliore la capacité de DT-Mem à s'adapter à des scénarios inconnus.
Il convient de noter que les jeux utilisés pour les tests dans le tableau ci-dessous sont connus de MDT, donc les performances de MDT ne sont pas utilisées comme base de mesure dans ce tour.
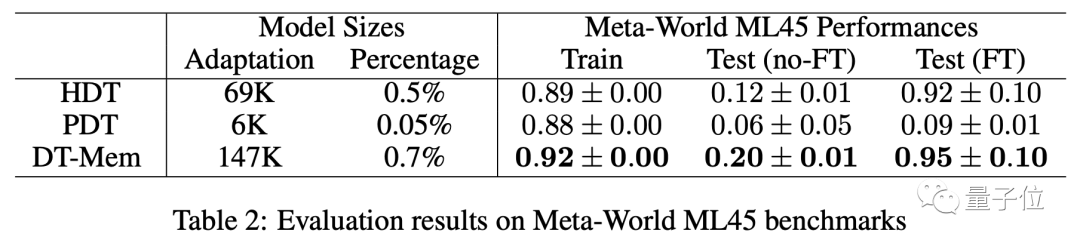
En plus de jouer à des jeux, l'équipe a également testé DT-Mem à l'aide du benchmark Meta-World ML45.
Ceux utilisés comme référence cette fois-ci sont H[yper]DT et P[romot]DT.
Les résultats montrent que parmi les modèles sans réglage fin, les performances du DT-Mem sont 8 points de pourcentage supérieures à celles du HDT.
Il convient de noter que bien que le HDT testé ici ne comporte que 69 000 paramètres, il repose sur un modèle pré-entraîné avec 2,3 millions de paramètres, de sorte que le nombre réel de paramètres est plus de 10 fois celui du DT-Mem (147 000).
Adresse papier : https://arxiv.org/abs/2305.16338
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI