
Maison >Périphériques technologiques >IA >Sans avoir besoin d'étiqueter des données massives, le nouveau paradigme de détection de cibles OVD va encore plus loin avec l'AGI multimodale
Sans avoir besoin d'étiqueter des données massives, le nouveau paradigme de détection de cibles OVD va encore plus loin avec l'AGI multimodale

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-05 19:21:201320parcourir
La détection de cible est une tâche de base très importante en vision par ordinateur. Différente des tâches courantes de classification/reconnaissance d'images, la détection de cible nécessite que le modèle fournisse en outre des informations sur l'emplacement et la taille de la cible en plus de la catégorie de cible donnée. un poste clé comme lien entre les trois tâches majeures du CV (identification, détection et segmentation).
Le GPT-4 multimodal actuellement populaire n'a la capacité de reconnaissance de cible qu'en termes de capacités visuelles et est incapable d'effectuer des tâches de détection de cible plus difficiles. La reconnaissance des informations sur la catégorie, l'emplacement et la taille des objets dans les images ou les vidéos est la clé de nombreuses applications d'intelligence artificielle en production réelle, telles que la reconnaissance des piétons et des véhicules en conduite autonome, le verrouillage du visage dans les applications de surveillance de sécurité et l'analyse d'images médicales. , etc.
Les méthodes de détection de cibles existantes telles que la série YOLO, la série R-CNN et d'autres algorithmes de détection de cibles ont atteint une précision et une efficacité de détection de cible élevées grâce aux efforts continus des chercheurs scientifiques. Cependant, parce que les méthodes existantes doivent être testées au préalable. formation sur modèle Définissez simplement l'ensemble (ensemble fermé) de cibles à détecter, afin qu'elles ne puissent pas détecter des cibles en dehors de l'ensemble de formation. Par exemple, un modèle entraîné à détecter des visages ne peut pas être utilisé pour détecter des véhicules. dépendant de l'intelligence artificielle. Pour les données étiquetées, lorsque les catégories cibles à détecter doivent être ajoutées ou modifiées, d'une part, les données d'entraînement doivent être ré-étiquetées, et d'autre part, le modèle doit être ré-étiqueté. -formés, ce qui prend du temps et demande beaucoup de travail.
Une solution possible consiste à collecter des images massives et à étiqueter manuellement les informations Box et les informations sémantiques, mais cela nécessitera des coûts d'étiquetage extrêmement élevés, et l'utilisation de données massives pour entraîner le modèle de détection pose également des défis aux chercheurs scientifiques. Le problème de distribution à longue traîne des données et la qualité instable de l'annotation manuelle affecteront les performances du modèle de détection.
L'article OVR-CNN [1] publié dans CVPR 2021 propose un nouveau paradigme de détection de cible : la détection de vocabulaire ouvert (OVD, également connue sous le nom de détection de cible en monde ouvert) pour traiter le problème mentionné ci-dessus est le scénario de détection de objets inconnus dans le monde ouvert.
OVD a attiré l'attention continue du monde universitaire et de l'industrie depuis qu'il a été proposé en raison de sa capacité à identifier et à localiser n'importe quel nombre et catégorie de cibles sans augmenter manuellement la quantité de données annotées, et a également apporté un grand succès à la détection de cible classique. Elle apporte une nouvelle vitalité et de nouveaux défis, et devrait devenir un nouveau paradigme pour la détection de cibles à l'avenir.
Plus précisément, la technologie OVD ne nécessite pas d'annotation manuelle d'images massives pour améliorer la capacité de détection du modèle de détection pour les catégories inconnues, mais combine un détecteur de région indépendant de la classe avec une bonne généralisation avec des images massives. Le modèle formé sur des données non étiquetées est combiné pour étendre la capacité du modèle de détection de cible à comprendre les cibles du monde ouvert grâce à un alignement intermodal des caractéristiques de la zone d'image et du texte descriptif de la cible à détecter.
Les travaux de grands modèles cross-modaux et multimodaux se sont développés très rapidement récemment, comme CLIP [2], ALIGN [3] et R2D2 [4], etc., et leur développement a également favorisé la naissance de l'OVD et le domaine de l'OVD Itération et évolution rapides des travaux connexes.
La technologie OVD implique la résolution de deux problèmes clés : 1) Comment améliorer l'adaptation entre les informations régionales et les grands modèles intermodaux ; 2) Comment améliorer la généralisation des détecteurs de cibles pan-catégories à la capacité de nouvelles catégories. De ces deux perspectives, certains travaux connexes dans le domaine de l’OVD seront présentés en détail ci-dessous.
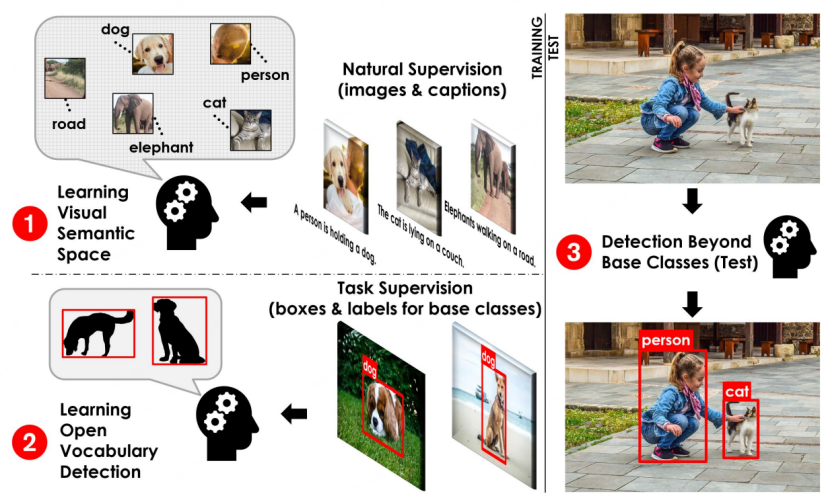
Schéma du processus de base de l'OVD [1]
Concept de base de l'OVD : L'utilisation de l'OVD implique principalement deux scénarios majeurs : quelques tirs et zéro tir, quelques tirs Il fait référence à la catégorie cible avec un petit nombre d'échantillons d'entraînement étiquetés manuellement, tandis que le tir nul fait référence à la catégorie cible sans aucun échantillon d'entraînement étiqueté manuellement. Dans les ensembles de données d'évaluation académique couramment utilisés COCO et LVIS, l'ensemble de données est divisé en classe de base et classe Novel, où la classe de base correspond au scénario à quelques tirs et la classe Novel correspond au scénario à tir zéro. Par exemple, l'ensemble de données COCO contient 65 catégories, et un paramètre d'évaluation courant est que l'ensemble de base contient 48 catégories, et seules ces 48 catégories sont utilisées dans un entraînement à quelques tirs. L'ensemble Novel contient 17 catégories, totalement invisibles pendant l'entraînement. Les indicateurs de test se réfèrent principalement à la valeur AP50 de la classe Novel à des fins de comparaison.
Article 1 : Détection d'objets à vocabulaire ouvert à l'aide de légendes

- Adresse de l'article : https://arxiv.org/pdf/2011.10678.pdf
- Code adresse : https://github.com/alirezazareian/ovr-cnn
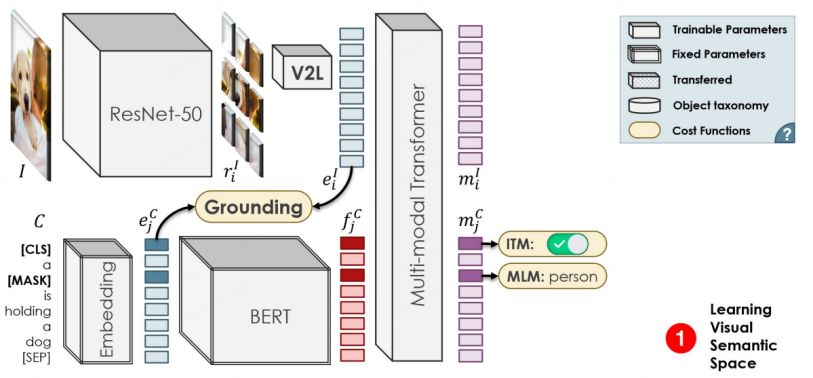
OVR-CNN est l'Oral-Paper du CVPR 2021 et un travail pionnier dans le domaine de l'OVD. Son paradigme de formation en deux étapes a influencé de nombreux travaux ultérieurs de l'OVD. Comme le montre la figure ci-dessous, la première étape utilise principalement des paires image-légende pour pré-entraîner l'encodeur visuel, dans lequel BERT (paramètres fixes) est utilisé pour générer des masques de mots, et la mise à la terre faiblement supervisée est effectuée avec ResNet50 chargé avec ImageNet. Avec des poids pré-entraînés, l'auteur pense qu'une supervision faible fera tomber l'appariement dans l'optimalité locale, c'est pourquoi un transformateur multimodal est ajouté pour la prédiction du masque de mots afin d'augmenter la robustesse.
