
Maison >base de données >Redis >Comment déterminer si Redis a des problèmes de performances et comment les résoudre
Comment déterminer si Redis a des problèmes de performances et comment les résoudre

- PHPzavant
- 2023-06-03 17:16:21885parcourir

Redis est généralement un élément important de notre système commercial, tel que le cache, les informations de connexion au compte, les classements, etc.
Une fois le délai de requête Redis augmenté, cela peut provoquer une "avalanche" du système métier.
Je travaille pour une seule société Internet de type entremetteur. Durant Double Eleven, j'ai lancé une campagne pour offrir un cadeau à ma copine lorsque je passe une commande.
Qui aurait pensé qu'après 12 heures du matin, le nombre d'utilisateurs augmentait fortement, et qu'il y avait un problème technique qui empêchait les utilisateurs de passer des commandes. A ce moment-là, le vieil incendie s'est déclaré !
Après la recherche, j'ai découvert que Redis signalait Impossible d'obtenir une ressource du pool. Could not get a resource from the pool。
获取不到连接资源,并且集群中的单台 Redis 连接量很高。
大量的流量没了 Redis 的缓存响应,直接打到了 MySQL,最后数据库也宕机了……
于是各种更改最大连接数、连接等待数,虽然报错信息频率有所缓解,但还是持续报错。
后来经过线下测试,发现存放 Redis 中的字符数据很大,平均 1s 返回数据。
可以发现,一旦 Redis 延迟过高,会引发各种问题。
今天跟大家一起来分析下如何确定 Redis 有性能问题和解决方案。
Redis 性能出问题了么?
最大延迟是客户端发出命令到客户端收到命令的响应的时间,正常情况下 Redis 处理的时间极短,在微秒级别。
当 Redis 出现性能波动的时候,比如达到几秒到十几秒,这个很明显我们可以认定 Redis 性能变慢了。
有的硬件配置比较高,当延迟 0.6ms,我们可能就认定变慢了。硬件比较差的可能 3 ms 我们才认为出现问题。
那我们该如何定义 Redis 真的变慢了呢?
所以,我们需要对当前环境的 Redis 基线性能做测量,也就是在一个系统在低压力、无干扰情况下的基本性能。
当你发现 Redis 运行时时的延迟是基线性能的 2 倍以上,就可以判定 Redis 性能变慢了。
延迟基线测量
redis-cli 命令提供了–intrinsic-latency 选项,用来监测和统计测试期间内的最大延迟(以毫秒为单位),这个延迟可以作为 Redis 的基线性能。
redis-cli --latency -h `host` -p `port`
比如执行如下指令:
redis-cli --intrinsic-latency 100 Max latency so far: 4 microseconds. Max latency so far: 18 microseconds. Max latency so far: 41 microseconds. Max latency so far: 57 microseconds. Max latency so far: 78 microseconds. Max latency so far: 170 microseconds. Max latency so far: 342 microseconds. Max latency so far: 3079 microseconds. 45026981 total runs (avg latency: 2.2209 microseconds / 2220.89 nanoseconds per run). Worst run took 1386x longer than the average latency.
注意:参数100是测试将执行的秒数。我们运行测试的时间越长,我们就越有可能发现延迟峰值。
通常运行 100 秒通常是合适的,足以发现延迟问题了,当然我们可以选择不同时间运行几次,避免误差。
运行的最大延迟是 3079 微秒,所以基线性能是 3079 (3 毫秒)微秒。
需要注意的是,我们要在 Redis 的服务端运行,而不是客户端。这样,可以避免网络对基线性能的影响。
可以通过 -h host -p port
On constate qu'une fois le délai Redis trop élevé, divers problèmes surviendront. Aujourd'hui, analysons comment déterminer si Redis a des problèmes de performances et des solutions. Y a-t-il un problème avec les performances de Redis ?Plus tard, après des tests hors ligne, nous avons constaté que les données de caractères stockées dans Redis sont très volumineuses et qu'il faut en moyenne 1 seconde pour renvoyer les données.
Lorsque les performances de Redis fluctuent, par exemple, elles atteignent quelques secondes à plus de dix secondes, il est évident que l'on peut conclure que les performances de Redis ont ralenti. Certaines configurations matérielles sont relativement élevées Lorsque le délai est de 0,6 ms, on peut le considérer comme lent. Si le matériel est médiocre, cela peut prendre 3 ms avant que nous pensions qu'il y a un problème.Le délai maximum est le temps écoulé entre le client émettant une commande et le client recevant la réponse à la commande. Dans des circonstances normales, le temps de traitement de Redis est extrêmement court, de l'ordre de la microseconde.
Alors, comment définir si Redis est vraiment lent ?
- Nous devons donc mesurer les performances de base Redis de l'environnement actuel, qui sont les performances de base d'un système sous basse pression et sans interférence. Lorsque vous constatez que la latence du runtime Redis est plus de 2 fois supérieure aux performances de base, vous pouvez déterminer que les performances de Redis ralentissent.
Mesure de base de la latence
La commande redis-cli fournit l'option –intrinsic-latency pour surveiller et compter la latence maximale (en millisecondes) pendant la période de test. Cette latence peut être utilisée comme performance de base de Redis.
redis-cli CONFIG SET slowlog-log-slower-than 6000Par exemple, exécutez la commande suivante :
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 6
2) (integer) 1458734263
3) (integer) 74372
4) 1) "hgetall"
2) "max.dsp.blacklist"
2) 1) (integer) 5
2) (integer) 1458734258
3) (integer) 5411075
4) 1) "keys"
2) "max.dsp.blacklist"
Remarque : le paramètre 100 est le nombre de secondes pendant lesquelles le test sera exécuté. Plus nous exécutons le test longtemps, plus nous avons de chances de trouver des pics de latence.
Habituellement, une exécution de 100 secondes est généralement appropriée, ce qui est suffisant pour détecter les problèmes de latence. Bien entendu, nous pouvons choisir d'exécuter plusieurs fois à des moments différents pour éviter les erreurs.
La latence maximale en cours d'exécution est de 3079 microsecondes, donc les performances de base sont de 3079 (3 millisecondes) microsecondes. Il convient de noter que nous devons exécuter sur le serveur Redis, pas sur le client. De cette façon, l’impact du réseau sur les performances de base peut être évité. 🎜🎜Vous pouvez vous connecter au serveur via -h host -p port Si vous souhaitez surveiller l'impact du réseau sur les performances de Redis, vous pouvez utiliser Iperf pour mesurer le délai réseau entre le client et le client. le serveur. 🎜🎜Si le retard du réseau atteint plusieurs centaines de millisecondes, cela peut indiquer que d'autres programmes à fort trafic sont en cours d'exécution, provoquant une congestion du réseau. Vous devez contacter le personnel d'exploitation et de maintenance pour coordonner la répartition du trafic réseau. 🎜🎜Surveillance des commandes lentes🎜🎜🎜Comment juger s'il s'agit d'une commande lente ? 🎜🎜🎜Vérifiez si la complexité de l'opération est O(N). La documentation officielle présente la complexité de chaque commande. Utilisez autant que possible les commandes O(1) et O(log N). 🎜🎜La complexité impliquée dans les opérations d'ensemble est généralement O(N), comme la requête d'ensemble complet HGETALL, SMEMBERS et les opérations d'agrégation d'ensembles : SORT, LREM, SUNION, etc. 🎜🎜🎜Y a-t-il des données de surveillance qui peuvent être observées ? Je n'ai pas écrit le code. Je ne sais pas si quelqu'un a utilisé des instructions lentes. 🎜🎜🎜Il existe deux façons de dépanner : 🎜🎜🎜🎜Utilisez la fonction de journal lent de Redis pour détecter les commandes lentes ; 🎜🎜🎜🎜outil latency-monitor (surveillance de la latence). 🎜🎜🎜🎜De plus, vous pouvez vérifier rapidement la consommation CPU du processus principal Redis en utilisant vous-même (top, htop, prstat, etc.). Si l'utilisation du processeur est élevée mais que le trafic est faible, cela indique généralement que des commandes lentes sont utilisées. 🎜🎜🎜Fonction de journal lent🎜🎜🎜La commande slowlog dans Redis nous permet de localiser rapidement les commandes lentes qui dépassent le temps d'exécution spécifié. Par défaut, si le temps d'exécution de la commande dépasse 10 ms, il sera enregistré dans le journal. 🎜🎜slowlog enregistre uniquement le temps d'exécution de la commande, à l'exclusion des opérations aller-retour d'E/S et de la réponse lente causée par les retards du réseau. 🎜🎜Nous pouvons personnaliser la norme des commandes lentes en fonction des performances de base (configurées à 2 fois le délai maximum des performances de base) et ajuster le seuil qui déclenche l'enregistrement des commandes lentes. 🎜🎜Vous pouvez saisir la commande suivante dans redis-cli pour configurer la commande pour qu'elle enregistre pendant plus de 6 millisecondes : 🎜CONFIG SET latency-monitor-threshold 9🎜Elle peut également être définie dans le fichier de configuration Redis.config, en microsecondes. 🎜
想要查看所有执行时间比较慢的命令,可以通过使用 Redis-cli 工具,输入 slowlog get 命令查看,返回结果的第三个字段以微秒位单位显示命令的执行时间。
假如只需要查看最后 2 个慢命令,输入 slowlog get 2 即可。
示例:获取最近2个慢查询命令
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 6
2) (integer) 1458734263
3) (integer) 74372
4) 1) "hgetall"
2) "max.dsp.blacklist"
2) 1) (integer) 5
2) (integer) 1458734258
3) (integer) 5411075
4) 1) "keys"
2) "max.dsp.blacklist"以第一个 HGET 命令为例分析,每个 slowlog 实体共 4 个字段:
字段 1:1 个整数,表示这个 slowlog 出现的序号,server 启动后递增,当前为 6。
字段 2:表示查询执行时的 Unix 时间戳。
字段 3:表示查询执行微秒数,当前是 74372 微秒,约 74ms。
字段4表示查询命令及其参数,如果参数数量较多或较大,则只显示部分参数。hgetall max.dsp.blacklist是当前正在执行的命令。
Latency Monitoring
Redis 在 2.8.13 版本引入了 Latency Monitoring 功能,用于以秒为粒度监控各种事件的发生频率。
启用延迟监视器的第一步是设置延迟阈值(单位毫秒)。只有超过该阈值的时间才会被记录,比如我们根据基线性能(3ms)的 3 倍设置阈值为 9 ms。
可以用 redis-cli 设置也可以在 Redis.config 中设置;
CONFIG SET latency-monitor-threshold 9
工具记录的相关事件的详情可查看官方文档:https://redis.io/topics/latency-monitor
如获取最近的 latency
127.0.0.1:6379> debug sleep 2 OK (2.00s) 127.0.0.1:6379> latency latest 1) 1) "command" 2) (integer) 1645330616 3) (integer) 2003 4) (integer) 2003
事件的名称;
事件发生的最新延迟的 Unix 时间戳;
毫秒为单位的时间延迟;
该事件的最大延迟。
如何解决 Redis 变慢?
Redis 的数据读写由单线程执行,如果主线程执行的操作时间太长,就会导致主线程阻塞。
一起分析下都有哪些操作会阻塞主线程,我们又该如何解决?
网络通信导致的延迟
客户端使用 TCP/IP 连接或 Unix 域连接连接到 Redis。1 Gbit/s 网络的典型延迟约为 200 us。
redis 客户端执行一条命令分 4 个过程:
发送命令-〉 命令排队 -〉 命令执行-〉 返回结果
这个过程称为 Round trip time(简称 RTT, 往返时间),mget mset 有效节约了 RTT,但大部分命令(如 hgetall,并没有 mhgetall)不支持批量操作,需要消耗 N 次 RTT ,这个时候需要 pipeline 来解决这个问题。
Redis pipeline 将多个命令连接在一起来减少网络响应往返次数。
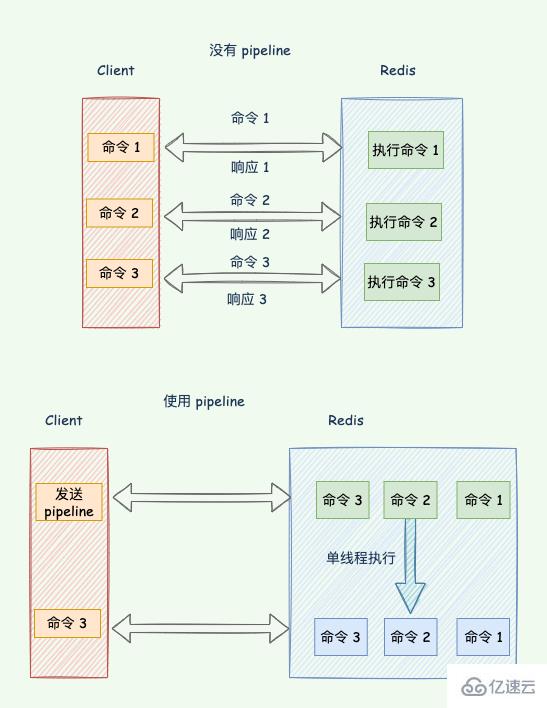
redis-pipeline
慢指令导致的延迟
根据上文的慢指令监控查询文档,查询到慢查询指令。可以通过以下两种方式解决:
在 Cluster 集群中,聚合运算等 O(N) 操作可以在 slave 节点上运行,也可以在客户端端完成。
使用高效的命令代替。采用增量迭代的方法查询数据,避免一次性查询大量数据,在此可参考SCAN、SSCAN、HSCAN和ZSCAN命令。
除此之外,生产中禁用KEYS 命令,它只适用于调试。因为它会遍历所有的键值对,所以操作延时高。
Fork 生成 RDB 导致的延迟
生成 RDB 快照,Redis 必须 fork 后台进程。fork 操作(在主线程中运行)本身会导致延迟。
Redis 使用操作系统的多进程写时复制技术 COW(Copy On Write) 来实现快照持久化,减少内存占用。

写时复制技术保证快照期间数据可修改
但 fork 会涉及到复制大量链接对象,一个 24 GB 的大型 Redis 实例需要 24 GB / 4 kB * 8 = 48 MB 的页表。
执行 bgsave 时,这将涉及分配和复制 48 MB 内存。
此外,从库加载 RDB 期间无法提供读写服务,所以主库的数据量大小控制在 2~4G 左右,让从库快速的加载完成。
内存大页(transparent huge pages)
常规的内存页是按照 4 KB 来分配,Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配。
Redis 使用了 fork 生成 RDB 做持久化提供了数据可靠性保证。
当生成 RDB 快照的过程中,Redis 采用**写时复制**技术使得主线程依然可以接收客户端的写请求。
也就是当数据被修改的时候,Redis 会复制一份这个数据,再进行修改。
采用了内存大页,生成 RDB 期间,即使客户端修改的数据只有 50B 的数据,Redis 需要复制 2MB 的大页。当写的指令比较多的时候就会导致大量的拷贝,导致性能变慢。
使用以下指令禁用 Linux 内存大页即可:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
swap:操作系统分页
当物理内存(内存条)不够用的时候,将部分内存上的数据交换到 swap 空间上,以便让系统不会因内存不够用而导致 oom 或者更致命的情况出现。
当某进程向 OS 请求内存发现不足时,OS 会把内存中暂时不用的数据交换出去,放在 SWAP 分区中,这个过程称为 SWAP OUT。
当某进程又需要这些数据且 OS 发现还有空闲物理内存时,又会把 SWAP 分区中的数据交换回物理内存中,这个过程称为 SWAP IN。
内存 swap 是操作系统里将内存数据在内存和磁盘间来回换入和换出的机制,涉及到磁盘的读写。
触发 swap 的情况有哪些呢?
对于 Redis 而言,有两种常见的情况:
Redis 使用了比可用内存更多的内存;
与 Redis 在同一机器运行的其他进程在执行大量的文件读写 I/O 操作(包括生成大文件的 RDB 文件和 AOF 后台线程),文件读写占用内存,导致 Redis 获得的内存减少,触发了 swap。
我要如何排查是否因为 swap 导致的性能变慢呢?
Linux 提供了很好的工具来排查这个问题,所以当怀疑由于交换导致的延迟时,只需按照以下步骤排查。
获取 Redis 实例 pid
$ redis-cli info | grep process_id process_id:13160
进入此进程的 /proc 文件系统目录:
cd /proc/13160
在这里有一个 smaps 的文件,该文件描述了 Redis 进程的内存布局,运行以下指令,用 grep 查找所有文件中的 Swap 字段。
$ cat smaps | egrep '^(Swap|Size)' Size: 316 kB Swap: 0 kB Size: 4 kB Swap: 0 kB Size: 8 kB Swap: 0 kB Size: 40 kB Swap: 0 kB Size: 132 kB Swap: 0 kB Size: 720896 kB Swap: 12 kB
每行 Size 表示 Redis 实例所用的一块内存大小,和 Size 下方的 Swap 对应这块 Size 大小的内存区域有多少数据已经被换出到磁盘上了。
如果 Size == Swap 则说明数据被完全换出了。
可以看到有一个 720896 kB 的内存大小有 12 kb 被换出到了磁盘上(仅交换了 12 kB),这就没什么问题。
Redis 本身会使用很多大小不一的内存块,所以,你可以看到有很多 Size 行,有的很小,就是 4KB,而有的很大,例如 720896KB。不同内存块被换出到磁盘上的大小也不一样。
敲重点了
如果 Swap 一切都是 0 kb,或者零星的 4k ,那么一切正常。
当出现百 MB,甚至 GB 级别的 swap 大小时,就表明,此时,Redis 实例的内存压力很大,很有可能会变慢。
解决方案
增加机器内存;
将 Redis 放在单独的机器上运行,避免在同一机器上运行需要大量内存的进程,从而满足 Redis 的内存需求;
增加 Cluster 集群的数量分担数据量,减少每个实例所需的内存。
AOF 和磁盘 I/O 导致的延迟
为了保证数据可靠性,Redis 使用 AOF 和 RDB 快照实现快速恢复和持久化。
可以使用 appendfsync 配置将 AOF 配置为以三种不同的方式在磁盘上执行 write 或者 fsync (可以在运行时使用 CONFIG SET命令修改此设置,比如:redis-cli CONFIG SET appendfsync no)。
no:Redis 不执行 fsync,唯一的延迟来自于 write 调用,write 只需要把日志记录写到内核缓冲区就可以返回。
everysec:Redis 每秒执行一次 fsync。使用后台子线程异步完成 fsync 操作。最多丢失 1s 的数据。
always:每次写入操作都会执行 fsync,然后用 OK 代码回复客户端(实际上 Redis 会尝试将同时执行的许多命令聚集到单个 fsync 中),没有数据丢失。建议使用能够快速执行 fsync 并搭配快速的磁盘的文件系统实现,因为在这种模式下性能通常非常低。
我们通常将 Redis 用于缓存,数据丢失完全恶意从数据获取,并不需要很高的数据可靠性,建议设置成 no 或者 everysec。
除此之外,避免 AOF 文件过大, Redis 会进行 AOF 重写,生成缩小的 AOF 文件。
可以把配置项 no-appendfsync-on-rewrite设置为 yes,表示在 AOF 重写时,不进行 fsync 操作。
也就是说,Redis 实例把写命令写到内存后,不调用后台线程进行 fsync 操作,就直接返回了。
expires 淘汰过期数据
Redis 有两种方式淘汰过期数据:
惰性删除:当接收请求的时候发现 key 已经过期,才执行删除;
定时删除:每 100 毫秒删除一些过期的 key。
定时删除的算法如下:
随机采样 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的 key,删除所有过期的 key;
如果发现还有超过 25% 的 key 已过期,则执行步骤一。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP默认设置为 20,每秒执行 10 次,删除 200 个 key 问题不大。
Si le deuxième élément est déclenché, Redis supprimera systématiquement les données expirées pour libérer de la mémoire. Et la suppression bloque.
Quelles sont les conditions de déclenchement ?
C'est-à-dire qu'un grand nombre de touches définissent les mêmes paramètres de temps. Plusieurs déduplications sont nécessaires pour réduire le nombre de clés expirées à moins de 25 %. Ces clés expirent en grand nombre dans la même seconde.
En bref : un grand nombre de clés qui expirent en même temps peuvent entraîner des fluctuations de performances.
Solution
Si un lot de clés expire en même temps, vous pouvez ajouter un nombre aléatoire dans une certaine plage de taille aux paramètres de délai d'expiration d'EXPIREAT et d'EXPIRE. Cela garantit que les clés sont dans un délai proche. La plage doit être supprimée dans le fichier et éviter en même temps la pression causée par l'expiration.
bigkey
Habituellement, nous appelons les clés qui contiennent des données volumineuses ou un grand nombre de membres ou de listes comme grandes clés. Ci-dessous, nous utiliserons plusieurs exemples pratiques pour décrire les caractéristiques des grandes clés :
-
Une clé de type STRING. , sa valeur est de 5Mo (les données sont trop volumineuses)
Une Clé de type LIST, son nombre de listes est de 10 000 (le nombre de listes est trop grand)
Une Clé de type ZSET, Elle compte 10 000 membres (trop de nombreux membres)
Une clé au format HASH Bien qu'elle ne compte que 1 000 membres, la taille totale de la valeur de ces membres est de 10 Mo (la taille des membres est trop grande)
Les problèmes causés par bigkey sont les suivants :
La mémoire Redis continue de croître, provoquant un MOO ou atteignant la valeur de paramètre maxmemory, provoquant un blocage en écriture ou l'expulsion de clés importantes
La mémoire d'un certain nœud du cluster Redis dépasse de loin celle des autres nœuds ; . Cependant, comme la granularité minimale de la migration des données dans Redis Cluster est Key, la mémoire sur le nœud ne peut pas être équilibrée
-
la demande de lecture de bigkey prend trop de bande passante, se ralentit et affecte les autres services du serveur ;
- La suppression d'une grande clé entraînera le blocage de la bibliothèque principale pendant une longue période et provoquera une interruption de la synchronisation ou une commutation maître-esclave
Trouver la grande clé
Utilisez l'outil redis-rdb-tools pour trouver la grande clé ; grande clé de manière personnalisée.Solution
Diviser les grandes clésPar exemple, divisez une clé HASH contenant des dizaines de milliers de membres en plusieurs clés HASH et assurez-vous que le nombre de membres de chaque clé se situe dans une plage raisonnable, dans le cluster Redis. structure , le fractionnement de grandes clés peut jouer un rôle important dans l'équilibre de la mémoire entre les nœuds. Nettoyage asynchrone des grandes clésRedis fournit la commande UNLINK depuis la version 4.0, qui peut nettoyer lentement et progressivement les clés entrantes de manière non bloquante. Grâce à UNLINK, vous pouvez supprimer en toute sécurité des clés volumineuses ou même des clés extra-larges.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!