
Maison >base de données >Redis >Comment résoudre le problème de cohérence en double écriture entre Redis et MySQL
Comment résoudre le problème de cohérence en double écriture entre Redis et MySQL

- 王林avant
- 2023-06-03 12:28:101380parcourir
La cohérence en double écriture de Redis et MySQL fait référence à dans le scénario où le cache et la base de données sont utilisés pour stocker des données sur en même temps (il y a principalement une situation de forte concurrence), Comment assurer la cohérence des données entre les deux (le contenu est le même ou le plus proche possible).
Processus commercial normal :
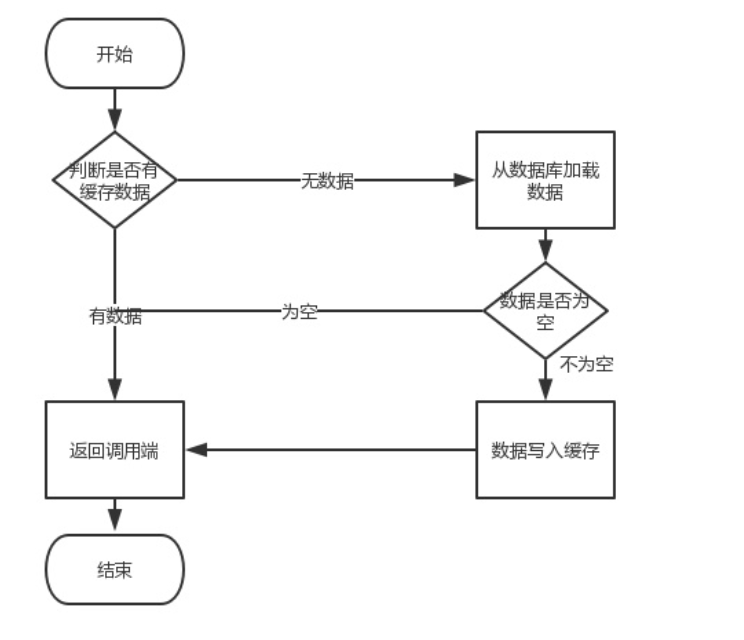
La lecture n'est pas un problème, c'est un problème Le problème réside dans l'opération d'écriture (mise à jour). Plusieurs problèmes peuvent survenir à ce stade. Nous devons d'abord mettre à jour la base de données, puis effectuer des opérations de mise en cache. Lorsque vous traitez le cache, vous devez vous demander s'il faut mettre à jour le cache ou supprimer le cache, ou mettre à jour d'abord le cache, puis mettre à jour la base de données
Pour résumer, devez-vous d'abord utiliser le cache puis la base de données, ou exploiter d'abord la base de données puis le cache ?
Continuons avec ces questions.
Tout d'abord, parlons du cache d'opération, qui comprend deux types : le cache de mise à jour et le cache de suppression. Comment choisir ?
Mettre à jour le cache ? Supprimer le cache ?
# 🎜🎜#Supposons que la base de données soit mise à jour en premier (car faire fonctionner le cache d'abord, puis faire fonctionner la base de données est un gros problème, qui sera abordé plus tard)
- # 🎜🎜#
- Mettre à jour le cache
Lorsque deux requêtes modifient les mêmes données en même temps, d'anciennes données peuvent exister dans le cache car leur ordre peut être inversé. Les demandes de lecture ultérieures liront les anciennes données et ce n'est que lorsque le cache sera invalidé que la valeur correcte pourra être obtenue à partir de la base de données.
- Supprimer le cache
#🎜🎜 #
Mettez d'abord à jour la base de données, puis supprimez le cache.
Il ressort de ce qui précède que les exigences en matière de données sales sont supérieures à les conditions requises pour la mise à jour du cache. De plus, les conditions suivantes doivent être remplies : 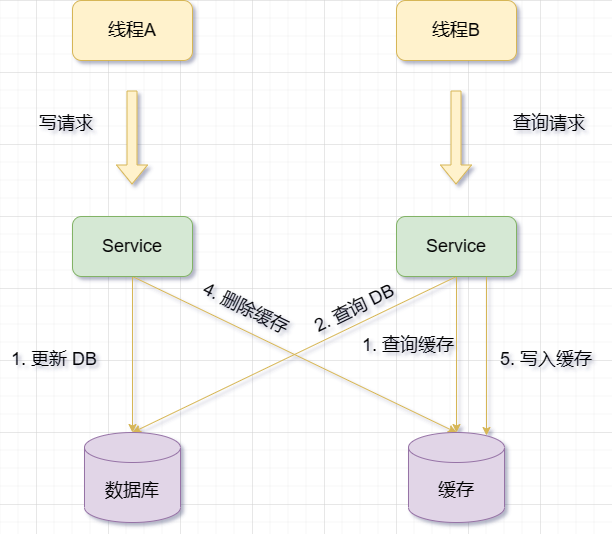 #🎜🎜 #
#🎜🎜 #
Mise à jour de la base de données + suppression du cache # 🎜🎜# prend plus de temps que #🎜 🎜#Lire la base de données + écrire le temps de cacheCourt
-
Les deux premiers sont très satisfaisants. . Est-ce que cela arrivera vraiment ? La base de données est généralement verrouillée lors de la mise à jour et l'opération de lecture est beaucoup plus rapide que l'opération d'écriture, donc la probabilité que le troisième point se produise est extrêmement faible (bien sûr, cela peut arriver)
#🎜🎜 # Remarque : je ne comprends pas vraiment cela. En termes simples, la probabilité que cela se produise est faible, mais s'il y a un retard du réseau, etc., cela n'arrivera-t-il pas également ? J’espère que quelqu’un de bonnes intentions pourra dissiper cette confusion, mais de toute façon, je ne la comprends pas. -
Par conséquent, lorsque vous choisissez de supprimer le cache, vous devez également combiner d'autres technologies pour optimiser les performances et la cohérence. Par exemple :
Utilisez la file d'attente des messages pour supprimer ou mettre à jour le cache de manière asynchrone afin d'éviter de bloquer le fil de discussion principal ou de perdre des messages.
ComparaisonDans le cache de mise à jour, le cache est mis à jour à chaque fois, mais les données du le cache n'est pas Il sera certainement lu
- immédiatement par
- , ce qui entraînera le stockage de nombreuses données rarement consultées dans le cache, gaspillant ainsi les ressources du cache. Et dans de nombreux cas, la valeur écrite dans le cache ne correspond pas exactement à la valeur dans la base de données. Il est très probable que la base de données soit d'abord interrogée, puis qu'une valeur soit obtenue grâce à une série de « calculs ». avant que la valeur ne soit écrite dans le cache. On peut voir que ce schéma de mise à jour du cache
- a non seulement une faible utilisation du cache, mais entraîne également un gaspillage des performances de la machine. Nous considérons donc généralement
Supprimer le cache
Lors de la mise à jour des données,d'abord Écrivez de nouvelles données dans le cache (Redis), puis écrivez les nouvelles données dans la base de données (MySQL)
Mais il y a un problème :
#🎜 🎜# La mise à jour du cache a réussi, mais la mise à jour de la base de données a échoué, entraînant une incohérence des données
Exemple# 🎜🎜# : L'utilisateur a modifié son pseudo. Le système écrit d'abord le nouveau pseudo dans le cache puis met à jour la base de données. Cependant, pendant le processus de mise à jour de la base de données, des situations anormales telles qu'une panne de réseau ou un temps d'arrêt de la base de données se sont produites, entraînant la non-modification du surnom dans la base de données. De cette façon, le pseudo dans le cache ne sera pas cohérent avec le pseudo dans la base de données.
La mise à jour du cache réussit, mais la mise à jour de la base de données est retardée, ce qui entraîne d'autres demandes de lecture d'anciennes données
Exemple : L'utilisateur passe une commande pour un produit, le système écrit d'abord le statut de la commande dans le cache, puis met à jour sa base de données. Cependant, pendant le processus de mise à jour de la base de données, en raison d'une concurrence importante ou pour d'autres raisons, la vitesse d'écriture de la base de données est plus lente que la vitesse d'écriture du cache. De cette façon, d'autres requêtes liront le statut de la commande comme payé à partir du cache et liront le statut de la commande comme non payé à partir de la base de données.
La mise à jour du cache est réussie, mais avant la mise à jour de la base de données, d'autres requêtes interrogent le cache et la base de données, et réécrivent les anciennes données dans le cache, écrasant les nouvelles données
Exemple : Utilisateur A a modifié son avatar et l'a téléchargé sur le serveur. Le système écrit d'abord la nouvelle adresse de l'avatar dans le cache et la renvoie à l'utilisateur A pour l'afficher. Mettez ensuite à jour la nouvelle adresse de l'avatar dans la base de données. Mais au cours de ce processus, l'utilisateur B a visité la page d'accueil personnelle de l'utilisateur A et a lu la nouvelle adresse de l'avatar dans le cache. L'invalidation du cache peut être due à la politique d'expiration du cache ou à d'autres raisons, telles que des opérations de redémarrage, entraînant l'effacement ou l'expiration du cache. À ce moment-là, l'utilisateur B visite à nouveau la page d'accueil personnelle de l'utilisateur A, lit l'ancienne adresse de l'avatar dans la base de données et la réécrit dans le cache. Cela peut empêcher l'adresse de l'avatar dans le cache de correspondre à l'adresse dans la base de données.
Beaucoup de choses ont été dites ci-dessus, mais le résumé est que la mise à jour du cache a réussi, mais la base de données n'a pas été mise à jour (échec de la mise à jour), ce qui a conduit le cache à stocker la dernière valeur et l'inventaire des données à stocker l'ancienne. valeur. Si le cache échoue, l'ancienne valeur de la base de données sera obtenue.
J'ai également été confus plus tard. Étant donné que le problème était dû à l'échec de la mise à jour de la base de données, puis-je résoudre le problème d'incohérence des données en m'assurant simplement que la mise à jour de la base de données réussit, continuez à réessayer la mise à jour ? base de données jusqu'à ce que la mise à jour de la base de données soit terminée.
Plus tard, j'ai découvert que j'étais trop naïf et qu'il y avait de nombreux problèmes, tels que :
Si la raison de l'échec de la mise à jour de la base de données est un temps d'arrêt de la base de données ou une panne du réseau, alors vos tentatives constantes de mise à jour de la base de données peuvent entraîner une pression plus grande et un retard peuvent même entraîner des difficultés dans la récupération de la base de données.
Si la raison de l'échec de la mise à jour de la base de données est un conflit de données ou une erreur de logique métier, vos tentatives constantes de mise à jour de la base de données peuvent entraîner une perte ou une confusion des données, et même affecter les données d'autres utilisateurs.
Si vous continuez à réessayer de mettre à jour la base de données, vous devez alors réfléchir à la manière de garantir l'idempotence et l'ordre des tentatives, et à la manière de gérer les exceptions qui se produisent pendant le processus de nouvelle tentative.
Cette méthode n'est donc pas une très bonne solution.
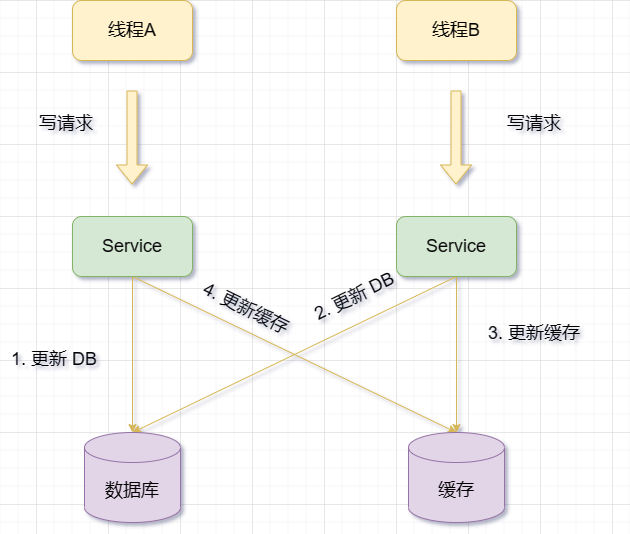
Mettez d'abord à jour la base de données, puis mettez à jour le cache
Lors d'une opération de mise à jour, mettez d'abord à jour les données de la base de données, puis mettez à jour les données du cache correspondantes
Cependant, cette solution présente également certains problèmes et risques, tels que :
Si la base de données est mise à jour avec succès, mais que la mise à jour du cache échoue, les anciennes données seront conservées dans le cache, alors que la base de données contient déjà de nouvelles données, c'est-à-dire des données sales.
S'il y a d'autres demandes pour les mêmes données entre la mise à jour de la base de données et la mise à jour du cache, et qu'il s'avère que le cache existe, alors les anciennes données seront lues à partir du cache. Cela entraînera également une incohérence entre le cache et la base de données.
Ainsi, lors de l'utilisation de l'opération de mise à jour du cache, peu importe qui vient en premier, si une exception se produit dans ce dernier, cela aura un impact sur l'activité. (Toujours l'image ci-dessus)
Alors, comment gérer les exceptions pour assurer la cohérence des données
La source de ces problèmes est causée par la concurrence multithread, le moyen le plus simple est donc de verrouiller (verrouillage distribué) . Si deux threads souhaitent modifier les mêmes données, chaque thread doit demander un verrou distribué avant d'apporter des modifications. Seul le thread qui a obtenu le verrou est autorisé à mettre à jour la base de données et le cache. Le thread qui ne peut pas obtenir le verrou renverra un échec et. attendez la prochaine tentative. La raison en est de limiter un seul thread aux données d'exploitation et au cache pour éviter les problèmes de concurrence.
Mais le verrouillage prend du temps et demande beaucoup de travail, il n'est donc absolument pas recommandé. De plus, chaque fois que le cache est mis à jour, les données du cache peuvent ne pas être lues immédiatement. Cela peut entraîner le stockage dans le cache d'un grand nombre de données rarement consultées, ce qui gaspille les ressources du cache. Et dans de nombreux cas, la valeur écrite dans le cache ne correspond pas exactement à la valeur dans la base de données. Il est très probable que la base de données soit d'abord interrogée, puis qu'une valeur soit obtenue grâce à une série de « calculs ». avant que la valeur ne soit écrite dans le cache.
On peut constater que cette solution de mise à jour de la base de données + mise à jour du cache entraîne non seulement une faible utilisation du cache, mais entraîne également un gaspillage de performances de la machine.
Donc, à ce stade, nous devons envisager une autre solution : Supprimer le cache
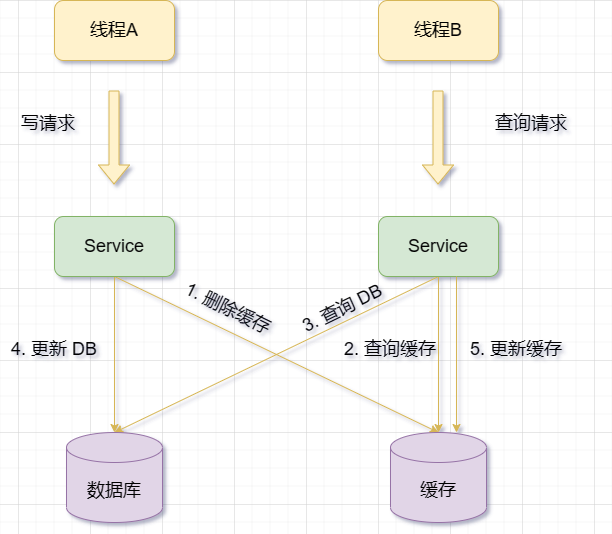
Supprimez d'abord le cache, puis mettez à jour la base de données
Lorsqu'il y a une opération de mise à jour, supprimez d'abord les données du cache correspondantes, puis mettez à jour les données de la base de données
Cependant, cette solution présente également certains problèmes et risques, tels que :
Si la mise à jour de la base de données échoue après la suppression du cache, le cache sera perdu et la prochaine requête devra recharger les données de la base de données, ce qui augmente la pression sur la base de données et le temps de réponse.
Si entre la suppression du cache et la mise à jour de la base de données, il y a d'autres requêtes pour les mêmes données et qu'il s'avère que le cache n'existe pas, alors les anciennes données seront lues dans la base de données et écrites dans le cache. Cela entraînerait une incohérence entre le cache et la base de données.
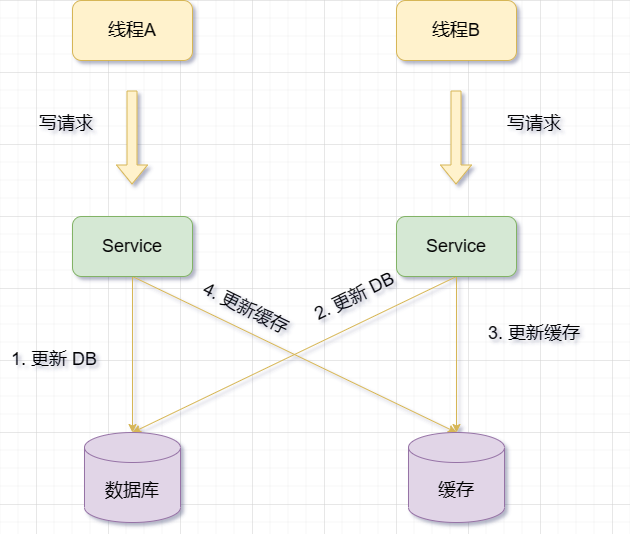
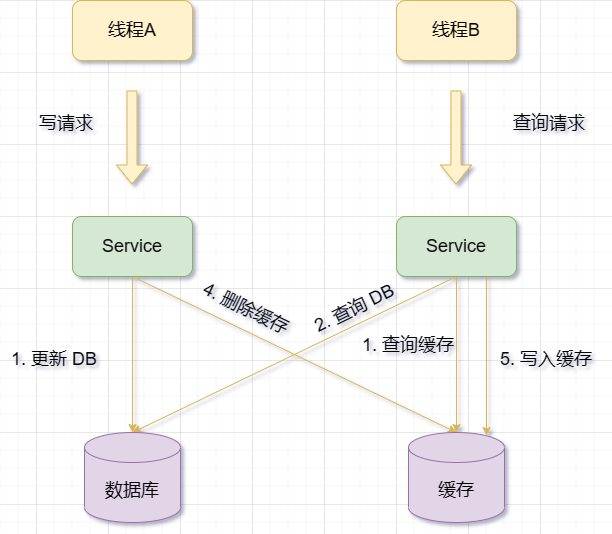
Mettez d'abord à jour la base de données, puis supprimez le cache
Lorsqu'il y a une opération de mise à jour, mettez d'abord à jour les données de la base de données, puis supprimez le cache
Je l'ai dit plus haut, permettez-moi de répéter encore une fois
Invalidation du cache Lorsque, la requête B peut être demandée pour interroger les données de la base de données et obtenir l'ancienne valeur. À ce stade, A est invité à mettre à jour la base de données, à écrire la nouvelle valeur dans la base de données et à supprimer le cache. La requête B écrit l'ancienne valeur dans le cache, ce qui entraîne des données sales
Il ressort de ce qui précède que les exigences pour les données sales sont plus que les exigences pour la mise à jour du cache. Les conditions suivantes doivent être remplies :
. "Invalidation du cache"Les deux premiers sont très satisfaisant pour nous. Regardons le troisième point, est-ce que cela arrivera vraiment ?
- Vous avez expliqué les problèmes qui surviendront après ces opérations, alors comment éviter ces problèmes ?
La base de données est généralement verrouillée lors de la mise à jour et l'opération de lecture est beaucoup plus rapide que l'opération d'écriture, donc la probabilité que le troisième point se produise est extrêmement faiblePour le problème de double écriture, une solution plus appropriée consiste à mettre à jour le base de données avant de la supprimer, bien entendu, des situations spécifiques nécessitent une analyse spécifique et ne peuvent pas être généralisées.
Supprimez d'abord le cache, puis mettez à jour la base de données, puis utilisez un thread asynchrone ou une file d'attente de messages pour reconstruire le cache.
Mettez d'abord à jour la base de données, puis supprimez le cache et définissez un délai d'expiration raisonnable pour garantir l'efficacité du cache. Utilisez des verrous distribués ou des verrous optimistes pour contrôler les accès simultanés et garantir qu'une seule requête peut faire fonctionner le cache et la base de données à la fois
……
Voici quelques méthodes courantes pour garantir la cohérence de la double écritureSolution
1. Réessayer
La file d'attente des messages garantit la fiabilité- 2. Nouvelle tentative asynchrone
Comme mentionné ci-dessus, lorsque la deuxième étape échoue, je réessayerai et j'essaierai d'y remédier autant que possible, mais le coût d'une nouvelle tentative est trop élevé, comme mentionné ci-dessus, je ne gagnerai pas. Je ne le répéterai pas.
- 2.1 Utilisez la file d'attente des messages pour implémenter une nouvelle tentative
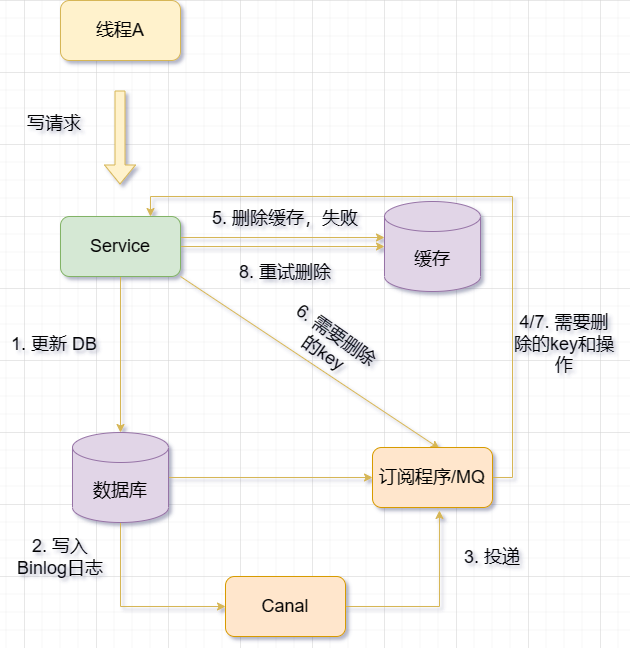
Étant donné que la méthode de nouvelle tentative consomme des ressources, je le ferai de manière asynchrone. Lors de la suppression ou de la mise à jour du cache, si l'opération échoue, une erreur n'est pas renvoyée immédiatement. Au lieu de cela, l'opération de nouvelle tentative du cache est déclenchée via certains mécanismes (tels que les files d'attente de messages, les tâches planifiées, les abonnements aux journaux binaires, etc.). Bien que cette méthode puisse éviter la perte de performances et les problèmes de blocage lors d'une nouvelle tentative de cache de manière synchrone, elle prolongera la période pendant laquelle les données du cache et de la base de données sont incohérentes.
: les messages écrits dans la file d'attente ne seront pas perdus jusqu'à ce qu'ils soient consommés avec succès (vous n'avez pas à vous soucier du redémarrage du projet)
La file d'attente des messages garantit la livraison réussie du message: l'aval extrait le message de la file d'attente et le supprime après une consommation réussie. Sinon, il continuera à transmettre le message au consommateur (conformément à nos exigences de nouvelle tentative).
Utilisation asynchrone de la file d'attente des messages La situation de nouvelle tentative du cache signifie que lorsque les informations changent, la base de données est d'abord mise à jour, puis le cache est supprimé si la suppression réussit, tout le monde est content. Si la suppression échoue, la clé qui doit être supprimée est envoyée à la file d'attente des messages. De plus, un thread consommateur récupérera la clé à supprimer de la file d'attente des messages et supprimera ou mettra à jour le cache Redis en fonction de la clé. Si l'opération échoue, elle est renvoyée à la file d'attente des messages pour une nouvelle tentative.
Remarque : vous pouvez également l'envoyer directement à la file d'attente des messages sans essayer de le supprimer au préalable, et laisser la file d'attente des messages
Par exemple, si vous avez une table d'informations utilisateur, vous souhaitez stocker les informations utilisateur dans Redis . Les étapes suivantes peuvent être effectuées, en prenant comme exemple la solution utilisant la mise en cache des nouvelles tentatives asynchrones de la file de messages :
Lorsque les informations utilisateur changent, mettez d'abord à jour la base de données et renvoyez le résultat réussi au front-end.
Essayez de supprimer le cache. Si cela réussit, l'opération se terminera. Si elle échoue, un message sera généré pour l'opération de suppression ou de mise à jour du cache (par exemple, incluant la clé et le type d'opération) et envoyé. à la file d'attente des messages (par exemple, en utilisant Kafka ou RabbitMQ).
De plus, il existe un fil de discussion consommateur qui s'abonne et obtient ces messages de la file d'attente des messages, et supprime ou met à jour les informations correspondantes dans Redis en fonction du contenu du message.
Si le cache est supprimé ou mis à jour avec succès, le message sera supprimé (rejeté) de la file d'attente des messages pour éviter des opérations répétées.
Si la suppression ou la mise à jour du cache échoue, mettez en œuvre une stratégie d'échec, telle que la définition d'un délai ou d'une limite de nouvelle tentative, puis renvoyez le message à la file d'attente des messages pour une nouvelle tentative.
Si les tentatives échouent toujours après avoir dépassé un certain nombre de fois, un message d'erreur sera envoyé à la couche métier et le journal sera enregistré.
2.2 Binlog implémente une nouvelle tentative de suppression asynchrone
L'idée de base de l'utilisation de binlog pour assurer la cohérence est d'utiliser les journaux binlog pour enregistrer les opérations de modification de la base de données, puis de synchroniser ou de restaurer les données via une réplication maître-esclave ou une sauvegarde incrémentielle.
Par exemple, si nous avons une base de données maître et une base de données esclave, nous pouvons activer binlog sur la base de données maître et définir la base de données esclave comme nœud de réplication. De cette façon, lorsqu'une opération de modification se produit sur la base de données maître, elle enverra le journal binlog correspondant à la base de données esclave, et la base de données esclave effectuera la même opération en fonction du journal binlog pour garantir la cohérence des données. De plus, si nous devons restaurer les données avant un certain moment, nous pouvons également utiliser les journaux binlog pour y parvenir. Tout d’abord, nous devons rechercher le fichier de sauvegarde complète le plus récent avant le moment correspondant et le restaurer dans la base de données cible. Ensuite, nous devons rechercher tous les fichiers de sauvegarde incrémentielle (c'est-à-dire les fichiers journaux binlog) avant le moment correspondant et les appliquer à la base de données cible dans l'ordre. De cette façon, nous pouvons restaurer l’état des données avant le moment cible.
Le journal binlog de MySQL enregistre les opérations de modification de la base de données, telles que les insertions, mettre à jour, supprimer, etc. Le journal binlog a deux fonctions principales, l'une est la réplication maître-esclave et l'autre est la sauvegarde incrémentielle.
- Utilisez Binlog pour mettre à jour/supprimer le cache Redis en temps réel. En utilisant Canal, le service responsable de la mise à jour du cache est déguisé en nœud esclave MySQL, reçoit le Binlog de MySQL, analyse le Binlog, obtient des informations sur les modifications des données en temps réel, puis met à jour/supprime le cache Redis en fonction des informations sur les modifications ;
La stratégie MQ+ Canal, fournit directement les données Binlog reçues par Canal Server à MQ pour le découplage, et utilise MQ pour consommer de manière asynchrone les journaux Binlog pour la synchronisation des données ;La réplication maître-esclave est le processus permettant de synchroniser les données en synchronisant les données d'une base de données maître vers une ou plusieurs bases de données esclaves. La base de données maître enverra son propre journal binlog à la base de données esclave, et la base de données esclave effectuera la même opération en fonction du journal binlog pour garantir la cohérence des données. En mettant en œuvre cette approche, la disponibilité et la fiabilité des données peuvent être améliorées, ainsi que l'équilibrage de charge et la récupération après panne.
À ce stade, nous pouvons conclure que afin d'assurer la cohérence de la base de données et du cache, il est recommandé d'adopter la solution « mettre d'abord à jour la base de données, puis supprimer le cache », et de coopérer avec la « File d'attente des messages » ou la méthode "S'abonner au journal des modifications" pour le faire.3. Double suppression retardée
Notre objectif est de mettre à jour d'abord la base de données, puis de supprimer le cache. Que se passe-t-il si je souhaite d'abord supprimer le cache, puis mettre à jour la base de données ?
Rappelez-vous ce que j'ai dit précédemment à propos de la suppression d'abord du cache, puis de la mise à jour de la base de données. Cela entraînera l'écrasement de l'ancienne valeur. C'est facile à gérer. Nous supprimons simplement l'ancienne valeur et c'est terminé. double suppression. Son idée de base est la suivante :
Supprimez d'abord le cache
- puis mettez à jour la base de données
- Veillez pendant un certain temps (déterminé en fonction des conditions du système)
- Supprimez le cache. encore une fois
- Afin d'éviter de mettre à jour la base de données, cette mesure a été prise après que d'autres threads aient lu les données mises en cache expirées et les aient réécrites dans le cache, provoquant une incohérence des données.
Par exemple : supposons qu'il existe un tableau d'informations sur l'utilisateur, dont l'un contient des points utilisateur. Il y a maintenant deux threads A et B opérant sur les points de l'utilisateur en même temps :
Le thread A veut augmenter les points de l'utilisateur de 100 points
- Le thread B veut diminuer les points de l'utilisateur de 50 points
Si la stratégie de double suppression différée est utilisée, le processus d'exécution des threads A et B peut être le suivant :
Le thread A supprime d'abord les informations utilisateur dans le cache
Le thread A lit ensuite les informations utilisateur à partir de la base de données, il s'avère que le score de l'utilisateur est de 1000
Le fil A ajoute 100 au score de l'utilisateur, devient 1100 et le met à jour dans la base de données
Le fil A dort pendant 5 secondes (en supposant que cette heure soit assez pour que la base de données se synchronise)
Le thread A supprime à nouveau les informations utilisateur dans le cache
Le thread B supprime d'abord les informations utilisateur dans le cache
Le thread B lit ensuite les informations utilisateur de la base de données et constate que les points utilisateur sont de 1 100 (car le thread A a été mis à jour)
Le thread B soustrait 50 des points utilisateur à 1050 et le met à jour dans la base de données
Le thread B dort pendant 5 secondes (en supposant que ce temps soit suffisant pour que la base de données se synchronise)
Le thread B supprime à nouveau le cache Informations utilisateur
Le résultat final est : les points utilisateur dans la base de données sont 1050 et il n'y a aucune information utilisateur dans le cache. La prochaine fois que les informations utilisateur seront interrogées, elles seront d'abord lues à partir du cache, au lieu d'être obtenues à partir de la base de données et écrites dans le cache. Cela garantit la cohérence des données.
La double suppression différée convient aux scénarios de concurrence élevée, en particulier aux situations où les opérations de modification de données sont fréquentes et les opérations de requête sont peu nombreuses. Cela peut réduire la pression sur la base de données et améliorer les performances tout en garantissant la cohérence éventuelle des données. La double suppression retardée convient également aux scénarios dans lesquels la base de données présente un délai de synchronisation maître-esclave, car elle peut éviter de lire les anciennes données mises en cache et de les réécrire dans le cache après la mise à jour de la base de données et avant que la synchronisation ne soit terminée à partir de la base de données esclave.
Remarque : Ce temps de veille = le temps nécessaire pour lire les données de la logique métier + quelques centaines de millisecondes. Afin de garantir la fin de la demande de lecture, la demande d'écriture peut supprimer les données sales mises en cache qui peuvent être apportées par la demande de lecture.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!