
Maison >base de données >tutoriel mysql >Comment implémenter l'extraction aléatoire dans MySQL
Comment implémenter l'extraction aléatoire dans MySQL

- PHPzavant
- 2023-06-03 08:25:522099parcourir
1. Introduction
Il est désormais nécessaire de sélectionner au hasard trois mots à la fois dans une liste de mots.
L'instruction de création de table de cette table est la suivante :
mysql> Create table 'words'(
'id' int(11) not null auto_increment;
'word' varchar(64) default null;
primary key ('id')
) ENGINE=InnoDB;Ensuite, nous y insérons 10 000 lignes de données. Voyons ensuite comment en sélectionner au hasard 3 mots.
2. Table temporaire mémoire
Tout d'abord, on pense généralement à utiliser order by rand() pour implémenter cette logique :
mysql> select word from words order by rand() limit 3;
Bien que cette phrase Les mots sont simples, mais le processus d'exécution est plus compliqué. Nous utilisons expliquer pour voir l'exécution de l'instruction :

Using Temporary dans le champ Extra indique qu'une table temporaire doit être utilisée, et Using filesort indique qu'un tri est requis. C'est-à-dire qu'une opération de tri est nécessaire.
Pour les tables InnoDB, effectuer un tri complet des champs peut réduire l'accès au disque, il sera donc préféré.
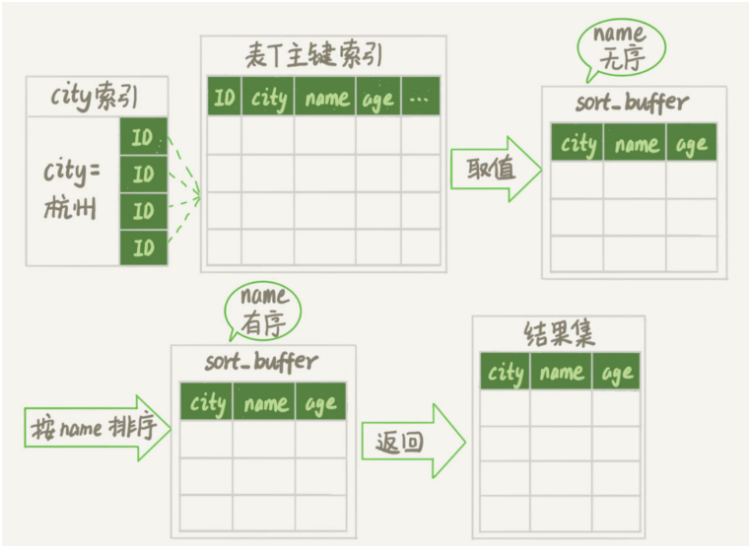
Pour les tables mémoire, le processus de retour de table accède simplement à la mémoire directement pour obtenir les données en fonction de l'emplacement des lignes de données. N'entraînera pas plusieurs accès au disque . Ainsi, à ce stade, MySQL donnera la priorité au tri des rowids.
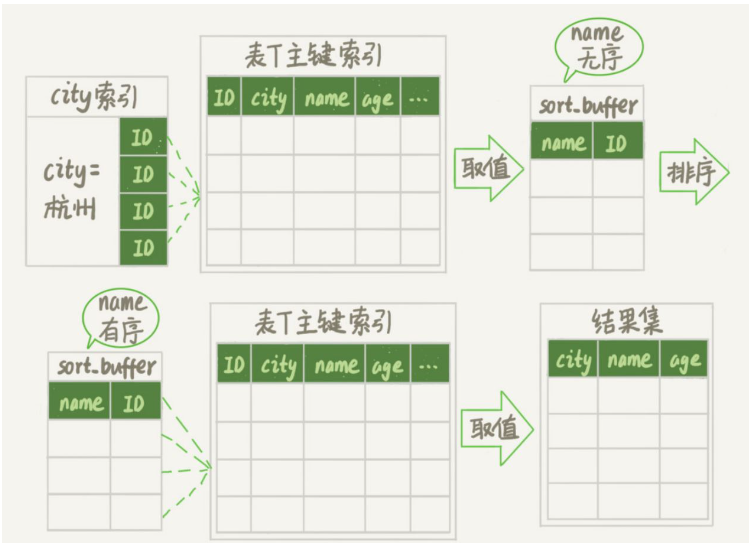
Voyons le processus d'exécution de cette instruction :
# 🎜🎜# Créez une table temporaire. Cette table utilise le moteur de mémoire Il y a deux champs dans la table. Le premier champ est de type double, enregistré sous la forme R, et le deuxième champ est de type varchar(64), enregistré sous la forme W. Et ce tableau n'a pas d'index.
- Dans le tableau des mots, supprimez tous les mots par ordre de clé primaire. Pour chaque mot, appelez la fonction rand() pour générer aléatoirement un nombre décimal aléatoire supérieur à 0 et inférieur à 1, et stockez le nombre décimal aléatoire et le mot dans les champs R et W de la table temporaire respectivement.
- La prochaine étape consiste à trier par champ R
- Initialiser sort_buffer. sort_buffer comprend un type double et un champ entier.
- Retirez la valeur R et les informations de position ligne par ligne de la table de mémoire temporaire et stockez-les respectivement dans les deux champs de sort_buffer.
- sort_buffer est trié en fonction de la valeur R
- Une fois le tri terminé, retirez l'emplacement informations des trois premiers résultats, récupérer le mot correspondant dans la table mémoire temporaire, et le renvoyer au client.
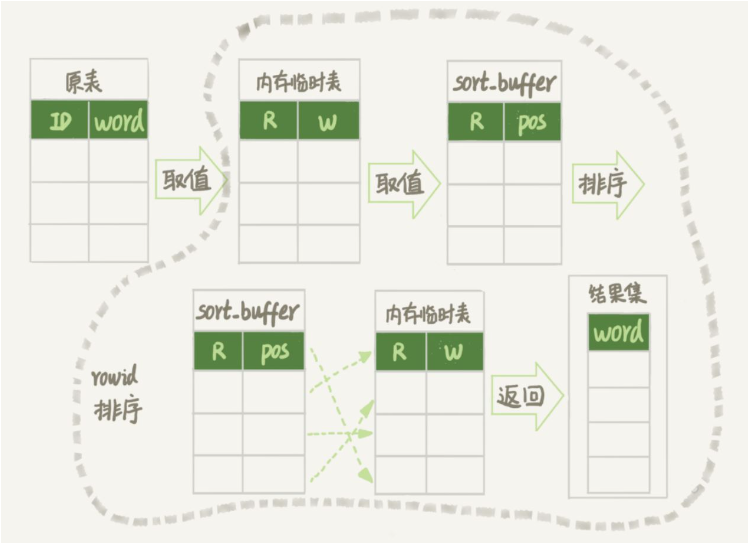
L'emplacement mentionné ci-dessus L'information est en fait l'emplacement de la ligne, qui est le rowid que nous avons mentionné précédemment.
Pour le moteur InnoDB, il existe deux manières de déterminer s'il existe une table de clé primaire :- Pour # 🎜 🎜#Table InnoDB avec clé primaire
, ce rowid est l'identifiant de la clé primaire
Pour - Table InnoDB sans clé primaire
Disons que ce rowid est généré par le système et est utilisé pour identifier différentes lignes.
Par conséquent,
3. Table temporaire de disque
Toutes les tables temporaires ne sont pas des tables temporaires en mémoire
. La configuration tmp_table_size limite la taille de la table temporaire mémoire Si cette taille est dépassée, la table temporaire du disque sera utilisée.Le moteur InnoDB utilise par défaut des tables temporaires de disque . 4. Algorithme de tri de file d'attente prioritaire
Après MySQL5.6, l'algorithme de tri de file d'attente prioritaire #🎜🎜 a été introduit. Cet algorithme ne nécessite pas l'utilisation de fichiers temporaires#. 🎜🎜#. L'algorithme de tri par fusion d'origine nécessite l'utilisation de fichiers temporaires. Parce que lorsque vous utilisez l'algorithme de fusion, vous n'avez en fait besoin que d'obtenir le top 3, mais si vous manquez de tri par fusion, tout est déjà en ordre, provoquant un gaspillage de ressources.L'algorithme de tri de la file d'attente prioritaire ne peut obtenir que les trois premiers. Le processus d'exécution est le suivant :
Pour ces 10 000 (R , rowid ), prenez d'abord les trois premières lignes, construisez un tas et placez la plus grande valeur en haut du tas, comparez avec le plus grand R du tas actuel, si R’ du tas et remplacez-le par (R’, rowid’).- Répétez le processus ci-dessus.
- Le processus est le suivant :
Mais lorsque le nombre limite est relativement large , il est difficile de maintenir le tas, c'est pourquoi l'algorithme de tri par fusion sera utilisé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!