
Maison >Périphériques technologiques >IA >Le rival de Midjourney est là ! L'as StyleDrop de Google 'Customization Master' fait exploser le cercle de l'art de l'IA
Le rival de Midjourney est là ! L'as StyleDrop de Google 'Customization Master' fait exploser le cercle de l'art de l'IA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-05 13:33:25868parcourir
Dès que Google StyleDrop est sorti, il a instantanément fait son apparition sur Internet.
Avec la Nuit étoilée de Van Gogh, AI devient Maître Van Gogh et crée d'innombrables peintures similaires après une compréhension de haut niveau de ce style abstrait.

Un autre style de dessin animé, les objets que je veux dessiner sont beaucoup plus mignons.

Même, il peut contrôler avec précision les détails et concevoir un logo de style original.

Le charme de StyleDrop est que vous n'avez besoin que d'une seule image comme référence, quelle que soit la complexité du style artistique, vous pouvez le déconstruire et le recréer.
Les internautes ont dit que c'est le genre d'outil d'IA qui élimine les concepteurs.
StyleDrop hot search est le dernier produit de l'équipe de recherche de Google.

Adresse papier : https://arxiv.org/pdf/2306.00983.pdf
Maintenant, avec des outils comme StyleDrop, non seulement vous pouvez dessiner de manière plus contrôlable, mais vous pouvez également compléter le travail précédent Travail incroyablement détaillé, comme dessiner un logo.
Même les scientifiques de NVIDIA l'ont qualifié de réalisation « phénoménale ».

Maître "Personnalisation"
L'auteur de l'article a expliqué que l'inspiration pour StyleDrop venait d'Eyedropper (outil d'absorption/sélection des couleurs).
De même, StyleDrop espère également que tout le monde pourra « choisir » rapidement et sans effort un style parmi une ou quelques images de référence pour générer une image de ce style.

Un paresseux peut avoir 18 styles :

Un panda peut avoir 24 styles :

Une aquarelle dessinée par un enfant, Style Laissez tomber un contrôle parfait, même les plis du papier ont été restaurés.
Je dois dire que c'est trop fort.

Il existe également le design StyleDrop de lettres anglaises basées sur différents styles :

C'est aussi une lettre de style Van Gogh.

Il y a aussi des dessins au trait. Le dessin au trait est une image très abstraite et nécessite une très grande rationalité dans la composition de l'image. Les méthodes précédentes étaient difficiles à réussir.

Les traits de l'ombre du fromage dans l'image originale sont restitués aux objets de chaque image.

Référez-vous à la création du LOGO Android.

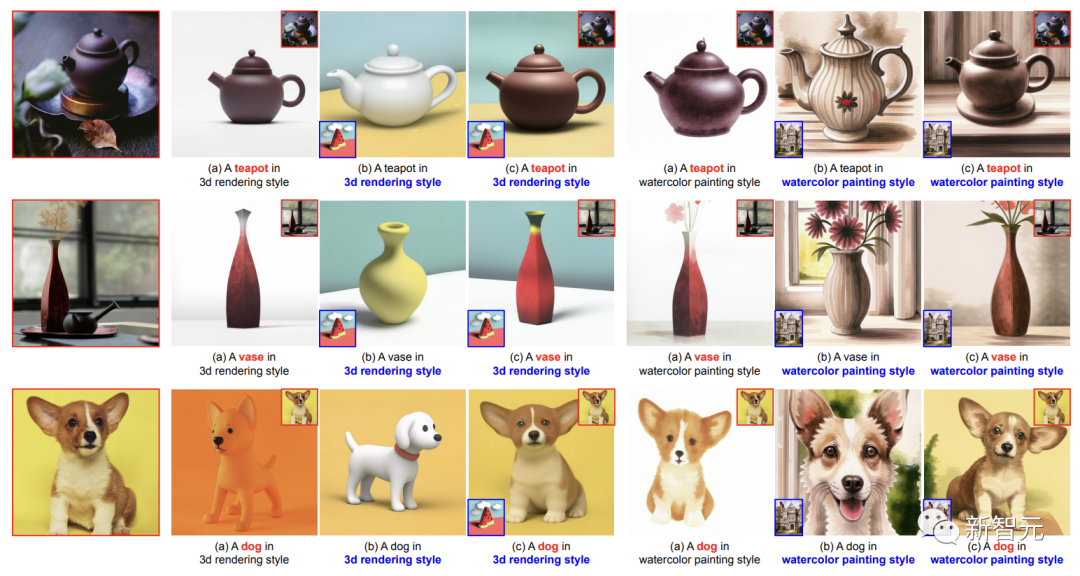
De plus, les chercheurs ont également étendu les capacités de StyleDrop, non seulement pour personnaliser le style, combiné avec DreamBooth, mais aussi pour personnaliser le contenu.
Par exemple, toujours dans le style Van Gogh, générez une peinture de style similaire pour le petit Corgi :
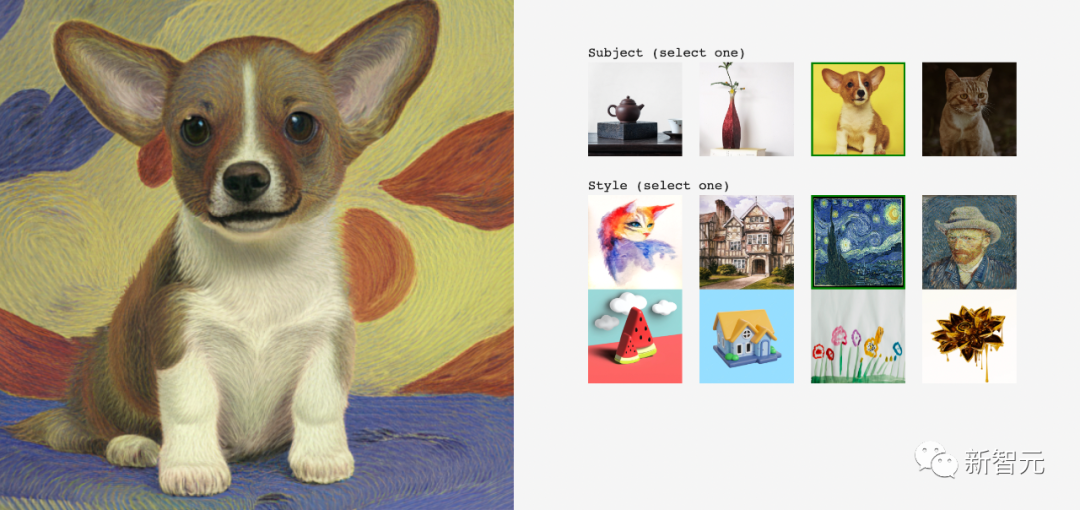
En voici une autre, le Corgi ci-dessous ressemble au "Sphinx" des pyramides égyptiennes. .

Comment ça marche ?
StyleDrop est construit sur Muse et se compose de deux parties clés :
L'une est le réglage fin efficace des paramètres du transformateur visuel généré, et l'autre est une formation itérative avec feedback.
Après cela, les chercheurs ont synthétisé les images des deux modèles affinés.
Muse est le dernier modèle de synthèse texte-image basé sur un transformateur d'image généré par masque. Il contient deux modules de synthèse pour la génération d'images de base (256 × 256) et la super-résolution (512 × 512 ou 1024 × 1024).

Chaque module se compose d'un encodeur de texte T, d'un transformateur G, d'un échantillonneur S, d'un encodeur d'image E et d'un décodeur D.
T mappe l'invite textuelle t∈T à l'espace d'intégration continue E. G traite les intégrations de texte e ∈ E pour générer des logarithmes de séquences de jetons visuels l ∈ L. S extrait une séquence de jetons visuels v ∈ V du logarithme via un décodage itératif qui exécute plusieurs étapes d'inférence de transformateur conditionnées par le texte intégrant e et les jetons visuels décodés à partir des étapes précédentes.
Enfin, D mappe la séquence de jetons discrets à l'espace de pixels I. En résumé, étant donné une invite de texte t, la synthèse de l'image I est la suivante :
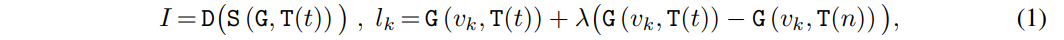
La figure 2 est une architecture simplifiée de la couche de transformateur Muse, qui a été partiellement modifiée pour prendre en charge le paramètre d'efficacité Trim (PEFT) avec adaptateur.
Utilisez le transformateur de la couche L pour traiter la séquence de jetons visuels affichée en vert sous la condition d'intégration de texte e. Les paramètres appris θ sont utilisés pour construire des poids pour le réglage de l'adaptateur.

Pour entraîner θ, dans de nombreux cas, les chercheurs ne peuvent donner des images qu'à titre de références de style.
Les chercheurs doivent joindre manuellement des invites textuelles. Ils ont proposé une approche simple et basée sur un modèle pour créer des invites textuelles consistant en une description du contenu suivie d'une phrase de style description.
Par exemple, le chercheur utilise « chat » pour décrire un objet dans le tableau 1, et ajoute « aquarelle » comme description de style.

Inclure une description du contenu et du style dans une invite de texte est crucial car cela permet de séparer le contenu du style, ce qui est l'objectif principal du chercheur.
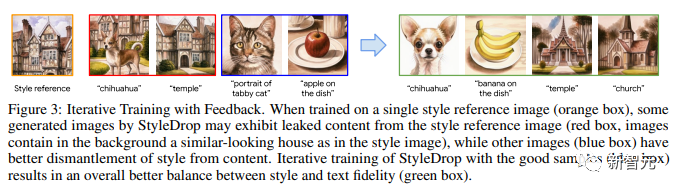
La figure 3 montre une formation itérative avec feedback.
Lors d'un entraînement sur une seule image de référence de style (case orange), certaines images générées par StyleDrop peuvent présenter du contenu extrait de l'image de référence de style (case rouge, le fond de l'image contient des éléments similaires à l'image de style maison).
D'autres images (cases bleues) séparent mieux le style du contenu. L'entraînement itératif de StyleDrop sur de bons échantillons (encadré bleu) permet d'obtenir un meilleur équilibre entre le style et la fidélité du texte (encadré vert).
Ici, les chercheurs ont également utilisé deux méthodes :
-CLIP score
Cette méthode est utilisée pour mesurer l'alignement des images et du texte. Par conséquent, il peut évaluer la qualité des images générées en mesurant le score CLIP (c'est-à-dire la similarité cosinusoïdale des intégrations CLIP visuelles et textuelles).
Les chercheurs peuvent sélectionner l'image CLIP avec le score le plus élevé. Ils appellent cette méthode la formation itérative (CF) CLIP-feedback.
Au cours d'expériences, les chercheurs ont découvert que l'utilisation des scores CLIP pour évaluer la qualité des images synthétiques est un moyen efficace d'améliorer le rappel (c'est-à-dire la fidélité textuelle) sans perte excessive de fidélité du style.
D'un autre côté, cependant, les partitions CLIP peuvent ne pas s'aligner entièrement sur l'intention humaine, ni capturer des attributs stylistiques subtils.
-HF
Le feedback humain (HF) est un moyen plus direct d'injecter l'intention de l'utilisateur directement dans l'évaluation de la qualité des images synthétiques.
En matière de mise au point LLM pour l'apprentissage par renforcement, HF a prouvé sa puissance et son efficacité.
HF peut être utilisé pour compenser l'incapacité des scores CLIP à capturer des attributs de style subtils.
Actuellement, de nombreuses recherches se sont concentrées sur le problème de personnalisation des modèles de diffusion texte-image pour synthétiser des images contenant plusieurs styles personnels.
Les chercheurs montrent comment DreamBooth et StyleDrop peuvent être combinés de manière simple pour personnaliser à la fois le style et le contenu.
Cela se fait en échantillonnant à partir de deux distributions génératives modifiées, guidées par θs pour le style et θc pour le contenu, respectivement des paramètres d'adaptateur formés indépendamment sur les images de référence de style et de contenu.
Contrairement aux produits existants, l'approche de l'équipe ne nécessite pas de formation conjointe de paramètres apprenables sur plusieurs concepts, ce qui conduit à de plus grandes capacités combinatoires car les adaptateurs pré-entraînés sont formés séparément sur des sujets et des styles individuels.
Le processus d'échantillonnage global des chercheurs suit le décodage itératif de l'équation (1), avec une manière différente d'échantillonner les logarithmes à chaque étape de décodage.
Soit t l'invite de texte et c l'invite de texte sans descripteur de style. Le logarithme est calculé à l'étape k comme suit :
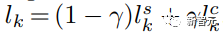
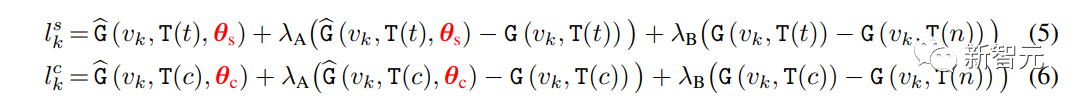
où : γ est utilisé pour équilibrer StyleDrop et DreamBooth - si γ est 0, nous obtenons StyleDrop, si 1, nous obtenons DreamBooth.
En réglant γ de manière appropriée, nous pouvons obtenir une image appropriée.
Configuration expérimentale
Jusqu'à présent, il n'y a pas eu de recherches approfondies sur l'ajustement de style des modèles génératifs texte-image.
Par conséquent, les chercheurs ont proposé un nouveau plan expérimental :
-collecte de données
Les chercheurs ont collecté des dizaines d'images de styles différents, allant des aquarelles et peintures à l'huile, des illustrations plates, des rendus 3D à différentes sculptures matérielles. .
- Configuration du modèle
Les chercheurs utilisent des adaptateurs pour régler StyleDrop basé sur Muse. Pour toutes les expériences, l'optimiseur Adam a été utilisé pour mettre à jour les poids de l'adaptateur sur 1 000 étapes avec un taux d'apprentissage de 0,00003. Sauf indication contraire, les chercheurs utilisent StyleDrop pour représenter le modèle du deuxième tour, qui a été formé sur plus de 10 images synthétiques avec retour humain.
-Évaluation
Évaluation quantitative des rapports de recherche basés sur CLIP, mesurant la cohérence du style et l'alignement du texte. De plus, les chercheurs ont mené des études sur les préférences des utilisateurs pour évaluer la cohérence du style et l’alignement du texte.
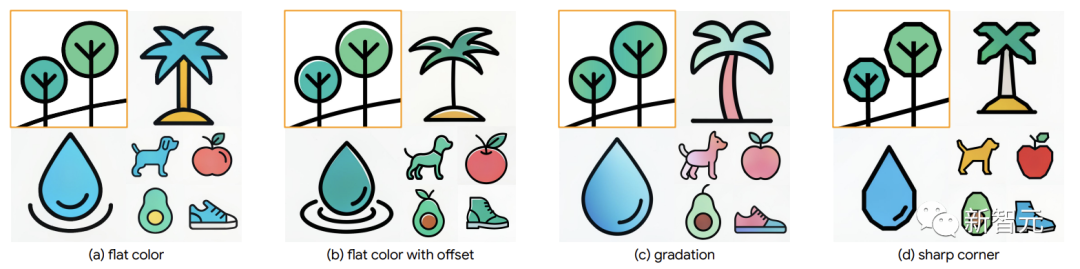
Comme le montre l'image, les résultats du traitement StyleDrop de 18 images de styles différents collectées par les chercheurs.
Comme vous pouvez le constater, StyleDrop est capable de capturer les nuances de texture, d'ombrage et de structure de différents styles, vous donnant un meilleur contrôle sur le style qu'auparavant.

À titre de comparaison, les chercheurs ont également présenté les résultats de DreamBooth sur Imagen, l'implémentation LoRA de DreamBooth sur Stable Diffusion et les résultats de l'inversion de texte.

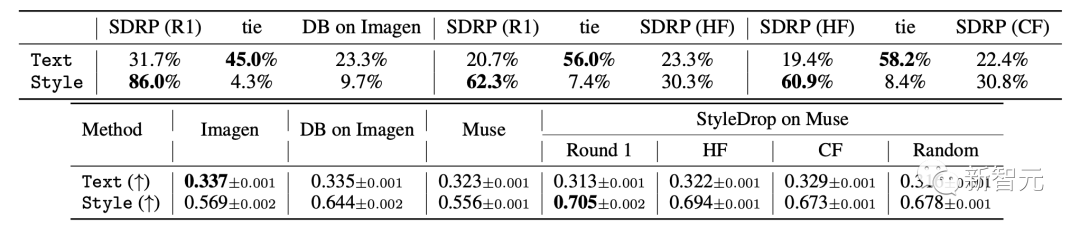
Les résultats spécifiques sont présentés dans le tableau, les indicateurs d'évaluation de la notation humaine (en haut) et de la notation CLIP (en bas) de l'alignement image-texte (Texte) et de l'alignement du style visuel (Style).
Comparaison qualitative de (a) DreamBooth, (b) StyleDrop et (c) DreamBooth + StyleDrop :
Ici, les chercheurs ont appliqué le CLIP mentionné ci-dessus Deux métriques pour la partition - partitions de texte et de style.
Pour le score de texte, les chercheurs mesurent la similarité cosinus entre les intégrations d'images et de texte. Pour le score de style, les chercheurs mesurent la similitude cosinus entre la référence de style et l’intégration de l’image synthétique.
Les chercheurs ont généré un total de 1 520 images pour 190 invites textuelles. Même si les chercheurs espéraient que le score final serait plus élevé, les mesures ne sont pas parfaites.
Et la formation itérative (IT) a amélioré le score du texte, ce qui correspond aux objectifs des chercheurs.
Cependant, en guise de compromis, leurs scores de style sur le modèle du premier tour sont réduits car ils sont formés sur des images synthétiques et le style peut être biaisé par un biais de sélection.
DreamBooth sur Imagen est inférieur à StyleDrop en termes de score de style (0,644 contre 0,694 pour HF).
Les chercheurs ont remarqué que l'augmentation du score de style de DreamBooth sur Imagen n'était pas évidente (0,569 → 0,644), tandis que l'augmentation de StyleDrop sur Muse était plus évidente (0,556 → 0,694).
Les chercheurs ont analysé que le réglage fin du style sur Muse est plus efficace que celui sur Imagen.
De plus, pour un contrôle plus fin, StyleDrop capture les différences de style subtiles, telles que le décalage des couleurs, la gradation ou le contrôle de l'angle précis.
Commentaires chauds des internautes
Si les designers ont StyleDrop, leur efficacité de travail sera 10 fois plus rapide, ce qui a déjà décollé.
Un jour sur l'IA, 10 ans sur terre, l'AIGC se développe à la vitesse de la lumière, le genre de vitesse de la lumière qui aveugle les yeux !
Les outils ne font que suivre la tendance, et ceux qui devraient être éliminés l'ont déjà été depuis longtemps.
Cet outil est beaucoup plus facile à utiliser que Midjourney pour créer des logos.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI