
Maison >Périphériques technologiques >IA >Aperçu des principes de la technologie Transformer
Aperçu des principes de la technologie Transformer

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-04 17:03:201943parcourir

1. Avant-propos
Récemment, l'AIGC (AI-Generated Content) s'est développé rapidement et est non seulement recherché par les consommateurs, mais attire également l'attention des cercles technologiques et industriels. Le 23 septembre 2022, Sequoia America a publié un article « Generative AI : A Creative New World », estimant que l'AIGC représentera le début d'un nouveau cycle de changement de paradigme. En octobre 2022, Stability AI a publié le modèle open source Stable Diffusion, qui peut générer automatiquement des images basées sur des descriptions textuelles (appelées invites) saisies par les utilisateurs, à savoir Text-to-Image, DALL-E 2 , Midjourney, Wenxin Yige. et d'autres modèles AIGC capables de générer des images ont fait exploser le domaine de la peinture IA qui est devenue populaire, marquant la pénétration de l'intelligence artificielle dans le domaine de l'art. L'image ci-dessous montre une œuvre sur le thème "Future Mecha" créée par la plateforme "Wenxin Yige" de Baidu.

Figure 1 Peinture IA créée par la plateforme « Wenxin Yige » de Baidu
Le développement rapide du domaine AIGC est indissociable des progrès des réseaux de neurones profonds. Plus précisément, l'émergence du modèle Transform donne au réseau neuronal des capacités informatiques globales plus puissantes, réduit le temps consacré à la formation du réseau et améliore les performances du modèle de réseau. Les modèles de domaine AIGC actuels qui fonctionnent relativement bien incluent les technologies Attention et Transform dans leur architecture technique sous-jacente.
2. Historique du développement
2.1 Réseau neuronal profond
Le développement des technologies de l'information représentées par un réseau neuronal profond a favorisé le progrès et l'expansion du domaine de l'intelligence artificielle. En 2006, Hinton et al. ont utilisé le pré-entraînement à l'auto-encodage RBM monocouche pour réaliser une formation approfondie sur les réseaux neuronaux ; en 2012, le modèle de réseau neuronal AlexNet conçu par Hinton et Alex Krizhevsky a obtenu la reconnaissance et la classification d'images dans le cadre du concours ImageNet, devenant ainsi un nouveau modèle de réseau neuronal. tour de Le point de départ du développement de l'intelligence artificielle. Le réseau de neurones profonds actuellement populaire est calqué sur les concepts proposés par les réseaux de neurones biologiques. Dans les réseaux de neurones biologiques, les neurones biologiques transmettent les informations reçues couche par couche, et les informations provenant de plusieurs neurones sont agrégées pour obtenir le résultat final. Les modèles mathématiques construits à l'aide d'unités neuronales logiques conçues de manière analogue aux unités neuronales biologiques sont appelés réseaux de neurones artificiels. Dans les réseaux de neurones artificiels, les unités neuronales logiques sont utilisées pour explorer la relation cachée entre les données d'entrée et les données de sortie. Lorsque la quantité de données est faible, les réseaux de neurones superficiels peuvent toutefois répondre aux exigences de certaines tâches, à mesure que l'échelle des données continue de le faire. augmenter, les réseaux neuronaux profonds et en expansion commencent à montrer leurs avantages uniques.
2.2 Mécanisme d'attention
Le mécanisme d'attention a été proposé par l'équipe Bengio en 2014 et a été largement utilisé dans divers domaines de l'apprentissage profond ces dernières années, comme dans la vision par ordinateur pour capturer des images. pour localiser les jetons ou les fonctionnalités clés du PNL. Un grand nombre d'expériences ont prouvé que les modèles dotés de mécanismes d'attention ont permis d'améliorer considérablement la classification, la segmentation, le suivi, l'amélioration et la reconnaissance, la compréhension, la réponse aux questions et la traduction du langage naturel.
Le mécanisme d’attention est calqué sur le mécanisme d’attention visuelle. Le mécanisme d’attention visuelle est une capacité innée du cerveau humain. Lorsque nous voyons une image, nous la numérisons d’abord rapidement, puis nous nous concentrons sur la zone cible sur laquelle nous devons nous concentrer. Par exemple, lorsque nous regardons les images suivantes, notre attention se concentre facilement sur le visage du bébé, le titre de l'article et la première phrase de l'article. Imaginez, si chaque information locale n'est pas abandonnée, elle consommera certainement beaucoup d'énergie, ce qui n'est pas propice à la survie et à l'évolution des êtres humains. De même, l’introduction de mécanismes similaires dans les réseaux d’apprentissage profond peut simplifier les modèles et accélérer les calculs. Essentiellement compris, l'attention consiste à filtrer une petite quantité d'informations importantes à partir d'une grande quantité d'informations et à se concentrer sur ces informations importantes, tout en ignorant la plupart des informations sans importance.

Figure 2 Schéma schématique du mécanisme de l'attention humaine
3. Le modèle intelligent Transformer abandonne les unités traditionnelles CNN et RNN, et l'ensemble de la structure du réseau est entièrement composée de mécanismes d'attention. Dans ce chapitre, nous présenterons d'abord le processus global du modèle Transformer, puis présenterons en détail les informations de codage de position et le calcul de l'auto-attention impliqués. 3.1 Aperçu du processus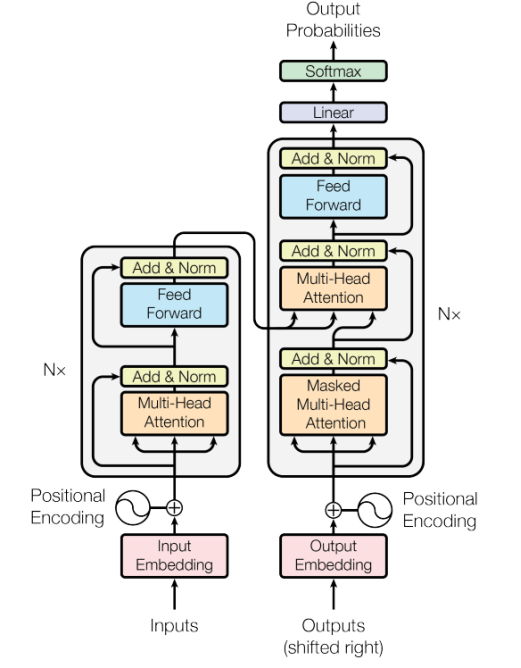
Figure 3 Organigramme du mécanisme d'attention
Comme le montre la figure ci-dessus, le transformateur se compose de deux parties : le module d'encodeur et der Composition du module, l'encodeur et le décodeur contiennent N blocs. En prenant la tâche de traduction comme exemple, le flux de travail de Transformer est à peu près le suivant :
Étape 1 : Obtenir le vecteur de représentation X de chaque mot de la phrase d'entrée X est obtenu en ajoutant l'incorporation du mot lui-même et l'incorporation de. la position du mot.
Étape 2 : Transmettez la matrice vectorielle de représentation de mot obtenue dans le module Encoder. Le module Encoder utilise la méthode Attention pour calculer les données d'entrée. Après N modules Encoder, la matrice d'informations de codage de tous les mots de la phrase peut être obtenue. Les dimensions de la matrice sorties par chaque module Encoder sont exactement les mêmes que celles de l'entrée.
Étape 3 : Transmettez la matrice d'informations d'encodage sortie par le module Encoder au module Décodeur, et le Décodeur traduira le mot suivant i+1 en fonction du mot actuellement traduit i. Comme la structure Encoder, la structure Decoder utilise également la méthode Attention pour le calcul. Pendant l'utilisation, lors de la traduction vers le mot i+1, vous devez utiliser l'opération Masque pour couvrir les mots après i+1.
3.2 Calcul de l'attention personnelle
Le cœur du modèle Transform est le calcul de l'attention, qui peut être exprimé par la formule
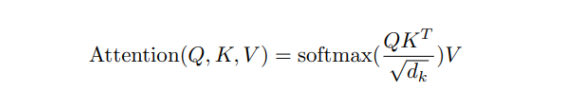
où Q, K, V représentent respectivement Requête, Clé, Valeur, Ces trois concepts sont tirés des systèmes de recherche d'informations, à titre d'exemple de recherche simple. Lorsque vous recherchez un produit sur une plateforme de commerce électronique, le contenu que vous saisissez sur le moteur de recherche est une requête, puis le moteur de recherche fait correspondre la clé pour vous en fonction de la requête (telle que le type, la couleur, la description, etc. ) du produit, puis, en fonction de la requête et de la similarité de la clé, obtient le contenu correspondant (valeur).
Q, K, V dans l'auto-attention jouent également un rôle similaire. Dans les calculs matriciels, le produit scalaire est l'une des méthodes pour calculer la similarité de deux matrices, donc la matrice Q multipliée par la matrice K est utilisée dans la formule ci-dessus La transposition est utilisée pour calculer la similarité. Afin d'éviter que le produit interne ne soit trop grand, il doit être divisé par la racine carrée de d, et enfin une fonction d'activation softmax est appliquée au résultat.
3.3 Encodage positionnel
En plus de l'intégration du mot lui-même, le transformateur doit également utiliser l'intégration positionnelle pour représenter la position où le mot apparaît dans la phrase. Étant donné que Transformer n'utilise pas la structure de RNN, mais utilise des informations globales, il ne peut pas utiliser les informations d'ordre des mots, et cette partie de l'information est très importante pour la PNL ou le CV. Par conséquent, l'intégration de position est utilisée dans Transformer pour enregistrer la position relative ou absolue du mot dans la séquence.
Position Embedding est représenté par PE, et la dimension de PE est la même que le mot Embedding. Le PE peut être obtenu grâce à la formation ou calculé à l'aide d'une certaine formule. Ce dernier est utilisé dans Transformer, et la formule de calcul est la suivante :
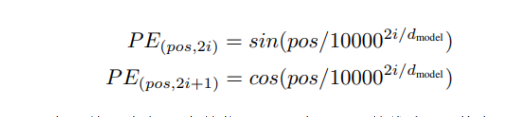
où pos représente la position du mot dans la phrase, d représente la dimension de PE, et sa taille est la même que l'Embedding du mot lui-même, 2i représente le nombre pair de dimensions, 2i+1 représente les dimensions impaires.
4.Résumé
L'objectif de Transformer est la structure d'auto-attention. Grâce à la structure d'attention multidimensionnelle, le réseau peut capturer les relations cachées entre les mots dans plusieurs dimensions. Cependant, Transformer lui-même ne peut pas utiliser les informations d'ordre des mots, l'intégration de position doit donc le faire. être ajouté à l'entrée, utilisé pour stocker les informations de position des mots. Par rapport au réseau neuronal récurrent, le réseau Transformer peut mieux être entraîné en parallèle. Par rapport au réseau neuronal convolutif, le nombre d'opérations requises par le réseau Transformer pour calculer l'association entre deux positions n'augmente pas avec la distance, ce qui peut se rompre. à travers le réseau neuronal convolutif. La distance calculée est limitée à la taille du champ récepteur. Dans le même temps, le réseau Transformer peut produire des modèles plus interprétables. Nous pouvons examiner la répartition de l’attention à partir du modèle, et chaque responsable de l’attention peut apprendre à effectuer différentes tâches.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI