
Maison >base de données >tutoriel mysql >Analyse d'exemples d'infrastructure MySQL et de système de journalisation
Analyse d'exemples d'infrastructure MySQL et de système de journalisation

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-04 16:27:311055parcourir

1. Infrastructure MySQL
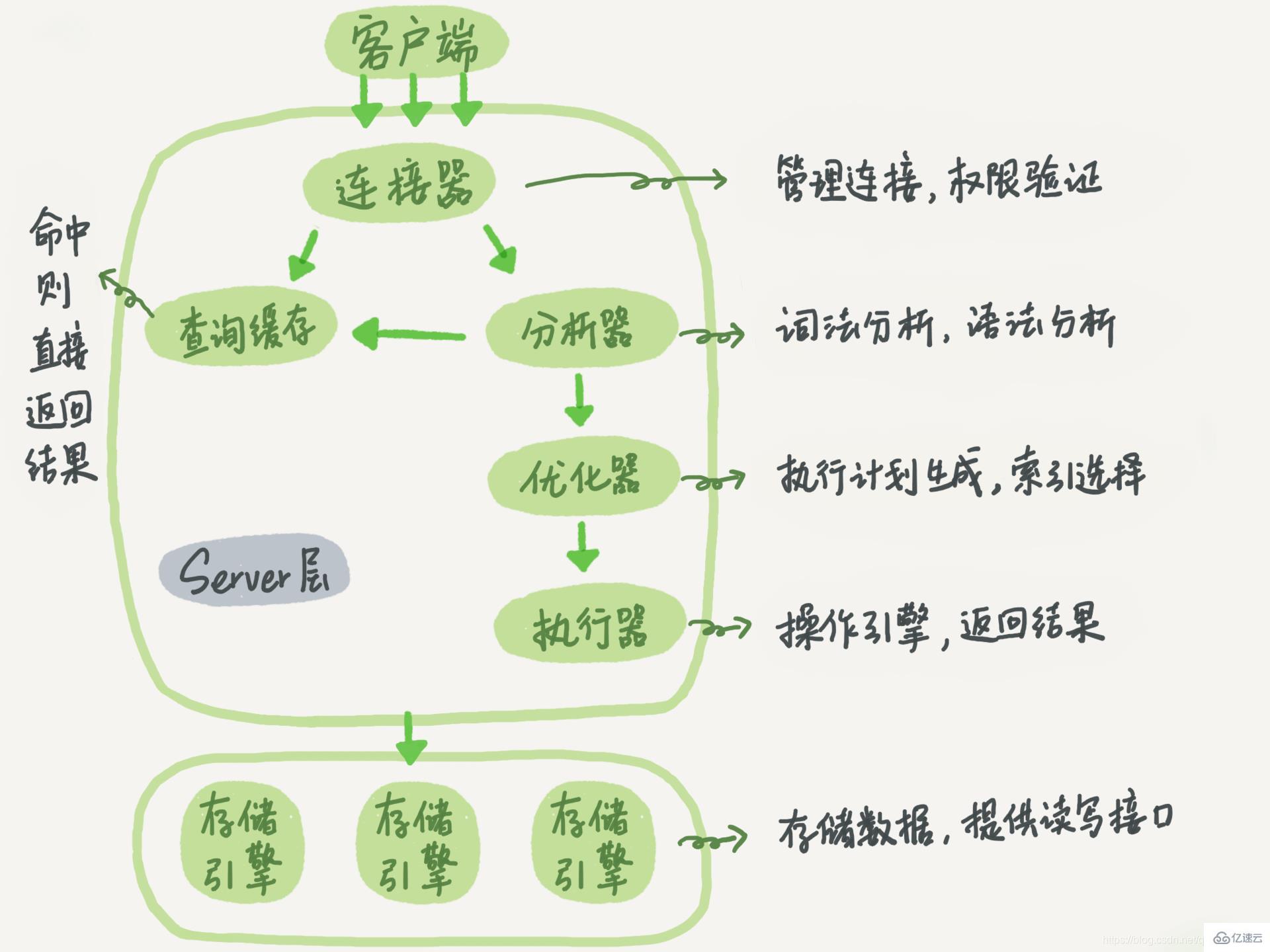
MySQL peut être divisé en serveur La couche serveur comprend des connecteurs, des caches de requêtes, des analyseurs, des optimiseurs, des exécuteurs, etc., couvrant la plupart des fonctions de base du service MySQL, ainsi que toutes les fonctions intégrées (telles que les fonctions de date, d'heure, mathématiques et de chiffrement, etc.), toutes les fonctions du moteur de stockage croisé sont implémentées dans cette couche, telles que les procédures stockées, les déclencheurs, les vues, etc.
Le moteur de stockage est responsable du stockage et de la récupération des données. Plusieurs moteurs de stockage (tels que InnoDB, MyISAM et Memory) peuvent être pris en charge, sur la base du modèle d'architecture de plug-in. InnoDB est actuellement le moteur de stockage le plus utilisé et est devenu le moteur de stockage par défaut depuis la version 5.5.5 de MySQL. La méthode pour spécifier l'exécution du moteur de mémoire consiste à utiliser engin=memory
Différents moteurs de stockage partagent une couche serveur
1, Connector#🎜🎜 ##🎜🎜 #Le connecteur est chargé d'établir une connexion avec le client, d'obtenir les autorisations, de maintenir et de gérer la connexion. La commande de connexion est généralement : mysql -h$ip -P$port -u$user -p
Le mysql dans la commande de connexion est un outil client utilisé pour établir une connexion avec le serveur. Après avoir terminé la négociation TCP, le connecteur commencera à authentifier l'identité
Si le nom d'utilisateur ou le mot de passe est incorrect, vous recevrez une erreur « Accès refusé pour l'utilisateur ». Ensuite, le programme client termine l'exécution
Le connecteur récupérera les autorisations dont vous disposez dans le tableau des autorisations après avoir vérifié le nom d'utilisateur et le mot de passe. Ensuite, la logique de jugement des autorisations dans cette connexion dépendra des autorisations lues à ce moment-là
Cela signifie qu'après qu'un utilisateur ait établi avec succès une connexion, si le compte administrateur modifie les autorisations de cet utilisateur, cela n'affectera pas les autorisations des connexions existantes. Une fois la modification terminée, seules les connexions nouvellement créées utiliseront les nouveaux paramètres d'autorisation
Une fois la connexion terminée, si vous n'avez aucune action ultérieure, la connexion sera dans un état inactif, ce qui peut être vu dans la commande show processlist, elle
 Si le client ne le fait pas bougez trop longtemps, le connecteur Il sera automatiquement déconnecté. Ce temps est contrôlé par le paramètre wait_timeout. La valeur par défaut est de 8 heures
Si le client ne le fait pas bougez trop longtemps, le connecteur Il sera automatiquement déconnecté. Ce temps est contrôlé par le paramètre wait_timeout. La valeur par défaut est de 8 heures
Si le client envoie à nouveau une requête après la déconnexion de la connexion, il recevra un message d'erreur : Connexion perdue au serveur MySQL lors de la requête. A ce moment, vous devez vous reconnecter puis exécuter la requête
Lorsque le client continue d'envoyer des requêtes, une connexion longue fait référence à l'utilisation de la même connexion après avoir établi une connexion avec la base de données. Une connexion courte signifie que la connexion est déconnectée après l'exécution de quelques requêtes à chaque fois, et qu'une nouvelle est rétablie pour la requête suivante
Le processus d'établissement d'une connexion est généralement plus compliqué, donc. il est recommandé d'utiliser une connexion longue
Mais après que toutes les connexions longues soient utilisées, parfois la mémoire occupée par MySQL augmente très rapidement En effet, la mémoire temporairement utilisée par MySQL lors de l'exécution est gérée dans l'objet de connexion. . Ces ressources seront libérées lorsque la connexion sera déconnectée. Par conséquent, si de longues connexions s'accumulent, elles peuvent occuper trop de mémoire et être interrompues de force par le système (MOO). À en juger par le phénomène, MySQL redémarre anormalement
Vous pouvez résoudre ce problème grâce aux deux solutions suivantes. :# 🎜🎜#
1. Déconnectez régulièrement les longues connexions. Selon le jugement interne du programme, si une requête occupant une grande quantité de mémoire est exécutée, la connexion sera déconnectée après un certain temps. Si vous devez effectuer une nouvelle requête, vous devez rétablir la connexion 2 Si vous utilisez MySQL5.7 ou une version plus récente, vous pouvez réinitialiser la connexion en exécutant mysql_reset_connection après chaque opération importante. Reformulé : bien que ce processus ne nécessite pas de reconnexion ou de vérification des autorisations, il restaurera l'état de connexion à l'état initial de création 🎜🎜#Une fois la connexion établie, l'instruction select peut être exécutée. Une fois que MySQL a reçu une requête de requête, il ira d'abord dans le cache de requêtes pour voir si cette instruction a déjà été exécutée. Les instructions précédemment exécutées et leurs résultats peuvent être mis en cache directement en mémoire sous forme de paires clé-valeur. La clé est l'instruction de requête et la valeur est le résultat de la requête. Si la clé est trouvée dans le cache, la valeur correspondante sera renvoyée directement au clientSi l'instruction n'est pas dans le cache des requêtes, la phase d'exécution suivante se poursuivra. Une fois l'exécution terminée, les résultats de l'exécution seront stockés dans le cache des requêtes. Si la requête atteint le cache, MySQL peut renvoyer directement le résultat sans effectuer d'opérations complexes ultérieures. Cependant, dans la plupart des cas, il n'est pas recommandé d'utiliser le cache de requêtes. échoue très fréquemment, tant qu'une table est mise à jour, tous les caches de requêtes sur cette table seront effacés. Pour les bases de données soumises à une forte pression de mise à jour, le taux de réussite du cache de requêtes sera très faible可以将参数query_cache_type设置成DEMAND,这样对于默认的SQL语句都不使用查询缓存。而对于确定要是查询缓存的语句,可以用SQL_CACHE显示指定,如下面这条语句一样:
select SQL_CACHE * from T where ID=10;
MySQL8.0版本直接将查询缓存的整块功能删掉了
3、分析器
如果没有命中查询缓存,就要开始真正执行语句了。MySQL首先要对SQL语句做解析
分析器会先做词法分析。MySQL需要识别一条由多个字符串和空格组成的SQL语句,将其中的每个字符串识别并理解其代表的意义
select * from T where ID=10;
当输入select关键字时,MySQL会识别它为一个查询语句。它也要把字符串T识别成表名T,把字符串ID识别成列ID
做完了这些识别以后,就要做语法分析。基于词法分析的结果,语法分析器会依据MySQL语法规则来检查这个SQL语句是否符合规范。如果语法不对,就会收到"You have an error in your SQL syntax"的错误提示
4、优化器
经过了分析器,在开始执行之前,还要先经过优化器的处理
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联的时候,决定各个表的连接顺序
5、执行器
优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段,开始执行语句
开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示
mysql> select * from T where ID=10; ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口
比如在表T中,ID字段没有索引,那么执行器的执行流程是这样的:
1.调用InnoDB引擎接口取这个表的第一行,判断ID值是不是10,如果不是则跳过,如果是则将这个行存在结果集中
2.调用引擎接口取下一行,重复相同的判断逻辑,直到取到这个表的最后一行
3.执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端
在慢查询日志中可以查看到一个名为rows_examined的字段,其表示执行该语句所扫描的行数。这个值就是在执行器每次调用引擎获取数据行的时候累加的
在有些场景下,执行器调用一次,在引起内部则扫描了多行,因此引擎扫描行数跟rows_examined并不是完全相同的
二、日志系统
表T的创建语句如下,这个表有一个主键ID和一个整型字段c:
create table T(ID int primary key, c int);
如果要将ID=2这一行的值加1,SQL语句如下:
update T set c=c+1 where ID=2;
1、redo log(重做日志)
在MySQL中,如果每次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程IO成本、查找成本都很高。MySQL里常说的WAL技术,全称是Write-Ahead Logging,它的关键点就是先写日志,再写磁盘
当有一条记录需要更新的时候,InnoDB引擎就会把记录写到redo log里面,并更新buffer pool的page,这个时候更新就算完成了
buffer pool是物理页的缓存,对InnoDB的任何修改操作都会首先在buffer pool的page上进行,然后这样的页面将被标记为脏页并被放到专门的flush list上,后续将由专门的刷脏线程阶段性的将这些页面写入磁盘
InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,从头开始写,写到末尾就又回到开头循环写
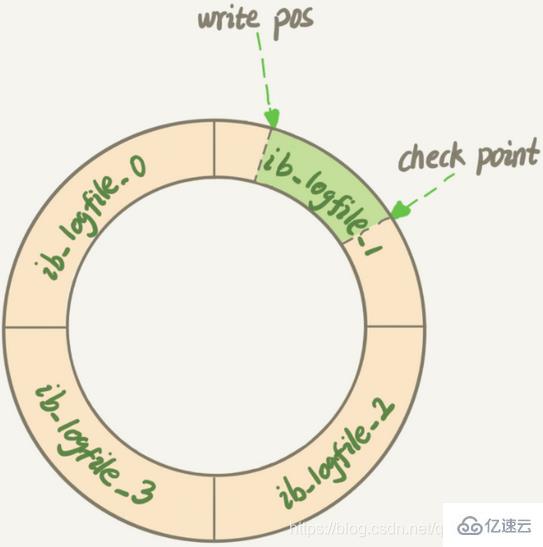
write pos是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。check point是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
write pos和check point之间空着的部分,可以用来记录新的操作。如果write pos追上check point,这时候不能再执行新的更新,需要停下来擦掉一些记录,把check point推进一下
有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe
2、binlog(归档日志)
MySQL整体来看就有两块:一块是Server层,主要做的是MySQL功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。InnoDB引擎拥有一种特定的日志称为redo log,而Server层也有其自己的日志,被称为binlog
为什么会有两份日志?
Parce qu'il n'y avait pas de moteur InnoDB dans MySQL au début. Le moteur fourni avec MySQL est MyISAM, mais MyISAM n'a pas de fonctionnalités de sécurité contre les pannes et les journaux binlog ne peuvent être utilisés qu'à des fins d'archivage. InnoDB est introduit dans MySQL sous la forme d'un plug-in. Étant donné que le fait de s'appuyer uniquement sur binlog n'a pas de fonctionnalités anti-crash, InnoDB utilise le redo log pour obtenir des capacités anti-crash : Il existe trois formats de journal binlog : STATEMENT, ROW, MIXED
1), mode STATEMENT
Le texte original de l'instruction SQL est enregistré dans le binlog. L'avantage est qu'il n'est pas nécessaire d'enregistrer les modifications de données dans chaque ligne, ce qui réduit la quantité de journaux binlog, économise les E/S et améliore les performances. L'inconvénient est que dans certains cas, les données du maître-esclave seront incohérentes (comme la fonction sleep(), last_insert_id() et les fonctions définies par l'utilisateur (udf), etc. causeront des problèmes)
2) , mode ROW
Il suffit d'enregistrer les données qui ont été modifiées et l'état modifié, sans enregistrer les informations contextuelles de chaque instruction SQL. Et il n'y aura aucun problème si les appels et les déclencheurs de procédures, de fonctions ou de déclencheurs stockés ne peuvent pas être copiés correctement dans certaines circonstances. L'inconvénient est qu'il générera une grande quantité de logs, notamment lors d'opérations de modification de table, ce qui entraînera une augmentation rapide des logs
3), mode MIXTE
L'utilisation mixte des deux modes ci-dessus, réplication générale utilise le mode STATEMENT pour enregistrer le binlog, pour les opérations qui ne peuvent pas être copiées en mode STATEMENT, utilisez le mode ROW pour enregistrer le binlog. MySQL sélectionnera la méthode de sauvegarde du journal en fonction de l'instruction SQL exécutée
3.
1. Le redo log est unique au moteur InnoDB ; Binlog est implémenté par la couche serveur de MySQL et peut être utilisé par tous les moteurs
2. Redo log est un journal physique, qui enregistre les modifications apportées à un certain. data; binlog est un journal logique, qui enregistre la version originale de l'instruction. Logique, par exemple, ajoutez 1 au champ c dans la ligne avec ID=23. Le journal redo est écrit en boucle, et le journal logique est enregistré. l'espace sera toujours utilisé ; le journal binlog peut être écrit en plus, et le fichier binlog sera basculé vers le suivant après avoir atteint une certaine taille. Un, il n'écrasera pas le journal précédent
4. Le processus interne de l'exécuteur et du moteur InnoDB lors de l'exécution de cette instruction de mise à jour :1 L'exécuteur trouve d'abord le moteur et prend ID=2 Cette ligne. L'ID est la clé primaire et le moteur utilise directement la recherche arborescente pour trouver cette ligne. Si les données de la ligne avec ID=2 sont déjà dans la mémoire, elles seront renvoyées directement à l'exécuteur ; sinon, elles doivent d'abord être lues dans la mémoire à partir du disque, puis renvoyées 2. L'exécuteur récupère le. données de ligne fournies par le moteur, ajoutez 1 à cette valeur pour obtenir une nouvelle ligne de données, puis appelez l'interface du moteur pour écrire la nouvelle ligne de données
3 Le moteur met à jour la nouvelle ligne de données dans la mémoire et enregistre. l'opération de mise à jour dans le journal redo. Ceci lorsque le journal redo est en état de préparation. Informez ensuite l'exécuteur que l'exécution est terminée et que vous pouvez soumettre la transaction à tout moment4 L'exécuteur génère le binlog de cette opération et écrit le binlog sur le disque
5 L'exécuteur appelle l'interface de transaction de validation du moteur, et le moteur écrit le redo qui vient d'être écrit. Le journal passe à l'état soumis et la mise à jour est terminée. L'organigramme d'exécution de l'instruction de mise à jour est le suivant. La boîte lumineuse dans l'image indique qu'elle est exécutée dans InnoDB et. la case sombre indique qu'il est exécuté dans l'exécuteur.
L'écriture du redo log est divisée en deux étapes : préparer et valider, qui est une validation en deux étapes puisque le redo log et le binlog sont deux logiques indépendantes, si. une validation en deux étapes n'est pas nécessaire, soit écrivez d'abord le journal de rétablissement, puis écrivez le journal binaire, soit écrivez d'abord le journal binaire, puis écrivez le journal de rétablissement1 Complétez d'abord le journal de rétablissement, puis écrivez le journal binaire. Si le processus MySQL redémarre anormalement lorsque le redo log a été écrit mais que le binlog n'a pas encore été écrit. Puisqu'une fois le journal redo écrit, même si le système tombe en panne, les données peuvent toujours être récupérées, donc la valeur de c dans cette ligne après la récupération est 1. Cependant, comme le binlog s'est écrasé avant d'être terminé, cette instruction n'a pas été enregistrée dans le binlog pour le moment. La valeur de c dans cette ligne enregistrée dans le binlog est 02. Écrivez d'abord le binlog, puis le redo log. S'il y a un crash après l'écriture du binlog, puisque le redo log n'a pas encore été écrit, la transaction sera invalide après la récupération sur crash, donc la valeur de c dans cette ligne est 0. Mais le binlog a déjà enregistré le journal du changement de c de 0 à 1. Par conséquent, lors de l'utilisation de la récupération du journal binaire, il y aura une transaction supplémentaire et la valeur de la colonne c finalement récupérée sera 1Si la validation en deux phases n'est pas utilisée, l'état de la base de données peut être incohérent avec l'état de la bibliothèque utilisant sa récupération de journal. . Le journal redo et le binlog peuvent être utilisés pour représenter l'état de validation d'une transaction, et la validation en deux étapes consiste à maintenir les deux états logiquement cohérents. Le journal redo est utilisé pour garantir des capacités de sécurité en cas de crash. Lorsque le paramètre innodb_flush_log_at_trx_commit est défini sur 1, cela signifie que le journal redo de chaque transaction est directement conservé sur le disque. Cela peut garantir que les données ne seront pas perdues après un redémarrage anormal de MySQL. Lorsque le paramètre sync_binlog est défini sur 1, cela signifie. le journal binaire de chaque transaction. Tous sont conservés sur le disque, ce qui garantit que le journal binaire ne sera pas perdu après un redémarrage anormal de MySQL三、MySQL刷脏页
1、刷脏页的场景
当内存数据页跟磁盘数据页不一致的时候,我们称这个内存页为脏页。当内存数据被写入磁盘后,内存和磁盘上的数据页就会保持一致,这种状态被称为“干净页”
第一种场景是,InnoDB的redo log写满了,这时候系统会停止所有更新操作,把checkpoint往前推进,redo log留出空间可以继续写

checkpoint位置从CP推进到CP’,就需要将两个点之间的日志对应的所有脏页都flush到磁盘上。之后,上图中从write pos到CP’之间就是可以再写入的redo log的区域第二种场景是,系统内存不足。当内存空间不足以分配新的内存页时,系统会选择淘汰一些数据页来腾出内存空间以供其他数据页使用。如果淘汰的是脏页,就要先将脏页写到磁盘
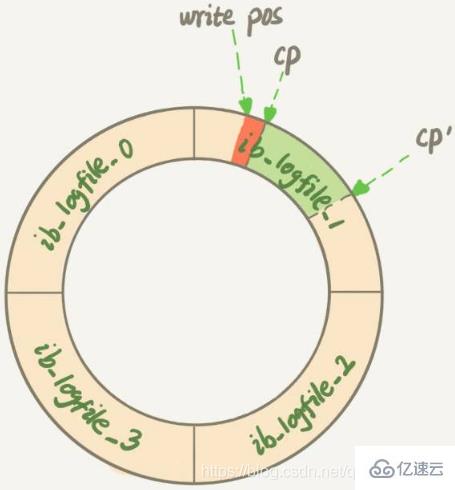
这时候不能直接把内存淘汰掉,下次需要请求的时候,从磁盘读入数据页,然后拿redo log出来应用不就行了?
这里是从性能考虑的。如果刷脏页一定会写盘,就保证了每个数据页有两种状态:一种是内存里存在,内存里就肯定是正确的结果,直接返回;另一种是内存里没有数据,就可以肯定数据文件上是正确的结果,读入内存后返回。这样的效率最高
第三种场景是,MySQL认为系统空闲的时候刷脏页,当然在系统忙的时候也要找时间刷一点脏页
第四种场景是,MySQL正常关闭的时候会把内存的脏页都flush到磁盘上,这样下次MySQL启动的时候,就可以直接从磁盘上读数据,启动速度会很快
redo log写满了,要flush脏页,出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住
内存不够用了,要先将脏页写到磁盘,这种情况是常态。InnoDB用缓冲池管理内存,缓冲池中的内存页有三种状态:
第一种是还没有使用的
第二种是使用了并且是干净页
第三种是使用了并且是脏页
InnoDB的策略是尽量使用内存,因此对于一个长时间运行的库来说,未被使用的页面很少
如果要读取的数据页不在内存中,则需要从缓冲池中请求一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页,即必须将脏页先刷到磁盘,变成干净页后才能复用
刷页虽然是常态,但是出现以下两种情况,都是会明显影响性能的:
一个查询要淘汰的脏页个数太多,会导致查询的响应时间明显变长
日志写满,更新全部堵住,写性能跌为0,这种情况对敏感业务来说,是不能接受的
2、InnoDB刷脏页的控制策略
首先,要正确地告诉InnoDB所在主机的IO能力,这样InnoDB才能知道需要全力刷脏页的时候,可以刷多快。参数为innodb_io_capacity,建议设置成磁盘的IOPS
考虑到脏页比例和redo log写入速度,InnoDB的刷盘速度得到优化。默认值为75%,参数innodb_max_dirty_pages_pct限制了脏页的比例。脏页比例是通过Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total得到的,SQL语句如下:
mysql> select VARIABLE_VALUE into @a from performance_schema.global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty'; select VARIABLE_VALUE into @b from performance_schema.global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total'; select @a/@b;
四、日志相关问题
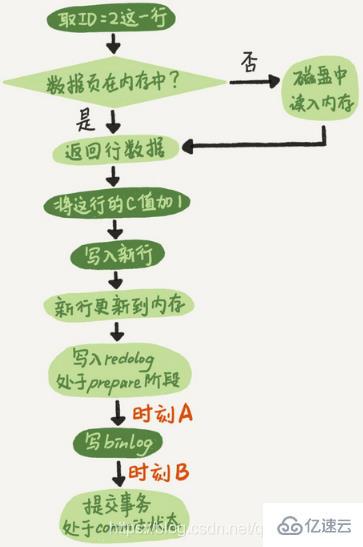
问题一:在两阶段提交的不同时刻,MySQL异常重启会出现什么现象
如果在图中时刻A的地方,也就是写入redo log处于prepare阶段之后、写binlog之前,发生了崩溃,由于此时binlog还没写,redo log也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog还没写,所以也不会传到备库
如果在图中时刻B的地方,也就是binlog写完,redo log还没commit前发生崩溃,那崩溃恢复的时候MySQL怎么处理?
崩溃恢复时的判断规则:
1)如果redo log里面的事务是完整的,也就是已经有了commit标识,则直接提交
2)如果redo log里面的事务只有完整的prepare,则判断对应的事务binlog是否存在并完整
a.如果完整,则提交事务
b.否则,回滚事务
时刻B发生崩溃对应的就是2(a)的情况,崩溃恢复过程中事务会被提交
问题二:MySQL怎么知道binlog是完整的?
一个事务的binlog是有完整格式的:
statement格式的binlog,最后会有COMMIT
row格式的binlog,最后会有一个XID event
问题三:redo log和binlog是怎么关联起来的?
它们有一个共同的数据字段,叫XID。崩溃恢复的时候,会按顺序扫描redo log:
如果碰到既有prepare、又有commit的redo log,就直接提交
如果碰到只有prepare、而没有commit的redo log,就拿着XID去binlog找对应的事务
问题四:redo log一般设置多大?
如果是现在常见的几个TB的磁盘的话,redo log设置为4个文件、每个文件1GB
问题五:正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在数据最终落盘是由redo log更新过去的情况
脏页是指在正常运行的实例中,当数据页被修改后,与存储在磁盘上的数据页不一致。最终数据落盘,就是把内存中的数据页写盘。这个过程,甚至与redo log毫无关系
2.在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它对到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态
问题六:redo log buffer是什么?是先修改内存,还是先写redo log文件?
在一个事务的更新过程中,日志是要写多次的。比如下面这个事务:
begin;insert into t1 ...insert into t2 ...commit;
这个事务要往两个表中插入记录,插入数据的过程中,生成的日志都得先保存起来,但又不能在还没commit的时候就直接写到redo log文件里
所以,redo log buffer就是一块内存,用来先存redo日志的。也就是说,在执行第一个insert的时候,数据的内存被修改了,redo log buffer也写入了日志。在执行commit语句时,才真正将日志写入redo log文件
五、MySQL是怎么保证数据不丢的?
只要redo log和binlog保证持久化到磁盘,就能确保MySQL异常重启后,数据可以恢复
1、binlog的写入机制
事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog文件中。无法分割一个事务的binlog,因此无论该事务有多大,都必须确保一次性写入
系统给binlog cache分配了一片内存,每个线程一个,参数binlog_cache_size用于控制单个线程内binlog cache所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘
事务提交的时候,执行器把binlog cache里的完整事务写入到binlog中,并清空binlog cache
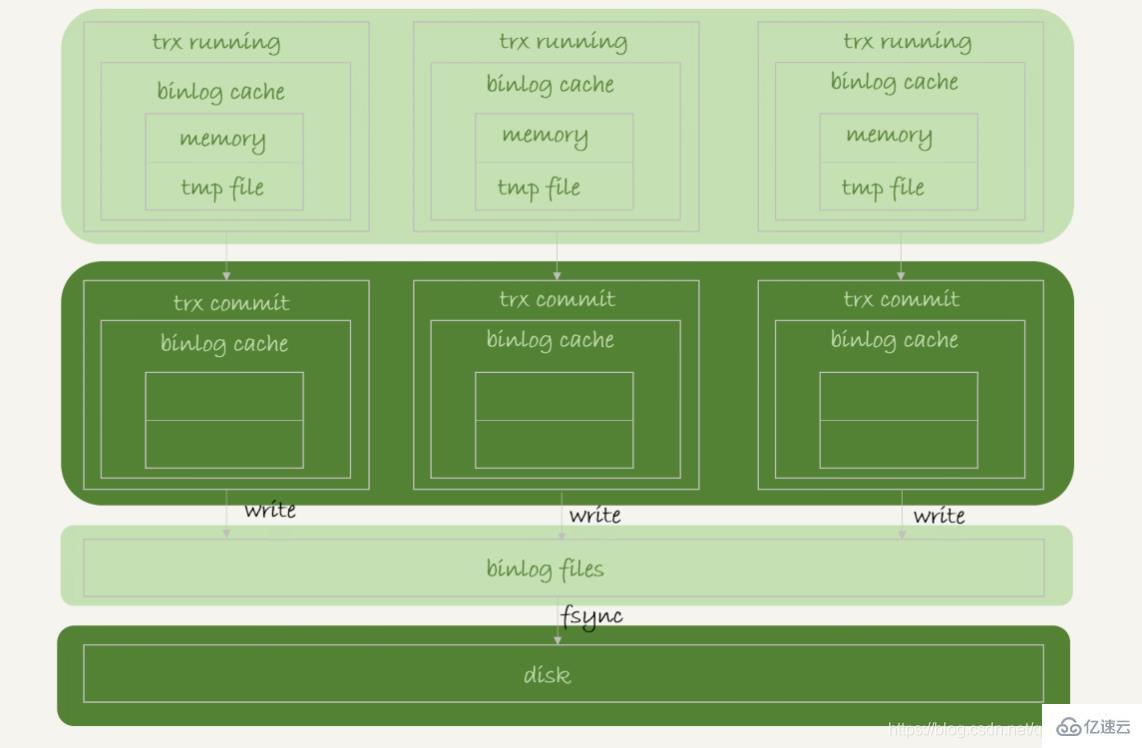
每个线程有自己binlog cache,但是共用一份binlog文件
图中的write,指的就是把日志写入到文件系统的page cache,并没有把数据持久化到磁盘,所以速度比较快
图中的fsync,才是将数据持久化到磁盘的操作。一般情况下认为fsync才占磁盘的IOPS
write和fsync的时机,是由参数sync_binlog控制的:
sync_binlog=0的时候,表示每次提交事务都只write,不fsync
sync_binlog=1的时候,表示每次提交事务都会执行fsync
sync_binlog=N(N>1)的时候,表示每次提交事务都write,但累积N个事务后才fsync
因此,在出现IO瓶颈的场景中,将sync_binlog设置成一个比较大的值,可以提升性能,对应的风险是:如果主机发生异常重启,会丢失最近N个事务的binlog日志
2、redo log的写入机制
在执行事务过程中所产生的 redo log 需要先写入 redo log 缓存。redo log buffer里面的内容不是每次生成后都要直接持久化到磁盘,也有可能在事务还没提交的时候,redo log buffer中的部分日志被持久化到磁盘
redo log可能存在三种状态,对应下图的三个颜色块

这三张状态分别是:
Existe dans le tampon de journalisation, physiquement dans la mémoire du processus MySQL, qui est la partie rouge sur l'image
est écrite sur le disque, mais n'est pas conservée, physiquement dans le cache de pages du système de fichiers, c'est-à-dire La partie jaune sur l'image
est conservée sur le disque, ce qui correspond au disque dur, qui est la partie verte sur l'image
Écriture du journal dans le tampon de journalisation et écriture dans le cache de la page sont à la fois rapides, mais durables La vitesse de vidage sur le disque est beaucoup plus lente
Afin de contrôler la stratégie d'écriture du redo log, InnoDB fournit le paramètre innodb_flush_log_at_trx_commit, qui a trois valeurs possibles :
Lorsqu'il est défini sur 0, il signifie que chaque transaction est soumise. Laissez simplement le journal de rétablissement dans le tampon de journalisation
Lorsqu'il est défini sur 1, cela signifie que le journal de rétablissement sera conservé directement sur le disque à chaque fois qu'une transaction est soumise
Quand défini sur 2, cela signifie que chaque transaction est soumise. InnoDB a un thread d'arrière-plan. Toutes les secondes, il appelle write pour écrire le journal dans le tampon de journalisation dans le cache de pages du système de fichiers, puis appelle fsync pour la persistance sur le disque. . Le journal redo au milieu de l'exécution de la transaction est également écrit directement dans le tampon de journalisation, et ces journaux redo seront également conservés sur le disque par le thread d'arrière-plan. En d'autres termes, même si une transaction n'a pas encore été validée, son journal redo peut avoir été conservé sur le disque
Il existe deux scénarios dans lesquels le journal redo d'une transaction non validée sera écrit sur le disque
1.redo log buffer Lorsque l'espace occupé est sur le point d'atteindre la moitié de innodb_log_buffer_size, le thread d'arrière-plan écrira activement sur le disque. Étant donné que la transaction n'a pas été soumise, l'action d'écriture sur le disque consiste uniquement à écrire sans appeler fsync, ce qui signifie qu'elle ne reste que dans le cache de pages du système de fichiers
2 Lorsqu'une transaction parallèle est soumise, le tampon de journalisation de cette transaction. est conservé sur le disque. Supposons que la transaction A est à mi-chemin de l'exécution et qu'elle a écrit des journaux de rétablissement dans le tampon. À ce stade, la transaction B d'un autre thread est soumise. Si innodb_flush_log_at_trx_commit est défini sur 1, la transaction B conservera tous les journaux dans le tampon de rétablissement. disque. Lorsque cela se produit, le tampon de journalisation lié à la transaction A sera enregistré ensemble sur le disque.
Validation en deux étapes, le journal de restauration est préparé en premier, puis le journal binaire est écrit et enfin le journal de restauration est écrit. engagé. Si innodb_flush_log_at_trx_commit est défini sur 1, alors le journal redo sera conservé une fois dans la phase de préparation
La configuration double 1 de MySQL signifie que sync_binlog et innodb_flush_log_at_trx_commit sont tous deux définis sur 1. En d'autres termes, avant qu'une transaction ne soit entièrement validée, elle doit attendre deux vidages de disque, un pour le redo log (étape de préparation) et un pour le binlog
3 Mécanisme de soumission de groupeLe numéro de séquence logique du journal LSN est. croissant de manière monotone Utilisé pour correspondre aux points d'écriture du redo log Chaque fois qu'un redo log de longueur length est écrit, la valeur de LSN sera ajoutée à la longueur. LSN sera également enregistré dans la page de données d'InnoDB pour garantir que l'exécution répétée du journal de rétablissement évitera les mises à jour répétées de la page de données
L'image ci-dessus montre trois transactions simultanées dans la phase de préparation, qui ont toutes écrit le rétablissement. tampon de journal et conservé dans le processus du disque, les LSN correspondants sont respectivement 50, 120 et 160
1. trx1 est le premier à arriver et sera sélectionné comme leader de ce groupe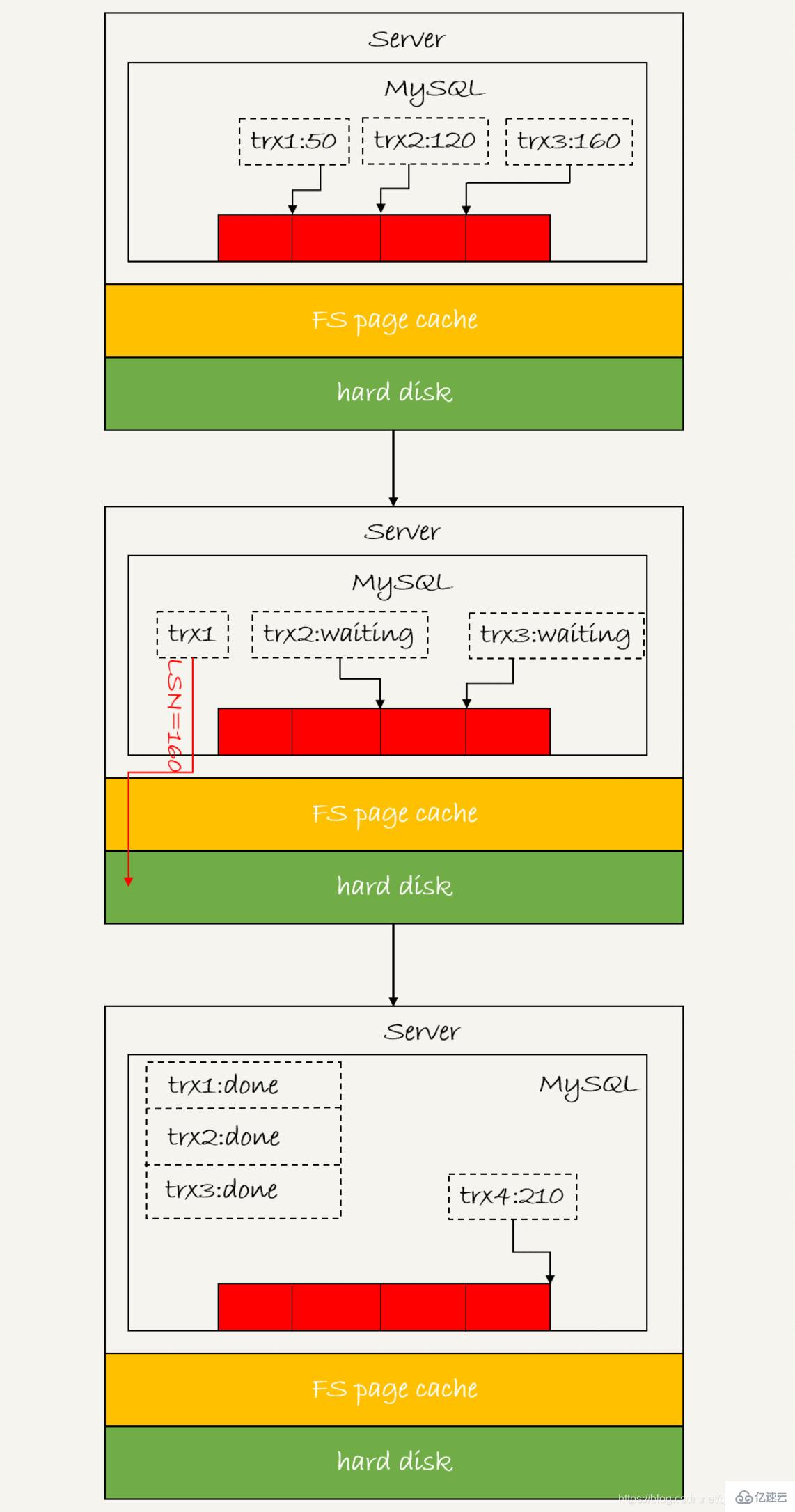
2 au moment où trx1 est sur le point d'arriver. commence à écrire sur le disque, ce groupe a déjà Avec trois transactions, le LSN est également devenu 160
3 Lorsque trx1 écrit sur le disque, il apporte LSN=160 Par conséquent, lorsque trx1 revient, tous les journaux de rétablissement avec LSN inférieur à. ou égal à 160 ont été supprimés. Persistance sur le disque
4 À l'heure actuelle, trx2 et trx3 peuvent être renvoyés directement
Dans une soumission de groupe, plus il y a de membres du groupe, meilleur est l'effet de sauvegarde des IOPS sur le disque
Dans l'ordre. pour permettre à un fsync d'amener plus de membres du groupe, MySQL Nous avons optimisé le délai
binlog peut également être soumis en groupe lors de l'exécution de l'étape 4 de la figure ci-dessus pour fsync le binlog sur le disque, si les binlogs de. plusieurs transactions ont été écrites, elles seront conservées ensemble, cela peut donc également réduire la consommation d'IOPS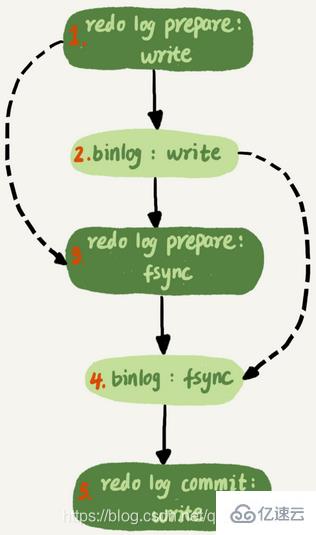 Si vous souhaitez améliorer l'effet de la soumission du groupe binlog, vous pouvez y parvenir en définissant les deux paramètres binlog_group_commit_sync_delay et binlog_group_commit_sync_no_delay_count
Si vous souhaitez améliorer l'effet de la soumission du groupe binlog, vous pouvez y parvenir en définissant les deux paramètres binlog_group_commit_sync_delay et binlog_group_commit_sync_no_delay_count
1 . Le paramètre binlog_group_commit_sync_delay indique combien de microsecondes attendre avant d'appeler fsync
2.binlog_group_commit_sync Le paramètre _no_delay_count indique l'accumulation Combien de fois fsync sera appelé tant que l'une de ces deux conditions est remplie, fsync sera appelé. bénéficie principalement de deux aspects :
redo log et binlog sont écrits séquentiellement, et l'écriture séquentielle du disque est plus rapide que l'écriture aléatoireLe mécanisme de soumission de groupe peut réduire considérablement la consommation d'IOPS des commandes de disque
4. Si MySQL a maintenant un goulot d'étranglement en termes de performances et que le goulot d'étranglement concerne les E/S, quelles méthodes peuvent être utilisées pour améliorer les performances
# 🎜🎜 #1. Définissez les paramètres binlog_group_commit_sync_delay (combien de microsecondes attendre avant d'appeler fsync) et binlog_group_commit_sync_no_delay_count (combien de fois accumuler avant d'appeler fsync) pour réduire le nombre d'écritures binlog sur le disque. Bien que cette méthode puisse augmenter le temps de réponse de l'instruction, il n'y a aucun risque de perte de données car elle est obtenue en attendant délibérément 2 Définissez sync_binlog sur une valeur supérieure à 1 (chaque validation Toutes les transactions sont. write, mais fsync n'est effectué qu'après que N transactions ont été accumulées). Le risque de faire cela est que le journal binlog sera perdu lorsque l'hôte est mis hors tension 3 Définissez innodb_flush_log_at_trx_commit sur 2 (écrivez uniquement le journal de rétablissement dans le cache de page à chaque fois qu'une transaction est validée). . Le risque de faire cela est que les données seront perdues lorsque l'hôte est éteintCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!