
Maison >base de données >Redis >Comment implémenter le partage de données Redis
Comment implémenter le partage de données Redis

- 王林avant
- 2023-06-03 09:05:251664parcourir
Introduction à Twemproxy
Twemproxy de Twitter est actuellement le service de cluster Redis le plus utilisé sur le marché. Étant donné que Redis est monothread et que le cluster officiel n'est pas très stable et largement utilisé. Twemproxy est un mécanisme de partage de proxy. En tant que proxy, Twemproxy peut accepter l'accès de plusieurs programmes, le transmettre à chaque serveur Redis en arrière-plan selon les règles de routage, puis revenir à l'itinéraire d'origine. Cette solution résout bien le problème de la capacité de charge d’une seule instance Redis. Bien entendu, Twemproxy lui-même est également un point unique et doit utiliser Keepalived comme solution à haute disponibilité (ou LVS). Grâce à Twemproxy, plusieurs serveurs peuvent être utilisés pour étendre horizontalement le service Redis, ce qui peut efficacement éviter les points de défaillance uniques. Bien que l'utilisation de Twemproxy nécessite plus de ressources matérielles et entraîne une certaine perte de performances Redis (environ 20 % dans le test Twitter), il est assez rentable d'améliorer la haute disponibilité de l'ensemble du système. En fait, twemproxy implémente non seulement le protocole redis, mais également le protocole memcached. Qu'est-ce que cela signifie ? En d'autres termes, twemproxy peut non seulement proxy Redis, mais également proxy Memcached.
Avantages de Twemproxy :
1) L'exposition d'un nœud d'accès au monde extérieur réduit la complexité du programme.
2) Prend en charge la suppression automatique des nœuds défaillants. Vous pouvez définir l'heure de reconnexion du nœud et supprimer le nœud après avoir défini le nombre de connexions. Cette méthode convient au stockage du cache, sinon la clé sera. perdu ; #🎜🎜 #
3) Prise en charge de la configuration de HashTag. Grâce à HashTag, vous pouvez définir deux KEYhash sur la même instance. 4) Plusieurs algorithmes de hachage et le poids de l'instance backend peuvent être définis. 5) Réduisez le nombre de connexions directes à Redis : maintenez une longue connexion avec Redis, définissez le numéro de chaque connexion Redis entre l'agent et le backend, et partagez-la automatiquement sur plusieurs instances Redis sur le back-end. 6) Évitez les problèmes ponctuels : plusieurs couches proxy peuvent être déployées en parallèle et le client sélectionne automatiquement celle disponible. 7) Haut débit : réutilisation des connexions, réutilisation de la mémoire, demandes de connexion multiples, composées de pipeline redis et de requêtes unifiées vers redis. Inconvénients de Twemproxy : 1) Il ne prend pas en charge les opérations sur plusieurs valeurs, telles que prendre la sous-intersection et le complément d'ensembles, etc. 2) Les opérations de transaction Redis ne sont pas prises en charge. 3) La mémoire appliquée ne sera pas libérée. Toutes les machines doivent avoir une grande mémoire et doivent être redémarrées régulièrement, sinon des erreurs de connexion client se produiront. 4) L'ajout et la suppression dynamiques de nœuds ne sont pas pris en charge, et un redémarrage est requis après avoir modifié la configuration. 5) Lors du changement de nœuds, le système ne réaffectera pas les données existantes. Si vous n'écrivez pas votre propre script pour la migration des données, certaines clés seront perdues (la clé elle-même existe sur un certain redis, mais la clé a été piratée) Hope atteint d'autres nœuds, provoquant une "perte"). 6) Le poids affecte directement le résultat de hachage de la clé. Changer le poids du nœud entraînera la perte de certaines clés. 7) Par défaut, Twemproxy s'exécute dans un seul thread, mais la plupart des entreprises qui utilisent Twemproxy effectueront elles-mêmes le développement secondaire et le changeront en multi-threading. Dans l'ensemble, twemproxy est toujours très fiable, même s'il y a une perte de performances, il en vaut toujours la peine. Il a été testé pendant longtemps et est largement utilisé. Pour des informations plus détaillées, veuillez vous référer à la documentation officielle. De plus, twemproxy ne convient qu'aux clusters statiques et ne convient pas aux scénarios nécessitant l'ajout et la suppression dynamiques de nœuds et un ajustement manuel de la charge. Si nous l'utilisons directement, nous devons effectuer un travail de développement et d'amélioration. https://github.com/wandoulabs/codis Ce système est basé sur twemproxy et ajoute des fonctions telles que la migration dynamique des données. L'utilisation spécifique nécessite des tests supplémentaires. Architecture d'utilisation de TwemproxyLe premier type : Twemproxy à nœud unique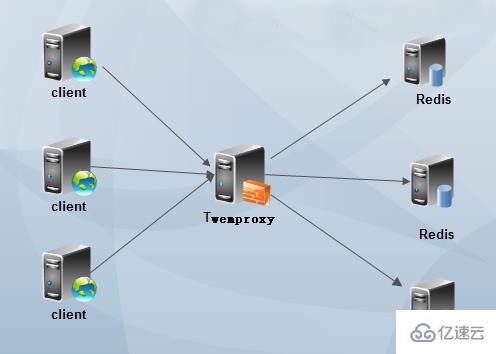
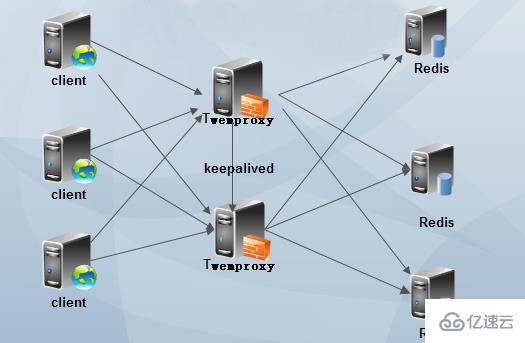
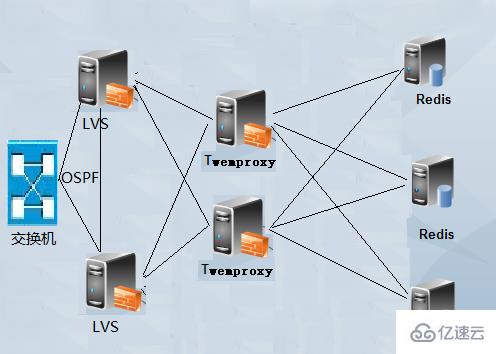
Veuillez réécrire la déclaration suivante en une seule phrase : Clonez le référentiel twemproxy sur votre machine locale à l'aide de la commande suivante : git clone https://github.com/twitter/twemproxy.git Après réécriture : Utilisez la commande suivante sur votre ordinateur local : git clone https://github.com/twitter/twemproxy.git pour cloner le référentiel twemproxy
2 Installez Twemproxy
Twemproxy doit utiliser Autoconf pour la compilation et la configuration. GNU Autoconf est un outil permettant de créer des scripts de configuration pour compiler, installer et empaqueter des logiciels sous le shell Bourne. Autoconf n'est pas limité par le langage de programmation et est couramment utilisé en C, C++, Erlang et Objective-C. Un script de configuration contrôle l'installation d'un progiciel sur un système spécifique. En exécutant une série de tests, le script de configuration génère le makefile et les fichiers d'en-tête à partir du modèle et ajuste le package si nécessaire pour l'adapter au système spécifique. Autoconf, avec Automake et Libtool, forment le GNU Build System. Autoconf a été écrit par David McKenzie à l'été 1991 pour soutenir son travail de programmation à la Free Software Foundation. Autoconf a incorporé un code amélioré écrit par plusieurs personnes et est devenu le logiciel de compilation et de configuration gratuit le plus utilisé.
Commençons par utiliser autoreconf pour compiler et configurer twemproxy :
[root@www twemproxy]# autoreconfconfigure.ac:8: error: Autoconf version 2.64 or higher is required configure.ac:8: the top level autom4te: /usr/bin/m4 failed with exit status: 63 aclocal: autom4te failed with exit status: 63 autoreconf: aclocal failed with exit status: 63 [root@www twemproxy]# autoconf --versionautoconf (GNU Autoconf) 2.63
Cela indique que la version d'autoreconf est trop basse. La version autoconf 2.63 est utilisée ci-dessus, téléchargeons donc la version autoconf 2.69 pour la compilation et l'installation. Notez que si vous utilisez CentOS6, votre version par défaut est 2.63. Si vous êtes CentOS7, votre version par défaut doit être 2.69. Si vous utilisez Debian8 ou Ubuntu16, votre version par défaut doit également être 2.69. Quoi qu'il en soit, si une erreur est signalée lors de l'exécution d'autoreconf, cela signifie que la version est ancienne et doit être compilée et installée.
Compilez et installez Autoconf
[root@www ~]# wget http://ftp.gnu.org/gnu/autoconf/autoconf-2.69.tar.gz[root@www ~]# tar xvf autoconf-2.69.tar.gz[root@www ~]# cd autoconf-2.69[root@www autoconf-2.69]# ./configure --prefix=/usr[root@www autoconf-2.69]# make && make install[root@www autoconf-2.69]# autoconf --versionautoconf (GNU Autoconf) 2.69
Compilez et installez Twemproxy
[root@www ~]# cd /root/twemproxy/[root@www twemproxy]# autoreconf -fvi[root@www twemproxy]# ./configure --prefix=/etc/twemproxy CFLAGS="-DGRACEFUL -g -O2" --enable-debug=full[root@www twemproxy]# make && make install
Si autoreconf -fvi signale l'erreur suivante, cela signifie que vous devez installer l'outil libtool et vous fier à libtool (s'il s'agit de CentOS, utilisez simplement yum install libtool directement, s'il s'agit de Debian, utilisez apt - installez simplement libtool).
autoreconf: Entering directory `.'
autoreconf: configure.ac: not using Gettext
autoreconf: running: aclocal --force -I m4
autoreconf: configure.ac: tracing
autoreconf: configure.ac: adding subdirectory contrib/yaml-0.1.4 to autoreconf
autoreconf: Entering directory `contrib/yaml-0.1.4'autoreconf: configure.ac: not using Autoconf
autoreconf: Leaving directory `contrib/yaml-0.1.4'
autoreconf: configure.ac: not using Libtool
autoreconf: running: /usr/bin/autoconf --force
configure.ac:36: error: possibly undefined macro: AC_PROG_LIBTOOL
If this token and others are legitimate, please use m4_pattern_allow.
See the Autoconf documentation.
autoreconf: /usr/bin/autoconf failed with exit status: 1Twemproxy ajoute un fichier de configuration
[root@www twemproxy]# mkdir /etc/twemproxy/conf[root@www twemproxy]# cat /etc/twemproxy/conf/nutcracker.ymlredis-cluster: listen: 0.0.0.0:22122 hash: fnv1a_64 distribution: ketama timeout: 400 backlog: 65535 preconnect: true redis: true server_connections: 1 auto_eject_hosts: true server_retry_timeout: 60000 server_failure_limit: 3 servers: - 172.16.0.172:6546:1 redis01 - 172.16.0.172:6547:1 redis02
Introduction aux options de configuration :
redis-cluster : donnez un nom à ce segment de configuration, il peut y avoir plusieurs segments de configuration
listen : définissez l'adresse IP et le port de surveillance
hash ; La fonction de hachage spécifique prend en charge plus de dix types de md5, crc16, crc32, finv1a_32, fnv1a_64, hsieh, murmur, jenkins, etc. Généralement, fnv1a_64 peut être utilisé, et la valeur par défaut est fnv1a_64
Réécriture : utilisez la fonction hash_tag pour ; ajuster la fonction en fonction d'une clé Calcule partiellement la valeur de hachage de la clé. Hash_tag se compose de deux caractères, l'un est le début de hash_tag et l'autre est la fin de hash_tag se trouve la partie qui sera utilisée pour calculer la valeur de hachage de la clé, et le résultat calculé sera. être utilisé pour sélectionner le serveur. Par exemple : si hash_tag est défini comme "{}", alors les valeurs de hachage avec les valeurs clésde "user:{user1}:ids" et "user:{user1}:tweets" sont basées sur " user1" et sera éventuellement mappé sur le même serveur. Et "user:user1:ids" utilisera la clé entière pour calculer le hachage, qui peut être mappé sur différents serveurs.
distribution : Spécifiez l'algorithme de hachage. Cet algorithme de hachage détermine comment les clés hachées ci-dessus sont distribuées sur plusieurs serveurs. La valeur par défaut est le hachage cohérent "ketama". ketama : L'algorithme de hachage cohérent ketama construira un anneau de hachage basé sur le serveur et allouera des plages de hachage aux nœuds de l'anneau. L'avantage de ketama est qu'après l'ajout ou la suppression d'un seul nœud, les valeurs clés mises en cache dans l'ensemble du cluster peuvent être réutilisées au maximum. Modula : Modula est très simple. Il prend le modulo en fonction de la valeur de hachage de la valeur clé et sélectionne le serveur correspondant en fonction du résultat modulo. Aléatoire : aléatoire signifie que quel que soit le hachage de la valeur clé, un serveur est sélectionné au hasard comme cible de l'opération sur la valeur clé.
timeout : définissez le délai d'expiration de twemproxy. Lorsque le délai d'attente est défini, si aucune réponse n'est reçue du serveur après le délai d'attente, le message d'erreur de délai d'attente SERVER_ERROR Connection time out sera envoyé au client
backlog : Surveillance de la longueur. du backlog TCP (file d'attente de connexion), la valeur par défaut est 512.
preconnect : Spécifiez si twemproxy établira des connexions avec tous les redis au démarrage du système. La valeur par défaut est false, une valeur booléenne ;
redis : Spécifiez si cette section de configuration doit être utilisée comme proxy pour Redis. , c'est vrai. Vous pouvez agir en tant que proxy pour le cluster memcached (c'est la seule différence entre Twemproxy en tant que proxy de cluster redis ou memcached) : si votre backend Redis a l'authentification activée, alors vous avez besoin de redis_auth ; spécifiez le mot de passe d'authentification ;
server_connections : Le nombre de connexions entre twemproxy et chaque serveur redis est de 1 par défaut. S'il est supérieur à 1, les commandes utilisateur peuvent être envoyées à différentes connexions, ce qui peut entraîner l'ordre d'exécution réel des commandes. être incohérent avec l'utilisateur spécifié (similaire à la concurrence) ;
auto_eject_hosts : si Eliminate lorsque le nœud ne peut pas répondre. Cependant, il convient de noter qu'après l'élimination du nœud, car le nombre de machines diminue et. la position du hachage de la machine change, certaines touches ne seront pas touchées. Cependant, si la connexion au programme n'est pas éliminée, une erreur sera signalée
server_retry_timeout : Contrôle l'intervalle de temps de connexion au serveur, en millisecondes. défini sur true. La valeur par défaut est 30 000 millisecondes ;
server_failure_limit:Redis连续超时的次数,超过这个次数就视其为无法连接,如果auto_eject_hosts设置为true,那么此Redis会被移除;
servers:一个pool中的服务器的地址、端口和权重的列表,包括一个可选的服务器的名字,如果提供服务器的名字,将会使用它决定server的次序,从而提供对应的一致性hash的hash ring。否则,将使用server被定义的次序,可以通过两种字符串格式指定’host:port:weight’或者’host:port:weight name’。一般都是使用第二种别名的方式,这样当其中某个Redis节点出现问题时,可以直接添加一个新的Redis节点但服务器名字不要改变,这样twemproxy还是使用相同的服务器名称进行hash ring,所以其他数据节点的数据不会出现问题(只有挂点的机器数据丢失)。
PS:要严格按照Twemproxy配置文件的格式来,不然就会有语法错误;另外,在Twemproxy的配置文件中可以同时设置代理Redis集群或Memcached集群,只需要定义不同的配置段即可。
启动twemproxy (nutcracker)
刚已经加好了配置文件,现在测试下配置文件:
[root@www twemproxy]# /etc/twemproxy/sbin/nutcracker -tnutcracker: configuration file 'conf/nutcracker.yml' syntax is ok
说明配置文件已经成功,现在开始运行nutcracker:
[root@www ~]# /etc/twemproxy/sbin/nutcracker -c /etc/twemproxy/conf/nutcracker.yml -p /var/run/nutcracker.pid -o /var/log/nutcracker.log -d选项说明: -h, –help #查看帮助文档,显示命令选项;-V, –version #查看nutcracker版本;-c, –conf-file=S #指定配置文件路径 (default: conf/nutcracker.yml);-p, –pid-file=S #指定进程pid文件路径,默认关闭 (default: off);-o, –output=S #设置日志输出路径,默认为标准错误输出 (default: stderr);-d, –daemonize #以守护进程运行;-t, –test-conf #测试配置脚本的正确性;-D, –describe-stats #打印状态描述;-v, –verbosity=N #设置日志级别 (default: 5, min: 0, max: 11);-s, –stats-port=N #设置状态监控端口,默认22222 (default: 22222);-a, –stats-addr=S #设置状态监控IP,默认0.0.0.0 (default: 0.0.0.0);-i, –stats-interval=N #设置状态聚合间隔 (default: 30000 msec);-m, –mbuf-size=N #设置mbuf块大小,以bytes单位 (default: 16384 bytes);
PS:一般在生产环境中,都是使用进程管理工具来进行twemproxy的启动管理,如supervisor或pm2工具,避免当进程挂掉的时候能够自动拉起进程。
验证是否正常启动
[root@www ~]# ps aux | grep nutcrackerroot 20002 0.0 0.0 19312 916 ? Sl 18:48 0:00 /etc/twemproxy/sbin/nutcracker -c /etc/twemproxy/conf/nutcracker.yml -p /var/run/nutcracker.pid -o /var/log/nutcracker.log -d root 20006 0.0 0.0 103252 832 pts/0 S+ 18:48 0:00 grep nutcracker [root@www ~]# netstat -nplt | grep 22122tcp 0 0 0.0.0.0:22122 0.0.0.0:* LISTEN 20002/nutcracker
Twemproxy代理Redis集群
这里我们使用第一种方案在同一台主机上测试Twemproxy代理Redis集群,一个twemproxy和两个Redis节点(想添加更多的也可以)。Twemproxy就是用上面的配置了,下面只需要增加两个Redis节点。
安装配置Redis
在安装Redis之前,需要安装Redis的依赖程序tcl,如果不安装tcl在Redis执行make test的时候就会报错的哦。
[root@www ~]# yum install -y tcl[root@www ~]# wget https://github.com/antirez/redis/archive/3.2.0.tar.gz[root@www ~]# tar xvf 3.2.0.tar.gz -C /usr/local[root@www ~]# cd /usr/local/[root@www local]# mv redis-3.2.0 redis[root@www local]# cd redis[root@www redis]# make[root@www redis]# make test[root@www redis]# make install
配置两个Redis节点
[root@www ~]# mkdir /data/redis-6546[root@www ~]# mkdir /data/redis-6547[root@www ~]# cat /data/redis-6546/redis.confdaemonize yes pidfile /var/run/redis/redis-server.pid port 6546bind 0.0.0.0 loglevel notice logfile /var/log/redis/redis-6546.log [root@www ~]# cat /data/redis-6547/redis.confdaemonize yes pidfile /var/run/redis/redis-server.pid port 6547bind 0.0.0.0 loglevel notice logfile /var/log/redis/redis-6547.log
PS:简单提供两个Redis配置文件,如果开启了Redis认证,那么在twemproxy中也需要填写Redis密码。
启动两个Redis节点
[root@www ~]# /usr/local/redis/src/redis-server /data/redis-6546/redis.conf[root@www ~]# /usr/local/redis/src/redis-server /data/redis-6547/redis.conf[root@www ~]# ps aux | grep redisroot 23656 0.0 0.0 40204 3332 ? Ssl 20:14 0:00 redis-server 0.0.0.0:6546 root 24263 0.0 0.0 40204 3332 ? Ssl 20:16 0:00 redis-server 0.0.0.0:6547
验证Twemproxy读写数据
首先twemproxy配置项中servers的主机要配置正确,然后连接Twemproxy的22122端口即可测试。
[root@www ~]# redis-cli -p 22122127.0.0.1:22122> set key vlaue OK 127.0.0.1:22122> get key"vlaue"127.0.0.1:22122> FLUSHALL Error: Server closed the connection 127.0.0.1:22122> quit
上面我们set一个key,然后通过twemproxy也可以获取到数据,一切正常。但是在twemproxy中使用flushall命令就不行了,不支持。
然后我们去找分别连接两个redis节点,看看数据是否出现在某一个节点上了,如果有,就说明twemproxy正常运行了。
[root@www ~]# redis-cli -p 6546127.0.0.1:6546> get key (nil) 127.0.0.1:6546>
由上面的结果我们可以看到,数据存储到6547节点上了。目前没有很好的办法明确知道某个key存储到某个后端节点了。
如何Reload twemproxy?
Twemproxy没有为启动提供脚本,只能通过命令行参数启动。所以,无法使用对twemproxy进行reload的操作,在生产环境中,一个应用无法reload(重载配置文件)是一个灾难。当你对twemproxy进行增删节点时如果直接使用restart的话势必会影响线上的业务。所以最好的办法还是reload,既然twemproxy没有提供,那么可以使用kill命令带一个信号,然后跟上twemproxy主进程的进行号即可。
kill -SIGHUP PID
注意,PID就是twemproxy master进程。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!