
Maison >Périphériques technologiques >IA >L'Université Tsinghua et d'autres « références d'apprentissage d'outils » open source ToolBench, modèle de réglage fin, les performances de ToolLLaMA dépassent ChatGPT
L'Université Tsinghua et d'autres « références d'apprentissage d'outils » open source ToolBench, modèle de réglage fin, les performances de ToolLLaMA dépassent ChatGPT

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-06 11:12:031430parcourir
Les êtres humains ont la capacité de créer et d'utiliser des outils, nous permettant de dépasser les limites du corps et d'explorer un monde plus vaste.
Le modèle de base de l'intelligence artificielle est similaire. Si vous vous fiez uniquement aux poids obtenus lors de la phase de formation, les scénarios d'utilisation seront très limités. Cependant, l'apprentissage des outils récemment proposé combine des outils spécialisés dans des domaines spécifiques avec des outils de base à grande échelle. Modèles, peuvent atteindre une efficacité et des performances plus élevées.
Cependant, les recherches actuelles sur l'apprentissage des outils ne sont pas suffisamment approfondies et il y a un manque de données et de codes open source pertinents.
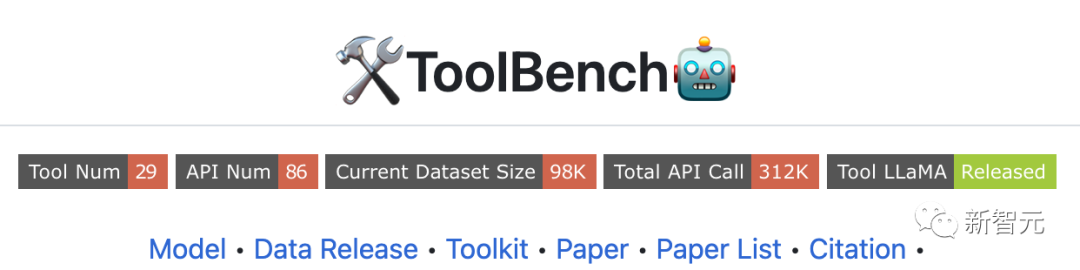
Récemment, OpenBMB (Open Lab for Big Model Base), une communauté open source soutenue par le Natural Language Processing Laboratory de l'Université Tsinghua et d'autres, a publié le projet ToolBench, qui peut aider les développeurs à créer des applications open source, à grande échelle et de haute qualité. données de réglage des instructions de qualité Facilite la construction de grands modèles de langage avec la possibilité d’utiliser des outils communs.
Lien du référentiel : https://github.com/OpenBMB/ToolBench
Le référentiel ToolBench fournit des ensembles de données pertinents, des scripts de formation et d'évaluation, ainsi que le modèle fonctionnel ToolLLaMA affiné sur ToolBench. , les fonctionnalités spécifiques sont :
1. Prise en charge des solutions à outil unique et multi-outils
Le paramètre d'outil unique suit le style d'invite LangChain et le paramètre multi-outil suit le style d'invite AutoGPT.
2. La réponse du modèle inclut non seulement la réponse finale, mais inclut également le processus de chaîne de réflexion du modèle, l'exécution de l'outil et les résultats de l'exécution de l'outil
3. Prend en charge la complexité du monde réel et les appels d'outils en plusieurs étapes
.4. API riche qui peut être utilisée pour des scénarios du monde réel, tels que les informations météorologiques, la recherche, les mises à jour des stocks et l'automatisation PowerPoint
5. Toutes les données sont automatiquement générées par l'API OpenAI et filtrées par l'équipe de développement . Le processus de création est facilement évolutif
Cependant, il est important de noter que les données publiées jusqu'à présent ne sont pas définitives et que les chercheurs sont encore en train de post-traiter les données pour améliorer la qualité des données et augmenter la couverture des outils du monde réel. .
ToolBench
L'idée générale de ToolBench est basée sur BMTools, entraînant de grands modèles de langage dans des données supervisées.
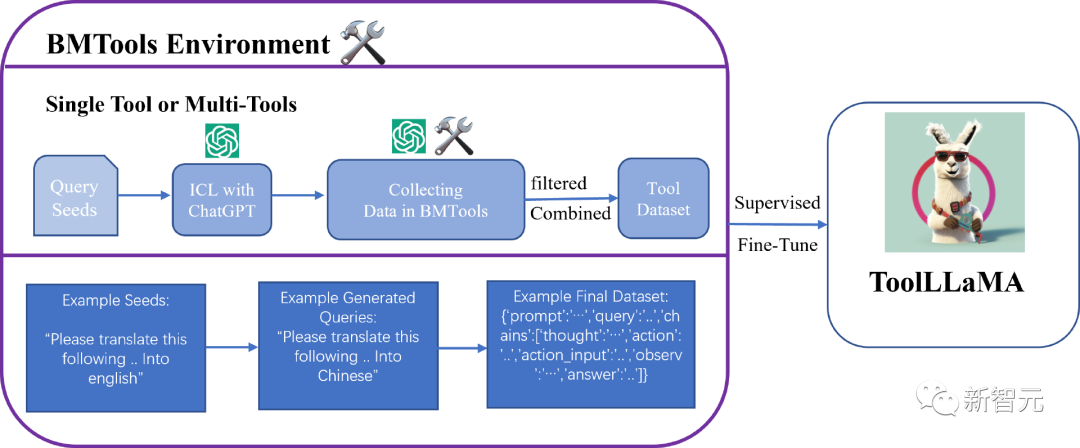
L'entrepôt contient 9 800 éléments de données obtenus à partir de 312 000 appels d'API réels, couvrant des scénarios à outil unique et des scénarios à outils multiples. Voici les informations statistiques d'un seul outil.
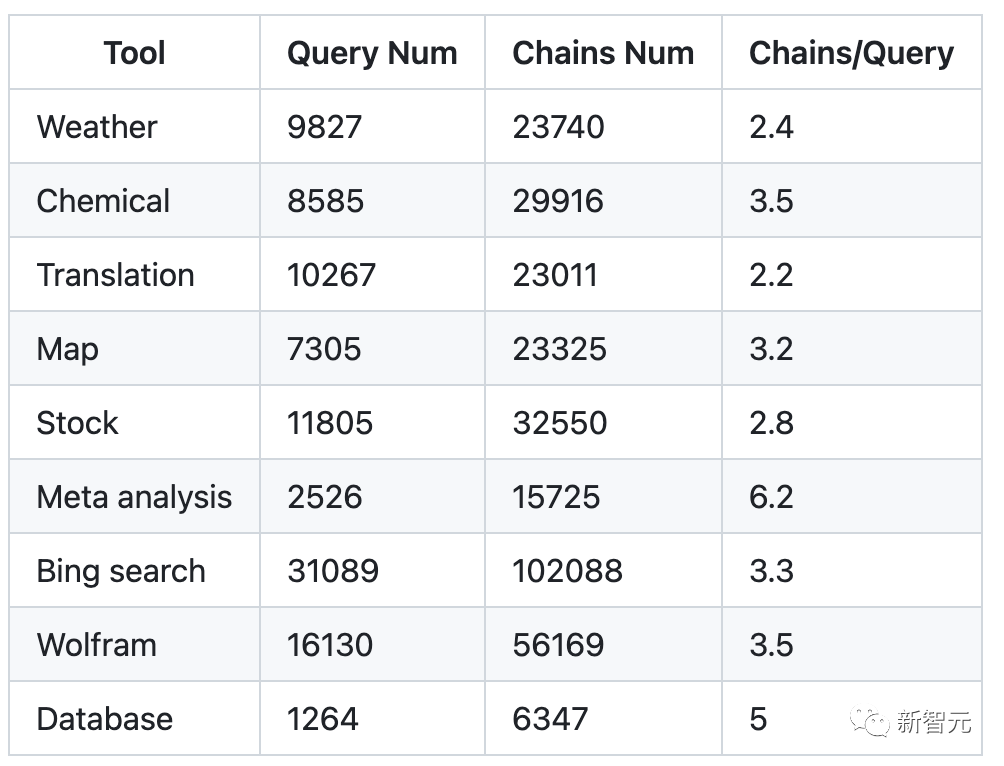
Chaque ligne de données est un dict json, comprenant le modèle d'invite pour la création de données, les instructions manuelles (requête) pour l'utilisation de l'outil, la boucle intermédiaire de réflexion/exécution de l'outil et la finale répondre.
Tool Descrition:BMTools Tool_name: translationTool action: get_translationaction_input: {"text": target texts, "tgt_lang": target language}Generated Data:{"prompt": "Answer the following questions as best you can. Specifically, you have access to the following APIs:\n\nget_translation: . Your input should be a json (args json schema): {{\"text\" : string, \"tgt_lang\" : string, }} The Action to trigger this API should be get_translation and the input parameters should be a json dict string. Pay attention to the type of parameters.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [get_translation]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times, max 7 times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin! Remember: (1) Follow the format, i.e,\nThought:\nAction:\nAction Input:\nObservation:\nFinal Answer:\n (2) Provide as much as useful information in your Final Answer. (3) Do not make up anything, and if your Observation has no link, DO NOT hallucihate one. (4) If you have enough information and want to stop the process, please use \nThought: I have got enough information\nFinal Answer: **your response. \n The Action: MUST be one of the following:get_translation\nQuestion: {input}\n Agent scratchpad (history actions):\n {agent_scratchpad}","query": "My intention is to convert the data provided in ما هي الأقسام الثلاثة للقوات المسلحة؟ into Arabic(ara).\n","chains": [{"thought": "I need to use the get_translation API to convert the text into Arabic.","action": "get_translation","action_input": "{\"text\": \"What are the three branches of the military?\", \"tgt_lang\": \"ara\"}","observation": "\"ما هي الفروع الثلاثة للجيش ؟\""}],"answer": "The translation of \"What are the three branches of the military?\" into Arabic is \"ما هي الفروع الثلاثة للجيش ؟\"."}
Expérience sur modèle
Évaluation de la machine : les chercheurs ont sélectionné au hasard 100 étapes de chaîne pour chaque outil afin de construire une plate-forme de test d'évaluation de machine, avec une moyenne de 27 étapes finales et 73 étapes d'appel d'outils intermédiaires, où la finale L'étape est évaluée à l'aide de la métrique Rouge-L et les étapes intermédiaires sont évaluées à l'aide de la métrique ExactMatch.
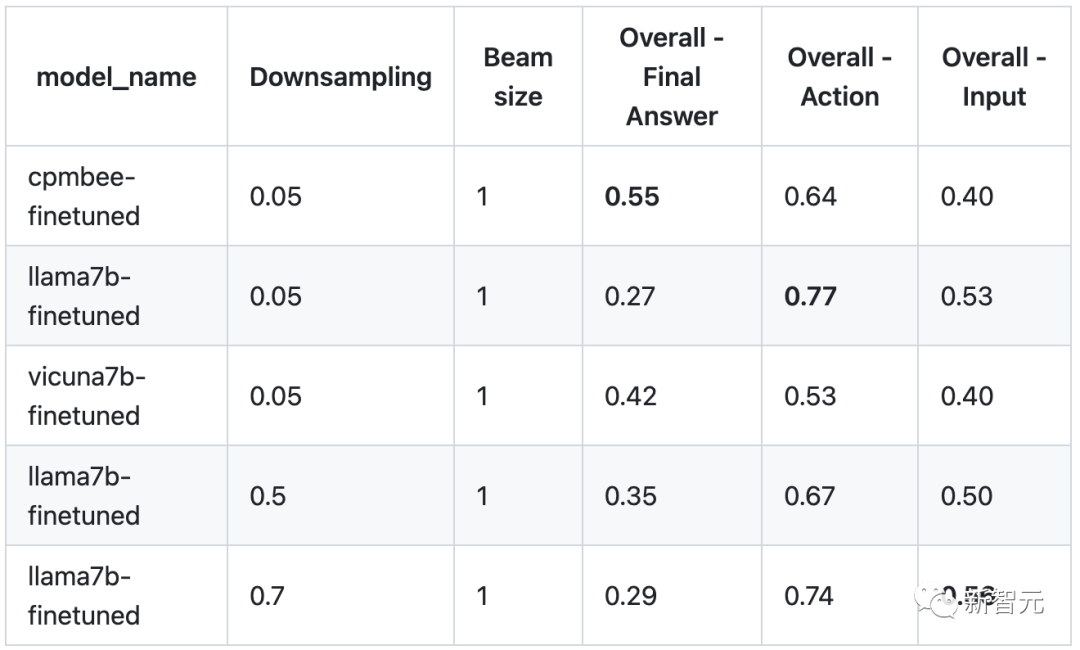
Évaluation manuelle : sélectionnez au hasard 10 requêtes parmi les outils météo, carte, stock, traduction, chimie et WolframAlpha, puis évaluez le taux de réussite du processus d'appel de l'outil, le résultat final réponse et comparaison des réponses finales de ChatGPT.
Évaluation ChatGPT : évaluation automatique des réponses et des chaînes d'utilisation des outils pour LLaMA et ChatGPT via ChatGPT.
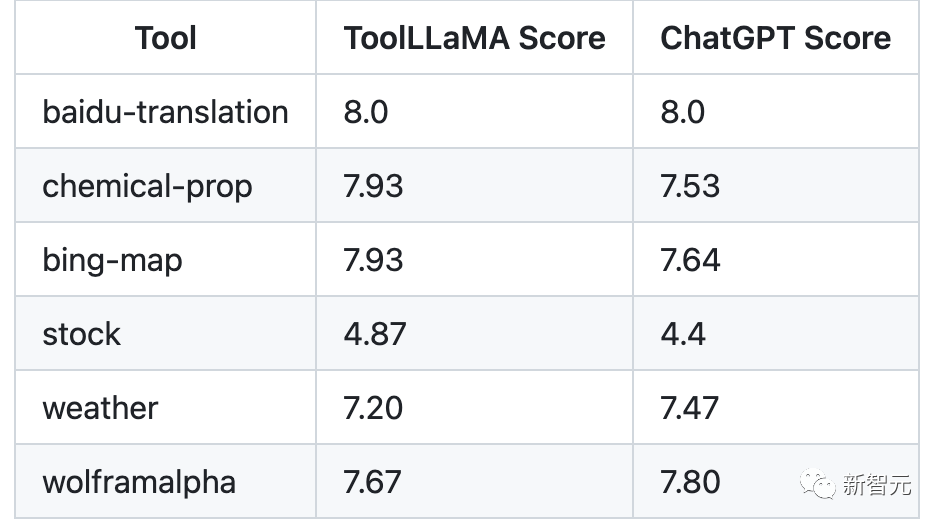
Les résultats de l'évaluation sont les suivants (plus le score est élevé, mieux c'est). On peut voir que ToolLLaMA a des performances identiques ou meilleures que ChatGPT dans différents scénarios.
Tool Learning
Dans un article publié conjointement par des collèges et universités nationaux et étrangers bien connus tels que l'Université Tsinghua, l'Université Renmin et l'Université des postes et télécommunications de Pékin, l'apprentissage par outils a été étudiée systématiquement, présente le contexte de l'apprentissage instrumental, y compris les origines cognitives, les changements de paradigme dans les modèles sous-jacents et les rôles complémentaires des outils et des modèles.

Lien papier : https://arxiv.org/pdf/2304.08354.pdf
L'article passe également en revue les recherches existantes sur l'apprentissage des outils, y compris l'apprentissage amélioré et orienté vers les outils, et formule un cadre général d'apprentissage des outils : à partir de la compréhension des instructions utilisateur, le modèle doit apprendre à décomposer une tâche complexe en plusieurs sous-composants. , adaptez dynamiquement vos plans grâce au raisonnement et maîtrisez chaque sous-tâche efficacement en choisissant les bons outils.
L'article explique également comment former des modèles pour améliorer l'utilisation des outils et promouvoir la vulgarisation de l'apprentissage des outils.
Considérant l'absence d'évaluation systématique de l'apprentissage des outils dans les travaux antérieurs, les chercheurs ont mené des expériences avec 17 outils représentatifs et ont démontré le potentiel du modèle de base actuel dans l'utilisation habile des outils.
Le document se termine en abordant plusieurs questions ouvertes dans l'apprentissage des outils qui nécessitent des recherches plus approfondies, telles que garantir une utilisation sûre et fiable des outils, mettre en œuvre la création d'outils avec des modèles de base et résoudre les défis de personnalisation.
Référence :
https://github.com/OpenBMB/ToolBench
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI