
Maison >base de données >tutoriel mysql >Quelles sont les techniques d'optimisation de la base de données MySQL ?
Quelles sont les techniques d'optimisation de la base de données MySQL ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-05 12:29:592458parcourir
1. Optimisez vos requêtes pour la mise en cache des requêtes
La plupart des serveurs MySQL ont la mise en cache des requêtes activée. C'est l'un des moyens les plus efficaces d'améliorer les performances, et il est géré par le moteur de base de données MySQL. Lorsque plusieurs des mêmes requêtes sont exécutées plusieurs fois, les résultats de la requête seront placés dans un cache, de sorte que les requêtes identiques suivantes n'auront pas besoin d'exploiter la table mais d'accéder directement aux résultats mis en cache.
Le principal problème ici est que pour les programmeurs, cette question est facilement négligée. Parce que certaines de nos instructions de requête empêcheront MySQL d'utiliser le cache . Veuillez consulter l'exemple suivant :

La différence entre les deux instructions SQL ci-dessus est
CURDATE(). Le cache de requêtes de MySQL ne fonctionne pas sur cette fonction. Par conséquent, les fonctions SQL commeNOW()etRAND()ou d'autres fonctions similaires ne permettront pas la mise en cache des requêtes, car les retours de ces fonctions seront volatiles. Il vous suffit donc de remplacer la fonction MySQL par une variable pour activer la mise en cache.CURDATE(),MySQL 的查询缓存对这个函数不起作用。所以,像NOW()和RAND()或是其它的诸如此类的 SQL 函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替 MySQL 的函数,从而开启缓存。
2. EXPLAIN 你的 SELECT 查询
使用
EXPLAIN关键字可以让你知道 MySQL 是如何处理你的 SQL 语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。EXPLAIN的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
挑一个你的SELECT语句(推荐挑选那个最复杂的,有多表联接的),把关键字EXPLAIN加到前面。你可以使用phpmyadmin来做这个事。然后,你会看到一张表格。下面的这个示例中,我们忘记加上了group_id索引,并且有表联接:
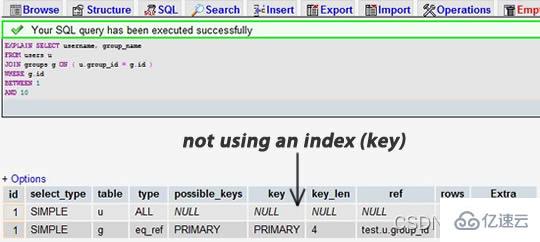
当我们为 group_id 字段加上索引后: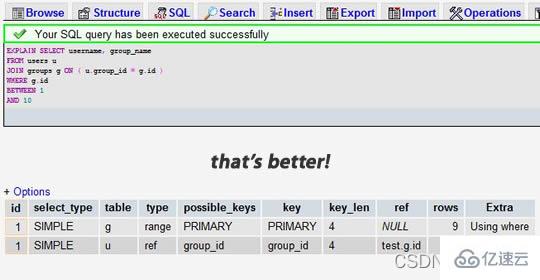
我们可以看到,前一个结果显示搜索了 7883 行,而后一个只是搜索了两个表的 9 和 16 行。查看 rows 列可以让我们找到潜在的性能问题。
3. 当只要一行数据时使用 LIMIT 1 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去
fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上LIMIT 1可以增加性能。这样一样,MySQL 数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
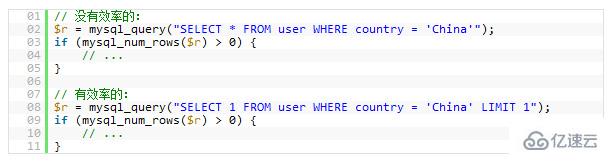
下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1)
4. 为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧
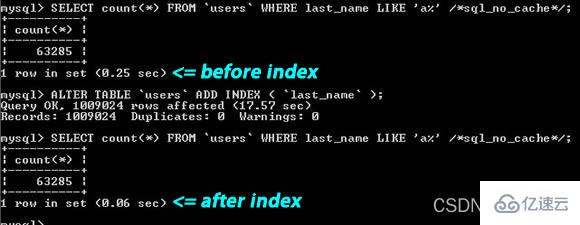
从上图你可以看到那个搜索字串 “
last_name LIKE ‘a%’”,一个是建了索引,一个是没有索引,性能差了 4 倍左右。
另外,你应该也需要知道什么样的搜索是不能使用正常的索引的。例如,当你需要在一篇大的文章中搜索一个词时,如: “WHERE post_content LIKE ‘%apple%’”,索引可能是没有意义的。你可能需要使用 MySQL 全文索引 或是自己做一个索引(比如说:搜索关键词或是 Tag 什么的)
5. 在 Join 表的时候使用相同类型的例
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中 Join 的字段是被建过索引的。这样,MySQL 内部会启动为你优化 Join 的 SQL 语句的机制。
🎜2. EXPLIQUEZ votre requête SELECT 🎜🎜🎜L'utilisation du mot-clé
而且,这些被用来 Join 的字段,应该是相同的类型的。例如:如果你要把DECIMAL字段和一个 INT 字段Join在一起,MySQL 就无法使用它们的索引。对于那些STRINGEXPLAINpeut 🎜vous permettre de savoir comment MySQL gère votre instruction SQL🎜. Cela peut vous aider à analyser les goulots d'étranglement des performances de vos instructions de requête ou de vos structures de table. 🎜EXPLIQUERLes résultats de la requête vous indiqueront également comment votre clé primaire d'index est utilisée, comment votre table de données est recherchée et triée... etc., etc. 🎜Choisissez l'une de vos instructionsSELECT(il est recommandé de choisir la plus complexe avec plusieurs connexions de tables) et ajoutez le mot-cléEXPLAINau début. Vous pouvez utiliserphpmyadminpour ce faire. Ensuite, vous verrez un formulaire. Dans l'exemple ci-dessous, nous avons oublié d'ajouter l'indexgroup_idet de joindre une table : 🎜🎜🎜🎜🎜Quand on ajoute un index au champ group_id :🎜
🎜Nous pouvons voir que le premier résultat montre que 7883 lignes ont été recherchées, tandis que le second n'en a recherché que 9 et 9 des deux tableaux 16 lignes. L'examen de la colonne des lignes nous permet de détecter des problèmes de performances potentiels. 🎜🎜3. Utilisez LIMIT 1 1 lorsqu'il n'y a qu'une seule ligne de données🎜🎜🎜Parfois, lorsque vous interrogez une table, vous savez déjà que le résultat ne sera qu'un seul résultat, mais parce que vous devrez peut-être accéder au
fetchCurseur, ou vous pouvez vérifier le nombre d'enregistrements renvoyés. 🎜Dans ce cas, l'ajout deLIMIT 1peut 🎜augmenter les performances🎜. De cette façon, le moteur de base de données MySQL arrêtera la recherche après avoir trouvé une donnée, au lieu de continuer à rechercher la donnée suivante correspondant à l'enregistrement. 🎜L'exemple suivant sert simplement à savoir s'il existe des utilisateurs "Chine". Évidemment, ce dernier sera plus efficace que le premier. (Veuillez noter que le premier estSelect *et le second estSelect 1)🎜🎜🎜🎜🎜4. Construire un index pour le champ de recherche🎜🎜L'index ne signifie pas nécessairement la clé primaire ou le seul champ. S'il y a un champ dans votre table que vous utilisez toujours pour la recherche, veuillez l'indexer🎜🎜
🎜🎜🎜Dans l'image ci-dessus, vous pouvez voir la chaîne de recherche "
last_name LIKE 'a%' ", l'une est indexée, et la les autres ne sont pas indexés, les performances sont environ 4 fois moins bonnes. 🎜De plus, vous devez également savoir quels types de recherches ne peuvent pas utiliser l'indexation normale. Par exemple, lorsque vous devez rechercher un mot dans un article volumineux, tel que : "WHERE post_content LIKE '%apple%'", l'index peut ne pas avoir de sens. Vous devrez peut-être utiliser l'index de texte intégral MySQL ou créer un index vous-même (par exemple : rechercher des mots-clés ou des balises)🎜🎜🎜5 Utilisez le même type d'exemple lorsque vous rejoignez la table🎜🎜🎜Si votre application a Pour plusieurs. JOIN, vous devez vous assurer que les champs Join des deux tables sont indexés. De cette façon, MySQL lancera un mécanisme en interne pour optimiser l'instruction Join SQL pour vous. 🎜De plus, ces champs utilisés pour Join doivent être du même type. Par exemple : si vousRejoignezun champDECIMALavec un champ INT, MySQL ne peut pas utiliser leurs index. Pour ces typesSTRING, ils doivent également avoir le même jeu de caractères. (Les jeux de caractères des deux tables peuvent être différents)🎜

6. Ne jamais ORDER BY RAND()
Vous souhaitez perturber les lignes de données renvoyées ? morceau de données au hasard ? Je ne sais pas qui a inventé cet usage, mais beaucoup de novices aiment l'utiliser de cette façon. Mais vous ne comprenez vraiment pas à quel point le problème de performances est grave.
Si vous souhaitez vraiment brouiller les lignes de données renvoyées, vous disposez de N façons d'y parvenir. Son utilisation ne fera qu'entraîner une baisse exponentielle des performances de votre base de données. Le problème ici est : MySQL devra exécuter la fonctionRAND()(qui consomme du temps CPU), et cela consiste à enregistrer les lignes pour chaque ligne d'enregistrements, puis à les trier . Même si vous utilisezLimite 1cela n'aidera pas (car vous devez trier)RAND()函数(很耗 CPU 时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
下面的示例是随机挑一条记录: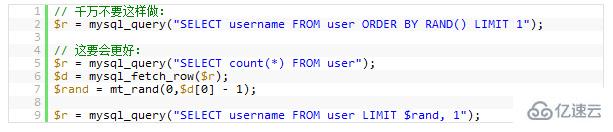
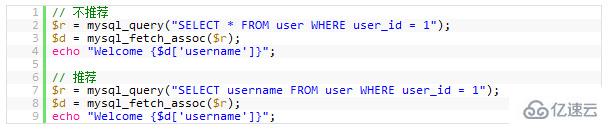
7.避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和 WEB 服务器是两台独立的服务器的话,这还会增加网络传输的负载。所以,你应该养成一个需要什么就取什么的好的习惯。
8. 永远为每张表设置一个 ID
我们应该为数据库里的每张表都设置一个 ID 做为其主键,而且最好的是一个
INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “VARCHAR类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的 ID 来构造你的数据结构。
而且,在 MySQL 数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区……
在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比如:有一个“学生表”有学生的 ID,有一个“课程表”有课程 ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生 ID 和课程 ID 叫“外键”其共同组成主键。
9. 使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是
TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用ENUM而不是VARCHAR。
MySQL 也有一个“建议”(见第十条)告诉你怎么去重新组织你的表结构。当你有一个VARCHAR字段时,这个建议会告诉你把其改成ENUM类型。使用PROCEDURE ANALYSE()你可以得到相关的建议
10. 从 PROCEDURE ANALYSE() 取得建议
PROCEDURE ANALYSE()会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。
例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成MEDIUMINT。或是你使用了一个VARCHAR字段,因为数据不多,你可能会得到一个让你把它
改成ENUM的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。
在phpmyadmin里,你可以在查看表时,点击“Propose table structure”
L'exemple suivant sélectionne un enregistrement au hasard : #🎜 🎜# 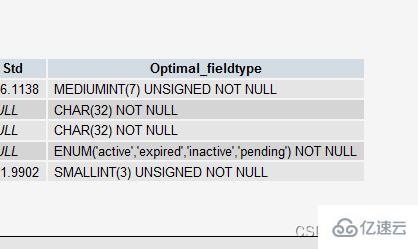 # 🎜🎜#7 .Évitez SELECT *
# 🎜🎜#7 .Évitez SELECT *
Plus de données sont lues dans la base de données, plus la requête deviendra lente. De plus, si votre serveur de base de données et votre serveur WEB sont deux serveurs indépendants, cela augmentera également la charge de transmission réseau. Par conséquent, vous devez développer une bonne habitude de prendre tout ce dont vous avez besoin
. #🎜🎜# #🎜🎜 ## 🎜🎜##🎜🎜#8. Définissez toujours un identifiant pour chaque table#🎜🎜##🎜🎜##🎜🎜#Nous devrions définir un identifiant pour chaque table de la base de données comme clé primaire, et c'est mieux Il est de type
#🎜🎜 ## 🎜🎜##🎜🎜#8. Définissez toujours un identifiant pour chaque table#🎜🎜##🎜🎜##🎜🎜#Nous devrions définir un identifiant pour chaque table de la base de données comme clé primaire, et c'est mieux Il est de type INT (il est recommandé d'utiliser UNSIGNED), et est défini avec l'indicateur AUTO_INCREMENT automatiquement ajouté. #🎜🎜#Même si votre table utilisateurs contient un champ avec une clé primaire appelée "email", n'en faites pas la clé primaire. L'utilisation du type VARCHAR comme clé primaire dégradera les performances. De plus, dans votre programme, vous devez utiliser des ID de table pour construire vos structures de données. #🎜🎜# De plus, sous le moteur de données MySQL, certaines opérations nécessitent l'utilisation de clés primaires. Dans ces cas, #🎜🎜#Les performances et les paramètres des clés primaires deviennent très importants, comme les clusters, les partitions.. .#🎜🎜# #🎜🎜#Ici, il n'y a qu'une seule exception, et c'est la "clé étrangère" de la "table associée". Autrement dit, la clé primaire de cette table est composée des clés primaires de plusieurs. tableaux individuels. Nous appelons cette situation « clé étrangère ». Par exemple : il existe une « table des étudiants » avec les identifiants des étudiants, et une « table des programmes » avec les identifiants des cours. Ensuite, la « table des notes » est une « table d'association », qui associe la table des étudiants et la table des cours. Dans la table, l'identifiant étudiant et l'identifiant du cours sont appelés « clés étrangères » et forment ensemble la clé primaire. #🎜🎜##🎜🎜##🎜🎜#9. Utilisez ENUM au lieu de VARCHAR#🎜🎜##🎜🎜##🎜🎜# Le type ENUM est très rapide et compact. En fait, il enregistre TINYINT, mais il apparaît sous forme de chaîne. De cette façon, il devient tout à fait parfait d'utiliser ce champ pour faire des listes de choix. #🎜🎜#Si vous avez un champ, tel que "sexe", "pays", "origine ethnique", "statut" ou "département", et que vous savez que les valeurs de ces champs sont limitées et fixes, alors vous devrait utiliser ENUM au lieu de VARCHAR. #🎜🎜#MySQL a également une "suggestion" (voir point 10) pour vous indiquer comment réorganiser la structure de vos tables. Lorsque vous disposez d'un champ VARCHAR, cette suggestion vous demandera de le changer en type ENUM. En utilisant PROCEDURE ANALYSE(), vous pouvez obtenir des suggestions associées#🎜🎜##🎜🎜##🎜🎜#10 Obtenez des suggestions de PROCEDURE ANALYSE()#🎜🎜##🎜🎜##🎜🎜 #. PROCEDURE ANALYSE() permettra à MySQL de vous aider à analyser vos champs et leurs données réelles, et de vous donner quelques suggestions utiles. Ces suggestions ne deviendront utiles que si le tableau contient des données réelles, car certaines décisions importantes nécessitent des données comme base. #🎜🎜#Par exemple, si vous créez un champ INT comme clé primaire, mais qu'il n'y a pas beaucoup de données, alors PROCEDURE ANALYSE() vous suggérera de changer le type de ce champ en MOYENINT. Ou si vous utilisez un champ VARCHAR, parce qu'il n'y a pas beaucoup de données, vous pouvez recevoir une suggestion pour #🎜🎜#le changer en ENUM. Ces suggestions sont toutes possibles car il n’y a pas suffisamment de données, donc la prise de décision n’est pas assez précise. #🎜🎜#Dans phpmyadmin, vous pouvez cliquer sur "Proposer la structure du tableau" lorsque vous consultez le tableau pour voir ces suggestions#🎜🎜##🎜🎜##🎜🎜 ## 🎜🎜##🎜🎜##🎜🎜#Assurez-vous de noter que ce ne sont que des suggestions. Ces suggestions ne deviendront exactes qu'à mesure que vous aurez de plus en plus de données dans votre tableau. N'oubliez pas que #🎜🎜#C'est vous qui prenez la décision finale#🎜🎜##🎜🎜#11. Utilisez NOT NULL autant que possible
Sauf si vous avez une raison très spécifique d'utiliser des valeurs
NULL, vous devez toujours conserver vos champsNOT NULL. Cela peut sembler un peu controversé, veuillez continuer à lire.NULL值,你应该总是让你的字段保持NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是 0 和 NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL和Empty的字符串是一样的!)
不要以为NULL不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用 NULL 值。
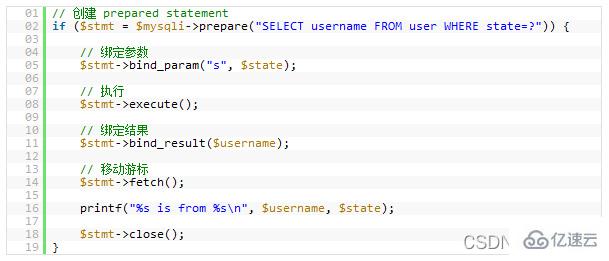
12.Prepared Statements
Prepared Statements很像存储过程,是一种运行在后台的 SQL 语句集合,我们可以从使用prepared statements获得很多好处,无论是性能问题还是安全问题。Prepared Statements可以检查一些你绑定好的变量,这样可以保护你的程序不会受到“SQL 注入式”攻击。当然,你也可以手动地检查你的这些变量,然而,手动的检查容易出问题,而且很经常会被程序员忘了。当我们使用一些framework或是ORM的时候,这样的问题会好一些。
性能方面,当一个相同的查询被使用多次的时候,这会为你带来可观的性能优势。你可以给这些Prepared Statements定义一些参数,而 MySQL 只会解析一次。
虽然最新版本的 MySQL 在传输Prepared Statements是使用二进制形式,所以这会使得网络传输非常有效率。
当然,也有一些情况下,我们需要避免使用Prepared Statements,因为其不支持查询缓存。但据说版本 5.1 后支持了。
在 PHP 中要使用 prepared statements,你可以查看其使用手册:mysql扩展 或是使用数据库抽象层,如: PDO.
13. 无缓冲的查询
正常的情况下,当你在当你在你的脚本中执行一个 SQL 语句的时候,你的程序会停在那里直到没这个 SQL 语句返回,然后你的程序再往下继续执行。你可以使用无缓冲查询来改变这个行为。
mysql_unbuffered_query()发送一个 SQL 语句到 MySQL 而并不像mysql_query()一样去自动fethch和缓存结果。这会相当节约很多可观的内存,尤其是那些会产生大量结果的查询语句,并且,你不需要等到所有的结果都返回,只需要第一行数据返回的时候,你就可以开始马上开始工作于查询结果了。
然而,这会有一些限制。因为你要么把所有行都读走,或是你要在进行下一次的查询前调用mysql_free_result()清除结果。而且,mysql_num_rows()或 mysql_data_seek()将无法使用。所以,是否使用无缓冲的查询你需要仔细考虑。
14. 把 IP 地址存成 UNSIGNED INT
12.Instructions préparées🎜🎜🎜很多程序员都会创建一个
VARCHAR(15)字段来存放字符串形式的 IP 而不是整形的 IP。如果你用整形来存放,只需要 4 个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当你需要使用这样的WHERE条件:IP between ip1 and ip2。
我们必需要使用UNSIGNED INT,因为 IP 地址会使用整个 32 位的无符号整型。
而你的查询,你可以使用INET_ATON()来把一个字符串 IP 转成一个整型,并使用INET_NTOA()把一个整形转成一个字符串 IP。在 PHP 中,也有这样的函数ip2long() 和 long2ip()Tout d'abord, demandez-vous quelle est la différence entre "Empty" et "NULL" (si c'estINT, c'est 0 et NULL ) ? Si vous pensez qu'il n'y a aucune différence entre eux, vous ne devez pas utiliserNULL. (Le saviez-vous ? Dans Oracle, les chaînesNULLetEmptysont les mêmes !)
Ne pensez pas que NULL ne nécessite aucun espace, il nécessite de l'espace supplémentaire et, lorsque vous effectuez des comparaisons, votre programme sera plus complexe. Bien sûr, cela ne signifie pas que vous ne pouvez pas utiliserNULL. La réalité est très compliquée, et il y aura toujours des situations où vous devrez utiliser des valeurs NULL.

Instructions préparées ressemble beaucoup à une procédure stockée. Il s'agit d'une collection d'instructions SQL exécutées en arrière-plan. Nous pouvons utiliser des instructions préparées<.> Bénéficiez de nombreux avantages, qu'il s'agisse d'un <strong>problème de performances ou d'un problème de sécurité</strong>. 🎜<code>Instructions préparées peut vérifier certaines variables que vous avez liées, ce qui peut protéger votre programme contre les attaques par "injection SQL". Bien entendu, vous pouvez également vérifier manuellement vos variables. Cependant, les vérifications manuelles sont sujettes à des problèmes et sont souvent oubliées par les programmeurs. Lorsque nous utilisons un framework ou un ORM, ce problème sera meilleur. 🎜En termes de performances, lorsque la même requête est utilisée plusieurs fois, cela vous apportera des avantages considérables en termes de performances. Vous pouvez définir certains paramètres pour ces Instructions préparées et MySQL ne les analysera qu'une seule fois. 🎜Bien que la dernière version de MySQL utilise la forme binaire lors de la transmission des instructions préparées, cela rendra la transmission réseau très efficace. 🎜Bien sûr, il y a certains cas où nous devons éviter d'utiliser les Instructions préparées car elles ne prennent pas en charge la mise en cache des requêtes. Mais il serait pris en charge après la version 5.1. 🎜Pour utiliser des instructions préparées en PHP, vous pouvez consulter son manuel : extension mysql ou utiliser une couche d'abstraction de base de données, telle que : PDO.🎜 🎜🎜13. Requête sans tampon🎜🎜🎜Dans des circonstances normales, quand vous l'êtes Quand vous l'êtes exécutez une instruction SQL dans votre script, votre programme s'arrêtera là jusqu'à ce qu'aucune instruction SQL ne soit renvoyée, puis votre programme continuera à s'exécuter. Vous pouvez utiliser des requêtes sans tampon pour modifier ce comportement. 🎜
🎜🎜13. Requête sans tampon🎜🎜🎜Dans des circonstances normales, quand vous l'êtes Quand vous l'êtes exécutez une instruction SQL dans votre script, votre programme s'arrêtera là jusqu'à ce qu'aucune instruction SQL ne soit renvoyée, puis votre programme continuera à s'exécuter. Vous pouvez utiliser des requêtes sans tampon pour modifier ce comportement. 🎜mysql_unbuffered_query() envoie une instruction SQL à MySQL au lieu de automatiquement fethch et de mettre en cache les résultats comme mysql_query(). Cela permettra d'économiser beaucoup de mémoire, en particulier pour les requêtes qui génèrent un grand nombre de résultats, et vous n'aurez pas besoin d'attendre que tous les résultats soient renvoyés. Il vous suffit de renvoyer la première ligne de données et vous pouvez commencer. fonctionne immédiatement. Les résultats de la requête sont disponibles. 🎜Cependant, il existe certaines limites à cela. Parce que soit vous devez lire toutes les lignes, soit vous devez appeler mysql_free_result() pour effacer les résultats avant la requête suivante. De plus, mysql_num_rows() ou mysql_data_seek() ne fonctionnera pas. Par conséquent, vous devez réfléchir attentivement à l’opportunité d’utiliser des requêtes sans tampon. 🎜🎜14. Enregistrez l'adresse IP sous UNSIGNED INT🎜🎜🎜De nombreux programmeurs créeront un champ VARCHAR(15) pour stocker l'adresse IP sous forme de chaîne au lieu de l'adresse IP entière. Si vous utilisez un entier pour le stocker, cela ne prend que 4 octets et vous pouvez avoir des champs de longueur fixe. De plus, cela vous apportera des avantages en matière de requête, en particulier lorsque vous devez utiliser de telles conditions WHERE : IP entre ip1 et ip2. 🎜Nous devons utiliser UNSIGNED INT, car l'adresse IP utilise l'intégralité du type entier non signé de 32 bits. 🎜Pour votre requête, vous pouvez utiliser INET_ATON() pour convertir une chaîne IP en un entier, et utiliser INET_NTOA() pour convertir un entier Convertir en un chaîne IP. En PHP, il existe également de telles fonctions ip2long() et long2ip(). 🎜🎜🎜
15. Les tableaux de longueur fixe seront plus rapides
Si tous les champs du tableau sont de "longueur fixe", le tableau entier sera considéré comme "
statique" ou "fixe" de longueur.". Par exemple, il n'y a aucun champ des types suivants dans la table :VARCHAR, TEXT. Tant que vous incluez l'un de ces champs, la table n'est plus une "table statique de longueur fixe" et le moteur MySQL la traitera d'une autre manière.
Les tables de longueur fixe amélioreront les performances car MySQL recherchera plus rapidement. Puisque ces longueurs fixes facilitent le calcul du décalage des données suivantes, la lecture sera naturellement plus rapide. Et si le champ n'est pas de longueur fixe, chaque fois que vous souhaitez trouver le suivant, le programme doit trouver la clé primaire.
De plus, les tables de longueur fixe sont plus faciles à mettre en cache et à reconstruire. Cependant, le seul effet secondaire est que les champs de longueur fixe gaspillent de l'espace, car les champs de longueur fixe nécessitent beaucoup d'espace pour être alloués, que vous les utilisiez ou non.static”或 “fixed-length”。 例如,表中没有如下类型的字段:VARCHAR,TEXT。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为 MySQL 搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
使用“垂直分割”技术(见下一条),你可以分割你的表成为两个一个是定长的,一个则是不定长的。
16. 垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。(以前,在银行做过项目,见过一张表有 100 多个字段,很恐怖)
示例一:在 Users 表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改写这个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有好的性
能。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户 ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去 Join 他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降
17.拆分大的 DELETE 或 INSERT 语句
如果你需要在一个在线的网站上去执行一个大的
DELETE或INSERT查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如 30 秒钟,那么对于一个有很高访问量的站点来说,这 30 秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊 WEB 服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用LIMIT条件是一个好的方法。下面是一个示例:
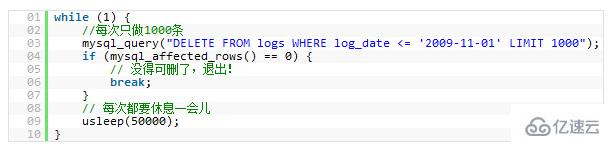
18.越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
参看 MySQL 的文档Storage Requirements查看所有的数据类型。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用INT来做主键,使用MEDIUMINT, SMALLINT或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用DATE要比DATETIME好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009 年 11 月 06 日),一个简单的ALTER TABLEGrâce à la technologie "Vertical Split" (voir article suivant), vous pouvez diviser votre table en deux, une de longueur fixe et une de longueur variable. 🎜🎜16. Division verticale🎜🎜🎜 La « division verticale » est une méthode permettant de transformer les tables de la base de données en plusieurs tables par colonnes, ce qui peut réduire la complexité de la table et le nombre de champs, atteignant ainsi des objectifs d'optimisation. (J'avais l'habitude de faire des projets dans une banque et j'ai vu une table avec plus de 100 champs, ce qui faisait peur) 🎜🎜🎜🎜Exemple 1 : Il y a un champ dans la table Utilisateurs qui est l'adresse du domicile. Ce champ est facultatif par rapport à. , et lorsque vous exploitez la base de données, à l'exception des informations personnelles, vous n'avez pas besoin de lire ou de réécrire ce champ fréquemment. Alors, pourquoi ne pas le mettre dans une autre table ? Cela permettra à votre table d'avoir de meilleures performances. Pensez-y, souvent, pour la table utilisateur, je n'ai que l'ID utilisateur, le nom d'utilisateur et le mot de passe, les rôles d'utilisateur. etc. seront utilisés fréquemment. Les tables plus petites auront toujours de meilleures performances
🎜🎜🎜🎜Exemple 2 : Vous disposez d'un champ appelé "last_login" qui sera mis à jour à chaque fois que l'utilisateur se connectera. Cependant, chaque mise à jour entraînera l'effacement du cache de requêtes de la table. Par conséquent, vous pouvez placer ce champ dans une autre table, afin qu'il n'affecte pas votre lecture continue de l'ID utilisateur, du nom d'utilisateur et du rôle de l'utilisateur, car le cache de requêtes vous aidera à augmenter considérablement les performances. 🎜🎜De plus, vous devez faire attention au fait que vous ne rejoindrez pas fréquemment les tables formées par ces champs séparés, sinon les performances seront pires que lorsqu'elles ne sont pas divisées, et ce sera une baisse extrême. 🎜🎜17. Divisez la grande instruction DELETE ou INSERT🎜🎜🎜Si vous devez exécuter une grande requête
DELETEouINSERT, vous devez être très prudent. pour éviter que vos opérations n’entraînent l’arrêt de la réponse de l’ensemble de votre site Web. Étant donné que ces deux opérations verrouillent la table, une fois la table verrouillée, aucune autre opération ne peut y entrer. <br>Apache aura de nombreux processus ou threads enfants. Par conséquent, cela fonctionne assez efficacement et notre serveur ne veut pas avoir trop de processus enfants, de threads et de liens de base de données. Cela consomme beaucoup de ressources du serveur, en particulier de mémoire. <br>Si vous verrouillez votre table pendant un certain temps, par exemple 30 secondes, alors pour un site avec un nombre élevé de visites, les processus/threads d'accès accumulés, les liens de base de données et les fichiers ouverts accumulés au cours de ces 30 secondes A plusieurs fois, cela peut non seulement provoquer un <code>Crashde votre service WEB, mais également provoquer le blocage immédiat de l'ensemble de votre serveur.
Donc, si vous avez un processus volumineux et que vous êtes sûr de le diviser, utiliser la conditionLIMITest un bon moyen de le faire. Voici un exemple : 🎜🎜
Consultez la documentation MySQLExigences de stockagepour afficher tous les types de données.
Si une table ne comporte que quelques colonnes (comme une table de dictionnaire, une table de configuration), alors nous n'avons aucune raison d'utiliserINTcomme clé primaire et d'utiliserMEDIUMINT, SMALLINT ou un TINYINT plus petit serait plus économique. Si vous n'avez pas besoin d'enregistrer l'heure, il est préférable d'utiliser <code>DATEqueDATETIME.
Bien sûr, vous devez également laisser suffisamment d'espace d'extension, sinon, si vous faites cela à l'avenir, vous mourrez moche. Voir l'exemple deSlashdot(6 novembre 2009 ), une simple instructionALTER TABLEa pris plus de 3 heures car elle contenait 16 millions de données. 🎜
19. Choisissez le bon moteur de stockage
Il existe deux moteurs de stockage dans MySQL, MyISAM et InnoDB. Chaque moteur a des avantages et des inconvénients. L'article précédent de Cool Shell « MySQL : InnoDB ou MyISAM ? » traitait de ce sujet.
MyISAM convient à certaines applications qui nécessitent un grand nombre de requêtes, mais il n'est pas très bon pour un grand nombre d'opérations d'écriture. Même si vous avez juste besoin de mettre à jour un champ, la table entière sera verrouillée et les autres processus, même le processus de lecture, ne pourront pas fonctionner tant que l'opération de lecture n'est pas terminée. De plus, MyISAM est extrêmement rapide pour les calculs tels queSELECT COUNT(*).SELECT COUNT(*)这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比MyISAM还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
20. 使用一个对象关系映射器 (Object Relational Mapper)
使用 ORM (
Object Relational Mapper),你能够获得可靠的性能增涨。一个ORM 可以做的所有事情,也能被手动的编写出来。但是,这需要一个高级专家。
ORM 的最重要的是“Lazy Loading”,也就是说,只有在需要的去取值的时候才会去真正的去做。但你也需要小心这种机制的副作用,因为这很有可能会因为要去创建很多很多小的查询反而会降低性能。
ORM 还可以把你的 SQL 语句打包成一个事务,这会比单独执行他们快得多得多。
目前,个人最喜欢的 PHP 的 ORM 是:Doctrine
21. 小心 “ 永久链接 ”
“永久链接”的目的是用来减少重新创建 MySQL 链接的次数。当一个链接被创建了,它会永远处在连接的状态,就算是数据库操作已经结束了。而且,自从我们的 Apache 开始重用它的子进程后——也就是说,下一次的 HTTP 请求会重用 Apache 的子进程,并重用相同的 MySQL 链接。
在理论上来说,这听起来非常的不错。但是从个人经验(也是大多数人的)上来说,这个功能制造出来的麻烦事更多。因为,你只有有限的链接数,内存问题,文件句柄数,等等。
而且,Apache 运行在极端并行的环境中,会创建很多很多的了进程。这就是为什么这种“永久链接”的机制工作地不好的原因。在你决定要使用“永久链接”之前,你需要好好地考虑一下你的整个系统的架构
22.sql优化之索引优化
1.独立的列
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
例如下面的查询不能使用 actor_id 列的索引:
#这是错误的SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
优化方式:可以将表达式、函数操作移动到等号右侧。如下:
SELECT actor_id FROM sakila.actor WHERE actor_id = 5 - 1;
2.多列索引
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。
例如下面的语句中,最好把actor_id 和 film_id 设置为多列索引。猿辅导有道题,详见链接,可以让理解更深刻。
SELECT film_id, actor_ id FROM sakila.film_actorWHERE actor_id = 1 AND film_id = 1;
3.索引列的顺序
让选择性最强的索引列放在前面。
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity, COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity, COUNT(*) FROM payment; #结果如下 staff_id_selectivity: 0.0001 customer_id_selectivity: 0.0373 COUNT(*): 16049
4.前缀索引
对于 BLOB、TEXT 和 VARCHARLa tendance d'InnoDB sera un moteur de stockage très complexe pour certaines petites applications, il sera plus lent que MyISAM. L'autre raison est qu'il prend en charge le "verrouillage des lignes", ce sera donc mieux lorsqu'il y aura plus d'opérations d'écriture. De plus, il prend également en charge des applications plus avancées, telles que les transactions.
En utilisant un ORM (Mappeur relationnel d'objet), vous pouvez obtenir des augmentations de performances fiables. Tout ce qu'un ORM peut faire peut également être écrit manuellement. Toutefois, cela nécessite un expert de haut niveau.
Lazy Loading", c'est-à-dire qu'il ne sera réellement effectué que lorsqu'il sera nécessaire d'obtenir la valeur. Mais vous devez également faire attention aux effets secondaires de ce mécanisme, car il est susceptible de réduire les performances en créant de très nombreuses petites requêtes. ORM peut également regrouper vos instructions SQL dans une transaction, ce qui est beaucoup plus rapide que de les exécuter individuellement.Le but des « liens permanents » est de réduire le nombre de fois que vous recréez. Liens MySQL. Lorsqu'un lien est créé, il reste connecté pour toujours, même après la fin de l'opération de base de données. De plus, depuis que notre Apache a commencé à réutiliser son processus enfant, c'est-à-dire que la prochaine requête HTTP réutilisera le processus enfant Apache et réutilisera la même connexion MySQL.Actuellement, mon ORM préféré pour PHP est :
21 Soyez prudent avec les « liens permanents »Doctrine
En théorie, cela semble très bien. Mais d'après mon expérience personnelle (et celle de la plupart des gens), cette fonctionnalité crée plus de problèmes. Parce que vous ne disposez que d’un nombre limité de liens, de problèmes de mémoire, de descripteurs de fichiers, etc.1 Colonnes indépendantesLors de l'exécution de requêtes, les colonnes d'index ne peuvent pas faire partie d'un. expression et ne peut pas être un paramètre d’une fonction, sinon l’index ne peut pas être utilisé.De plus, Apache fonctionne dans un environnement extrêmement parallèle et créera de très nombreux processus. C'est pourquoi ce mécanisme de « lien permanent » ne fonctionne pas bien. Avant de décider d'utiliser des "liens permanents", vous devez examiner attentivement l'architecture de l'ensemble de votre système
22. Optimisation SQL Optimisation de l'index
Par exemple, la requête suivante ne peut pas utiliser l'index de la colonne Actor_id :
#进行全表查询,没有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_%'; EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_'; #有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE 'ptd_%';🎜Méthode d'optimisation : les expressions et les opérations de fonction peuvent être déplacées vers la droite du signe égal. Comme suit : 🎜
SELECT * FROM `user` WHERE username LIKE '张%';🎜 2. Index multi-colonnes 🎜🎜 Lorsque plusieurs colonnes doivent être utilisées comme conditions pour les requêtes, l'utilisation d'index multi-colonnes offre de meilleures performances que l'utilisation de plusieurs index à colonne unique. 🎜Par exemple, dans l'instruction suivante, il est préférable de définir
actor_id et film_id comme index multi-colonnes. Yuanfudao a une question, consultez le lien pour plus de détails, ce qui peut vous aider à comprendre plus en profondeur. 🎜SELECT * FROM t WHERE id IN (2,3)SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)🎜3. L'ordre des colonnes d'index🎜🎜Que la colonne d'index la plus sélective soit placée en premier. 🎜La sélectivité de l'index fait référence au rapport entre les valeurs d'index uniques et le nombre total d'enregistrements. La valeur maximale est 1, auquel moment chaque enregistrement possède un index unique qui lui correspond. Plus la sélectivité est élevée, plus la discrimination de chaque enregistrement est élevée et plus l'efficacité des requêtes est élevée. 🎜🎜Par exemple, dans les résultats ci-dessous,
customer_id est plus sélectif que staff_id, il est donc préférable de placer la colonne customer_id devant l'index multi-colonnes. 🎜SELECT * FROM t WHERE id BETWEEN 2 AND 3🎜4. Index de préfixe🎜🎜Pour les colonnes de type
BLOB, TEXT et VARCHAR, vous devez utiliser un index de préfixe pour indexer uniquement les caractères de début. 🎜🎜La sélection de la longueur du préfixe doit être déterminée en fonction de la sélectivité de l'index. 🎜🎜5. Index de couverture 🎜🎜L'index contient les valeurs de tous les champs qui doivent être interrogés. Il présente les avantages suivants : 🎜🎜🎜1. L'index est généralement beaucoup plus petit que la taille de la ligne de données, et la lecture uniquement de l'index peut réduire considérablement la quantité d'accès aux données. 🎜2. Certains moteurs de stockage (tels que MyISAM) mettent uniquement en cache les index en mémoire, et les données dépendent du système d'exploitation pour la mise en cache. Par conséquent, accéder uniquement à l’index élimine le besoin d’appels système (qui prennent souvent du temps). 🎜3. Pour le moteur InnoDB, si l'index secondaire peut couvrir la requête, il n'est pas nécessaire d'accéder à l'index primaire. 🎜🎜🎜6. Donnez la priorité à l'utilisation des index pour éviter les analyses de table complètes🎜🎜🎜🎜mysql met % derrière lors de l'utilisation de likes pour les requêtes floues afin d'éviter les requêtes floues au début🎜Parce que mysql n'utilise que le % suivant lors de l'utilisation de requêtes similaires, le l'index sera utilisé. 🎜🎜🎜🎜Par exemple : '%ptd_' et '%ptd_%' n'utilisent pas d'index ; mais 'ptd_%' utilise des index. 🎜SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t1.username = t2.username)🎜Autre exemple : une requête couramment utilisée pour toutes les personnes portant le nom de famille Zhang dans la base de données :🎜
SELECT * FROM `user` WHERE username LIKE '张%';
7.尽量避免使用in 和not in,会导致数据库引擎放弃索引进行全表扫描。
比如:
SELECT * FROM t WHERE id IN (2,3)SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3
如果是子查询,可以用exists代替。如下:
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t1.username = t2.username)
8.尽量避免使用or,会导致数据库引擎放弃索引进行全表扫描
如:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1UNIONSELECT * FROM t WHERE id = 3
9.尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
10.尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描
同第1个,单独的列;
SELECT * FROM t2 WHERE score/10 = 9SELECT * FROM t2 WHERE SUBSTR(username,1,2) = 'li'
优化方式:可以将表达式、函数操作移动到等号右侧。如下:
SELECT * FROM t2 WHERE score = 10*9SELECT * FROM t2 WHERE username LIKE 'li%'
11.当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描
SELECT * FROM t WHERE 1=1
优化方式:用代码拼装sql时进行判断,没where加where,有where加and。
索引的好处:建立索引后,查询时不会扫描全表,而会查询索引表锁定结果。索引的缺点:在数据库进行DML操作的时候,除了维护数据表之外,还需要维护索引表,运维成本增加。应用场景:数据量比较大,查询字段较多的情况。
索引规则:
1.选用选择性高的字段作为索引,一般unique的选择性最高;
2.复合索引:选择性越高的排在越前面。(左前缀原则);
3.如果查询条件中两个条件都是选择性高的,最好都建索引;
23.SQL优化之查询优化
1.使用Explain进行分析
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
select_type: 查询类型,有简单查询、联合查询、子查询等;key: 使用的索引;rows: 扫描的行数;
2.优化数据访问
1.减少请求的数据量
只返回必要的列:最好不要使用
SELECT *语句。
只返回必要的行:使用LIMIT语句来限制返回的数据。
缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
2.减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
3.重构查询方式
1.切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
2.分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
让缓存更高效:对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
减少锁竞争;
在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
SELECT * FROM tab JOIN tag_post ON tag_post.tag_id=tag.id JOIN post ON tag_post.post_id=post.id WHERE tag.tag='mysql'; SELECT * FROM tag WHERE tag='mysql'; SELECT * FROM tag_post WHERE tag_id=1234; SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
24.分析查询语句
通过对查询语句的分析,可以了解查询语句执行的情况,找出查询语句执行的瓶颈,从而优化查询语句。mysql中提供了EXPLAIN语句和
DESCRIBE语句,用来分析查询语句。EXPLAIN语句的基本语法如下:
EXPLAIN [EXTENDED] SELECT select_options;
使用EXTENED关键字,EXPLAIN语句将产生附加信息。select_options是select语句的查询选项,包括from where子句等等。
执行该语句,可以分析EXPLAIN后面的select语句的执行情况,并且能够分析出所查询的表的一些特征。
例如:EXPLAIN SELECT * FROM user;
查询结果进行解释说明:
a、id:select识别符,这是select的查询序列号。
b、select_type:标识select语句的类型。
它可以是以下几种取值:
b1、SIMPLE(simple)表示简单查询,其中不包括连接查询和子查询。
b2、PRIMARY(primary)表示主查询,或者是最外层的查询语句。
b3、UNION(union)表示连接查询的第2个或者后面的查询语句。
b4、DEPENDENT UNION(dependent union)连接查询中的第2个或者后面的select语句。取决于外面的查询。
b5、UNION RESULT(union result)连接查询的结果。
b6、SUBQUERY(subquery)子查询的第1个select语句。
b7、DEPENDENT SUBQUERY(dependent subquery)子查询的第1个select,取决于外面的查询。
b8、DERIVED(derived)导出表的SELECT(FROM子句的子查询)。
c、table:表示查询的表。
d、type:表示表的连接类型。
下面按照从最佳类型到最差类型的顺序给出各种连接类型。
d1、system,该表是仅有一行的系统表。这是const连接类型的一个特例。
d2、const,数据表最多只有一个匹配行,它将在查询开始时被读取,并在余下的查询优化中作为常量对待。const表查询速度很快,因为它们只读一次。const用于使用常数值比较primary key或者unique索引的所有部分的场合。
例如:EXPLAIN SELECT * FROM user WHERE id=1;
d3、eq_ref,对于每个来自前面的表的行组合,从该表中读取一行。当一个索引的所有部分都在查询中使用并且索引是UNIQUE或者PRIMARY KEY时候,即可使用这种类型。eq_ref可以用于使用“=”操作符比较带索引的列。比较值可以为常量或者一个在该表前面所读取的表的列的表达式。
例如:EXPLAIN SELECT * FROM user,db_company WHERE user.company_id = db_company.id;
d4、ref对于来自前面的表的任意行组合,将从该表中读取所有匹配的行。这种类型用于所以既不是UNION也不是primaey key的情况,或者查询中使用了索引列的左子集,即索引中左边的部分组合。ref可以用于使用=或者操作符的带索引的列。
d5、ref_or_null,该连接类型如果ref,但是如果添加了mysql可以专门搜索包含null值的行,在解决子查询中经常使用该连接类型的优化。
d6、index_merge,该连接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
d7、unique_subquery,该类型替换了下面形式的in子查询的ref。是一个索引查询函数,可以完全替代子查询,效率更高。
d8、index_subquery,该连接类型类似于unique_subquery,可以替换in子查询,但是只适合下列形式的子查询中非唯一索引。
d9、range,只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。key_len包含所使用索引的最长关键元素。当使用=,,>,>=,,between或者in操作符,用常量比较关键字列时,类型为range。
d10、index,该连接类型与all相同,除了只扫描索引树。着通常比all快,引文索引问价通常比数据文件小。
d11、all,对于前面的表的任意行组合,进行完整的表扫描。如果表是第一个没有标记const的表,这样不好,并且在其他情况下很差。通常可以增加更多的索引来避免使用all连接。
e、possible_keys:possible_keys列指出mysql能使用那个索引在该表中找到行。如果该列是null,则没有相关的索引。在这种情况下,可以通过检查where子句看它是否引起某些列或者适合索引的列来提高查询性能。如果是这样,可以创建适合的索引来提高查询的性能。
f.key:表示查询实际使用到的索引,如果没有选择索引,该列的值是null,要想强制mysql使用或者忽视possible_key列中的索引,在查询中使用force index、use index或者ignore index。
g、key_len:表示mysql选择索引字段按照字节计算的长度,如果健是null,则长度为null。注意通过key_len值可以确定mysql将实际使用一个多列索引中的几个字段。
h、ref:表示使用那个列或者常数或者索引一起来查询记录。
i、rows:显示mysql在表中进行查询必须检查的行数。
j、Extra: Les informations détaillées de cette colonne lorsque MySQL traite la requête.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!