
Maison >base de données >Redis >Analyse des instances de cluster Redis
Analyse des instances de cluster Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-04 08:21:011844parcourir
1. Pourquoi les K8
1. Isolement des ressources
Redis actuel Le cluster est déployé sur un cluster de machines physiques afin d'améliorer l'utilisation des ressources et de réduire les coûts, les clusters Redis de plusieurs secteurs d'activité sont mélangés. Comme il n'y a pas d'isolation des ressources CPU, il arrive souvent que l'utilisation du CPU d'un nœud Redis soit trop élevée, ce qui amène d'autres nœuds du cluster Redis à entrer en concurrence pour les ressources CPU, provoquant une instabilité de retard. Étant donné que différents clusters sont mélangés, ce type de problème est difficile à localiser rapidement et affecte l'efficacité du fonctionnement et de la maintenance. Le déploiement conteneurisé de K8 peut spécifier la demande de CPU et la limite de CPU, ce qui améliore l'utilisation des ressources tout en évitant les conflits de ressources.
2. Déploiement automatisé
Le processus de déploiement actuel de Redis Cluster sur des machines physiques est très lourd et vous devez vérifier la méta- base de données d'informations pour trouver les ressources disponibles de la machine, modifier manuellement de nombreux fichiers de configuration et déployer les nœuds un par un, et enfin utiliser l'outil redis_trib pour créer un cluster. L'initialisation d'un nouveau cluster prend souvent une heure ou deux.
K8s déploie des clusters Redis via StatefulSet et utilise configmap pour gérer les fichiers de configuration. Le déploiement d'un nouveau cluster ne prend que quelques minutes, ce qui améliore considérablement l'efficacité de l'exploitation et de la maintenance.
2. Comment K8s
Le client dispose d'un accès unifié via le VIP de LVS et transmet les demandes de service au cluster Redis Cluster via Redis Proxy . Nous présentons ici Redis Proxy pour transférer les demandes.
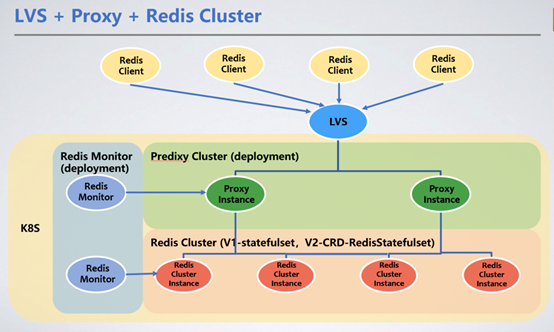
1 Méthode de déploiement du cluster Redis
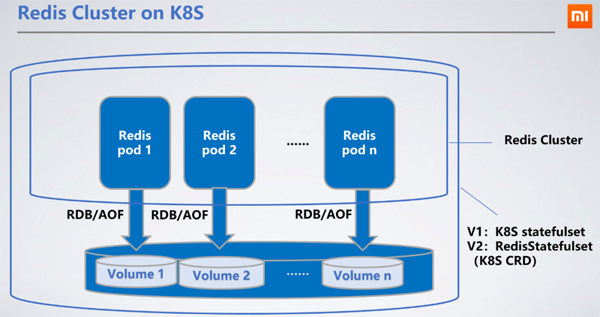
Redis est déployé en tant que StatefulSet, comme a stateful Pour les services, il est plus raisonnable de choisir StatefulSet, qui peut conserver le RDB/AOF du nœud dans le stockage distribué. Lorsque le nœud redémarre et dérive vers d'autres machines, le RDB/AOF d'origine peut être obtenu via le PVC monté (PersistentVolumeClaim) pour synchroniser les données.
Le service de bloc Ceph est le PV de stockage persistant (PersistentVolume) que nous avons choisi. Les performances de lecture et d'écriture de Ceph sont pires que celles des disques durs locaux, ce qui augmentera les délais de lecture et d'écriture de 100 à 200 millisecondes. La latence de lecture et d'écriture du stockage distribué n'affecte pas le service car l'écriture RDB/AOF de Redis est asynchrone.
2. Sélection du proxy
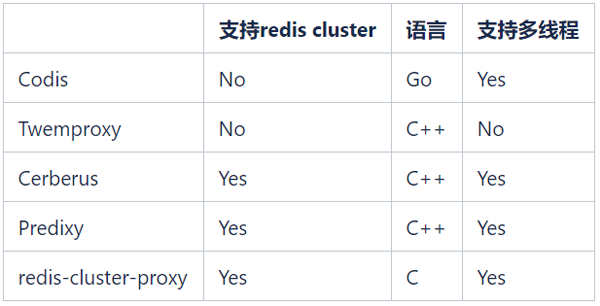
Il existe de nombreux proxy Redis open source, courants Le Proxy Redis open source est le suivant :
Nous espérons continuer à utiliser Redis Cluster pour gérer le cluster Redis, donc Codis et Twemproxy ne sont plus pris en compte. redis-cluster-proxy est un proxy officiellement lancé par Redis en version 6.0 qui prend en charge le protocole Redis Cluster. Cependant, il n'existe actuellement aucune version stable et il ne peut pas être appliqué à grande échelle pour le moment.
Les seules options sont Cerberus et Predixy. Voici les résultats des tests de performances de Cerberus et Predixy que nous avons effectués dans l'environnement K8 :
Environnement de test
Outil de test : redis-benchmark # 🎜🎜#
CPU proxy : 2 cœursCPU client : 2 cœursCluster Redis : 3 nœuds maîtres, 1 CPU par nœud# 🎜 🎜#
Résultats des tests
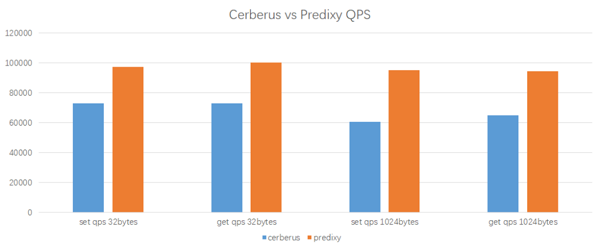 Predixy sur la même charge de travail et la configuration, un QPS plus élevé peut être obtenu, et sa latence est également assez proche de celle de Cerberus. Dans l'ensemble, les performances de Predixy sont 33 % à 60 % supérieures à celles de Cerberus, et plus la clé/valeur des données est grande, plus l'avantage de Predixy est évident, nous avons donc finalement choisi Predixy.
Predixy sur la même charge de travail et la configuration, un QPS plus élevé peut être obtenu, et sa latence est également assez proche de celle de Cerberus. Dans l'ensemble, les performances de Predixy sont 33 % à 60 % supérieures à celles de Cerberus, et plus la clé/valeur des données est grande, plus l'avantage de Predixy est évident, nous avons donc finalement choisi Predixy.
Afin de nous adapter à l'environnement business et K8, nous avons apporté de nombreuses modifications à Predixy avant de le mettre en ligne et ajouté de nombreuses nouvelles fonctionnalités, telles que la commutation dynamique du cluster Redis back-end, en noir et blanc listes, audit de fonctionnement anormal, etc.
3. Méthode de déploiement du proxyEn raison de ses caractéristiques de déploiement sans état et légères, le proxy (Proxy) est utilisé comme méthode de déploiement, via l'équilibrage de charge (LB) fournit des services qui peuvent facilement réaliser une expansion et une contraction dynamiques. Dans le même temps, nous avons développé la fonction de commutation dynamique du cluster Redis back-end pour proxy, qui peut ajouter et basculer le cluster Redis en ligne.
4. Méthode d'expansion et de contraction automatique du proxyNous utilisons le HPA (Horizontal Pod Autoscaler) natif de K8 pour obtenir une expansion et une contraction dynamiques du proxy. Permettre. Lorsque l'utilisation moyenne du processeur de tous les pods proxy dépasse un certain seuil, l'expansion sera automatiquement déclenchée. HPA augmentera le numéro de réplique du proxy de 1. Après cela, LVS détectera le nouveau pod proxy et coupera une partie du trafic. Lorsque l'utilisation du processeur dépasse le seuil spécifié, la capacité sera étendue. Si l'utilisation du processeur ne répond toujours pas aux exigences, la logique d'extension continuera à être déclenchée. Cependant, dans les 5 minutes suivant une expansion réussie, quelle que soit la baisse de l'utilisation du processeur, la logique de réduction ne sera pas déclenchée, évitant ainsi l'impact d'une expansion et d'une réduction fréquentes sur la stabilité du cluster.
HPA peut configurer le nombre minimum (MINPODS) et maximum (MAXPODS) de pods dans le cluster, quelle que soit la faible charge du cluster, elle ne sera pas réduite au nombre de pods inférieurs à MINPODS. . Il est recommandé aux clients de juger de leurs conditions commerciales réelles pour déterminer les valeurs de MINPODS et MAXPODS.
3. Pourquoi le redémarrage du proxyLes clients Redis qui utilisent Redis Cluster doivent configurer certaines adresses IP et ports du cluster pour trouver l'entrée de Redis Cluster lorsque le client redémarre. Pour les nœuds Redis déployés dans des clusters de machines physiques, même si l'instance ou la machine est redémarrée, l'adresse IP et le port peuvent rester inchangés et le client peut toujours trouver la topologie du cluster Redis. Cependant, pour le cluster Redis déployé sur les K8, il n'est pas garanti que l'adresse IP reste inchangée au redémarrage du pod (même s'il est redémarré sur le nœud K8 d'origine), donc lorsque le client redémarre, il se peut qu'il ne puisse pas trouver l'adresse IP. entrée du cluster Redis.
En ajoutant un proxy entre le client et le cluster Redis, les informations du cluster Redis sont protégées du client. Le proxy peut détecter dynamiquement les changements de topologie du cluster Redis. Le client n'a besoin que d'utiliser l'adresse IP : port de LVS comme entrée. pointer vers la demande En le transmettant au proxy, vous pouvez utiliser le cluster Redis tout comme vous utilisez la version autonome de Redis, sans avoir besoin d'un client intelligent Redis.
2. Redis gère une charge de connexion élevée
Avant la version 6.0, Redis traitait la plupart des tâches dans un seul thread. Lorsque les connexions aux nœuds Redis sont élevées, Redis doit consommer beaucoup de ressources CPU pour traiter ces connexions, ce qui entraîne une latence accrue. Avec le proxy, un grand nombre de connexions se trouvent sur le proxy, et seules quelques connexions sont maintenues entre le proxy et l'instance Redis, ce qui réduit la charge sur Redis et évite l'augmentation de la latence Redis provoquée par l'augmentation des connexions.
3. La migration et le changement de cluster nécessitent le redémarrage de l'application
Pendant l'utilisation, à mesure que l'activité se développe, le volume de données du cluster Redis continuera d'augmenter. Lorsque le volume de données de chaque nœud est trop élevé, le temps BGSAVE augmentera. être considérablement augmentée, réduisant ainsi la disponibilité du cluster. Dans le même temps, l’augmentation du QPS entraînera également une augmentation de l’utilisation du processeur de chaque nœud. Ce problème doit être résolu en ajoutant un cluster d'extension. À l'heure actuelle, l'évolutivité horizontale de Redis Cluster n'est pas très bonne et la solution de migration des slots natifs est très inefficace. Après avoir ajouté un nouveau nœud, certains clients tels que Lettuce ne pourront pas reconnaître le nouveau nœud en raison du mécanisme de sécurité. De plus, le temps de migration est totalement imprévisible et il n'y a aucun moyen de revenir en arrière en cas de problèmes pendant le processus de migration.
Le plan d'expansion actuel pour les clusters de machines physiques est le suivant :
Créer de nouveaux clusters à la demande ;
Utiliser des outils de synchronisation pour synchroniser les données de l'ancien cluster vers le nouveau cluster ;
Après avoir confirmé que les données sont enregistrées. est correct, communiquez avec l'entreprise, redémarrez le service et passez au nouveau cluster.
L'ensemble du processus est lourd et risqué, et l'entreprise doit être redémarrée.
Avec la couche Proxy, la création, la synchronisation et la commutation de clusters sur le backend peuvent être protégées du client. Une fois la synchronisation des nouveaux et anciens clusters terminée, vous pouvez envoyer une commande au proxy pour basculer la connexion vers le nouveau cluster, ce qui peut réaliser une expansion et une contraction du cluster sans aucune connaissance du client.
4. Risques pour la sécurité des données
Redis met en œuvre des opérations d'authentification via AUTH Le client est directement connecté à Redis et le mot de passe doit toujours être enregistré sur le client. En utilisant un proxy, le client n'a besoin d'accéder à Redis que via le mot de passe du proxy et n'a pas besoin de connaître le mot de passe Redis. Le proxy restreint également les opérations telles que FLUSHDB et CONFIG SET, empêchant les clients d'effacer par erreur des données ou de modifier la configuration Redis, ce qui améliore considérablement la sécurité du système.
En même temps, Redis ne fournit pas de fonctions d'audit. Nous avons ajouté une fonction de journalisation pour les opérations à haut risque sur le serveur proxy, offrant des capacités d'audit sans affecter les performances globales.
4. Problèmes causés par le proxy
1. Le délai causé par un saut supplémentaire
Proxy se situe entre le client et l'instance Redis. Lorsque le client accède aux données Redis, il doit d'abord accéder au proxy. puis accédez à Redis, un saut supplémentaire entraînera une augmentation du délai. Selon les résultats des tests, l'ajout d'un saut augmentera le délai de 0,2 à 0,3 ms, mais cela est généralement acceptable pour les entreprises.
2. La dérive des pods provoque des changements d'IP
Sur les K8, le proxy est implémenté via le déploiement, il y a donc aussi le problème des changements d'IP provoqués par les redémarrages des nœuds. Notre solution K8s LB peut détecter les changements IP du proxy et basculer dynamiquement le trafic LVS vers le proxy redémarré.
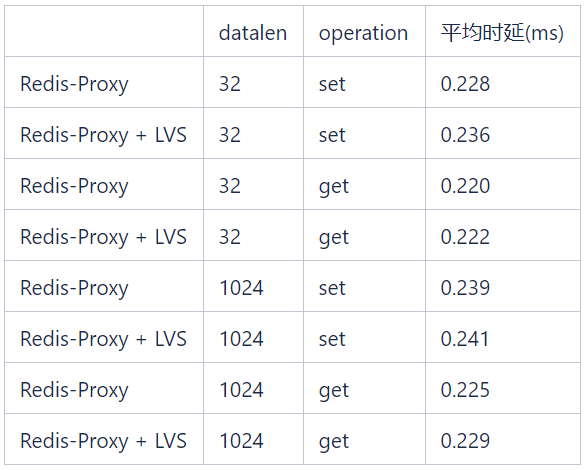
3. Latence causée par LVS
Dans les tests présentés dans le tableau ci-dessous, la latence LVS introduite par les opérations get/set de différentes longueurs de données est inférieure à 0,1 ms.
5. Avantages apportés par les K8
1. Déploiement facile
L'API K8s est appelée via la plateforme d'exploitation et de maintenance pour déployer le cluster, ce qui améliore considérablement l'efficacité de l'exploitation et de la maintenance.
2. Résoudre le problème de gestion des ports
Actuellement, le déploiement par Xiaomi des instances Redis sur les machines physiques se distingue par des ports, et les ports hors ligne ne peuvent pas être réutilisés, ce qui signifie que chaque instance Redis dans l'ensemble de l'entreprise possède un numéro de port unique. . Actuellement, plus de 40 000 des 65 535 ports sont utilisés. Selon le rythme actuel de développement des affaires, les ressources portuaires seront épuisées d'ici deux ans. Grâce au déploiement K8s, le pod K8s correspondant à chaque instance Redis dispose d'une adresse IP indépendante, et il n'y a aucun problème d'épuisement des ports ni de problèmes de gestion complexes.
3. Seuil d'utilisation client inférieur
Pour les applications, il suffit d'utiliser un client autonome non intelligent pour se connecter à VIP, ce qui abaisse le seuil d'utilisation et évite un paramétrage fastidieux et complexe. Les applications n'ont pas besoin de gérer elles-mêmes la topologie du cluster Redis, car les VIP et les ports sont fixes de manière statique.
4. Améliorer les performances du client
L'utilisation de clients non intelligents peut également réduire la charge du client, car les clients intelligents doivent être activés le client hache la clé pour déterminer à quel nœud Redis envoyer la requête, ce qui consommera les ressources CPU de la machine client lorsque le QPS est relativement élevé. Bien entendu, afin de faciliter la migration des applications clientes, nous avons également fait en sorte que Proxy prenne en charge le protocole client intelligent.
5. Mise à niveau dynamique et extension de capacité
Proxy prend en charge la fonction d'ajout et de commutation dynamique du cluster Redis, afin que le cluster Redis puisse être mis à niveau et étendu. Le processus de changement peut ignorer complètement l'aspect commercial. Par exemple, le côté commercial utilise un cluster Redis de 30 nœuds. En raison de l'augmentation du volume d'affaires, le volume de données et le QPS ont augmenté rapidement et la taille du cluster doit être doublée. Si la capacité est étendue sur la machine physique d'origine, le processus suivant est requis :
-
Coordonner les ressources et déployer un nouveau cluster de 60 nœuds ; 🎜##🎜🎜 #
Configurez manuellement l'outil de migration pour migrer les données du cluster actuel vers le nouveau cluster - Après avoir vérifié que les données sont correct, informez l'entreprise de modifier la topologie du pool de connexions du cluster Redis, redémarrez le service.
- Bien que Redis Cluster prenne en charge l'expansion en ligne, la migration des emplacements pendant le processus d'expansion affectera les activités en ligne et le temps de migration est incontrôlable, ce qui est donc rarement utilisé à ce stade. Cette méthode n’est utilisée qu’occasionnellement lorsque les ressources sont gravement insuffisantes.
Créez également un outil de synchronisation de cluster en un clic via l'interface API pour migrer les données vers un nouveau cluster
#🎜🎜 #- Vérifier les données Une fois que tout est correct, envoyez une commande au proxy pour ajouter de nouvelles informations sur le cluster et terminer le changement.
- L'ensemble du processus ignore complètement la fin commerciale. La mise à niveau du cluster est également très pratique : si l'entreprise peut accepter un certain problème de retard, elle peut être mise en œuvre via la mise à niveau continue de StatefulSet pendant les heures creuses si l'entreprise a des exigences de retard, elle peut le faire ; être atteint en créant un nouveau cluster. Mis en œuvre par la migration des données.
6. Améliorez la stabilité du service et l'utilisation des ressources
Utilisez la propre fonction d'isolation des ressources de K8 pour permettre le déploiement hybride de différents types d'applications. Cela améliore non seulement l'utilisation des ressources, mais garantit également la stabilité du service.6. Problèmes rencontrés
1. 🎜#
Lorsqu'un pod K8s rencontre un problème et redémarre, car la vitesse de redémarrage est trop rapide, le pod sera redémarré avant que le cluster Redis Cluster ne soit découvert et basculé vers le maître. Si Redis sur le pod est un esclave, cela n'aura aucun impact. Mais si Redis est le maître et qu'il n'y a pas d'AOF, toutes les données de la mémoire d'origine seront effacées après le redémarrage, Redis rechargera le fichier RDB précédemment stocké, mais le fichier RDB n'est pas une donnée en temps réel. Plus tard, l'esclave synchronisera également ses propres données avec le miroir de données du fichier RDB précédent, ce qui entraînera une perte de données.
Délai de mappage LVS
Le pod du proxy est équilibré via LVS, et le mappage LVS de l'IP:Port back-end prend effet après un certain temps. Après un certain délai, le nœud proxy se déconnecte soudainement, ce qui entraînera la perte de certaines connexions. Afin de minimiser l'impact de l'exploitation et de la maintenance du proxy sur l'entreprise, nous avons ajouté les options suivantes au modèle de déploiement du proxy :lifecycle: preStop: exec: command: - sleep - "171"Pour le pod proxy normal hors ligne, comme la réduction du cluster, la mise à jour continue de Version proxy Et les autres pods contrôlables par K8 se déconnectent. Avant que le pod ne se déconnecte, il enverra un message à LVS et attendra 171 secondes. Ce temps est suffisant pour que LVS bascule progressivement le trafic de ce pod vers d'autres pods sans aucune connaissance. de l'entreprise.
2. StatefulSet de K8 ne peut pas répondre aux exigences de déploiement du cluster Redis
Le StatefulSet natif de K8 ne peut pas répondre entièrement aux exigences de déploiement du cluster Redis : #🎜🎜 #Dans Redis Cluster, les nœuds ayant une relation maître-esclave ne peuvent pas être déployés sur la même machine. C'est facile à comprendre. Si la machine tombe en panne, le fragment de données deviendra indisponible.
2) Redis Cluster ne permet pas l'échec de plus de la moitié des nœuds maîtres du cluster, car si plus de la moitié des nœuds maîtres échouent, il n'y aura pas suffisamment de votes de nœuds pour répondre aux exigences du protocole des potins. Étant donné que le maître et la sauvegarde du cluster Redis peuvent être commutés à tout moment, nous ne pouvons pas éviter la situation dans laquelle tous les nœuds de la même machine sont des nœuds maîtres. Ainsi, lors du déploiement, nous ne pouvons pas autoriser plus d'un quart des nœuds du cluster à être déployé sur la même machine. Afin de répondre aux exigences ci-dessus, le StatefulSet natif peut utiliser la fonction anti-affinité pour garantir que le même cluster ne déploie qu'un seul nœud sur la même machine, mais l'utilisation de cette machine est très faible. Nous avons donc développé un CRD basé sur StatefulSet : RedisStatefulSet, qui utilisera diverses stratégies pour déployer les nœuds Redis. Ajout de certaines fonctionnalités pour gérer Redis dans RedisStatefulSet. Nous continuerons à en discuter en détail dans d’autres articles. 7. Résumé Des dizaines de clusters Redis ont été déployés et exécutés sur des K8 depuis plus de six mois, et ces clusters impliquent plusieurs entreprises au sein du groupe. Grâce aux capacités de déploiement rapide et de migration des pannes des K8, la charge de travail d'exploitation et de maintenance de ces clusters est bien inférieure à celle des clusters Redis sur les machines physiques, et leur stabilité a été entièrement vérifiée. Nous avons également rencontré de nombreux problèmes lors du processus d'exploitation et de maintenance. De nombreuses fonctions mentionnées dans l'article ont été affinées en fonction des besoins réels. Dans le processus suivant, de nombreux problèmes doivent encore être progressivement résolus pour améliorer l'efficacité de l'utilisation des ressources et la qualité du service. 1. Déploiement mixte vs déploiement indépendant Les instances Redis de la machine physique sont déployées indépendamment Toutes les instances Redis sont déployées sur une seule machine physique, ce qui est bénéfique pour la gestion, mais le taux d'utilisation des ressources n'est pas élevé. . Les instances Redis utilisent le processeur, la mémoire et les E/S réseau, mais l'espace de stockage est fondamentalement gaspillé. Lorsqu'une instance Redis est déployée sur K8, tout autre type de service peut être déployé sur la machine sur laquelle elle se trouve, bien que cela puisse améliorer l'utilisation de la machine, pour des services comme Redis qui ont des exigences de haute disponibilité et de latence, s'ils sont expulsés. parce que la machine manque de mémoire est inacceptable. Cela nécessite que le personnel d'exploitation et de maintenance surveille la mémoire de toutes les machines sur lesquelles les instances Redis sont déployées. Une fois la mémoire insuffisante, ils couperont les nœuds maîtres et migreront, mais cela augmentera la charge de travail d'exploitation et de maintenance. S'il existe d'autres applications à haut débit réseau dans le déploiement hybride, cela peut également avoir un impact négatif sur le service Redis. Bien que la fonction anti-affinité des K8 puisse déployer de manière sélective des instances Redis sur des machines qui ne disposent pas de telles applications, cette situation ne peut être évitée lorsque les ressources de la machine sont limitées. 2. Gestion du cluster Redis Redis Cluster est une architecture de cluster P2P sans nœud central. Il s'appuie sur le protocole Gossip pour se propager et se coordonner afin de réparer automatiquement l'état du nœud en ligne et hors ligne et les problèmes de réseau peuvent survenir. certains états de nœud du cluster Redis apparaissent, tels que des nœuds en état d'échec ou de prise de contact dans la topologie du cluster, ou même un cerveau divisé. Pour cet état anormal, nous pouvons ajouter plus de fonctions à Redis CRD pour le résoudre progressivement et améliorer encore l'efficacité de l'exploitation et de la maintenance. 3. Audit et sécurité Redis fournit uniquement une fonction de protection par authentification par mot de passe Auth et manque de gestion des autorisations, la sécurité est donc relativement faible. Grâce au proxy, nous pouvons distinguer les types de clients grâce aux mots de passe. Les administrateurs et les utilisateurs ordinaires utilisent des mots de passe différents pour se connecter, et les autorisations d'opération exécutables sont également différentes, de sorte que des fonctions telles que la gestion des autorisations et l'audit des opérations peuvent être réalisées. 4. Prend en charge plusieurs clusters Redis En raison des limitations du protocole Gossip, un seul cluster Redis a des capacités d'expansion horizontale limitées. Lorsque la taille du cluster est de 300 nœuds, l'efficacité des changements de topologie tels que la sélection du maître de nœud est. considérablement réduit. Dans le même temps, étant donné que la capacité d’une seule instance Redis ne doit pas être trop élevée, il est difficile pour un seul cluster Redis de prendre en charge une échelle de données supérieure à la To. Grâce au proxy, nous pouvons logiquement partager des clés, de sorte qu'un seul proxy puisse être connecté à plusieurs clusters Redis. Du point de vue du client, cela équivaut à se connecter à un cluster Redis pouvant prendre en charge une plus grande échelle de données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!