
Maison >Périphériques technologiques >IA >Explication détaillée de la structure du transformateur et de ses applications - GPT, BERT, MT-DNN, GPT-2
Explication détaillée de la structure du transformateur et de ses applications - GPT, BERT, MT-DNN, GPT-2

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-05 18:05:271784parcourir
Avant de présenter Transformer, passons en revue la structure de RNN
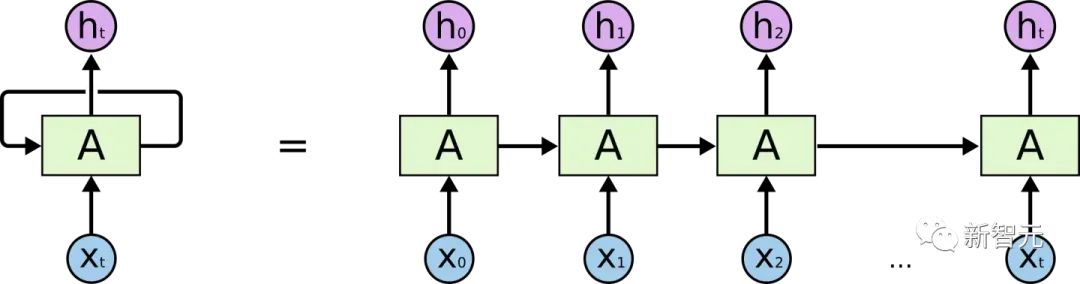
Si vous avez une certaine compréhension de RNN, vous saurez certainement que RNN a deux problèmes évidents
- Problème d'efficacité : il doit être mot par mot Pour le traitement, le mot suivant ne peut pas être traité jusqu'à ce que l'état caché du mot précédent soit sorti. Si la distance de transfert est trop longue, il y aura une disparition du gradient, une explosion du gradient et des problèmes d'oubli afin d'atténuer le gradient entre. problèmes de transferts et d'oubli, diverses cellules RNN ont été conçues, les deux plus connues sont LSTM et GRU
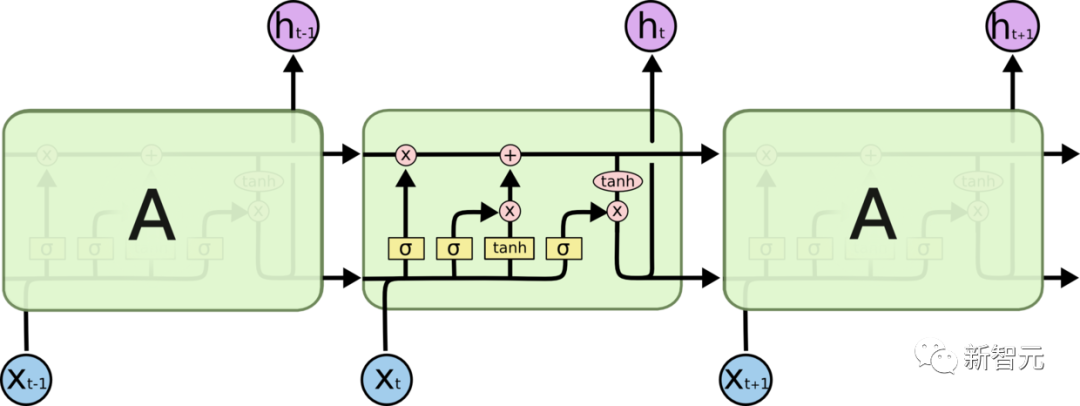
- LSTM (Long Short Term Memory)
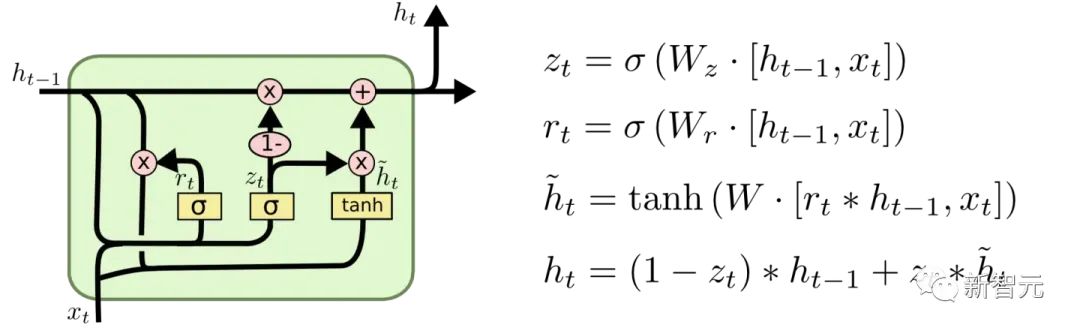
GRU (Gated Recurrent Unit)
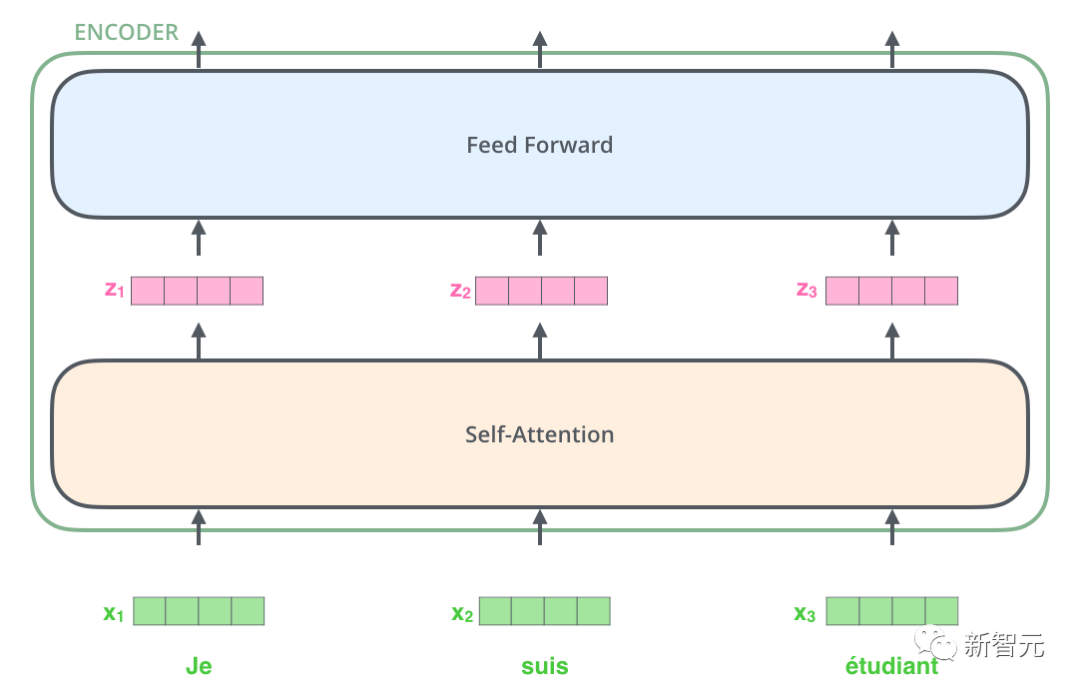
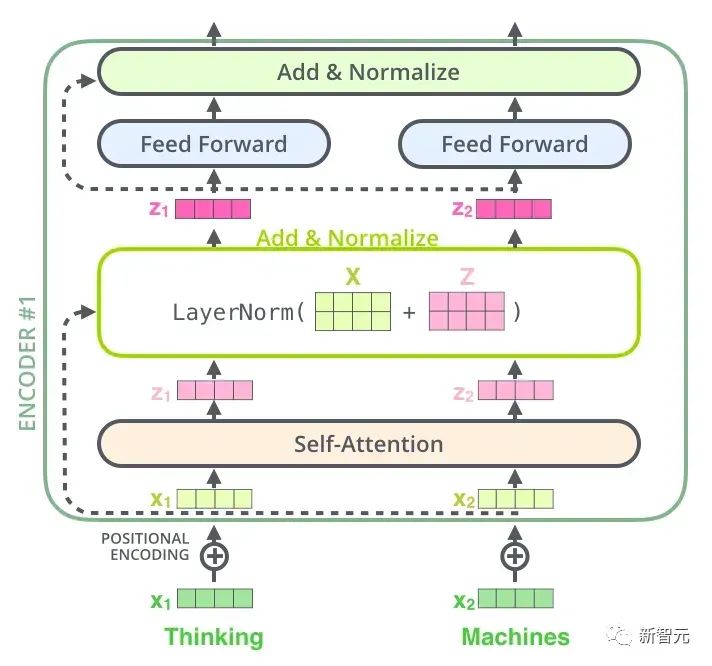
Il y a donc la structure de base que nous présenterons dans cet article - Transformer. Transformer est un travail proposé par Google Brain 2017. Il redessine les faiblesses du RNN, résout les problèmes d'efficacité du RNN et les défauts de transmission, et surpasse les performances du RNN sur de nombreux problèmes. La structure de base de Transformer est illustrée dans la figure ci-dessous. Il s'agit d'une structure N-in-N-out, c'est-à-dire que chaque unité Transformer est équivalente à une couche de couche RNN. Elle reçoit tous les mots d'une phrase entière. comme entrée, puis fournit chaque mot de la phrase. Chaque mot produit une sortie. Mais contrairement à RNN, Transformer peut traiter tous les mots de la phrase en même temps, et la distance de fonctionnement entre deux mots est de 1. Cela résout efficacement le problème d'efficacité et la question de distance de RNN mentionnés ci-dessus.
Chaque unité de transformateur comporte deux sous-couches les plus importantes, à savoir la couche d'auto-attention et la couche Feed Forward. Les structures détaillées de ces deux couches seront présentées plus tard. L'article utilise Transformer pour créer un modèle de traduction linguistique similaire à Seq2Seq et conçoit deux structures Transformer différentes pour Encoder et Decoder.
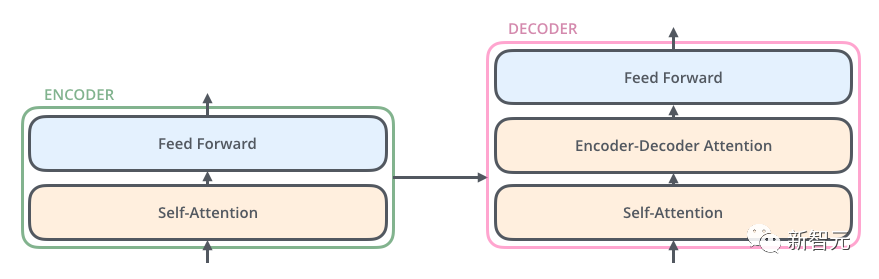
Tout d'abord, le Transformer encode la phrase dans la langue d'origine pour obtenir de la mémoire. 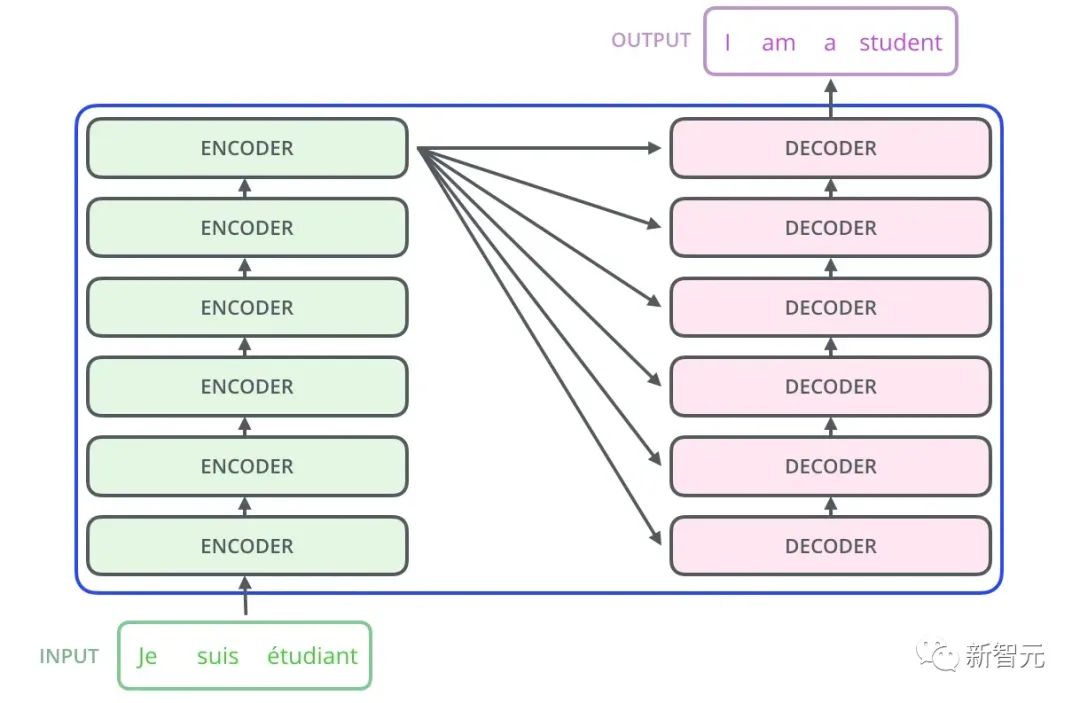
Lors du premier décodage, l'entrée n'a qu'un signe
- Le décodeur obtient une sortie unique à partir de cette entrée unique, qui est utilisée pour prédire le premier mot de la phrase.
- Décodez pour la deuxième fois. Ajoutez la première sortie à l'entrée. L'entrée devient
et le premier mot de la phrase (vérité terrain ou prédiction de l'étape précédente). est utilisé pour prédire le deuxième mot de la phrase. Par analogie (le processus est très similaire à Seq2Seq) - Après avoir compris la structure générale de Transformer et comment l'utiliser pour effectuer des tâches de traduction, jetons un œil à la structure détaillée de Transformer :
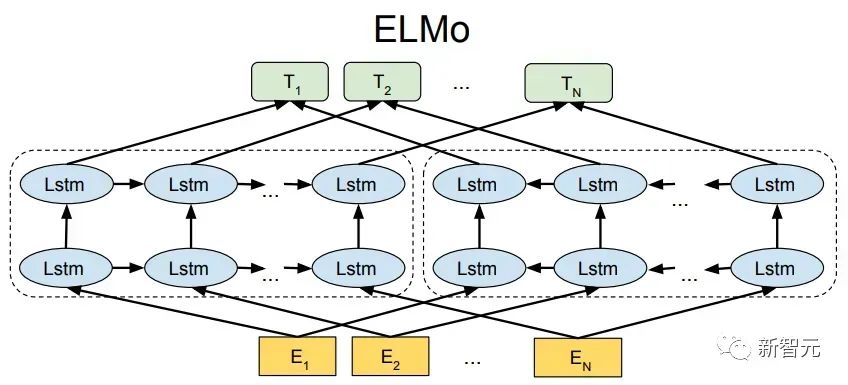
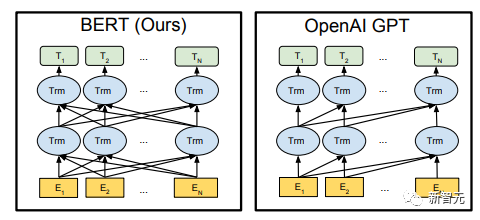
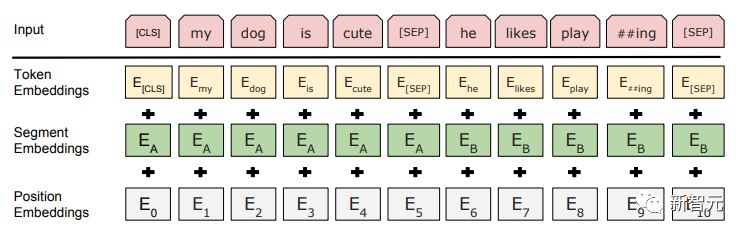
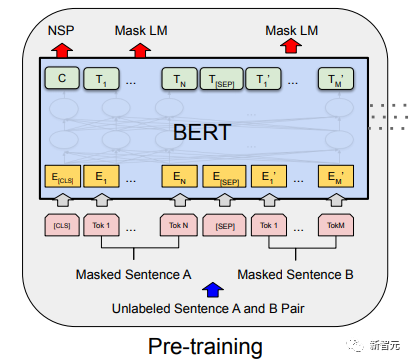
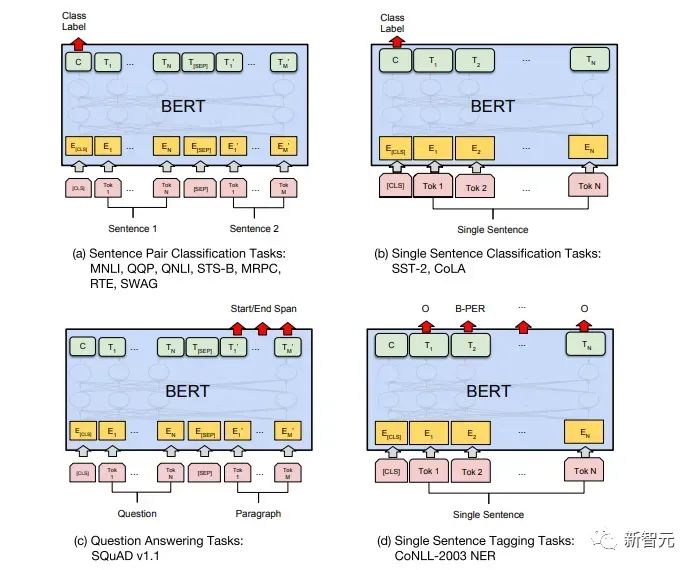
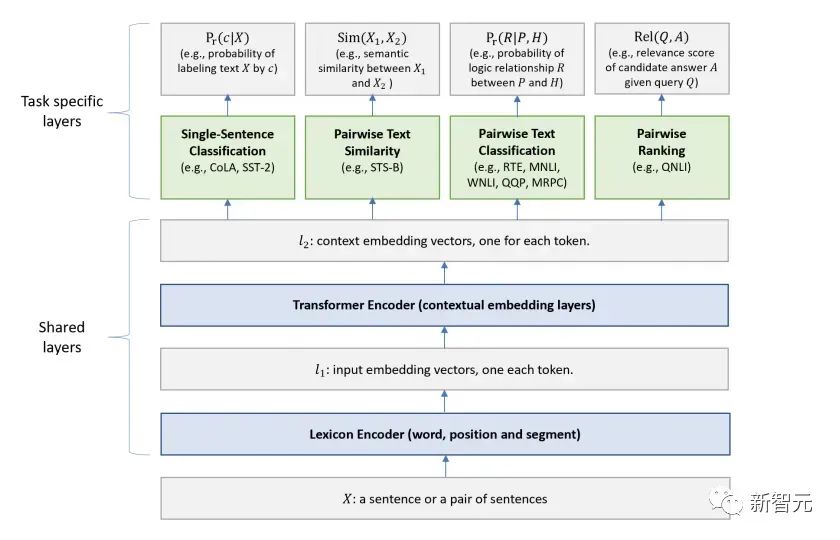
Les composants de base sont les réseaux d'auto-attention et de feed-forward mentionnés ci-dessus, mais il y a de nombreux autres détails. Ensuite, nous commencerons à interpréter la structure du transformateur par structure. Self Attention Self Attention, c'est lorsqu'un mot dans une phrase prête attention à tous ses mots. Calculez le poids de chaque mot pour ce mot, puis représentez ce mot comme la somme pondérée de tous les mots. Chaque opération d'auto-attention est comme une opération de convolution ou d'agrégation pour chaque mot. L'opération spécifique est la suivante : Tout d'abord, chaque mot subit un changement linéaire à travers trois matrices Wq, Wk, Wv, divisées en trois, et la requête, la clé et le vecteur de chaque mot sont générés. Lors de l'exécution de l'attention personnelle avec un mot comme centre, le vecteur clé du mot est utilisé pour faire le produit scalaire avec le vecteur de requête de chaque mot, puis le poids est normalisé via Softmax. Utilisez ensuite ces poids pour calculer la somme pondérée des vecteurs de tous les mots comme sortie de ce mot. Le processus spécifique est illustré dans la figure ci-dessous Avant la normalisation, il doit être standardisé en divisant par la dimension dk du vecteur, de sorte que l'attention personnelle finale puisse être exprimée comme Enfin, chaque soi L'attention peut être exprimée par transformation matricielle. Accepte n vecteurs de mots comme entrées et sorties n vecteurs agrégés. Comme mentionné ci-dessus, l'auto-attention dans l'encodeur est différente de celle du décodeur. Les Q, K et V dans l'encodeur proviennent tous de la sortie de l'unité de couche précédente, tandis que dans le décodeur, seul Q. provient de l’unité de décodage précédente, K et V proviennent tous deux de la sortie de la dernière couche de l’encodeur. En d’autres termes, le décodeur calcule le poids via l’état actuel et la sortie de l’encodeur, puis pondère l’encodage de l’encodeur pour obtenir l’état de la couche suivante. Attention masquée En observant le diagramme de structure ci-dessus, nous pouvons également trouver une autre différence entre le décodeur et l'encodeur, c'est-à-dire que la couche d'entrée de chaque unité de décodeur doit d'abord passer par une couche d'attention masquée. Alors, quelle est la différence entre Masked et la version ordinaire d’Attention ? L'encodeur doit prendre en compte le contexte de chaque mot car il souhaite encoder la phrase entière. Par conséquent, pendant le processus de calcul de chaque mot, tous les mots de la phrase peuvent être vus. Cependant, Decoder est similaire au décodeur de Seq2Seq. Chaque mot ne peut voir que l'état du mot précédent, il s'agit donc d'une structure d'auto-attention à sens unique. La mise en œuvre de l'attention masquée est également très simple, il suffit d'ajouter (&) à la matrice triangulaire inférieure précédente M avant l'étape Softmax d'auto-attention ordinaire Attention multi-têtes L'attention multi-têtes consiste à effectuer l'attention ci-dessus h fois, puis à concaténer les h sorties pour obtenir le résultat final. Cela peut grandement améliorer la stabilité de l’algorithme et a des applications pertinentes dans de nombreux travaux liés à l’attention. Dans la mise en œuvre de Transformer, afin d'améliorer l'efficacité de Multi-Head, W est agrandi de h fois, puis les k, q et v des différentes têtes du même mot sont disposés ensemble pour un calcul simultané via la vue (remodeler ) et des opérations de transposition pour terminer le calcul. Ensuite, l'épissage est à nouveau terminé par remodelage et transposition, ce qui équivaut à un traitement parallèle de toutes les têtes. Réseaux Feed Forward par position Les n vecteurs (ici n est le nombre de mots) produits par Attention dans l'encodeur et le décodeur sont respectivement entrés dans une couche entièrement connectée et complètent A par position réseau de rétroaction. Ajouter et Norm est un réseau résiduel, qui ajoute simplement l'entrée d'une couche et sa sortie standardisée. Chaque couche Self Attention et couche FFN dans Transformer sera suivie d'une couche Add & Norm. Encodage positionnel Comme il n'y a ni RNN ni CNN dans Transformer, tous les mots de la phrase sont traités de la même manière, il n'y a donc pas de relation séquentielle entre les mots. En d’autres termes, il risque de souffrir des mêmes défauts que le modèle du sac de mots. Afin de résoudre ce problème, Transformer a proposé la solution Positional Encoding, qui consiste à superposer un vecteur fixe sur chaque vecteur de mot d'entrée pour représenter sa position. Le codage positionnel utilisé dans l'article est le suivant : où pos est la position du mot dans la phrase, i est la i-ième position dans le vecteur de mot, c'est-à-dire que les vecteurs de mots de chaque mot sont superposés en une seule rangée, puis chaque colonne est superposée avec des ondes avec différentes phases ou des longueurs d'onde augmentant progressivement pour distinguer les emplacements de manière unique. "Workflow de Transformer" Chaque transformateur d'encodeur effectuera un processus d'auto-attention multi-têtes->Ajouter et normaliser->FFN->Ajouter et normaliser le processus, puis entrera la sortie dans l'encodeur suivant La sortie du dernier encodeur sera Il sera conservé en mémoire Chaque transformateur de décodeur effectuera un processus d'auto-attention multi-têtes masqué-> Auto-attention multi-têtes-> Ajouter et normaliser-> FFN-> Les Multi-K et V pendant l'auto-attention de la tête proviennent de la mémoire de l'encodeur. Générez la dernière couche d'intégration requise en fonction des exigences de la tâche. Le vecteur de sortie de Transformer peut être utilisé pour effectuer diverses tâches en aval. Bien qu'un modèle de traduction en langage naturel soit proposé dans l'article Transformer, de nombreux articles font référence à ce modèle sous le nom de Transformer. Mais nous avons toujours tendance à appeler la sous-structure de l’encodeur ou du décodeur qui utilise l’auto-attention dans l’article un transformateur. Le texte et le code source contiennent également de nombreuses autres optimisations telles que les changements dynamiques du taux d'apprentissage, l'abandon résiduel et le lissage des étiquettes, que je n'entrerai pas dans les détails ici. Les amis intéressés peuvent lire les références pertinentes pour en savoir plus. Si vous comprenez déjà le principe de Transformer, il vous suffit de comprendre les trois contenus ci-dessus pour avoir une compréhension plus approfondie de GPT. Méthode de formation pré-formation De nombreuses tâches d'apprentissage automatique nécessitent des ensembles de données étiquetés en entrée. Mais il existe autour de nous une grande quantité de données non étiquetées, telles que du texte, des images, du code, etc. L'étiquetage de ces données nécessite beaucoup de main-d'œuvre et de temps, et la vitesse d'étiquetage est bien inférieure à la vitesse de génération des données, de sorte que les données étiquetées n'occupent souvent qu'une petite partie de l'ensemble total de données. À mesure que la puissance de calcul continue de s’améliorer, la quantité de données que les ordinateurs peuvent traiter augmente progressivement. Ce serait un gaspillage si ces données non étiquetées ne pouvaient pas être utilisées à bon escient. Par conséquent, le modèle en deux étapes d'apprentissage semi-supervisé et de pré-formation + mise au point devient de plus en plus populaire. La méthode en deux étapes la plus courante est Word2Vec, qui utilise une grande quantité de texte non étiqueté pour former des vecteurs de mots avec certaines informations sémantiques, puis utilise ces vecteurs de mots comme entrée pour les tâches d'apprentissage automatique en aval, ce qui peut grandement améliorer la capacité de généralisation du modèle en aval. Mais il y a un problème avec Word2Vec, c'est-à-dire qu'un seul mot ne peut avoir qu'une seule intégration. De cette manière, la polysémie ne peut pas être bien représentée. ELMo a d'abord pensé à fournir des informations contextuelles pour chaque vocabulaire défini lors de la phase de pré-formation, en utilisant un modèle de langage basé sur bi-LSTM pour apporter une sémantique contextuelle au mot vecteur.Information : La formule ci-dessus représente respectivement le LSTM-RNN gauche et droit, et ils partagent l'entrée. vecteur de mot X Et le poids S de chaque couche de RNN, c'est-à-dire utiliser la sortie du RNN bidirectionnel pour prédire le mot suivant en même temps (le suivant à droite, le précédent à gauche), la structure spécifique est présentée dans la figure ci-dessous : #🎜 🎜# Mais ELMo utilise RNN pour compléter la pré-formation du modèle de langage, alors comment utiliser Transformer pour compléter la pré-formation ? Structure de transformateur à sens unique OpenAI GPT adopte un- façon dont Transformer accomplit cette tâche de pré-formation. Qu'est-ce qu'un Transformateur unidirectionnel ? Dans l'article Transformer, il est mentionné que le bloc Transformer utilisé par l'encodeur et le décodeur est différent. Dans le bloc décodeur, l'auto-attention masquée est utilisée, c'est-à-dire que chaque mot de la phrase ne peut prêter attention qu'à tous les mots précédents, y compris lui-même. La structure Transformer utilisée par GPT consiste à remplacer l'auto-attention dans l'encodeur par l'auto-attention masquée. La structure spécifique est la suivante : #🎜🎜. ##🎜 🎜# #🎜 🎜## 🎜🎜# En raison de l'utilisation de l'auto-attention masquée, les mots à chaque position ne "verront" pas ce qui suit ces mots, c'est-à-dire que la « réponse » ne peut pas être vue lors de la prédiction, ce qui garantit la rationalité du modèle. C'est pourquoi OpenAI utilise un transformateur unidirectionnel. Réglage fin et modifications des différentes structures de données d'entrée Ensuite, entrez dans la deuxième étape de la formation du modèle, en utilisant une petite quantité de données étiquetées pour affiner les paramètres du modèle. Nous n'avons pas utilisé la sortie du dernier mot dans l'étape précédente. Dans cette étape, nous utiliserons cette sortie comme entrée de l'apprentissage supervisé en aval. Afin d'éviter que le Fine-Tuning fasse tomber le modèle dans le surapprentissage, l'article mentionne également des méthodes d'objectifs de formation auxiliaires, similaires à un modèle multi-tâches ou à un apprentissage semi-supervisé. La méthode spécifique consiste à utiliser le résultat de prédiction du dernier mot pour un apprentissage supervisé tout en poursuivant l'apprentissage non supervisé des mots précédents, de sorte que la fonction de perte finale devienne : Pour différentes tâches, les données d'entrée doivent être modifié. Le format : Lien GitHub : https://github.com/openai/finetune-transformer-lm Post Scriptum OpenAI GPT est basé sur le utilisation de Transformer et de la méthode de formation en deux étapes. Il a fait une bonne exploration et obtenu de très bons résultats, ouvrant la voie au BERT plus tard. Modèle de formation bidirectionnelle en deux étapes - BERT BERT (Bidirectionnel Encoder Representation from Transformer) est un cadre de représentation en langage naturel basé sur Transformer proposé par Google Brain en 2018. C’est un modèle star devenu populaire dès sa proposition. Comme GPT, BERT adopte la méthode de formation Pré-formation + Mise au point et obtient de meilleurs résultats dans des tâches telles que la classification et l'étiquetage. BERT est très similaire à GPT. Les deux sont des modèles de formation en deux étapes basés sur Transformer. Les deux sont divisés en deux étapes : la pré-formation et la mise au point fine. Les deux entraînent un modèle universel dans la phase de pré-formation sans supervision. . Modèle de transformateur, puis affinez les paramètres de ce modèle lors de l'étape de réglage fin pour l'adapter aux différentes tâches en aval. Bien que BERT et GPT se ressemblent beaucoup, leurs objectifs de formation, leurs structures et utilisations de modèles sont encore légèrement différents : Transformateur bidirectionnel BERT utilise le transformateur sans masque est exactement le même que le transformateur encodeur ; structure dans l'article Transformer : Dans GPT, comme la formation du modèle de langage doit être terminée, une pré-formation est requise pour pouvoir voir uniquement les mots actuels et actuels lors de la prédiction du mot suivant. , c'est aussi la raison pour laquelle GPT a abandonné la structure bidirectionnelle originale de Transformer et a adopté une structure unidirectionnelle. BERT utilise un transformateur bidirectionnel afin d'obtenir des informations contextuelles en même temps, au lieu d'abandonner complètement les informations contextuelles comme GPT. Mais de cette façon, il n'est plus possible d'utiliser un modèle de langage normal pour la pré-formation comme GPT, car la structure de BERT fait que la sortie de chaque Transformer voit la phrase entière, peu importe ce que vous utilisez pour prédire cette sortie. vous le "verrez" "Réponse de référence, qui est la question de" se voir ". Bien qu'ELMo utilise un RNN bidirectionnel, les deux RNN sont indépendants, le problème de se voir peut donc être évité. Phase de pré-formation Ensuite, si BERT souhaite utiliser le modèle Transformer bidirectionnel, il doit abandonner le modèle de langage utilisé dans GPT comme fonction objectif de pré-formation. Au lieu de cela, BERT propose une méthode de pré-formation complètement différente. Dans Transformer, nous voulons non seulement connaître les informations ci-dessus, mais également connaître les informations ci-dessous, mais en même temps, nous devons nous assurer que l'ensemble Le modèle ne connaît pas les mots à prédire, alors ne donnez tout simplement pas au modèle les informations sur le mot. C'est-à-dire que BERT extrait certains mots qui doivent être prédits dans la phrase d'entrée, puis analyse la phrase à travers le contexte et utilise enfin la sortie de sa position correspondante pour prédire les mots extraits. C'est en fait comme faire un cloze. Cependant, le remplacement direct d'un grand nombre de mots par des balises 1 Sélectionnez aléatoirement 15 % des mots dans les données d'entrée pour la prédiction, 2,80 % de. les mots Lorsque le vecteur est saisi, il est remplacé par 3,10% des vecteurs de mots sont remplacés par les vecteurs de mots d'autres mots lors de la saisie 4 Les 10% restants restent inchangés. De cette façon, cela équivaut à dire au modèle que je peux vous donner une réponse, ou que je ne peux pas vous donner de réponse, ou que je peux vous donner une mauvaise réponse. Là où il y a BERT a également proposé une autre méthode de pré-entraînement NSP, qui est exécutée simultanément avec MLM pour former une pré-formation multitâche. Cette méthode de pré-entraînement consiste à saisir deux phrases consécutives dans le transformateur. La phrase de gauche est précédée d'une balise Afin de distinguer le contexte de deux phrases, BERT ajoute non seulement un codage positionnel, mais ajoute également un intégration de segments qui doit être appris lors de la pré-formation pour distinguer les deux phrases. De cette manière, l'entrée de BERT consiste en l'ajout de trois parties : le vecteur de mot, le vecteur de position et le vecteur de segment. De plus, les deux phrases sont distinguées à l'aide de la balise Le diagramme schématique de l'ensemble de la pré-formation est le suivant : Étape de réglage fin L'étape de réglage fin de BERT n'est pas très différente de GPT. En raison de l'utilisation d'un transformateur bidirectionnel, la cible de formation auxiliaire utilisée par GPT lors de l'étape de réglage fin, qui est le modèle de langage, est abandonnée. De plus, le vecteur de sortie pour la prédiction de classification passe de la position de sortie du dernier mot de GPT à la position Lien GitHub : https://github.com/google-research/bert Post Scriptum Personnellement, BERT n'est qu'un compromis du modèle GPT Afin d'obtenir des informations contextuelles de phrase en même temps dans les deux étapes, un modèle Transformer bidirectionnel est utilisé. Mais pour cela, nous devons payer le prix de la perte du modèle linguistique traditionnel et utiliser à la place une méthode plus complexe telle que MLM+NSP pour la pré-formation. Modèle multitâche - MT-DNN MT-DNN (Multi-Task Deep Neural Networks) utilise toujours la méthode de formation en deux étapes et le transformateur bidirectionnel de BERT. Dans la phase de pré-formation, MT-DNN est presque identique à BERT, mais dans la phase de réglage fin, MT-DNN adopte une méthode de réglage fin multitâche. Dans le même temps, la sortie de contexte Embedding de Transformer est utilisée pour la formation sur des tâches telles que la classification de phrases uniques, la similarité de paires de textes, la classification de paires de textes et les questions et réponses. La structure entière est présentée dans la figure ci-dessous : Lien GitHub : https://github.com/namisan/mt-dnn GPT-2 Le modèle de transformateur unidirectionnel utilisé à l'origine dans GPT continue d'être utilisé, et le but de cet article est de tirer parti autant que possible du transformateur unidirectionnel pour faire quelque chose que le transformateur bidirectionnel utilisé par BERT. ne peut pas faire. Il s’agit de générer le texte suivant à partir de ce qui précède. L'idée de GPT-2 est d'abandonner complètement le processus de réglage fin et d'utiliser à la place une formation non supervisée de plus grande capacité et un modèle linguistique plus général pour effectuer une variété de tâches. Nous n'avons pas du tout besoin de définir les tâches que ce modèle doit effectuer, car les informations contenues dans de nombreuses balises existent dans le corpus. Tout comme si une personne lit beaucoup de livres, elle peut facilement résumer automatiquement, répondre aux questions et continuer à écrire des articles en fonction du contenu qu'elle a lu. À proprement parler, GPT-2 n'est peut-être pas un modèle multitâche, mais il utilise le même modèle et les mêmes paramètres pour effectuer différentes tâches. Habituellement, nous formons un modèle dédié pour une tâche spécifique. Étant donné une entrée, nous pouvons renvoyer la sortie correspondante de la tâche, qui est Donc, si nous voulons concevoir un modèle général, ce modèle. donnera En plus de spécifier l'entrée, vous devez également spécifier le type de tâche, puis effectuer la sortie correspondante en fonction de l'entrée et de la tâche données. Ensuite, le modèle peut être exprimé comme suit C'est comme moi. besoin de traduire une phrase, un modèle de traduction doit être spécialement conçu. Si vous souhaitez un système de questions et réponses, un modèle de questions et réponses doit être spécialement conçu. Mais si un modèle est suffisamment intelligent et peut générer un contexte basé sur votre contexte, nous pouvons alors distinguer divers problèmes en ajoutant des identifiants à l'entrée. Par exemple, nous pouvons lui demander directement : ("Natural Language Processing", traduction chinoise) pour obtenir les résultats dont nous avons besoin en Nature Language Processing. À mon avis, GPT-2 ressemble plus à un système de questions et réponses omniscient en informant l'identifiant d'une tâche donnée, il peut apporter des réponses appropriées aux questions et réponses dans divers domaines et tâches. GPT-2 satisfait au paramètre zéro tir. Il n'est pas nécessaire de lui indiquer les tâches qu'il doit accomplir pendant le processus de formation, et la prédiction peut également donner une réponse plus raisonnable. Alors, qu'a fait GPT-2 pour répondre aux exigences ci-dessus ? Élargissez et agrandissez l'ensemble de données La première chose est de rendre le modèle bien lu S'il n'y a pas suffisamment d'échantillons d'entraînement, comment pouvons-nous effectuer l'inférence ? Les travaux précédents étaient axés sur un problème spécifique, de sorte que les ensembles de données étaient relativement unilatéraux. GPT-2 collecte un ensemble de données de plus en plus large. Dans le même temps, nous devons garantir la qualité de cet ensemble de données et conserver des pages Web avec un contenu de haute qualité. Enfin, un ensemble de données WebText de 8 millions de textes et 40G a été formé. Agrandissez la capacité du réseau Si vous avez trop de livres, vous devez en emporter avec vous, sinon vous ne pourrez pas vous souvenir des éléments du livre. Afin d'augmenter la capacité du réseau et de lui donner un potentiel d'apprentissage plus fort, GPT-2 a augmenté le nombre de couches de la pile Transformer à 48 couches, la dimension de la couche cachée était de 1 600 et le nombre de paramètres a atteint 1,5 milliard. Ajuster la structure du réseau GPT-2 augmente le vocabulaire à 50257, la taille maximale du contexte (taille du contexte) passe de 512 à 1024 pour GPT et la taille du lot passe de 512 à 1024. De plus, de petits ajustements ont été apportés au transformateur. La couche de normalisation a été placée avant chaque sous-bloc, et une couche de normalisation a été ajoutée après la dernière auto-attention, la méthode d'initialisation de la couche résiduelle a été modifiée, etc. Lien GitHub : https://github.com/openai/gpt-2 Post Scriptum En fait, la chose la plus étonnante à propos de GPT-2 est sa génération extrêmement forte capacité, et des capacités de génération aussi puissantes sont principalement dues à la qualité de ses données et à son nombre étonnant de paramètres et à son échelle de données. Le nombre de paramètres de GPT-2 est si grand que le modèle utilisé pour les expériences est toujours dans un état sous-ajusté. S'il est davantage entraîné, l'effet peut être encore amélioré. En résumé du développement ci-dessus du travail de Transformer, j'ai également compilé quelques réflexions personnelles sur les tendances de développement de l'apprentissage profond : 1. ou même sans supervision Le taux de croissance de l'échelle des données dépasse de loin la vitesse d'étiquetage des données, ce qui a également conduit à la génération d'une grande quantité de données non étiquetées. Ces données non étiquetées ne sont pas sans valeur. Au contraire, si vous trouvez la bonne « alchimie », vous pourrez tirer une valeur inattendue de ces données massives. Comment utiliser ces données non étiquetées pour améliorer les performances des tâches est devenu une question de plus en plus importante qui ne peut être ignorée. 2. Des modèles complexes avec une petite quantité de données aux modèles simples avec une grande quantité de données La capacité d'adaptation des réseaux de neurones profonds est très puissante, et un simple modèle de réseau de neurones suffit pour s'adapter à n'importe quelle fonction. Cependant, il est difficile d’utiliser une structure de réseau plus simple pour accomplir la même tâche, et les exigences en matière de volume de données sont également plus élevées. Plus la quantité de données augmente et la qualité des données s'améliore, plus les exigences du modèle diminuent. Plus la quantité de données est importante, plus il est facile pour le modèle de capturer des caractéristiques cohérentes avec les distributions du monde réel. Word2Vec en est un exemple. La fonction objectif qu'il utilise est très simple, mais comme une grande quantité de texte est utilisée, les vecteurs de mots formés contiennent de nombreuses fonctionnalités intéressantes. 3. Le développement de modèles spécialisés vers des modèles généraux GPT, BERT, MT-DNN et GPT-2 utilisent tous des modèles généraux pré-entraînés pour poursuivre les tâches d'apprentissage automatique en aval. le modèle lui-même serait requis. Si la capacité d'expression d'un modèle est suffisamment forte et la quantité de données utilisée lors de la formation est suffisamment importante, alors le modèle sera plus polyvalent et n'aura pas besoin d'être trop modifié pour des tâches spécifiques. Le cas le plus extrême est celui de GPT-2, qui peut entraîner un modèle multitâche général sans même savoir quelles sont les tâches ultérieures en aval pendant la formation. 4. Exigences accrues en matière d'échelle et de qualité des données Bien que GPT, BERT, MT-DNN et GPT-2 se soient classés plus haut les uns après les autres, je pense que dans l'amélioration des performances, l'amélioration de l'échelle des données représente une plus grande proportion que l'ajustement structurel. Avec la généralisation et la simplification des modèles, afin d'améliorer les performances du modèle, une plus grande attention se déplacera de la manière de concevoir un modèle complexe et spécialisé vers la manière d'obtenir, de nettoyer et d'affiner un grand nombre de modèles de qualité supérieure. les données. L'effet de l'ajustement de la méthode de traitement des données sera supérieur à l'effet de l'ajustement de la structure du modèle. En résumé, la compétition DL deviendra tôt ou tard une compétition entre grands constructeurs pour les ressources et la puissance de calcul. Un nouveau sujet pourrait émerger d’ici quelques années : l’IA verte, l’IA bas carbone, l’IA durable… 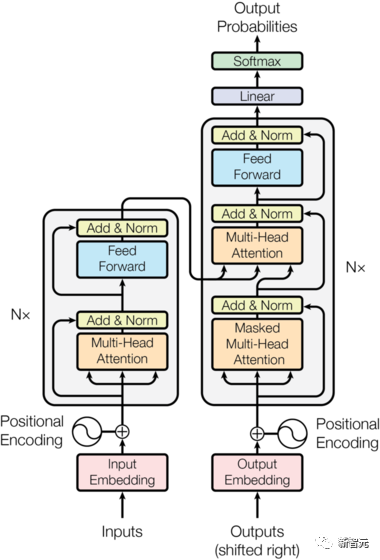
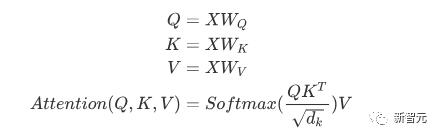
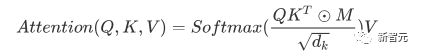
. Affiner les modifications avec différentes structures de données d'entrée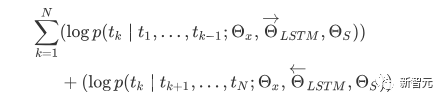
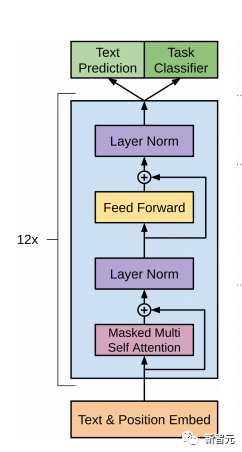
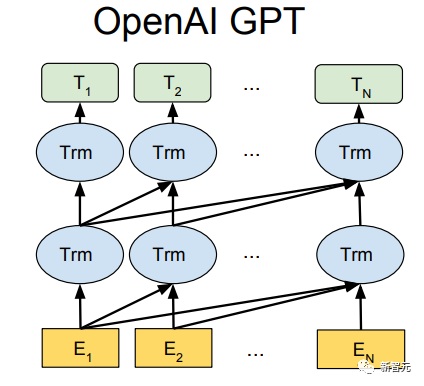 Puisqu'un transformateur unidirectionnel est utilisé, seuls les mots ci-dessus peuvent être vus, le modèle de langage est donc :
Puisqu'un transformateur unidirectionnel est utilisé, seuls les mots ci-dessus peuvent être vus, le modèle de langage est donc : 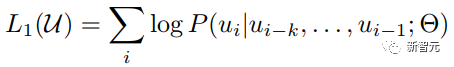
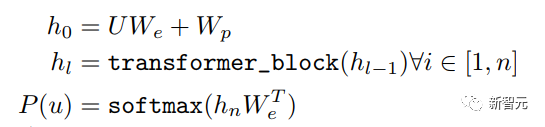
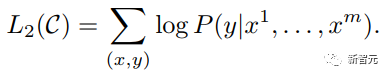
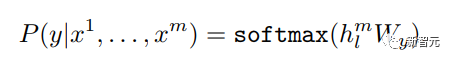
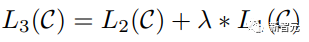
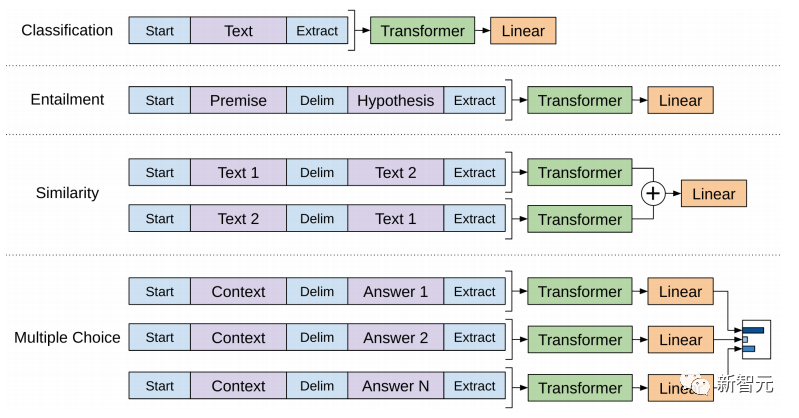
Modèle universel unidirectionnel - GPT-2
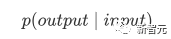
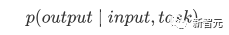
Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI