
Maison >base de données >tutoriel mysql >Quelle est l'utilisation des index dans la base de données MySQL
Quelle est l'utilisation des index dans la base de données MySQL

- WBOYavant
- 2023-06-03 11:18:572620parcourir
1. Introduction aux index MySQL
Un index est un "répertoire" que la base de données MySQL ajoute à une ou plusieurs colonnes de la table afin d'accélérer l'interrogation des données. L'index de MySQL est un fichier spécial, mais l'index de la table du moteur de type InnoDB (nous expliquerons le moteur MySQL dans un prochain article) fait partie intégrante de l'espace table.
La base de données MySQL prend en charge un total de 5 types d'index, à savoir les index ordinaires, les index uniques, les index de clé primaire, les index composites et les index de texte intégral Ci-dessous, je présenterai ces quatre types d'index un par un.
2. Explication détaillée des cinq types d'index MySQL
(1) Index ordinaire
L'index ordinaire est un index ordinaire dans la base de données MySQL L'ajout de colonnes d'index ordinaire n'a pas d'exigences particulières pour les données. l'index peut être joué Juste pour accélérer la requête de différence.
Un exemple d'ajout d'une instruction SQL d'index commun lors de la création d'une table de données est le suivant :
create table exp(id int , name varchar(20),index exp_name(name));
Ou remplacez index par key, comme suit :
create table exp (id ,int , name varahcr (20) , key exp_name(name));
Dans la commande SQL ci-dessus, key ou index signifie ajouter un index, suivi de près par le Nom de l'index, suivi de la colonne entre parenthèses à indexer.
Toutes les instructions SQL liées aux index présentées dans cet article peuvent être remplacées par une clé s'il n'y a pas d'instructions particulières. Afin d'économiser la longueur de l'article, ce point ne sera pas répété à l'avenir.
De plus, nous pouvons également ajouter un index sans préciser le nom de l'index. Dans ce cas, MySQL ajoutera automatiquement un nom d'index avec le même nom que le champ à l'index.
Le résultat de l'exécution est le suivant :
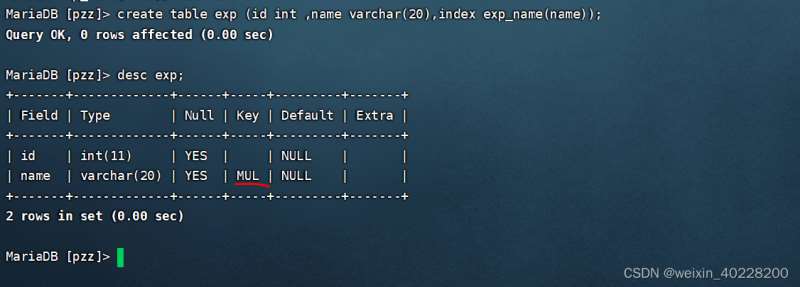
L'exemple d'instruction SQL pour ajouter un nouvel index ordinaire à la table après avoir créé la table de données est le suivant :
alter table exp add index exp_id(id);
Le résultat de l'exécution est le suivant :
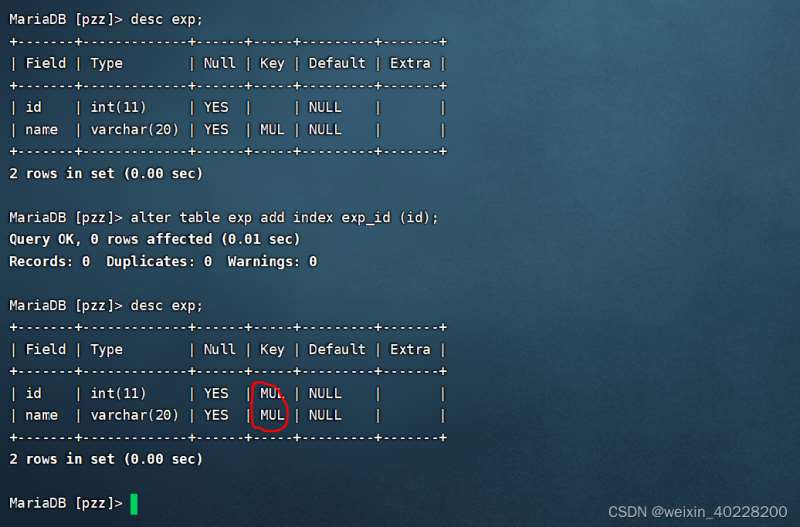
L'exemple d'instruction SQL pour supprimer l'index ordinaire après avoir créé la table de données est le suivant :
alter table drop index exp_name;
Les résultats de l'exécution sont les suivants :
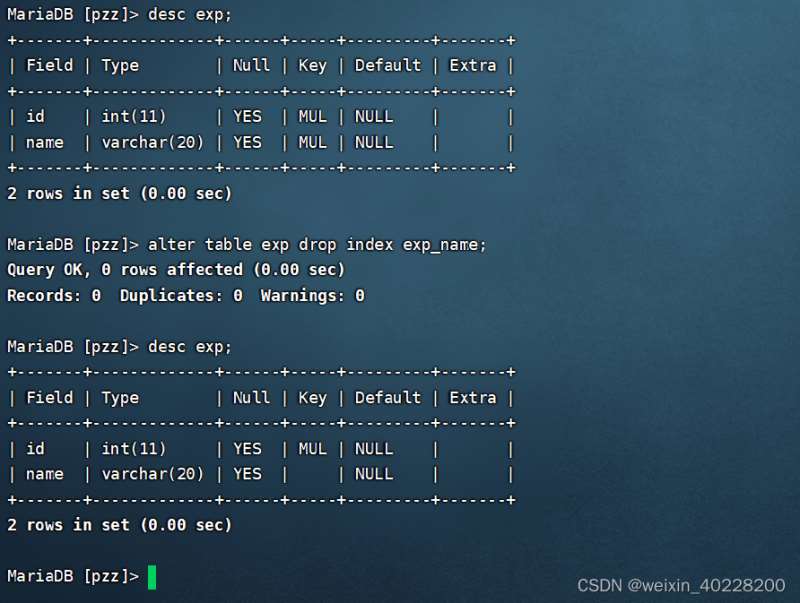
Notez que dans la commande ci-dessus, exp_name est le nom de l'index et pas le nom du champ contenant l'index. Si on oublie le nom de l'index dans la table, on peut exécuter la commande SQL suivante Requête d'entrée :
show index from exp;
où exp est le nom de la table. Le résultat de l'exécution de cette commande est le suivant :

Comme le montrent les images ci-dessus, après avoir ajouté un index normal, lorsque vous utilisez desc pour afficher la structure de la table, vous trouverez la colonne clé MUL apparaître sur la colonne, ce qui signifie qu'un index normal est ajouté à la colonne.
(2) Index unique
L'index unique est basé sur l'index ordinaire, exigeant que toutes les valeurs de la colonne ajoutées à l'index ne puissent apparaître qu'une seule fois. Les termes couramment utilisés pour les index uniques sont ajoutés dans des champs tels que le numéro d'identification et le numéro d'étudiant, mais ne peuvent pas être ajoutés dans des champs tels que le nom et le nom.
L'ajout d'un index unique est quasiment identique à celui d'un index normal, sauf que la clé et l'index de l'index normal doivent être remplacés par clé unique et index unique.
Un exemple d'instruction SQL pour ajouter un index unique lors de la création d'une table de données est le suivant :
create table exp (id int, name varchar(20), unique key (name));
Le résultat de l'exécution de la commande ci-dessus est le suivant :
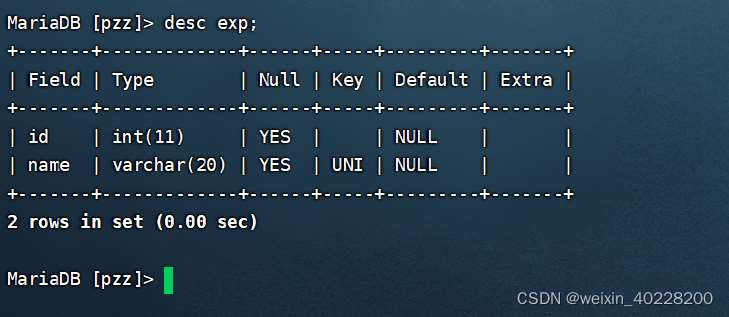
On peut voir que lors de l'ajout d'un index unique Dans ce champ, lorsque vous utilisez la commande desc pour interroger la structure de la table, UNI sera affiché dans la colonne Clé, indiquant qu'un index unique a été ajouté à ce champ.
L'exemple d'instruction SQL pour ajouter un index unique après avoir créé la table de données est le suivant :
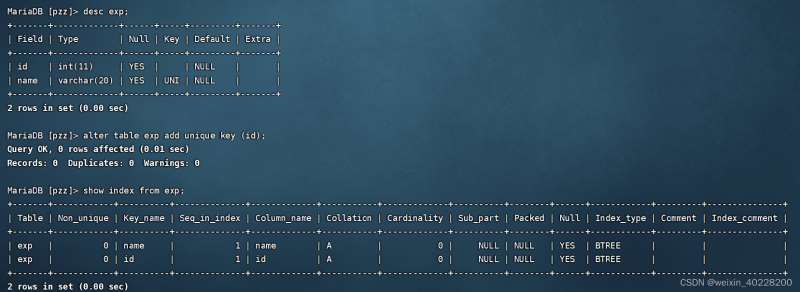
L'exemple d'instruction SQL pour supprimer l'index unique est le suivant :
alter table exp drop index name;
Les résultats d'exécution sont les suivants :
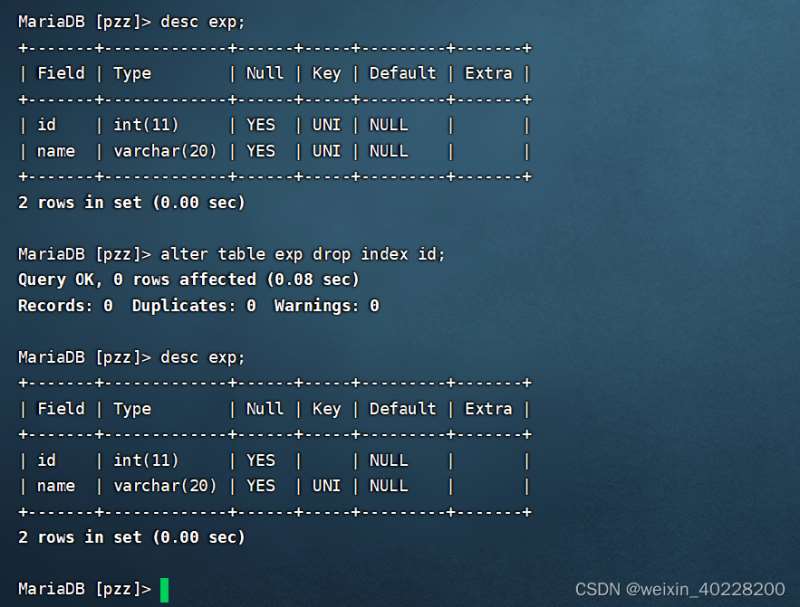
(3) Index de clé primaire
L'index de clé primaire est la requête la plus rapide parmi tous les index de la base de données, et chaque table de données ne peut avoir qu'une seule colonne d'index de clé primaire. Les colonnes indexées par la clé primaire n'autorisent pas les données en double ou les valeurs nulles.
L'ajout et la suppression d'index de clé primaire sont très similaires aux index ordinaires et aux index uniques, sauf que la clé est remplacée par la clé primaire. Les commandes SQL pertinentes sont les suivantes :
create table exp(id int ,name varchar(20), primary key (id));alter table exp add primary key (id);
La colonne de l'index de clé primaire est ajoutée, et le PRI sera affiché sur la colonne Clé lorsque desc visualise la structure de la table, comme indiqué ci-dessous :
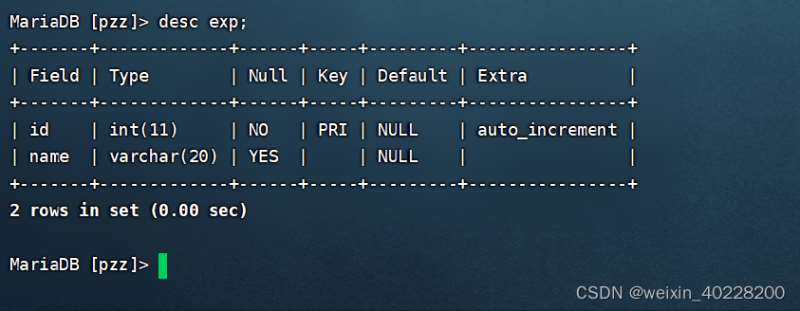
Pour supprimer le index de clé primaire, vous pouvez exécuter la commande :
alter table exp drop primary key;
Remarque : dans cette instruction SQL, la clé ne peut pas être remplacée par l'index.
Parfois, lorsque nous essayons de supprimer l'index de clé primaire, MySQL le rejette peut-être parce que l'attribut auto_increment est ajouté au champ. Nous pouvons supprimer le modificateur de champ et supprimer l'index de clé primaire du champ, comme indiqué ci-dessous :
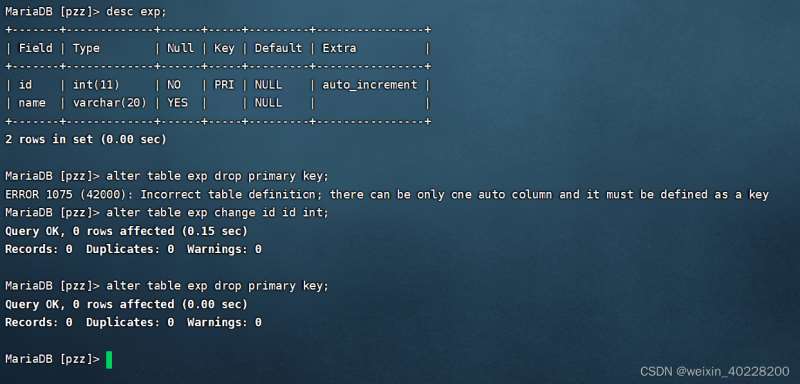
(四)复合索引
如果想要创建一个包含不同的列的索引,我们就可以创建符合索引。其实,复合索引在业务场景中应用的非常频繁,比如,如果我们想要记录数据包的内容,则需要将IP和端口号作为标识数据包的依据,这时就可以把IP地址的列和端口号的列创建为复合索引。复合、添加和删除索引创建SQL语句示例如下:
create table exp (ip varchar(15),port int ,primary key (ip,port)); alter table exp add pirmary key(ip ,port); alter table exp dorp priamary key;
复合索引在创建后,在使用desc查看数据表结构时,会在Key列中发现多个PRI,这就表示这些含有PRI的列就是复合索引的列了。如下所示:
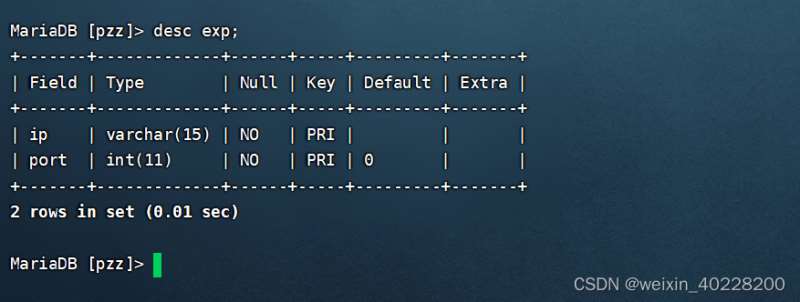
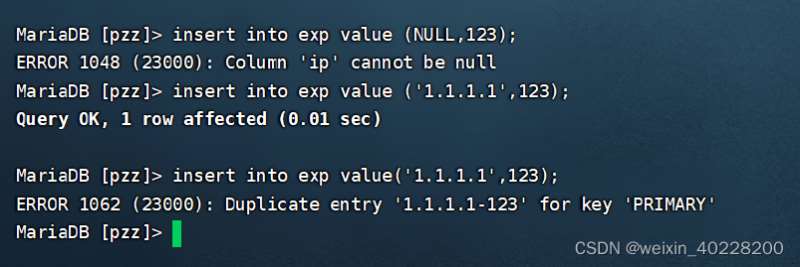
注意,复合索引相当于一个多列的主键索引,因此,添加复合索引的任何一个列都不允许数据为空,并且这些列不允许数据完全相同,否则MySQL数据库会报错。如下所示:
(五)全文索引
全文索引主要是用于解决大数据量的情况下模糊匹配的问题。如果数据库中某个字段的数据量非常大,那么如果我们想要使用like+通配符的方式进行查找,速度就会变得非常慢。针对这种情况,我们就可以使用全文索引的方式,来加快模糊查询的速度。全文索引的原理便是通过分词技术,分析处文本中关键字及其出现的频率,并依次建立索引。全文索引的使用,与数据库版本、数据表引擎乃至字段类型息息相关,主要限制如下:
1、MySQL3.2版本以后才支持全文索引。
2、MySQL5.7版本以后MySQL才内置ngram插件,全文索引才开始支持中文。
3、MySQL5.6之前的版本,只有MyISAM引擎才支持全文索引。
4、MySQL5.6以后的版本,MyISAM引擎和InnoDB引擎都支持全文索引。
5、只有字段数据类型为char、varchar、以及text的字段才支持添加全文索引。
创建、添加以及删除全文索引SQL命令如下:
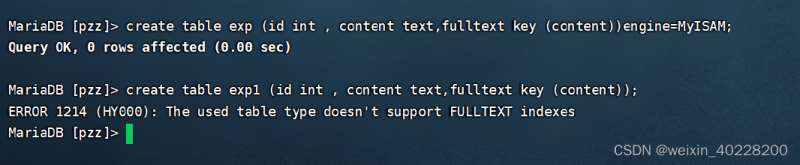
create table exp (id int ,content text ,filltext key (content))engine=MyISAM; alter table exp add fulltext index (content); alter table exp drop index content;
部分执行结果如下:
在创建了全文索引后,也不能够使用like+通配符的方式进行模糊查询,全文索引的使用有其特定的语法,如下所示:
select * from exp where match(content) against ('a');
其中,match后面的括号里是含有全文索引的字段,against后面的括号里是要模糊匹配的内容。
此外,全文索引的作用并不是唯一的,在很多场景下,我们并不会使用MySQL数据库内置的全文索引,而是使用第三方类似的索引以实现相同的功能。
三、MySQL索引使用原则
1、索引是典型的“以空间换时间”的策略,它会消耗计算机存储空间,但是会加快查询速度。
2、索引的添加,尽管加快了在查询时的查询速度,但是会减慢在插入、删除时的速度。因为在插入、删除数据时需要进行额外的索引操作。
3、索引并非越多越好,数据量不大时不需要添加索引。
4、如果一个表的值需要频繁的插入和修改,则不适合建立索引,反制,如果一个表中某个字段的值要经常进行查询、排序和分组的字段则需要建立索引。
5、如果一个字段满足建立唯一性索引的条件,就不要建立普通索引。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!