
Maison >base de données >Redis >Comment résoudre les problèmes liés à Redis
Comment résoudre les problèmes liés à Redis

- PHPzavant
- 2023-06-04 08:33:021248parcourir
Mécanisme de persistance Redis
Redis est une base de données en mémoire qui prend en charge la persistance. Elle synchronise les données en mémoire avec les fichiers du disque dur via le mécanisme de persistance pour garantir la persistance des données. Lorsque Redis est redémarré, les données peuvent être restaurées en rechargeant les fichiers du disque dur dans la mémoire.
Implémentation : créez un processus enfant fork() séparément, copiez les données de la base de données du processus parent actuel dans la mémoire du processus enfant, puis écrivez-les dans un fichier temporaire par le processus enfant. Lorsque le processus de persistance est terminé, remplacez-le. avec ce fichier temporaire. Le dernier fichier instantané, puis le processus enfant se termine et la mémoire est libérée.
RDB est la méthode de persistance par défaut de Redis. Selon une certaine stratégie de période de temps, les données de la mémoire sont enregistrées dans le fichier binaire du disque dur sous la forme d'un instantané. C'est-à-dire le stockage des instantanés d'instantanés, le fichier de données généré correspondant est dump.rdb et le cycle d'instantané est défini via le paramètre de sauvegarde dans le fichier de configuration. (Un instantané peut être une copie des données qu'il représente, ou une copie des données.)
AOF : Redis ajoutera chaque commande d'écriture reçue à la fin du fichier via la fonction Write, similaire au binlog MySQL. Au redémarrage de Redis, le contenu de l'intégralité de la base de données sera reconstruit en mémoire en réexécutant les commandes d'écriture enregistrées dans le fichier.
Lorsque les deux méthodes sont activées en même temps, la récupération de données Redis donnera la priorité à la récupération AOF.
Avalanche de cache, pénétration du cache, préchauffage du cache, mise à jour du cache, rétrogradation du cache et autres problèmes
Avalanche de cacheOn peut simplement le comprendre comme : en raison de l'invalidation du cache d'origine, le nouveau cache n'a pas encore expiré (par exemple exemple : nous définissons le même délai d'expiration pour la mise en cache, et une grande zone de cache expire en même temps). Toutes les requêtes qui devraient initialement accéder au cache vont interroger la base de données, ce qui exerce une pression énorme sur le cache. CPU et mémoire de la base de données, et peuvent sérieusement entraîner des temps d'arrêt de la base de données. Cela crée une série de réactions en chaîne, provoquant l’effondrement de l’ensemble du système.
Solution : La plupart des concepteurs de systèmes envisagent d'utiliser le verrouillage (la solution la plus courante) ou la mise en file d'attente pour garantir qu'il n'y aura pas un grand nombre de threads lisant et écrivant la base de données en même temps, évitant ainsi un grand nombre de concurrence dans le en cas d'échec La demande incombe au système de stockage sous-jacent. Une autre solution simple consiste à étaler le délai d’expiration du cache.
Pénétration du cache La pénétration du cache fait référence aux données de requête de l'utilisateur, qui ne sont pas trouvées dans la base de données et ne seront naturellement pas trouvées dans le cache. Cela empêchera l'utilisateur de le trouver dans le cache lors de l'interrogation et devra accéder à la base de données pour interroger à nouveau à chaque fois, puis retourner vide (l'équivalent de deux requêtes inutiles). De cette façon, la requête contourne le cache et vérifie directement la base de données. Il s'agit également d'un problème de taux de réussite du cache qui est souvent soulevé.
Solution ; La plus courante consiste à utiliser un
Filtre Bloom pour hacher toutes les données possibles dans un bitmap suffisamment grand. Les données qui n'existent certainement pas seront interceptées par ce bitmap, ce qui évite la pression des requêtes sur le stockage sous-jacent. système. Il existe également une
méthode plus simple et grossière Si les données renvoyées par une requête sont vides (que les données n'existent pas ou que le système tombe en panne), nous mettrons toujours en cache le résultat vide, mais son délai d'expiration sera très long. court, pas plus de cinq minutes. La valeur par défaut définie est directement stockée dans le cache, de sorte que la valeur soit obtenue une deuxième fois dans le cache sans continuer à accéder à la base de données. Cette méthode est la plus simple et la plus grossière. Le disque dur de 5 To est plein de données. Veuillez écrire un algorithme pour dédupliquer les données. Comment résoudre le problème si les données sont de 32 bits ? Et si c'était 64 bits ?
Bitmap : la table de hachage typique est celle-ci. L'inconvénient est que Bitmap ne peut enregistrer qu'un seul bit d'information pour chaque élément. Si vous souhaitez remplir des fonctions supplémentaires, je crains que vous ne puissiez le faire qu'en sacrifiant plus d'espace et de temps.
Filtre Bloom (recommandé)
introduit k(k>1)k(k>1) des fonctions de hachage mutuellement indépendantes pour garantir que la détermination du poids des éléments est terminée dans un espace et un taux d'erreur de jugement donnés.
Son avantage est que l'efficacité spatiale et le temps de requête sont bien supérieurs à l'algorithme général. Son inconvénient est qu'il présente un certain taux de mauvaise reconnaissance et des difficultés de suppression.
L'idée centrale de l'algorithme Bloom-Filter est d'utiliser plusieurs fonctions de hachage différentes pour résoudre les « conflits ».
Hash a un problème de conflit (collision), et les valeurs de deux URL obtenues en utilisant le même Hash peuvent être les mêmes. Afin de réduire les conflits, nous pouvons introduire plusieurs valeurs de hachage supplémentaires. Si nous concluons à partir de l'une des valeurs de hachage qu'un élément n'est pas dans l'ensemble, alors l'élément n'est certainement pas dans l'ensemble. Ce n'est que lorsque toutes les fonctions de hachage nous indiquent que l'élément est dans l'ensemble que nous pouvons être sûrs que l'élément existe dans l'ensemble. C'est l'idée de base de Bloom-Filter.
Bloom-Filter est généralement utilisé pour déterminer si un élément existe dans un grand ensemble de données.
Rappel supplémentaire : la différence entre la pénétration du cache et la panne du cache
Pompe du cache : fait référence à une clé très chaude, et une grande concurrence est concentrée sur l'accès à cette clé. Lorsque cette clé expire, elle continue d'être volumineuse. . L'accès simultané traversera le cache et demandera directement la base de données.
Solution : avant d'accéder à la clé, utilisez SETNX (défini si elle n'existe pas) pour définir une autre clé à court terme afin de verrouiller l'accès à la clé actuelle, et supprimez la clé à court terme une fois l'accès terminé.
3. Préchauffage du cache
Le préchauffage du cache devrait être un concept relativement courant. Je pense que de nombreux amis peuvent facilement le comprendre. Le préchauffage du cache signifie qu'une fois le système mis en ligne, les données du cache pertinentes sont directement chargées dans le système de mise en cache. De cette façon, vous pouvez éviter le problème d’interroger d’abord la base de données, puis de mettre les données en cache lorsque l’utilisateur le demande ! Les utilisateurs interrogent directement les données mises en cache qui ont été préchauffées !
Idées de solutions :
1. Écrivez directement une page d'actualisation du cache et faites-le manuellement lors de la connexion
2. La quantité de données n'est pas importante et peut être chargée automatiquement au démarrage du projet
3. Actualisez le cache régulièrement ;
Mise à jour du cache En plus de la stratégie d'invalidation du cache fournie avec le serveur de cache (Redis propose 6 stratégies par défaut), nous pouvons également personnaliser l'élimination du cache en fonction des besoins spécifiques de l'entreprise. :
(1) Nettoyez régulièrement les caches expirés ;
(2) Lorsqu'un utilisateur fait une demande, déterminez si le cache utilisé dans cette demande a expiré, accédez au système sous-jacent pour obtenir de nouvelles données et mettez à jour le cache.
Les deux ont leurs propres avantages et inconvénients. L'inconvénient du premier est qu'il est plus difficile de maintenir un grand nombre de clés en cache. L'inconvénient du second est qu'à chaque fois qu'un utilisateur le demande, le cache doit être jugé. être invalide, et la logique est relativement compliquée ! La solution à utiliser spécifiquement peut être évaluée en fonction de vos propres scénarios d'application.
5.
Rétrogradation du cache Lorsque le nombre de visites augmente fortement, que des problèmes de service surviennent (tels qu'un temps de réponse lent ou aucune réponse) ou que des services non essentiels affectent les performances des processus principaux, il est toujours nécessaire de s'assurer que le le service est toujours disponible, même s'il est endommagé. Servez. Le système peut automatiquement rétrograder en fonction de certaines données clés, ou configurer des commutateurs pour réaliser une rétrogradation manuelle.
Le but ultime du déclassement est de garantir que les services de base sont disponibles, même s'ils entraînent des pertes. Et certains services ne peuvent pas être rétrogradés (comme l'ajout au panier, le paiement).
Définissez le plan en fonction du niveau de journalisation de référence :
(1) Général : par exemple, certains services expirent occasionnellement en raison de la gigue du réseau ou lorsque le service est en ligne, et peuvent être automatiquement rétrogradés ;
(2) Avertissement : certains services ; avez des taux de réussite fluctuants sur une période de temps (par exemple entre 95 et 100 %), vous pouvez automatiquement rétrograder ou rétrograder manuellement et envoyer une alarme
(3) Erreur : par exemple, le taux de disponibilité est inférieur à 90 % ; ou le pool de connexions à la base de données est épuisé, ou le nombre de visites augmente soudainement jusqu'au seuil maximum que le système peut supporter. À ce moment, il peut être automatiquement rétrogradé ou manuellement selon la situation
(4) Erreur grave : Pour ; Par exemple, si les données sont erronées pour des raisons particulières, une rétrogradation manuelle d'urgence est requise.
Que sont les données chaudes et les données froides ?
Les données chaudes, le cache est précieux
Pour les données froides, la plupart des données peuvent avoir été extraites de la mémoire avant d'être consultées à nouveau, ce qui non seulement occupe de la mémoire, mais en a également peu valeur. Pour les données fréquemment modifiées, envisagez d'utiliser le cache en fonction de la situation. Pour les deux exemples ci-dessus, la liste de longévité et les informations de navigation ont toutes deux une caractéristique, c'est-à-dire que la fréquence de modification des informations n'est pas élevée et que le taux de lecture est généralement. très élevé.
Pour les données chaudes, telles que l'un de nos produits de messagerie instantanée, le module de vœux d'anniversaire et la liste des anniversaires du jour, le cache peut être lu des centaines de milliers de fois. Pour un autre exemple, dans un produit de navigation, nous mettons en cache les informations de navigation et pouvons les lire des millions de fois dans le futur.
**Lisez les données au moins deux fois avant la mise à jour, **la mise en cache est significative. Il s'agit de la stratégie la plus élémentaire. Si le cache échoue avant de prendre effet, il n'aura pas beaucoup de valeur.
Qu'en est-il du scénario où le cache n'existe pas et la fréquence de modification est très élevée, mais où la mise en cache doit être prise en compte ? avoir! Par exemple, cette interface de lecture exerce beaucoup de pression sur la base de données, mais il s'agit également de données chaudes. À ce stade, vous devez envisager des méthodes de mise en cache pour réduire la pression sur la base de données, comme le nombre de likes, de collections et. partages de l'un de nos produits assistants. Il s'agit de données chaudes très typiques, mais elles changent constamment. À l'heure actuelle, les données doivent être enregistrées de manière synchrone dans le cache Redis pour réduire la pression sur la base de données.
2). Toutes les valeurs du type de support de données memcached sont de simples chaînes en remplacement, redis prend en charge des types de données plus riches et fournit une liste, un ensemble et un stockage. de structures de données telles que zset et hash
3). Les modèles sous-jacents utilisés sont différents, les méthodes d'implémentation sous-jacentes et les protocoles d'application pour la communication avec le client sont différents. Redis a directement construit son propre mécanisme de VM, car si le système général appelle les fonctions système, il perdra un certain temps à se déplacer et à demander.
4) Les tailles des valeurs sont différentes : Redis peut atteindre un maximum de 512 M ; le cache mémoire ne fait que 1 Mo.
5) La vitesse de Redis est beaucoup plus rapide que celle de Memcached
6) Redis prend en charge la sauvegarde des données, c'est-à-dire la sauvegarde des données en mode maître-esclave.
(2) Fonctionnement monothread, évitant les changements de contexte fréquents
(3) Utilisation d'un mécanisme de multiplexage d'E/S non bloquant
(1) String
Il n'y a en fait rien à dire à ce sujet. L'opération set/get la plus courante, la valeur peut être une chaîne ou une. nombre. Généralement, certaines fonctions de comptage complexes sont mises en cache.
(2) Hash
La valeur ici stocke un objet structuré, et il est plus pratique d'y exploiter un certain champ. Lorsque les blogueurs effectuent une authentification unique, ils utilisent cette structure de données pour stocker les informations utilisateur, utilisent cookieId comme clé et définissent 30 minutes comme délai d'expiration du cache, ce qui peut très bien simuler un effet de session.
(3) list
En utilisant la structure de données de List, vous pouvez exécuter des fonctions simples de file d'attente de messages. Une autre chose est que vous pouvez utiliser la commande lrange pour implémenter la fonction de pagination basée sur Redis, qui offre d'excellentes performances et une bonne expérience utilisateur. J'utilise également un scénario très approprié : obtenir des informations sur le marché. C'est aussi une scène de producteurs et de consommateurs. Le LIST peut très bien mettre en œuvre le principe de file d’attente et du premier entré, premier sorti.
(4) set
Parce que set est une collection de valeurs uniques. Par conséquent, la fonction de déduplication globale peut être implémentée. Pourquoi ne pas utiliser le Set fourni avec la JVM pour la déduplication ? Étant donné que nos systèmes sont généralement déployés en clusters, il est difficile d'utiliser le Set fourni avec la JVM. Est-il trop compliqué de mettre en place un service public uniquement pour effectuer une déduplication globale ?
De plus, en utilisant des opérations telles que l'intersection, l'union et la différence, vous pouvez calculer les préférences communes, toutes les préférences, vos propres préférences, etc.
(5) ensemble trié
l'ensemble trié a un score de paramètre de poids supplémentaire, et les éléments de l'ensemble peuvent être classés en fonction du score. Vous pouvez créer une demande de classement et effectuer des opérations TOP N.
- dict sert essentiellement à résoudre le problème de recherche dans l'algorithme (Recherche). Il s'agit d'une structure de données utilisée pour maintenir la relation de mappage entre la clé et la valeur, similaire à la carte ou au dictionnaire dans de nombreuses langues. Il s'agit essentiellement de résoudre le problème de recherche (Recherche) dans l'algorithme
- sds sds est équivalent à char * Il peut stocker n'importe quelle donnée binaire et ne peut pas être représenté par des caractères comme les chaînes du langage C.
La stratégie d'expiration et le mécanisme d'élimination de la mémoire de redis
redis adopte la stratégie de suppression régulière + suppression paresseuse.
Pourquoi ne pas utiliser une stratégie de suppression planifiée ?
La suppression planifiée utilise une minuterie pour surveiller la clé, et elle sera automatiquement supprimée à son expiration. Bien que la mémoire soit libérée avec le temps, elle consomme beaucoup de ressources CPU. En cas de requêtes simultanées importantes, le processeur doit utiliser du temps pour traiter la requête au lieu de supprimer la clé, cette stratégie n'est donc pas adoptée.
Comment fonctionnent la suppression régulière + la suppression paresseuse ?
Suppression régulière, redis par défaut à 100 ms chacune Vérifiez s'il existe une clé expirée et supprimez-la s'il existe une clé expirée. Il convient de noter que Redis ne vérifie pas toutes les clés toutes les 100 ms, mais les sélectionne au hasard pour inspection (si toutes les clés sont vérifiées toutes les 100 ms, Redis ne serait-il pas bloqué) ? Par conséquent, si vous adoptez uniquement une stratégie de suppression régulière, de nombreuses clés ne seront pas supprimées à ce moment-là.
La suppression paresseuse est donc utile. C'est-à-dire que lorsque vous obtenez une clé, Redis vérifiera si la clé a expiré si un délai d'expiration est défini ? S'il expire, il sera supprimé à ce moment-là.
N'y a-t-il pas d'autres problèmes si vous utilisez la suppression régulière + la suppression paresseuse ?
Non, si la clé n'est pas supprimée si vous la supprimez régulièrement ? Ensuite, vous n'avez pas demandé la clé immédiatement, ce qui signifie que la suppression différée n'a pas pris effet. De cette façon, la mémoire de Redis deviendra de plus en plus élevée. Ensuite, le mécanisme d'élimination de la mémoire doit être adopté.
Il y a une ligne de configuration dans redis.conf
maxmemory-policy volatile-lru
Cette configuration est configurée avec la stratégie d'élimination de mémoire (Quoi, vous ne l'avez pas configuré ? Réfléchissez à vous-même)
volatile-lru : Depuis l'ensemble de données avec le délai d'expiration défini (sélectionnez les données les moins récemment utilisées dans server.db[i].expires) et éliminez-les
volatile-ttl : sélectionnez les données sur le point d'expirer dans l'ensemble de données (server.db[i] .expires) avec un délai d'expiration défini pour l'éliminer
volatile-random : Sélectionnez aléatoirement les données à éliminer de l'ensemble de données (server.db[i].expires) avec un délai d'expiration défini
allkeys-lru : Depuis le ensemble de données (server.db[i].dict) Choisissez les données les moins récemment utilisées pour l'élimination
allkeys-random : Sélectionnez arbitrairement les données de l'ensemble de données (server.db[i].dict) pour l'élimination
no- enviction (expulsion) : Désactiver l'expulsion des données, nouvelles opérations d'écriture Une erreur sera signalée
ps : Si la clé d'expiration n'est pas définie et que les conditions préalables ne sont pas remplies, alors le comportement de volatile-lru, volatile-random et volatile- ; Les stratégies ttl sont fondamentalement les mêmes que la noeviction (non supprimées).
Pourquoi Redis est-il monothread ?
La FAQ officielle indique que, comme Redis est une opération basée sur la mémoire, le processeur n'est pas le goulot d'étranglement de Redis. Le goulot d'étranglement de Redis est probablement la taille de la mémoire de la machine ou du réseau. bande passante. Étant donné que le monothreading est facile à mettre en œuvre et que le CPU ne deviendra pas un goulot d'étranglement, il est logique d'adopter une solution monothread (après tout, l'utilisation du multithreading causera beaucoup de problèmes !) Redis utilise la technologie de file d'attente pour transformer accès simultané à l'accès série
1) Absolument La plupart des requêtes sont des opérations de mémoire pure (très rapides) 2) Monothread, évitant les changements de contexte inutiles et les conditions de concurrence
3) Avantages des E/S non bloquantes :
1. Rapide car les données sont stockées en mémoire, similaire à HashMap, l'avantage de HashMap est que la complexité temporelle de la recherche et de l'opération est O(1)
2. Prend en charge les types de données riches, prend en charge les chaînes, les listes, les ensembles, les ensembles triés, le hachage
3. Prend en charge les transactions, les opérations sont atomiques, ce qu'on appelle l'atomicité signifie que toutes les modifications apportées aux données sont soit exécutées, soit pas exécutées du tout
4. Fonctionnalités riches : peut être utilisé pour la mise en cache, la messagerie et la définition du délai d'expiration par clé. Il sera automatiquement supprimé. après l'expiration. Comment résoudre le problème de la concurrence simultanée des clés dans Redis
Il existe plusieurs sous-systèmes pour définir une clé en même temps. À quoi devons-nous faire attention à ce moment-là ? Il n'est pas recommandé d'utiliser le mécanisme de transaction de Redis. Étant donné que notre environnement de production est essentiellement un environnement de cluster Redis, des opérations de partitionnement de données sont effectuées. Lorsque plusieurs opérations de clé sont impliquées dans une transaction, ces multiples clés ne sont pas nécessairement stockées sur le même serveur Redis. Par conséquent, le mécanisme de transaction de Redis est très inutile.
(1) Si vous opérez sur cette clé, la commande n'est pas obligatoire : Préparez une serrure distribuée, tout le monde saisit la serrure, et effectuez simplement l'opération définie après avoir saisi la serrure
(2) Si vous opérez sur cette clé, la commande est requis : Verrouillage distribué + horodatage. Supposons que le système B saisit le verrou en premier et définit key1 sur {valueB 3:05}. Ensuite, le système A saisit le verrou et constate que l'horodatage de sa propre valeur A est antérieur à l'horodatage dans le cache, il n'effectue donc pas l'opération définie. Et ainsi de suite.
(3) L'utilisation de files d'attente pour transformer la méthode set en accès série peut également aider Redis à rencontrer une concurrence élevée si la cohérence de la lecture et de l'écriture des clés est assurée
Toutes les opérations sur Redis sont atomiques et thread-safe. Pour prendre en compte les problèmes de concurrence, Redis a déjà traité les problèmes de concurrence pour vous en interne.
Que faire avec la solution cluster Redis ? Quels sont les projets ?
1.twemproxy, le concept général est qu'il est similaire à une méthode proxy. Lorsqu'il est utilisé, l'endroit où redis doit être connecté est remplacé par twemproxy. Il recevra la demande en tant que proxy et utilisera un algorithme de hachage cohérent. transférer la requête. Recevez le redis spécifique et renvoyez le résultat à twemproxy.
Inconvénients : en raison de la pression de la propre instance à port unique de twemproxy, après avoir utilisé un hachage cohérent, la valeur calculée change lorsque le nombre de nœuds Redis change et les données ne peuvent pas être automatiquement déplacées vers le nouveau nœud.
2.codis, la solution de cluster la plus couramment utilisée à l'heure actuelle, a fondamentalement le même effet que twemproxy, mais elle prend en charge la récupération des anciennes données de nœuds vers de nouveaux nœuds de hachage lorsque le nombre de nœuds change
3.redis est livré avec cluster3 .0 La caractéristique du cluster est que son algorithme distribué n'est pas un hachage cohérent, mais le concept d'emplacement de hachage, et il prend en charge la configuration des nœuds esclaves. Consultez la documentation officielle pour plus de détails.
Avez-vous essayé de déployer Redis sur plusieurs machines ? Comment assurer la cohérence des données ?
Réplication maître-esclave, séparation de la lecture et de l'écriture
L'une est la base de données maître (maître) et l'autre est la base de données esclave (esclave). La base de données maître peut effectuer des opérations de lecture et d'écriture. Lorsqu'une opération d'écriture se produit, les données. est automatiquement synchronisée avec la base de données esclave. La base de données esclave est généralement en lecture seule et reçoit les données synchronisées de la base de données maître. Une base de données maître peut avoir plusieurs bases de données esclave, tandis qu'une base de données esclave ne peut avoir qu'une seule base de données maître.
Comment traiter un grand nombre de requêtes
redis est un programme monothread, ce qui signifie qu'il ne peut gérer qu'une seule requête client à la fois
redis utilise le multiplexage IO (select, epoll, kqueue, selon ; la situation) plates-formes, adoptant différentes implémentations) pour gérer plusieurs demandes de clients
Redis problèmes de performances courants et solutions ?
(1) Il est préférable que le maître n'effectue aucun travail de persistance, tel que les instantanés de mémoire RDB et les fichiers journaux AOF
(2) Si les données sont importantes, un esclave active les données de sauvegarde AOF et la politique est définie pour se synchroniser une fois par seconde
(3) Pour la vitesse de réplication maître-esclave et la stabilité de la connexion, il est préférable que le maître et l'esclave soient dans le même LAN
(4) Essayez d'éviter d'ajouter des bibliothèques esclaves à la bibliothèque maître qui se trouve sous grande pression
(5) N'utilisez pas d'images pour la structure de réplication maître-esclave, il est plus stable d'utiliser une structure de liste chaînée unidirectionnelle, c'est-à-dire : Maître Esclave3.. .
Expliquez le modèle de thread Redis
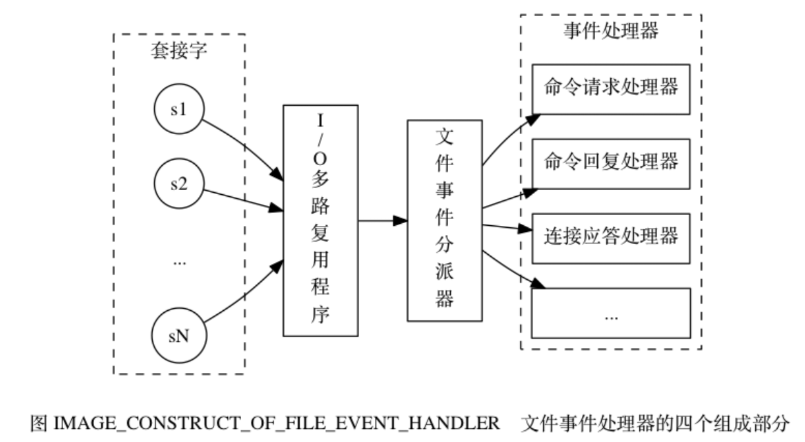
Le processeur d'événements de fichier comprend socket, un multiplexeur d'E/S, un répartiteur d'événements de fichier (répartiteur) et un gestionnaire d'événements . Utilisez un multiplexeur d'E/S pour écouter plusieurs sockets en même temps et associer différents gestionnaires d'événements aux sockets en fonction de la tâche qu'ils effectuent actuellement. Lorsque le socket surveillé est prêt à effectuer des opérations telles que la réponse de connexion (accepter), la lecture (lecture), l'écriture (écriture), la fermeture (fermeture), etc., l'événement de fichier correspondant à l'opération sera généré à ce moment-là. le fichier Le gestionnaire d'événements appellera le gestionnaire d'événements précédemment associé au socket pour gérer ces événements.
Le multiplexeur d'E/S est chargé d'écouter plusieurs sockets et de transmettre les sockets qui ont généré des événements au répartiteur d'événements de fichier.
Principe de fonctionnement :
1) Le multiplexeur d'E/S est chargé d'écouter plusieurs sockets et de transmettre les sockets qui ont généré des événements au répartiteur d'événements de fichier.
Bien que plusieurs événements de fichier puissent se produire simultanément, le multiplexeur d'E/S mettra toujours en file d'attente toutes les sockets génératrices d'événements dans une file d'attente, puis passera par cette file d'attente dans l'ordre (séquentiellement), de manière synchrone, en transmettant les sockets au répartiteur d'événements de fichier. à la fois : après le traitement de l'événement généré par le socket précédent (le socket est le gestionnaire d'événements associé à l'événement. Le multiplexeur d'E/S continuera à transmettre le socket suivant au répartiteur d'événements de fichier jusqu'à ce que le multiplexeur d'E/S ait terminé en cours d'exécution). Si un socket est à la fois lisible et inscriptible, alors le serveur lira d'abord le socket, puis l'écrira.
Pourquoi les opérations Redis sont-elles atomiques et comment garantir l'atomicité ?
Pour Redis, l'atomicité d'une commande signifie qu'une opération ne peut pas être subdivisée, et que l'opération est exécutée ou non.
La raison pour laquelle les opérations Redis sont atomiques est que Redis est monothread.
Toutes les API fournies par Redis lui-même sont des opérations atomiques. Les transactions dans Redis garantissent en fait l'atomicité des opérations par lots.
Plusieurs commandes sont-elles atomiques en simultanéité ?
Pas nécessairement, remplacez get et set par des opérations de commande unique, incr. Utilisez les transactions Redis ou utilisez Redis+Lua== pour implémenter.
Redis transaction
La fonction de transaction Redis est implémentée via les quatre primitives MULTI, EXEC, DISCARD et WATCH
Redis sérialisera toutes les commandes d'une transaction, puis appuiera sur Exécuté séquentiellement.
1.redis ne prend pas en charge le rollback "Redis n'annule pas lorsqu'une transaction échoue, mais continue d'exécuter les commandes restantes", afin que les composants internes de Redis puissent rester simples et rapides.
2. Si une erreur se produit dans la commande dans une transaction, alors toutes les commandes ne seront pas exécutées ; transaction Si une
erreur d'exécution se produit dans la transaction, alors la commande correcte sera exécutée. Remarque : la suppression de Redis ne fait que mettre fin à cette transaction, et l'impact de la commande correcte existe toujours
2) EXEC : Exécute des commandes dans tous les blocs de transactions. Renvoie les valeurs de retour de toutes les commandes du bloc de transaction, classées dans l'ordre d'exécution des commandes. Lorsque l'opération est interrompue, la valeur vide nil est renvoyée.
3) En appelant DISCARD, le client peut vider la file d'attente des transactions et renoncer à l'exécution de la transaction, et le client quittera le statut de la transaction.
4) La commande WATCH peut fournir un comportement de vérification et de définition (CAS) pour les transactions Redis. Une ou plusieurs clés peuvent être surveillées. Une fois l'une des clés modifiée (ou supprimée), les transactions suivantes ne seront pas exécutées et la surveillance se poursuit jusqu'à la commande EXEC.
Définissez la valeur de la clé sur value si et seulement si la clé n'existe pas. Si la clé donnée existe déjà, SETNX n'effectue aucune action
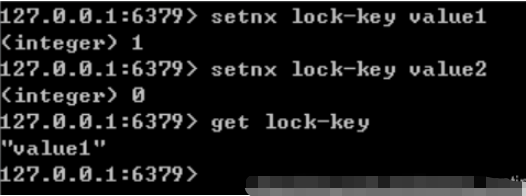
Résoudre l'impasse : #🎜 🎜# 1) Définissez le temps de maintien maximum du verrou via expire() dans Redis. S'il dépasse, Redis nous aidera à libérer le verrou.
2) Ceci peut être réalisé en utilisant la combinaison de commandes de la touche setnx "heure actuelle du système + temps de maintien du verrouillage" et de la touche getset "heure actuelle du système + temps de maintien du verrouillage".
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!