
Maison >base de données >Redis >Comment utiliser Redis pour implémenter l'interface de recherche
Comment utiliser Redis pour implémenter l'interface de recherche

- 王林avant
- 2023-06-02 21:31:211110parcourir
Pour les développeurs back-end, un seul SQL peut être utilisé pour implémenter l'interface de requête de liste. Si les conditions de requête sont complexes et que la conception de la base de données de table est déraisonnable, la requête sera difficile. Cet article vous expliquera comment utiliser Redis. pour implémenter l'interface de recherche.
Commençons par un exemple. Il s'agit de la condition de recherche d'un site Web commercial. Si on vous demandait de mettre en œuvre une telle interface de recherche, comment la mettriez-vous en œuvre
Bien sûr, vous avez dit cela avec l'aide de moteurs de recherche, comme ? Elasticsearch, vous pouvez absolument le faire. Mais ce que je veux dire ici, c'est : et si vous souhaitez l'implémenter vous-même ?

Comme vous pouvez le voir sur l'image ci-dessus, la recherche est divisée en 6 catégories principales, et chaque catégorie principale est divisée en sous-catégories.
Dans ce cas, le processus de filtrage prend l'intersection de diverses grandes catégories de conditions et prend en compte la sélection unique, la sélection multiple et la personnalisation dans chaque sous-catégorie pour produire un ensemble de résultats qui répond aux conditions.
D’accord, maintenant que les exigences sont claires, commençons à les mettre en œuvre.
Mise en œuvre 1
Le premier à apparaître est l'étudiant A. Il est un "expert" en écriture SQL. Little A a dit avec assurance : « N'est-ce pas juste une interface de requête ? Il existe de nombreuses conditions, mais avec ma riche expérience SQL, ce n'est pas un problème pour moi. »
J'ai donc écrit l'extrait de code suivant (en prenant MySQL comme exemple ici) :
select ... from table_1 left join table_2 left join table_3 left join (select ... from table_x where ...) tmp_1 ... where ... order by ... limit m,n
Le code a été exécuté dans l'environnement de test et les résultats semblaient correspondre, il était donc prêt pour la pré-version. Avec ce pré-lancement, des problèmes ont commencé à apparaître.
La pré-version vise à rendre l'environnement en ligne aussi réaliste que possible, de sorte que la quantité de données est naturellement beaucoup plus importante que celle du test. Ainsi, pour un SQL aussi complexe, son efficacité d'exécution peut être imaginée. Le camarade de classe du test a tapé de manière décisive le code de Little A.
Mise en œuvre 2
Résumé les leçons tirées de l'échec de Little A. Little B a commencé à optimiser SQL. Tout d'abord, il a transmis le mot-clé expliquer pour effectuer une analyse des performances SQL et a ajouté des index aux endroits où les index ont été ajoutés.
Divisez un SQL complexe en plusieurs SQL en même temps, et les résultats du calcul sont calculés dans la mémoire du programme.
Le pseudo code est le suivant :
$result_1 = query('select ... from table_1 where ...');
$result_2 = query('select ... from table_2 where ...');
$result_3 = query('select ... from table_3 where ...');
...
$result = array_intersect($result_1, $result_2, $result_3, ...);
Cette solution est évidemment bien meilleure que la première en termes de performances, mais lors de l'acceptation de la fonction, le chef de produit a quand même estimé que la vitesse des requêtes n'était pas assez rapide.
Little B lui-même sait également que chaque requête interrogera la base de données plusieurs fois et, pour certaines raisons historiques, les requêtes sur une seule table ne peuvent pas être effectuées dans certaines conditions, le temps d'attente pour les requêtes est donc inévitable.
Implémentation 3
Little C voit une marge d'optimisation à partir de la solution ci-dessus. Il a constaté que Little B n'avait aucun problème avec sa réflexion. Il a divisé les conditions complexes, calculé les ensembles de résultats de chaque sous-dimension, et finalement résumé et fusionné tous les ensembles de sous-résultats pour obtenir le résultat final souhaité.
Il s'est donc soudainement demandé s'il pouvait mettre en cache les ensembles de résultats de chaque sous-dimension à l'avance. Cela lui permettrait de récupérer directement le sous-ensemble souhaité lors de l'interrogation, sans avoir à vérifier la base de données pour le calcul à chaque fois.
Little C utilise ici Redis pour stocker les données du cache. La principale raison de son utilisation est qu'il fournit une variété de structures de données et qu'il est très facile d'effectuer des opérations d'intersection et d'union sur des ensembles dans Redis.
Le plan spécifique est comme indiqué sur la figure :
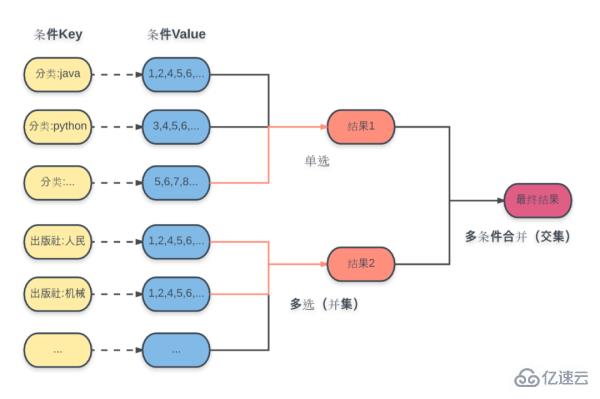
Pour chaque condition ici, l'ID de l'ensemble de résultats calculé est stocké à l'avance dans la clé correspondante et la structure de données sélectionnée est définie.
Les opérations de requête incluent :
Sélection radio de sous-catégorie : obtenez directement l'ensemble de résultats correspondant en fonction de la clé de condition.
Sélection multiple de sous-catégorie : effectuez une opération d'union basée sur plusieurs clés de condition pour obtenir l'ensemble de résultats correspondant.
Résultat final : effectuez une opération d'intersection sur tous les ensembles de résultats de sous-catégorie obtenus pour obtenir le résultat final.
C'est en fait ce qu'on appelle l'indice inversé. Vous constaterez ici qu'il manque une condition de prix. Il ressort de la demande que la condition de prix est une fourchette et qu’elle est infinie.
La méthode Key-Value mentionnée ci-dessus avec des conditions exhaustives n'est donc pas possible. Ici, nous utilisons la structure de données de l'ensemble commandé de Redis (Sorted Set) pour implémenter
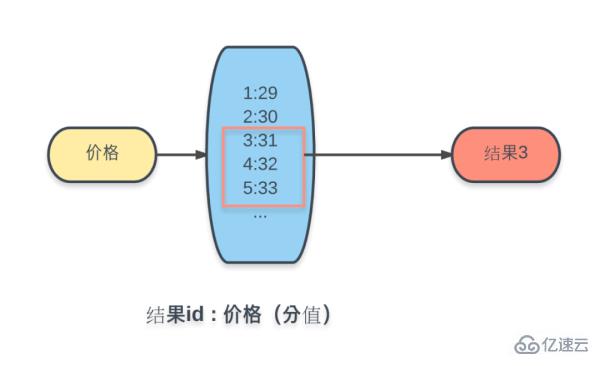
Ajouter tous les produits à l'ensemble commandé dont la clé est le prix, la valeur est l'ID du produit et chaque valeur correspond à Le score est la valeur numérique du prix du produit.
De cette façon, dans l'ensemble ordonné de Redis, vous pouvez utiliser la commande ZRANGEBYSCORE pour obtenir l'ensemble de résultats correspondant en fonction de la plage de scores (prix).
À ce stade, l'optimisation du plan 3 est terminée et la requête de données et le calcul ont été séparés via la mise en cache.
Chaque fois que vous effectuez une recherche, il vous suffit de rechercher Redis plusieurs fois pour obtenir le résultat. La vitesse des requêtes répond aux exigences d'acceptation.
Extension
①Paging
Vous avez peut-être découvert un grave défaut fonctionnel ici, comment une requête de liste peut-elle ne pas avoir de pagination. Oui, regardons tout de suite comment Redis implémente la pagination.
La pagination implique principalement du tri. Par souci de simplicité, prenons comme exemple le temps de création. Comme le montre la figure :
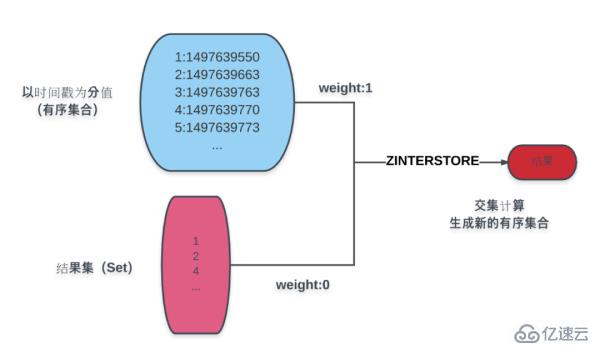
La partie bleue de la figure est une collection ordonnée de produits en fonction du temps de création. Le résultat défini sous le bleu est le résultat d'un calcul conditionnel. L'ensemble de résultats est attribué via la commande ZINTERSTORE. Le poids est 0, le résultat temporel du produit est 1 et l'ensemble de résultats obtenu en prenant l'intersection est donné pour créer un nouvel ensemble ordonné de scores temporels.
L'opération sur le nouvel ensemble de résultats permet d'obtenir les différentes données nécessaires à la pagination :
Le nombre total de pages est : commande ZCOUNT.
Contenu de la page actuelle : commande ZRANGE.
Si disposé dans l'ordre inverse : commande ZREVRANGE.
②Mise à jour des données
Concernant la question de la mise à jour des données d'index, il existe deux manières de procéder. L'une consiste à déclencher l'opération de mise à jour immédiatement via la modification des données du produit, et l'autre consiste à effectuer des mises à jour par lots via des scripts planifiés.
Il est à noter ici qu'en ce qui concerne la mise à jour du contenu de l'index, si vous supprimez la Clé violemment, alors réinitialisez la Clé.
Étant donné que les deux opérations dans Redis ne seront pas effectuées de manière atomique, il peut y avoir des écarts entre les deux. Il est recommandé de supprimer uniquement les éléments non valides de la collection et d'ajouter de nouveaux éléments.
③Optimisation des performances
Redis est une opération au niveau de la mémoire, donc une seule requête sera très rapide. Cependant, si plusieurs opérations Redis sont effectuées dans notre implémentation, les multiples temps de connexion Redis peuvent représenter une consommation de temps inutile.
En utilisant la commande MULTI, démarrez une transaction, regroupez plusieurs opérations Redis en une seule transaction et enfin effectuez une exécution atomique via EXEC.
Remarque : la soi-disant transaction ici n'exécute que plusieurs opérations en une seule connexion. Si un échec survient lors de l'exécution, elle ne sera pas annulée.
Résumé
Il s'agit simplement d'une simple démonstration utilisant Redis pour optimiser la recherche de requêtes. Par rapport aux moteurs de recherche open source existants, il est plus léger et le coût d'apprentissage est en conséquence inférieur.
Deuxièmement, certaines de ses idées sont similaires à celles des moteurs de recherche open source. Si l'analyse de mots est ajoutée, des fonctions similaires à la recherche en texte intégral peuvent également être obtenues.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!