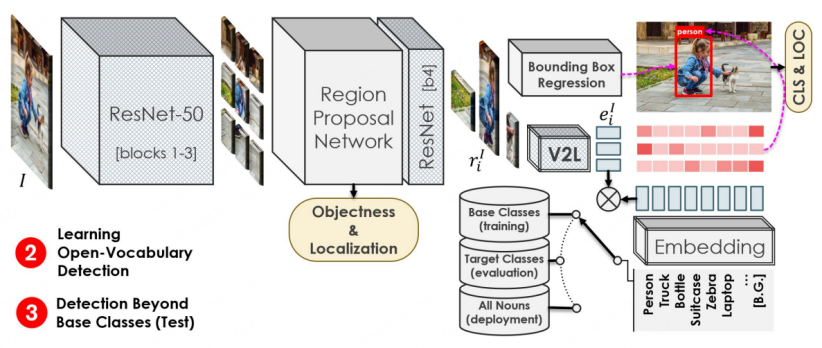
Le processus de formation de la deuxième étape est similaire à Faster-RCNN. La différence est que le backbone pour l'extraction de fonctionnalités provient des 1 à 3 couches de ResNet50 obtenues par pré-entraînement dans la première étape. ResNet50 est toujours utilisé après RPN. La quatrième couche effectue le traitement des fonctionnalités, puis utilise respectivement les fonctionnalités pour la régression de boîte et la prédiction de classification. La prédiction de classification est le signe clé que la tâche OVD est différente de la détection conventionnelle. Dans OVR-CNN, les caractéristiques sont saisies dans le module V2L (module vecteur graphique vers vecteur mot avec paramètres fixes) obtenu par un entraînement en une étape pour obtenir une image. et un vecteur de texte, qui est ensuite combiné avec le vecteur de mot d'étiquette. Dans la formation de deuxième étape, la classe Base est principalement utilisée pour effectuer une formation de régression en boîte et une formation d'appariement de catégories sur le modèle de détecteur. Puisque le module V2L est toujours fixe, il coopère avec les capacités de positionnement du modèle de détection de cible pour migrer vers de nouvelles catégories, permettant au modèle de détection d'identifier et de localiser les cibles d'une nouvelle catégorie.
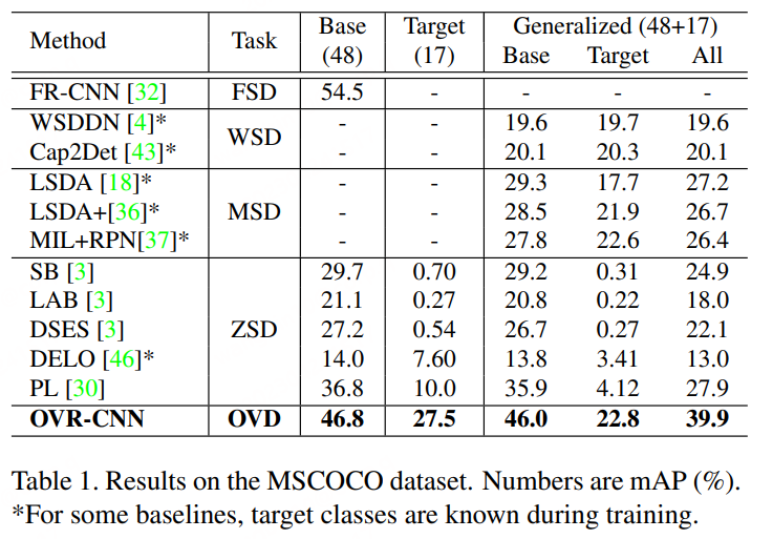
Comme le montre la figure ci-dessous, les performances d'OVR-CNN sur l'ensemble de données COCO dépassent de loin le précédent algorithme de détection d'objets Zero-shot.
Papier 2 : Préformation langue-image basée sur la région

- Adresse du papier : https://arxiv.org/abs/ 2112 .09106
- Adresse de code : https://github.com/microsoft/RegionCLIP
OVR-CNN utilise BERT et Transfomer multimodal pour la pré-entraînement des paires iamge-text, mais avec le grand cross-modal With Avec l'essor de la recherche sur les modèles, les chercheurs scientifiques ont commencé à utiliser de grands modèles intermodaux plus puissants tels que CLIP et ALIGN pour entraîner les tâches OVD. Le modèle de détecteur lui-même vise principalement à classer et à identifier les propositions, c'est-à-dire les informations régionales [5] publiées dans CVPR 2022, qui ont révélé que la capacité de classification des grands modèles actuellement existants, tels que CLIP, pour les zones cultivées est bien inférieure à celle des zones cultivées. capacité de classification de l'image originale elle-même, afin d'améliorer cela, RegionCLIP propose un nouveau schéma OVD en deux étapes.

Dans la première étape, l'ensemble de données utilise principalement des ensembles de données de correspondance d'images et de textes tels que CC3M et COCO-caption pour la pré-formation à la distillation au niveau régional. Plus précisément :
1. Extrayez les mots qui existaient à l'origine dans le texte long pour former un pool de concepts, puis formez un ensemble de descriptions simples sur la région pour la formation.
2. Utilisez RPN basé sur la pré-formation LVIS pour extraire les régions de proposition, et utilisez le CLIP original pour faire correspondre et classer les différentes régions extraites avec les descriptions préparées, puis les assembler dans de fausses étiquettes sémantiques.
3. Effectuez un apprentissage comparatif région-texte sur les nouvelles régions de proposition et les balises sémantiques sur le nouveau modèle CLIP, puis obtenez un CLIP spécialisé dans le modèle d'information sur les régions.
4. En pré-formation, le nouveau modèle CLIP apprendra également la capacité de classification du CLIP d'origine grâce à la stratégie de distillation et effectuera une image au niveau de l'image complète. -apprentissage par comparaison de texte, pour maintenir la capacité du nouveau modèle CLIP à exprimer l'image complète.
Dans la deuxième étape, le modèle pré-entraîné obtenu est transféré au modèle de détection pour un apprentissage par transfert.
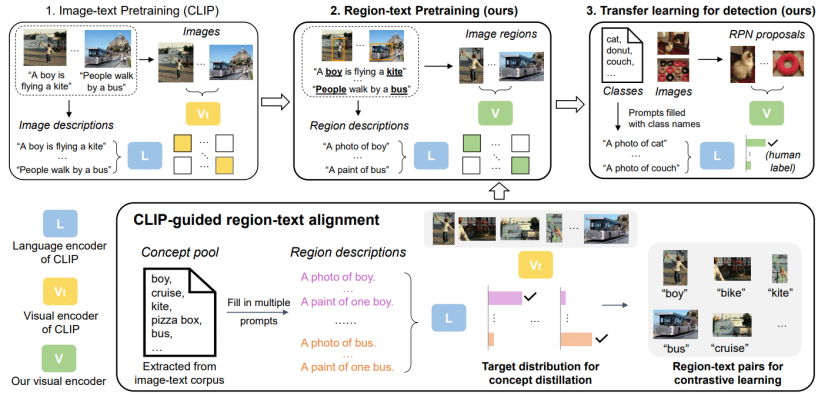
RegionCLIP étend encore les grands modèles multimodaux existants dans la détection de routine. La capacité de représentation sur le modèle a obtenu de meilleures performances. Comme le montre la figure ci-dessous, RegionCLIP a réalisé une grande amélioration dans la catégorie Novel par rapport à OVR-CNN. RegionCLIP améliore efficacement l'adaptabilité entre les informations régionales et les grands modèles multimodaux grâce à une pré-formation en une étape. Cependant, CORA estime que lorsqu'elle utilise un grand modèle intermodal plus grand avec une plus grande échelle de paramètres pour la formation en une étape, les coûts de formation augmenteront. être très élevé.
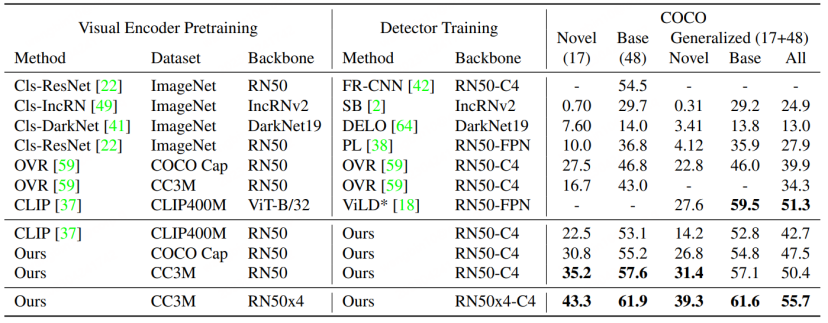
Paper 3 : CORA : Adaptation de CLIP pour Open- Détection de vocabulaire avec invite de région et pré-correspondance d'ancrage Adresse papier : https://arxiv.org/abs/2303.13076

- CORA [6] a été inclus dans le CVPR 2023, afin de surmonter son proposé Pour surmonter les deux obstacles actuellement rencontrés par les tâches OVD, un modèle OVD de type DETR est conçu. Comme le montre le titre de l'article, le modèle comprend principalement deux stratégies : Region Prompting et Anchor Pre-Matching. Le premier utilise la technologie Prompt pour optimiser les caractéristiques régionales extraites par le classificateur régional basé sur CLIP, atténuant ainsi l'écart de distribution entre l'ensemble et la région. Le second utilise la stratégie de pré-correspondance des points d'ancrage dans la méthode de détection DETR pour améliorer l'OVD. capacité du modèle à positionner de nouveaux types d'objets.
CLIP entre les caractéristiques globales de l'image et les caractéristiques régionales de l'encodeur visuel original Il existe un écart de distribution, ce qui entraîne une précision de classification inférieure du détecteur (ceci est similaire au point de départ de RegionCLIP). Par conséquent, CORA propose Region Prompting pour s’adapter à l’encodeur d’image CLIP et améliorer les performances de classification des informations régionales. Plus précisément, l'image entière est d'abord codée dans une carte de caractéristiques via les 3 premières couches de l'encodeur CLIP, puis les boîtes d'ancrage ou les boîtes de prédiction sont générées par RoI Align et fusionnées en caractéristiques régionales. Ceci est ensuite codé par la quatrième couche de l'encodeur d'image CLIP. Afin de réduire l'écart de distribution entre la carte de caractéristiques de l'image complète et les caractéristiques régionales de l'encodeur d'image CLIP, des invites de région apprenables sont configurées et combinées avec les caractéristiques produites par la quatrième couche pour générer les caractéristiques régionales finales à utiliser avec les caractéristiques de texte. Pour l'appariement, la perte d'appariement utilise une perte d'entropie croisée naïve, et les modèles de paramètres liés à CLIP sont tous gelés pendant le processus de formation.
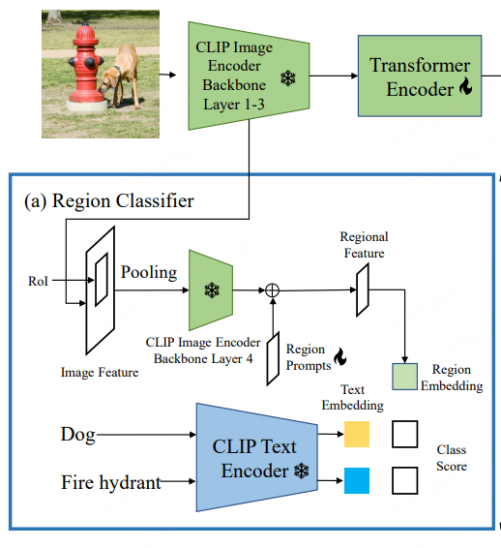
CORA est un modèle de détecteur de type DETR, similaire à DETR, qui utilise également la stratégie de pré-appariement d'ancre pour générer à l'avance des boîtes candidates pour l'entraînement à la régression des boîtes. Plus précisément, la pré-appariement des ancres associe chaque boîte d'étiquette à l'ensemble de boîtes d'ancrage le plus proche pour déterminer quelles boîtes d'ancrage doivent être considérées comme des échantillons positifs et lesquelles doivent être considérées comme des échantillons négatifs. Ce processus de mise en correspondance est généralement basé sur l'IoU (rapport d'intersection sur union). Si l'IoU entre la boîte d'ancrage et la boîte d'étiquette dépasse un seuil prédéfini, il est considéré comme un échantillon positif, sinon il est considéré comme un échantillon négatif. CORA montre que cette stratégie peut améliorer efficacement la généralisation des capacités de localisation à de nouvelles catégories.
Cependant, l'utilisation du mécanisme de pré-appariement d'ancre entraînera également certains problèmes. Par exemple, l'entraînement ne peut être effectué normalement que lorsqu'au moins une boîte d'ancrage correspond à la boîte d'étiquette. Sinon, la zone d'étiquette sera ignorée, empêchant la convergence du modèle. De plus, même si la zone d'étiquette obtient une zone de point d'ancrage plus précise, en raison de la précision de reconnaissance limitée du classificateur de région, la zone d'étiquette peut toujours être ignorée, c'est-à-dire que les informations de catégorie correspondant à la zone d'étiquette ne sont pas alignées avec le Classificateur de région basé sur la formation CLIP. Par conséquent, CORA utilise la technologie CLIP-Aligned pour exploiter les capacités de reconnaissance sémantique de CLIP et les capacités de positionnement du ROI pré-entraîné pour réétiqueter les images dans l'ensemble de données de formation avec moins de main-d'œuvre. formation Faites correspondre plus de boîtes d'étiquettes.
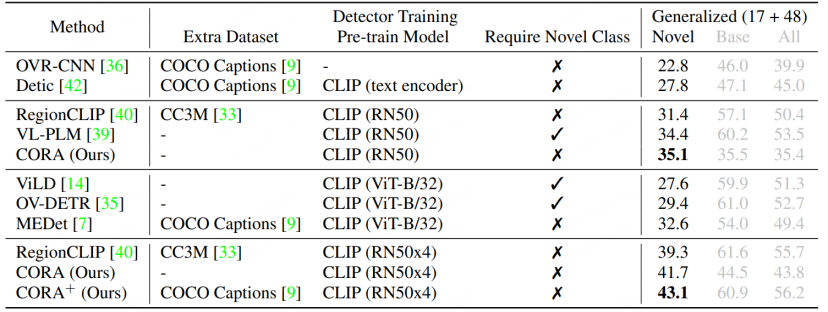
Par rapport à RegionCLIP, CORA améliore encore la valeur AP50 de 2,4 sur l'ensemble de données COCO.
Résumé et perspectives
La technologie OVD est non seulement étroitement liée au développement des grands modèles croisés/multimodaux actuellement populaires, mais hérite également de l'accumulation technologique des anciens chercheurs scientifiques dans le domaine de la détection de cibles. une technologie d'IA traditionnelle et orientée vers une convergence réussie de la recherche générale sur les capacités d'IA. L'OVD est une nouvelle technologie de détection de cibles tournée vers l'avenir. On peut s'attendre à ce que la capacité de l'OVD à détecter et à localiser n'importe quelle cible favorisera à son tour le développement ultérieur de grands modèles multimodaux et devrait devenir une pierre angulaire importante de l'AGI multimodale. en développement. À l'heure actuelle, la source de données de formation des grands modèles multimodaux est un grand nombre de paires d'informations brutes sur Internet, c'est-à-dire des paires texte-image ou des paires texte-parole. Si la technologie OVD est utilisée pour localiser avec précision les informations brutes d'origine de l'image et aider à prédire les informations sémantiques de l'image pour filtrer le corpus, la qualité des données de pré-entraînement du grand modèle sera encore améliorée, optimisant ainsi les capacités de représentation et de compréhension. du grand modèle.
Un bon exemple est SAM (Segment Anything)[7]. SAM permet non seulement aux chercheurs scientifiques de voir l'orientation future des grands modèles visuels généraux, mais déclenche également beaucoup de réflexion. Il convient de noter que la technologie OVD peut être bien connectée à SAM pour améliorer la capacité de compréhension sémantique de SAM et générer automatiquement les informations de boîte requises par SAM, libérant ainsi davantage de main-d'œuvre. De même pour l'AIGC (contenu généré par l'intelligence artificielle), la technologie OVD peut également améliorer la capacité d'interagir avec les utilisateurs. Par exemple, lorsque l'utilisateur a besoin de spécifier une certaine cible dans une image pour la modifier, ou de générer une description de la cible, il peut le faire. Utilisez les capacités de compréhension du langage d'OVD et la capacité d'OVD à détecter des cibles inconnues pour localiser avec précision les objets décrits par les utilisateurs, obtenant ainsi une génération de contenu de meilleure qualité. Les recherches pertinentes dans le domaine de l'OVD sont actuellement en plein essor, et les changements que la technologie OVD peut apporter aux futurs grands modèles généraux d'IA méritent d'être attendus avec impatience.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI