
Maison >base de données >tutoriel mysql >Quelles sont les utilisations des index dans MySQL
Quelles sont les utilisations des index dans MySQL

- 王林avant
- 2023-06-03 15:22:171349parcourir
Index
1. Avantages de l'index
(1) Améliorer l'efficacité des requêtes (réduire l'utilisation des E/S)
(2) Réduire l'utilisation du processeur
Par exemple, l'ordre des requêtes par âge, car l'arborescence d'index B+ elle-même est le classement Il est en bon état, donc si vous interrogez à nouveau et déclenchez l'index, vous n'avez pas besoin d'interroger à nouveau.
2. Inconvénients de l'index
(1) L'index lui-même est volumineux et peut être stocké en mémoire ou sur le disque dur, généralement sur le disque dur.
(2) Les index ne sont pas utilisés dans toutes les situations, comme ① une petite quantité de données ② des champs qui changent fréquemment ③ des champs rarement utilisés
(3) Les index réduiront l'efficacité des ajouts, des suppressions et des modifications
3. Classification de l'index
(1) Index à valeur unique
(2) Index unique
(3) Index union
(4) Index de clé primaire
Remarque : La seule différence entre l'index unique et l'index de clé primaire : clé primaire l'index ne peut pas être nul
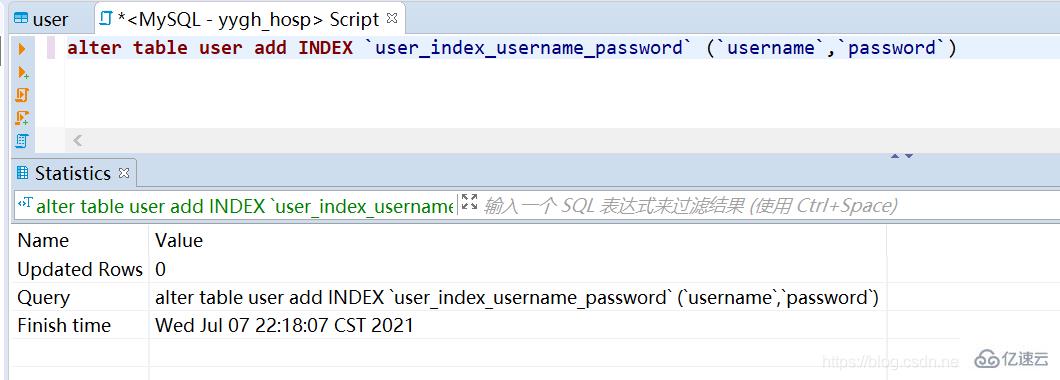
4. Créer un index
alter table user add INDEX `user_index_username_password` (`username`,`password`)
5. Principe de l'index MySQL -> Arbre B+
La structure de données sous-jacente de l'index MySQL est un arbre B+
B+Tree est une optimisation basée sur B-Tree, le rendant plus adapté à la mise en œuvre d'une structure d'index de stockage externe, le moteur de stockage InnoDB utilise B+Tree pour implémenter sa structure d'index.
Chaque nœud du diagramme de structure B-Tree contient non seulement la valeur clé des données, mais également la valeur des données. L'espace de stockage de chaque page est limité. Si les données sont volumineuses, le nombre de clés pouvant être stockées dans chaque nœud (c'est-à-dire une page) sera très faible. Lorsque la quantité de données stockées est importante, cela entraînera également. à B- La profondeur de l'arborescence est plus grande, ce qui augmente le nombre d'E/S disque pendant la requête, affectant ainsi l'efficacité de la requête. Dans B+Tree, tous les nœuds d'enregistrement de données sont stockés sur les nœuds feuilles dans la même couche par ordre de valeur clé. Seules les informations sur les valeurs clés sont stockées sur les nœuds non feuilles. Cela peut augmenter considérablement le nombre de valeurs clés stockées dans chacun. node. , réduisez la hauteur de B+Tree.
B+Tree présente plusieurs différences par rapport à B-Tree :
Les nœuds non-feuilles stockent uniquement les informations sur les valeurs clés.
Il existe un pointeur de lien entre tous les nœuds feuilles.
Les enregistrements de données sont stockés dans des nœuds feuilles.
Optimisez le B-Tree dans la section précédente. Étant donné que les nœuds non-feuilles de B+Tree stockent uniquement les informations sur les valeurs clés, en supposant que chaque bloc de disque puisse stocker 4 valeurs clés et des informations de pointeur, il deviendra la structure de B. +Tree. Comme le montre la figure ci-dessous :
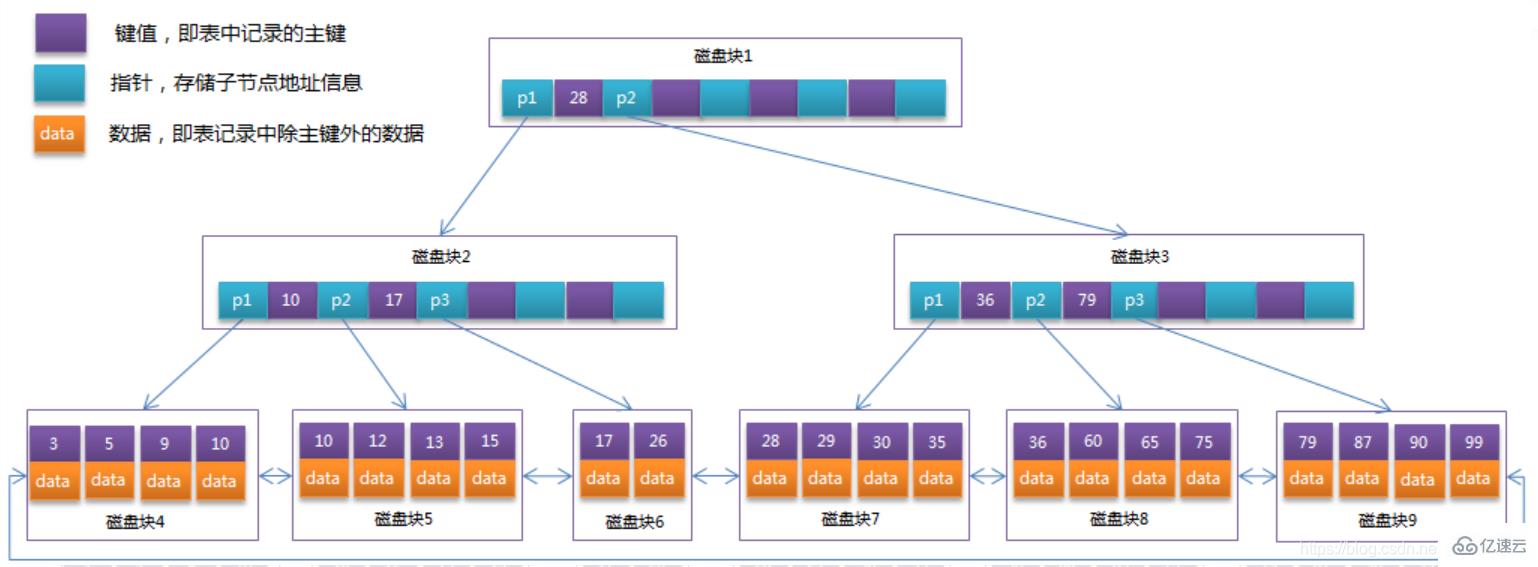
Il y a généralement deux pointeurs de tête sur B+Tree, l'un pointe vers le nœud racine et l'autre vers le nœud feuille avec le plus petit mot-clé, et il existe une sorte de relation entre tous les nœuds feuilles (c'est-à-dire les nœuds de données). Par conséquent, deux opérations de recherche peuvent être effectuées sur B+Tree : l’une est une recherche par plage et une recherche par pagination pour la clé primaire, et l’autre est une recherche aléatoire à partir du nœud racine.
Peut-être qu'il n'y a que 22 enregistrements de données dans l'exemple ci-dessus et que les avantages de B+Tree ne sont pas visibles. Voici un calcul :
La taille de la page dans le moteur de stockage InnoDB est de 16 Ko et le type de clé primaire du. la table générale est la section INT (occupe 4 mots) ou BIGINT (occupe 8 octets), le type de pointeur est généralement de 4 ou 8 octets, ce qui signifie qu'une page (un nœud dans B+Tree) stocke environ 16 Ko/(8B+8B )=1K valeur clé (car il s'agit d'une estimation, pour faciliter le calcul, la valeur de K ici est 〖10〗^3). En d'autres termes, un index B+Tree d'une profondeur de 3 peut conserver 10^3 * 10^3 * 10^3 = 1 milliard d'enregistrements.
Dans les situations réelles, chaque nœud peut ne pas être entièrement rempli, donc dans la base de données, la hauteur de B+Tree est généralement de 2 à 4 couches. Le moteur de stockage InnoDB de MySQL est conçu de telle sorte que le nœud racine réside en mémoire, ce qui signifie que seules 1 à 3 opérations d'E/S disque sont nécessaires pour trouver l'enregistrement de ligne d'une certaine valeur de clé.
L'index B+Tree dans la base de données peut être divisé en index clusterisé et index secondaire. L'exemple de diagramme B+Tree ci-dessus est implémenté dans la base de données en tant qu'index clusterisé. Les nœuds feuilles du B+Tree de l'index clusterisé stockent les données d'enregistrement de ligne de la table entière. La différence entre un index auxiliaire et un index clusterisé est que les nœuds feuilles de l'index auxiliaire ne contiennent pas toutes les données de l'enregistrement de ligne, mais la clé d'index clusterisé qui stocke les données de ligne correspondantes, c'est-à-dire la clé primaire. Lors de l'interrogation de données via un index secondaire, le moteur de stockage InnoDB parcourt l'index secondaire pour trouver la clé primaire, puis trouve les données complètes de l'enregistrement de ligne dans l'index clusterisé via la clé primaire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!