
Maison >base de données >tutoriel mysql >Comment migrer le système sans capteur SQL Server vers MySQL
Comment migrer le système sans capteur SQL Server vers MySQL

- PHPzavant
- 2023-06-02 20:36:431027parcourir
1. Présentation de l'architecture
Grâce à l'analyse des goulots d'étranglement du système existant, nous avons constaté que les principaux défauts sont concentrés dans le cache de données de commande dispersées, ce qui entraîne une incohérence à toutes les extrémités des données et une connexion directe entre chacune d'elles. l'application de commande et la base de données, ce qui entraîne une mauvaise évolutivité. Grâce à la pratique, nous avons écrit un middleware pour résumer et unifier la couche d'accès aux données, et construit un cache de commandes basé sur le miroir de l'architecture de déploiement de base de données pour gérer uniformément les données chaudes, résolvant ainsi les différences entre les différentes extrémités.
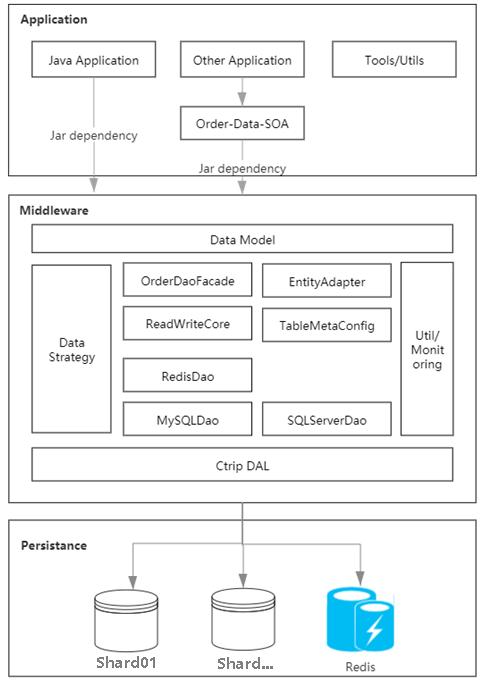
Figure 1.1 Schéma de l'architecture du système de stockage
2. Scénarios d'application
1. Nouvelle synchronisation de niveau d'une seconde de chaque extrémité
La vitesse entre la soumission de la commande et la visibilité à chaque extrémité est l'un des principaux indicateurs du service de stockage. Nous Les principaux maillons de la chaîne de données ont été optimisés, couvrant la synchronisation des nouvelles commandes, l'envoi de messages en temps réel, la construction d'index de requêtes et l'archivage hors ligne de la plate-forme de données, etc., de sorte que la vitesse d'arrivée des données dans le grand système soit dans les 3 secondes, c'est-à-dire que l'utilisateur vient de passer une commande. Cela passera à la liste visible de ma portabilité.
Lorsqu'un nouvel utilisateur crée une commande, le service de synchronisation sert d'entrée de liaison de données pour écrire les données de commande de l'utilisateur dans la bibliothèque de commandes via le middleware. À ce stade, le middleware termine en même temps la construction du cache de commande.
Lorsque la commande termine la construction du comportement d'entreposage et des données de point d'accès, les informations de commande sont ensuite vidées et transmises à chaque sous-système en temps réel
Lorsque la nouvelle commande est saisie dans la base de données, un index ES des détails de la commande est immédiatement généré ; construite pour fournir un support de récupération à des tiers ;
Enfin, la plateforme de données T+1 met en œuvre l'archivage et la fourniture de données au jour le jour. Utilisée pour diverses activités hors ligne telles que la BI.
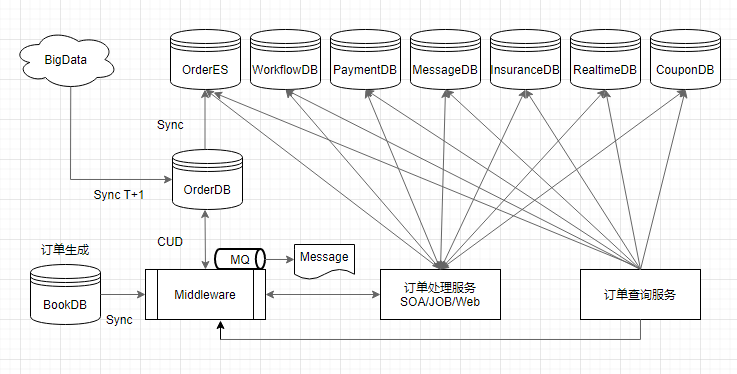
Figure 2.1 Lien de données
2. Émission automatique des commandes et établi
La prise en charge des clients, des commerçants et de l'établi des employés est le rôle de base du système de stockage des commandes. La connexion entre l’émission automatique des ordres et le workbench est indispensable. La commande automatique est le processus d'envoi des détails de la commande au commerçant le plus rapidement possible après que le client a soumis la commande pour vérifier l'inventaire et confirmer la commande. L'atelier aide les employés à obtenir des commandes et à traiter les événements manuels en temps opportun.
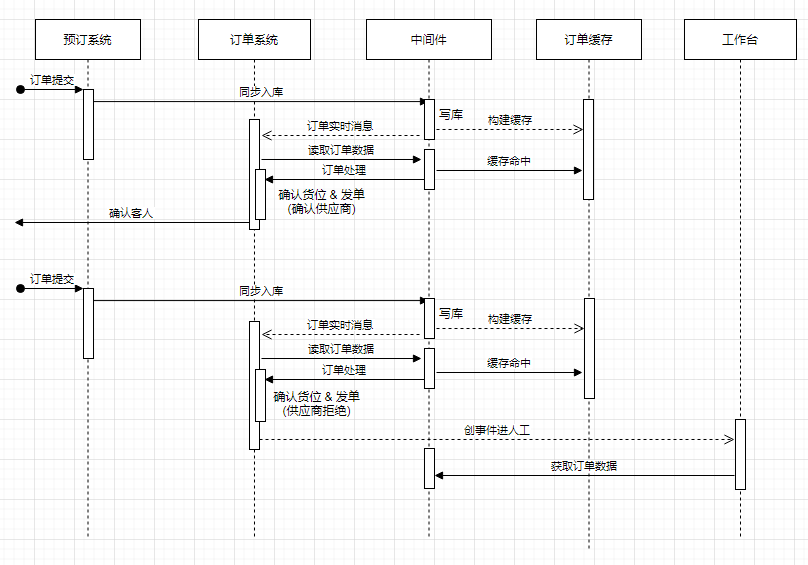
Figure 2.2 La relation entre l'émission des commandes et l'établi basé sur le système de stockage (détails abrégés)
3. Requête et analyse des données
Basé sur les données de commande comme noyau, il est principalement divisé en deux secteurs d'activité : en ligne. requêtes et analyse des données En prenant comme exemple une requête détaillée, le QPS d'accès reste à un niveau élevé toute l'année, et il est facile de provoquer des goulots d'étranglement lors des pics de vacances. Après l'examen des causes profondes, nous avons apporté des ajustements à cette mise à niveau de l'architecture pour l'optimiser. la haute disponibilité des scénarios associés.
La requête en ligne est principalement basée sur la mise en cache des commandes. Un cache hotspot est construit lors de la soumission de la commande pour soulager la pression des requêtes, et il peut être valide pendant une longue période en fonction des paramètres de temps configurés.
Les scénarios de requêtes non en ligne sont transmis via des messages en temps réel et combinés avec le mode T+1 de l'entrepôt de données Hive. Toute occasion nécessitant des données de commande à long terme (telles que des rapports en temps réel) peut accéder aux messages de commande. calcul en temps réel. Lors de l'analyse de données à grande échelle, la BI hors ligne utilisera les tables Hive et effectuera la synchronisation des données via un accès basse fréquence à partir de la base de données pendant la période de faible pointe, tôt le matin, chaque jour.
De cette façon, nous protégeons l'accès à la base de données principale des commandes derrière la troïka du cache de commandes, de la messagerie en temps réel et de l'entrepôt de données Hive, et nous la dissocions autant que possible de l'entreprise.
3. Pratique de mise à niveau du système
Dans le processus de mise à niveau du système de stockage principal de Ctrip, ce qui doit être fait tout au long du processus est une migration en direct, et l'objectif de rendre toutes les opérations transparentes et sans perte pour les applications sur la liaison de données est atteint. Notre conception analyse de manière exhaustive les caractéristiques des liaisons de données du groupe. Le système de cache de commande fournit une mise en miroir de la base de données pour réduire le couplage direct entre l'application et la base de données. Ensuite, le middleware est utilisé pour supprimer de manière transparente la relation physique entre les données provenant de SQLServer/. MySQL et fournit la couche sous-jacente à l'application. Espace d'opération pour la migration en direct.
Combiné à la conception du processus de migration sans perte, il se concentre sur la visibilité et la contrôlabilité du trafic de chaque base de données, prend en charge les stratégies de distribution du trafic au niveau de la base de données complète, au niveau du fragment, au niveau de la table et au niveau des opérations CRUD, et fournit des moyens de mise en œuvre suffisants pour les opérations sous-jacentes. migration de données. La conception de la connexion à l'entrepôt de données se concentre sur la résolution du problème de synchronisation entre les dizaines de milliards de données hors ligne sur la plate-forme de données et la période en ligne de la double base de données, ainsi que sur la résolution des problèmes de données qui surviennent lors d'un accès complet à MySQL.
Ce qui suit sera divisé en trois parties pour partager les expériences que nous avons apprises au cours de ce processus.
1. Mise en cache des commandes distribuées
Avec le développement commercial, le nombre d'utilisateurs et de visites augmente, et la pression sur les applications et les serveurs du système de commande augmente également. Avant l'introduction de la mise en cache des commandes, chaque application se connectait à la base de données de manière indépendante, ce qui empêchait le partage des données interrogées entre les applications, et il y avait une limite supérieure au nombre de requêtes et de connexions à la base de données par seconde. Cependant, la transaction principale de l'hôtel. le lien était basé sur le stockage de base de données et il n'y avait qu'un seul risque de défaillance ponctuelle.
Après l'analyse des données, le système de commande lit généralement plus et écrit moins. Afin de partager les données des requêtes chaudes et de réduire la charge de la base de données, un moyen efficace consiste à introduire un cache, comme le montre la figure 3.1. Lorsque la demande de l'utilisateur arrive, la requête est prioritaire. Cache, s'il y a des données en cache, le résultat sera renvoyé directement ; s'il n'y a aucun résultat dans le cache, la base de données sera interrogée et les données du résultat de la base de données seront vérifiées conformément à la politique de configuration. Si la vérification réussit, les données de la base de données seront écrites dans le cache pour une utilisation de requête ultérieure, sinon elles ne seront pas écrites dans le cache et renverront finalement les résultats de la requête DB.

Figure 3.1 Conception de base du cache de commandes
Concernant la surcharge matérielle après l'introduction de nouveaux composants de mise en cache, les différents composants d'origine les composants peuvent être convergés. Appliquez des ressources matérielles décentralisées pour réduire le coût total, mais la gestion centralisée entraînera également des problèmes de disponibilité et de cohérence des données. Par conséquent, il est nécessaire de procéder pleinement à l'évaluation de la capacité, à l'estimation du trafic et à l'analyse de la valeur de la table de cache du système existant. Mettre en cache uniquement les tables de données chaudes avec un volume d'accès élevé. Grâce à une conception appropriée de la structure du cache, à des stratégies de compression des données et d'élimination du cache, nous pouvons maximiser le taux de réussite du cache et faire un bon compromis entre la capacité du cache, le coût du matériel et la disponibilité.
La conception traditionnelle du cache est qu'un enregistrement de table de base de données correspond à une donnée du cache. Dans le système de commande, il est très courant d'interroger plusieurs tables pour une seule commande. Si une conception traditionnelle est utilisée, le nombre d'accès Redis dans une requête utilisateur augmente avec le nombre de tables. Cette conception a des E/S réseau plus importantes et prend plus de temps. -consommer longtemps. Lors de l'inventaire des données de trafic des dimensions des tables, nous avons constaté que certaines tables sont souvent interrogées ensemble et que moins de 30 % des tables représentent plus de 90 % du trafic des requêtes. En termes d'activité, elles peuvent être divisées en une seule. modèle de domaine abstrait, puis stocké sur la base de la structure de hachage, comme la figure 3.2 utilise le numéro de commande comme clé, le nom du champ comme champ et les données du champ comme valeur.
De cette façon, qu'il s'agisse d'une requête monotable ou multi-tables, chaque commande n'a besoin d'accéder à Redis qu'une seule fois, ce qui réduit la clé, réduit le nombre de requêtes multi-tables et améliore les performances . Dans le même temps, la valeur est compressée en fonction du protostuff, ce qui réduit également l'espace de stockage de Redis et la surcharge de trafic réseau qui en résulte.

Figure 3.2 Brève description de la structure de stockage basée sur le domaine
2. # Comment réaliser une migration à chaud sans perte est l'aspect le plus difficile de l'ensemble du projet. Notre travail préparatoire consiste d'abord à terminer le développement du middleware, dans le but de séparer les applications de base de données et de couche métier, afin que la conception des processus puisse être réalisée. Deuxièmement, la couche abstraite Dao implémente la domaineisation et la couche de domaine de données fournit des services de données aux applications. Sous le domaine, deux bases de données, SQLServer et MySQL, sont adaptées et packagées de manière uniforme. Sur cette base, une migration thermique sans perte peut être mise en œuvre pour la conception de processus suivante.
- Les doubles bases de données SQLServer et MySQL sont en ligne, la double écriture est implémentée, SQLServer est le rédacteur principal et MySQL est synchronisé en tant que rédacteur secondaire si l'opération SQLServer échoue. , l'ensemble de l'opération échoue et la transaction de double écriture est annulée.
- Ajouter un travail de synchronisation entre SQLServer et MySQL pour interroger les données modifiées dans la fenêtre horaire récente de SQLServer en temps réel pour vérifier la cohérence des entrées dans MySQL et rattraper son retard sur les différences. Cela peut garantir des incohérences inattendues des deux côtés lors d'une double écriture, ce qui est particulièrement utile lorsqu'il y a encore une écriture directe dans l'application SQL Server.
- Le middleware est conçu avec un système de configuration qui prend en charge toute dimension de requête majeure et peut diriger avec précision la source de données vers SQLServer ou MySQL en fonction de la configuration, et peut contrôler si pour lire le cache Charger dans la commande. Le paramètre initial consiste à charger uniquement la source de données SQLServer pour éviter les sauts de données du cache causés par des incohérences de données entre les deux bases de données. Dans la phase initiale, des niveaux de gris peuvent être configurés et un petit nombre de tables non principales peuvent être connectées directement à MySQL pour vérification afin de garantir la fiabilité. Une fois que l'attente de cohérence des données tardives est atteinte, le cache de commande peut être chargé à volonté sur la base de données spécifiée.
- Après avoir assuré la cohérence des données lors de l'interrogation des données, la politique de trafic prend en charge l'écriture unique dans la base de données selon toute dimension contrôlable dans la figure 3.3. Dans les projets réels, l'écriture unique est principalement implémentée dans les dimensions de table. Lorsqu'une table spécifiée est configurée avec MySQL à écriture unique, tous les comportements CRUD impliquant la table sont dirigés vers MySQL, y compris la source de chargement du cache.
- Enfin, les messages de commande envoyés au monde extérieur sont unifiés via le middleware. Tous les messages sont envoyés en fonction du fonctionnement CUD du middleware et n'ont rien à voir avec. la base de données physique, de sorte que la source de données du message soit transparente et qu'elle puisse relier toutes les opérations de processus ci-dessus et que la chaîne de données reste cohérente.
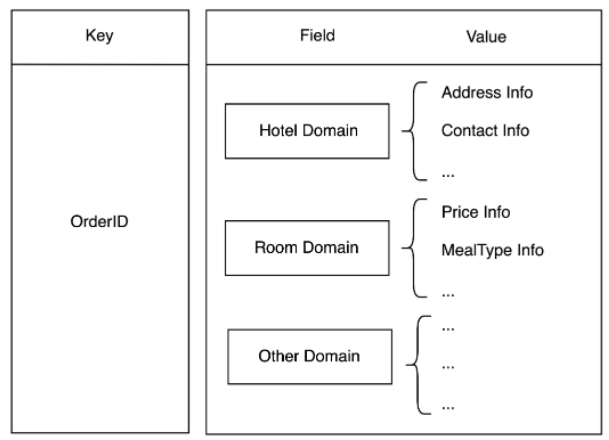 Figure 3.3 Introduction au processus d'exploitation
Figure 3.3 Introduction au processus d'exploitation
3. 🎜#
Afin de faciliter la compréhension de la migration des données de production vers les données de la couche ODS de l'entrepôt de données et de la rendre transparente vers l'aval, voici une brève introduction au système hiérarchique des entrepôts de données classiques. Habituellement, l'entrepôt de données est principalement divisé en cinq couches : ODS (couche de données d'origine), DIM (dimension), EDW (entrepôt de données d'entreprise), CDM (couche de modèle commun), ADM (couche de modèle d'application),#🎜 🎜#
Comme le montre l'image ci-dessous :
Figure 3.4 Structure hiérarchique de l'entrepôt de données
Comme le montre la figure 3.4, chaque couche de l'entrepôt de données s'appuie sur les données de la couche ODS. Afin de ne pas affecter toutes les applications de la plateforme de données, il suffit de transférer les données. Base de données de commande originale Source de données de la couche ODS de SQL Server Il suffit de migrer vers la bibliothèque MySQL.
On peut voir intuitivement sur l'image qu'il n'est pas très gênant de migrer simplement en changeant la source de données. Cependant, afin de garantir la qualité des données, nous avons effectué de nombreux pré-travail, tels que : DBA synchronise. les données de production vers la base de données MySQL de production, MySQL à l'avance Synchronisation des données en temps réel, vérification de la cohérence des données des deux côtés de la production, synchronisation des données côté MySQL avec la couche ODS, vérification de la cohérence des données de la couche ODS et commutation de la source de données du travail de synchronisation de la couche ODS d'origine, etc.
Parmi eux, le contrôle de cohérence des données des deux côtés de la production et le contrôle de cohérence des données sur la couche ODS de l'entrepôt de données sont les plus complexes et les plus longs. La source de données ne doit être changée que lorsque chaque table et champ le doivent. être cohérent. Cependant, en fonctionnement réel, cela ne peut pas être totalement cohérent. En fonction de la situation réelle, gérez de manière appropriée le type d'heure, la précision de la valeur à virgule flottante et les décimales, etc.
Ce qui suit est une introduction au processus global :
Tout d'abord, pour la vérification de la cohérence des données en ligne, nous avons développé un travail de synchronisation en ligne pour comparer les données SQLServer et les données MySQL. Lorsque des incohérences sont détectées, les données MySQL sont détectées. Les données sont mises à jour comme référence pour garantir la cohérence des données des deux côtés.
Deuxièmement, pour la vérification de la cohérence des données hors ligne, nous avons coopéré avec des collègues de l'entrepôt de données pour synchroniser les données secondaires MySQL avec la couche ODS (utilisez le nom de la base de données pour distinguer s'il s'agit d'une table SQLServer ou MySQL) et mettre les tâches planifiées et SQLServer tâches secondaires dans Essayez d'être cohérent dans le temps. Une fois les données des deux côtés préparées, nous avons développé un générateur de script de vérification des données hors ligne. Basé sur les métadonnées de l'entrepôt de données, une tâche de synchronisation a été générée pour chaque table et déployée sur la plateforme de planification.
La tâche de synchronisation s'appuiera sur les données de synchronisation des couches ODS des deux côtés. Une fois la synchronisation des données T+1 terminée, un contrôle de cohérence sera effectué, les numéros de commande incohérents seront enregistrés dans le tableau des détails incohérents, le La quantité de données incohérentes sera comptée et les résultats seront enregistrés dans le tableau des statistiques. Ensuite, nous créons un rapport sur la plateforme de reporting en libre-service et envoyons les statistiques quotidiennes des tableaux incohérents et le nombre d'incohérences à la boîte aux lettres. Nous résolvons chaque jour les tableaux incohérents pour détecter les problèmes, ajuster la stratégie de comparaison et mettre à jour la comparaison. emploi. Le processus général est le suivant :
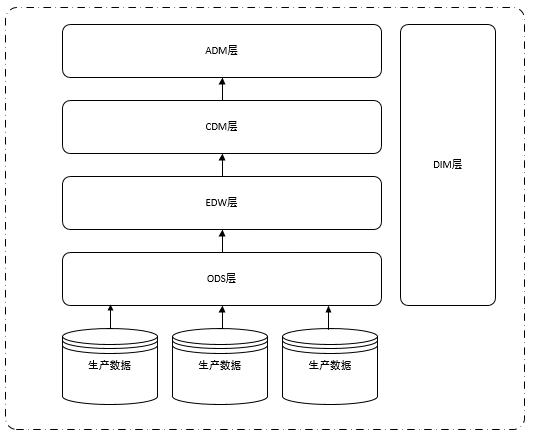
Figure 3.5 Le processus global de vérification de la cohérence
Enfin, à mesure que les données en ligne et hors ligne deviennent progressivement cohérentes, nous avons basculé la source de données que le serveur SQL d'origine a synchronisée avec le travail de la couche ODS vers MySQL. . Certains étudiants ici peuvent avoir des questions : Pourquoi ne pas utiliser directement les tables de la couche ODS côté MySQL ? La raison en est que, selon les statistiques, des milliers de tâches dépendent de la table de couche ODS d'origine. Si le travail dépendant est basculé vers la table ODS côté MySQL, la charge de travail de modification sera très lourde, nous basculons donc directement sur l'ODS d'origine. source de données de synchronisation de couches dans MySQL.
En fonctionnement réel, la découpe des sources de données ne peut pas être effectuée en une seule fois. Nous le faisons en trois lots. Nous trouvons d'abord une douzaine de tables moins importantes que le premier lot, nous l'exécutons pendant deux semaines et collectons les problèmes en aval. données. Le premier lot d'échantillons a été analysé avec succès deux semaines plus tard et nous n'avons reçu aucun problème de données dans les rapports en aval, ce qui prouve la fiabilité de la qualité des données d'échantillon. Divisez ensuite les centaines de tables restantes en deux lots selon leur importance et continuez à découper jusqu'à ce qu'elles soient terminées.
À ce stade, nous avons terminé la migration de la base de données des commandes de SQLServer vers MySQL au niveau de la couche entrepôt de données.
4. Problèmes fondamentaux raffinés
En fait, quelle que soit la rigueur de l'analyse et de la conception, il est inévitable de rencontrer divers défis au cours du processus d'exécution. Nous avons résumé quelques problèmes classiques. Bien que ces grands et petits problèmes aient finalement été résolus par des moyens techniques et que les objectifs aient été atteints, je pense que vous, lecteurs, devez avoir de meilleures solutions. Nous sommes heureux d'apprendre et de progresser ensemble.
1. Comment affiner la surveillance de la migration du trafic SQLServer et MySQL
Le système de commande implique un grand nombre d'applications et de tables. Une application correspond à 1 à n tables, et une table correspond à 1 à n applications. est typique qu'il existe des relations plusieurs à plusieurs. Comme le montre la figure 4.1, pour les applications de couche supérieure, lors du passage d'une base de données SQLServer à une autre base de données MySQL, le processus de base est divisé en au moins les étapes suivantes selon le chapitre sur le processus de fonctionnement :
De SQLServer à écriture unique à SQLServer et MySQL à double écriture
De SQLServer à lecture unique à MySQL à lecture unique
De SQLServer et MySQL à double écriture à MySQL à écriture unique
SQLServer hors ligne

Figure 4.1 Application, base de données et tables Diagramme de relation
Remplacer le système de base de données dans l'environnement de production, c'est comme changer un pneu sur l'autoroute sans s'arrêter. La vitesse d'origine doit être maintenue et elle est insensible à l'utilisateur, sinon les conséquences ne peuvent pas être. imaginé.
Dans le processus de commutation, les processus de double écriture, de lecture simple et d'écriture unique s'emboîtent et dépendent les uns des autres étape par étape. En tant que méthode de suivi de la conception de support, il est nécessaire de confirmer que l'opération précédente produit l'effet escompté. avant de passer au suivant. Si vous sautez ou passez à l'étape suivante de manière imprudente sans changer proprement, par exemple, si vous commencez à lire les données MySQL avant que la double écriture ne soit complètement cohérente, cela peut entraîner la découverte de données introuvables ou de données sales ! Ensuite, il est nécessaire de surveiller la lecture et l'écriture de chaque opération CRUD et d'obtenir un contrôle visuel de la segmentation du trafic à 360 degrés sans angles morts pendant le processus de migration. La méthode spécifique est la suivante :
-
Toutes les applications sont connectées au middleware, et CRUD est contrôlé par le middleware pour lire et écrire quelle base de données et quelle table selon le configuration
#🎜 🎜# - Les informations détaillées de chaque opération de lecture et d'écriture sont écrites dans ES et affichées visuellement sur Kibana et Grafana, et grâce à DBTrace, vous pouvez savoir quelle base de données chaque SQL est exécuté le #🎜🎜 # Configurez étape par étape la base de données à double écriture en fonction du niveau de l'application, comparez, réparez et enregistrez les différences de base de données des deux côtés en temps réel via le travail de synchronisation, puis vérifiez les différences dans la double écriture via hors ligne T+1. Au final, elles étaient incohérentes, et ainsi de suite jusqu'à ce que les deux écritures soient cohérentes
- # ; 🎜🎜#Une fois les deux écritures cohérentes, j'ai commencé à passer progressivement de la lecture de SQLServer à la lecture de MySQL, et j'ai confirmé via la surveillance ES et DBTrace qu'il n'y avait aucun problème. La lecture à partir de SQLServer indique que la lecture unique de MySQL est terminée. Compte tenu de la situation des clés primaires auto-incrémentées, nous adoptons la méthode consistant à interrompre l'écriture sur SQLServer par lots en fonction de la dimension de la table jusqu'à ce que toutes les tables soient écrites uniquement sur MySQL.
- Pour résumer, le plan de base est d'utiliser un middleware pour enterrer le pipeline de toutes les applications connectées, et d'observer la répartition du trafic en affichant le comportement de la couche application dans en temps réel. Il combine également l'outil de visualisation Trace côté base de données de l'entreprise pour vérifier que le comportement de commutation du trafic de l'application est cohérent avec le QPS réel et la fluctuation de charge de la base de données afin de superviser la tâche de migration.
#🎜. 🎜#
Double Lors de l'écriture, seul SQLServer a été réellement écrit et MySQL a été omis
La double écriture de SQLServer et MySQL a réussi. Il est possible que les données MySQL soient utilisées en cas de concurrence, de réseau peu fiable, de GC, etc., incompatibles avec SQL Server.
Concernant la garantie de cohérence des données en double écriture, nous utilisons le travail de synchronisation pour aligner les données SQL Server et extraire les données de la base de données des deux côtés pour une comparaison basée sur heure de la dernière mise à jour, en cas d'incohérence, réparez les données MySQL et écrivez les informations incohérentes dans ES pour un dépannage ultérieur de la cause première.
Cependant, l'introduction de tâches supplémentaires pour exploiter les données MySQL a apporté de nouveaux problèmes, c'est-à-dire que lors de la double écriture de plusieurs tables, parce que la consommation de temps est doublée, la tâche découvre que SQLServer a des données mais MySQL en a. non. Les données MySQL ont été réparées immédiatement, provoquant un double échec d'écriture. Par conséquent, lorsque la partie de double écriture échoue, un mécanisme de basculement est ajouté pour déclencher une nouvelle série de travaux de comparaison et de réparation en envoyant des messages jusqu'à ce que les données de la base de données des deux côtés soient complètement cohérentes.
Bien que le mécanisme de message de tâche et de basculement synchronisé puisse finalement rendre les données cohérentes, il existe après tout un intervalle de deuxième niveau et les données des deux côtés sont incohérentes. Et pour divers scénarios de nombreuses applications, il est inévitable qu'il y ait des omissions. Écrivez SQLServer seul. Ces écritures manquées sur MySQL ne peuvent pas être trouvées via DBTrace car il ne peut pas être déterminé qu'une opération CUD est uniquement écrite sur SQLServer et non sur MySQL. Alors, existe-t-il un moyen de connaître à l'avance le scénario de MySQL manquant ? Nous avons découvert une chose, c'est-à-dire changer la chaîne de connexion à la base de données, utiliser la nouvelle chaîne de connexion pour l'application connectée au middleware, puis tout découvrir. Les opérations utilisant l'ancienne chaîne de connexion SQL Server peuvent localiser avec précision le trafic qui manque MySQL.
Au final, nous avons progressivement réduit le taux d'incohérence des bases de données en double écriture de 2/100 000 à presque 0. Pourquoi est-il presque ? Parce que certaines différences dans les caractéristiques de la base de données conduiront naturellement à des données incomplètes. cela sera discuté en détail dans le contenu suivant.
3. Gestion du problème de désynchronisation des données causé par l'introduction du cache de commande
Une fois le cache introduit, cela implique l'écriture ou la mise à jour du cache. dans l'industrie sont les suivants : Les éléments suivants :
Écrivez d'abord dans la base de données, puis dans le cache
Écrivez cachez d'abord, puis écrivez la base de données#🎜 🎜#
- Supprimez d'abord le cache, puis écrivez la base de données
- Écrivez la base de données d'abord, puis supprimez le cache
- Ne comparez plus les avantages et les inconvénients des différentes approches. Le cache à double suppression ou le cache à double suppression retardée peuvent être utilisés lors d'une implémentation spécifique. Nous adoptons un schéma consistant à écrire d'abord dans la base de données, puis à supprimer le cache. Pour les tables sensibles aux données, une double suppression retardée sera effectuée. Le travail de synchronisation en arrière-plan compare, répare et enregistre régulièrement les différences entre les données de la base de données et les données Redis. Bien que la conception puisse garantir la cohérence finale des performances, il y avait encore de nombreuses incohérences dans les données au début. Cela se reflète principalement dans les aspects suivants :
#🎜 🎜#
- Le délai de suppression du cache après l'écriture dans la base de données entraîne la lecture de données sales mises en cache, telles qu'un réseau peu fiable, un GC, etc., provoquant un retard de suppression du cache
- # ; 🎜🎜#
#🎜 🎜#L'échec de la suppression du cache après l'écriture dans la base de données entraîne la lecture des données sales mises en cache. Par exemple, lors de la commutation maître-esclave Redis, elles ne peuvent être lues mais pas écrites.
Afin de résoudre le problème de cohérence du cache, comme le montre la figure 4.2, nous avons ajouté des marqueurs de verrouillage optimiste et de construction CUD basés sur le cache d'origine et la base de données pour limiter l'existence simultanée dans les situations de concurrence. Le comportement de chargement des données dans le cache s'écrasant mutuellement, ainsi que la perception que les opérations CUD sont effectuées sur les données actuellement vérifiées. Le mécanisme gagnant du dernier écrivain basé sur le verrouillage optimiste peut être utilisé pour réaliser le trafic de requêtes afin de se connecter directement à la base de données et résoudre le problème de concurrence lorsque ces deux scénarios ne sont pas terminés. Au final, notre taux d'incohérence du cache a été contrôlé de 2 parties par million à 3 parties par 10 millions.

Figure 4.2 Solution de cohérence du cache
Figure 4.2 Lorsque la requête manque le cache ou qu'il existe actuellement un verrou optimiste pour les données ou la marque de construction, la requête en cours est directement connectée à la base de données et la fonction de chargement automatique des données mises en cache est libérée jusqu'à ce que la transaction concernée soit terminée.
4. Comment calibrer les données de commande de stock en une seule fois
Au début du projet, nous avons effectué une préparation unique des N dernières années de données pour MySQL, ce qui a entraîné l'étape de double écriture. Les données des deux scénarios suivants ne peuvent pas être calibrées :
Parce que la base de données des ordres de production est prédéfinie pour conserver les données pendant près de N ans, le travail responsable du nettoyage de la sauvegarde est connecté au middleware. Auparavant, ce lot de données qui existait dans MySQL depuis N ans ne pouvait pas être écrasé par la politique et nettoyé.
Il faut beaucoup de temps pour appliquer tous les middlewares de connexion. Les données peuvent être incohérentes avant de double-écrire le middleware. Il est nécessaire d'appliquer tous les middlewares de connexion et. écrivez deux fois toutes les tables. Enfin, effectuez une réparation unique des données précédentes.
Pour le premier point, nous avons développé un travail de nettoyage de données MySQL. Étant donné que la base de données de commande comporte plusieurs fragments, le nombre total de threads principaux est défini en interne dans le travail. sur le nombre réel de fragments. Chaque thread est responsable du nettoyage de la table spécifiée dans le fragment, et l'exécution de plusieurs serveurs en parallèle pour répartir les tâches de nettoyage garantit l'efficacité sans affecter la charge de la base de données de production.
Concernant le deuxième point, une fois que tous les middlewares de l'interface d'application et toutes les tables ont été doublement écrits, les données de commande existantes sont réparées en ajustant l'horodatage de début de l'analyse des tâches de synchronisation en ligne. Lors de la réparation, une attention particulière doit être accordée au fait que les données numérisées doivent être traitées par tranches selon des périodes de temps afin d'éviter qu'une trop grande quantité de données ne soit chargée, ce qui rendrait la commande CPU du serveur de base de données trop élevée.
5. Certaines bases de données présentent des différences
Si nous voulons effectuer une migration en direct de bases de données dans un système énorme, nous devons avoir une compréhension approfondie des similitudes et des différences entre les différentes bases de données , afin de résoudre efficacement le problème. Bien que MySQL et SQL Server soient tous deux des bases de données relationnelles populaires et prennent tous deux en charge les requêtes SQL standardisées, il existe encore quelques différences dans les détails. Examinons de plus près les problèmes rencontrés lors de la migration.
1) Problème de clé d'auto-incrémentation
Afin d'éviter des risques encore plus importants de réparation de données causées par des numéros de série d'auto-incrémentation incohérents, deux doivent être assurés. Les bases de données partagent le même numéro de séquence à incrémentation automatique. Par conséquent, chacun ne devrait pas être autorisé à effectuer des opérations d’auto-incrémentation. Par conséquent, lorsque les données sont écrites en double, nous réécrivons l'identifiant d'incrémentation automatique généré par SQLServer dans la colonne d'incrémentation automatique MySQL. Lorsque les données sont écrites sur MySQL uniquement, MySQL est utilisé pour générer directement la valeur de l'identifiant d'incrémentation automatique.
2) Problème d'exactitude de la date
Afin de garantir la cohérence des données après une double écriture, la cohérence des données des deux côtés doit être vérifiée . Tapez Pour les champs Date, DateTime et Timestamp, en raison d'une précision de stockage incohérente, un traitement spécial est requis lors de la comparaison et les champs sont interceptés en secondes à des fins de comparaison.
3) Problème de champ XML
Le type de données XML est pris en charge dans SQL Server, mais MySQL 5.7 ne prend pas en charge le type XML. Après avoir utilisé varchar(4000) à la place, j'ai rencontré un cas où l'écriture des données MySQL a échoué, mais le travail de synchronisation a pu réécrire normalement les données SQLServer sur MySQL. Après analyse, le programme écrira des chaînes XML non compressées lors de l'écriture. Le type XML SQLServer les compressera et les stockera automatiquement, mais pas MySQL. Par conséquent, l'opération d'écriture d'une longueur supérieure à 4000 échouera et la longueur après la compression SQLServer. est inférieur à 4000. et peut normalement réécrire sur MySQL. À cette fin, nous proposons des contre-mesures, notamment la compression et la vérification de la longueur avant l'écriture, l'interception des champs non importants avant de les stocker, l'optimisation de la structure de stockage des champs importants ou la modification des types de champs.
Voici quelques points communs à noter lors du processus de migration.

5. Pratique d'alerte précoce
Notre pratique d'alerte précoce ne se limite pas à surveiller les demandes pendant l'avancement du projet. analyse périodique de l'écriture de données au niveau du milliard, examen du taux de cohérence des données doublement écrites pendant l'achèvement du projet, comment surveiller en temps réel et avertir précocement la tendance normale du volume d'écriture de commandes sur chaque fragment du commander la bibliothèque et comment accepter/vérifier régulièrement l'ensemble du système. La haute disponibilité est décrite ci-dessous.
1. Des dizaines de milliards d'avertissements de vérification des différences de données
Pour répondre aux exigences de migration des données de commande SQLServer vers la base de données MySQL, la qualité des données est une condition nécessaire à la migration, et les données la cohérence ne peut pas être assurée Une migration transparente est impossible si les exigences sont remplies, la conception d'un système de vérification raisonnable est donc liée à la progression de la migration. Pour la vérification des données, nous les divisons en deux types : en ligne et hors ligne :
Vérification des données en ligne et alerte précoce
Pendant la migration, nous avons synchronisé la tâche, calculé les données incohérentes, écrit les tables et les champs incohérents dans ElasticSearch, puis utilisé Kibana pour créer le volume de données incohérentes et la proportion de tables incohérentes . Tableau de bord de surveillance, grâce au tableau de bord de surveillance, nous pouvons surveiller en temps réel les tables présentant des incohérences de données élevées, puis utiliser les outils DBA pour découvrir quelles applications ont effectué des opérations CUD sur les tables en fonction des noms de tables, et localiser davantage les applications et. codes qui manquent de middleware.
Dans les opérations réelles, nous avons trouvé un grand nombre d'applications qui n'étaient pas connectées au middleware et les avons transformées. À mesure que de plus en plus d'applications sont connectées au middleware, la cohérence des données s'améliore progressivement, de la surveillance à la surveillance. Le nombre d’incohérences observées sur le tableau Kanban diminue également lentement. Cependant, la cohérence n'a jamais été réduite à zéro. La raison en est la concurrence des applications et des tâches de synchronisation. C'est également le problème le plus gênant.
Peut-être que certains étudiants se demanderont, depuis la double écriture, pourquoi ne pas arrêter le travail de synchronisation ? La raison en est que SQL Server est la principale méthode d'écriture et que la gamme CUD couverte par le middleware est utilisée comme référence. En plus de ne pas garantir un succès à 100 % dans l'écriture de données sur MySQL, il n'y a aucune garantie sur la quantité de données contenues dans le fichier. deux bases de données sont égales, donc un travail cohérent est requis. Même si les données ne peuvent pas être totalement cohérentes, les incohérences peuvent être encore réduites grâce à un traitement simultané.
Notre approche consiste à définir une ligne stable de 5 secondes lors de la comparaison des tâches de cohérence (c'est-à-dire que les données dans les 5 secondes suivant l'heure actuelle sont considérées comme des données instables), et l'horodatage des données de commande se situe dans la stabilité. ligne Aucune comparaison n'est effectuée. Lors de la comparaison en dehors de la ligne stable, il sera calculé à nouveau si les données de commande se trouvent dans la ligne stable. S'il est confirmé que toutes les données sont en dehors de la ligne stable, l'opération de comparaison sera effectuée. la comparaison sera abandonnée et le prochain planning sera cohérent.
Vérification et avertissement des données hors ligne
La migration de la bibliothèque de commandes implique des centaines de tables, et implique une grande quantité de données hors ligne. La quantité de données relatives aux commandes en un an seulement atteint des milliards, ce qui pose des défis considérables à l'inspection des données hors ligne. Nous avons écrit un générateur de script de cohérence des données pour générer un script de comparaison pour chaque table et le déployer sur la plate-forme de planification. Le script de comparaison s'appuie sur la tâche de synchronisation des deux côtés du serveur SQLServer et de MySQL en amont. Une fois la tâche en amont exécutée, les données. la comparaison est automatiquement effectuée pour comparer les données incohérentes. Le numéro de commande est écrit dans le tableau détaillé et le nombre d'incohérences est calculé sur la base du tableau détaillé, qui est émis sous la forme d'un rapport quotidien. Les tableaux présentant une incohérence de données élevée sont. vérifié et résolu chaque jour.
Nous dépannons et résolvons généralement continuellement les incohérences, notamment en résolvant les problèmes dans les scripts de comparaison et en vérifiant la qualité des données hors ligne. La vérification de chaque champ dans chaque table de données hors ligne est très compliquée. Nous écrivons une fonction UDF à des fins de comparaison. La fonction UDF est également très simple. Elle consiste à épisser les champs clés non primaires de chaque table pour générer une. nouveau champ. Les tables des deux côtés Lors de l'exécution d'une jointure externe complète, les enregistrements avec des clés primaires égales ou des clés primaires logiques doivent également générer de nouveaux champs. Tant qu'ils sont différents, ils seront considérés comme des données incohérentes. Ici, nous devons prêter attention à l'interception du champ de date, à l'exactitude des données et au traitement des décimales avec des zéros à la fin.
Après plus de trois mois de travail acharné, nous avons identifié toutes les applications qui ne sont pas connectées au middleware et connecté toutes leurs opérations CUD au middleware. Après avoir activé la double écriture, la cohérence en ligne et. les données hors ligne se sont progressivement améliorées, atteignant l'objectif de migration des données.
2. TOUS Shard surveillance du volume total des commandes en temps réel
Chaque entreprise est indispensable pour surveiller le volume des commandes Ctrip dispose d'une plate-forme d'alerte précoce unifiée Sitemon, qui surveille principalement les alertes pour. diverses commandes, notamment des hôtels, des billets d'avion, des services sans fil, des trains à grande vitesse et des vacances. Le système a une fonction de recherche et d'affichage indépendante basée sur les méthodes de paiement en ligne/hors ligne, nationales/internationales, ainsi que des alertes pour tous les types de commandes.
Lors de la migration des données de commande de SQL Server vers MySQL, nous avons trié près de deux cents stratégies d'alerte précoce qui s'appuyaient sur la base de données de commandes. Les collègues responsables de la surveillance ont fait une copie des stratégies d'alerte précoce. de la source de données SQL Server et connecté à la source de données MySQL. Une fois toutes les alarmes de surveillance avec MySQL comme source de données ajoutées, activez la stratégie d'alarme. Une fois que le volume de commande est anormal, NOC recevra deux notifications, une de l'alarme de données SQLServer et une de l'alarme MySQL si les deux côtés sont cohérents. signifie que la vérification en niveaux de gris est réussie. Sinon, il échoue et le problème de surveillance MySQL doit être étudié.
Après une période de vérification en niveaux de gris, les données d'alarme des deux côtés sont cohérentes. Lorsque la table de données SQLServer est hors ligne (c'est-à-dire que les données MySQL sont écrites seules), la stratégie d'alerte précoce utilise SQLServer comme serveur. la source de données se déconnecte également à temps.
3. Opération pratique "Wandering Earth"
Pour garantir la sécurité du système et améliorer la capacité à répondre aux urgences, les exercices et tests de résistance nécessaires doivent être effectués. Pour cela, nous avons élaboré un plan d'urgence complet et organisons régulièrement des exercices d'urgence - The Wandering Earth. Les éléments d'exercice comprennent un disjoncteur d'application principal/non principal, un disjoncteur DB, un disjoncteur Redis, un pare-feu central, un commutateur de commutation d'urgence, etc.
En prenant comme exemple la mise en cache, afin d'assurer la haute disponibilité du service de cache, nous mettrons hors ligne certains nœuds ou machines ou même couperons l'intégralité du service Redis pendant l'exercice pour simuler une avalanche de cache, du cache panne et autres scénarios. Selon le plan, avant la fusion, nous couperons d'abord l'accès Redis de l'application, réduirons progressivement la charge Redis, puis fusionnerons Redis pour tester si chaque système d'application peut fonctionner normalement sans Redis.
Lors du premier exercice, lorsque Redis a été interrompu, le nombre d'erreurs d'application a fortement augmenté, nous avons donc arrêté l'exercice de manière décisive et l'avons annulé tout en recherchant la cause du problème. Étant donné que les opérations Redis de certaines applications ne sont pas gérées de manière uniforme et ne sont pas contrôlées par un middleware, lorsque Redis tombe en panne, l'application devient immédiatement anormale. En réponse à cette situation, après analyse, d'une part, nous avons connecté le port d'accès au cache de commande de l'application de reporting d'erreurs au middleware. D'autre part, nous avons renforcé la faible dépendance entre le middleware et Redis, supporté en un seul clic. déconnexion des opérations Redis et amélioration de diverses surveillances métriques. Lors du deuxième exercice, le disjoncteur Redis a réussi et tous les systèmes de l'entreprise ont fonctionné normalement avec un accès complet au trafic vers MySQL. Lors du dernier exercice Wandering Earth, après des séries d'injections de fautes telles que le blocage du réseau de la salle informatique et le blocage des applications non essentielles, notre système a obtenu les très bons résultats attendus.
De cette façon, exercice après exercice, nous avons découvert des problèmes, résumé l'expérience, optimisé le système, amélioré les plans d'urgence, amélioré étape par étape la capacité du système à faire face à des pannes soudaines et assuré la continuité des activités et l'intégrité des données. Fournissez un support de données sous-jacent pour protéger l’ensemble du système de commande hôtelière.
VI. Planification future
1. Commandez un bureau de contrôle manuel du cache
Bien que nous disposions d'un tableau de surveillance complet et d'un système d'alerte précoce, pour les problèmes tels que les exercices de disjoncteur, les exercices de pannes automatisés, les pannes matérielles et la maintenance, ainsi que les problèmes imprévisibles. avance, s'il se trouve que les développeurs principaux n'ont pas réussi à répondre à l'opération sur site à temps et que le système n'est pas rétrogradé de manière entièrement autonome, ce qui peut entraîner une certaine dégradation des performances, telle qu'une augmentation du temps de réponse. À l'avenir, nous prévoyons d'ajouter des tableaux de bord de contrôle manuel. Après autorisation, NOC ou TS pourront être autorisés à effectuer des opérations ciblées. Par exemple, si tout ou partie du cluster Redis est en panne, les fragments Redis défectueux peuvent être coupés en un seul clic. , ou en fonction de la période d'indisponibilité prévue de Redis. Le réglage du temps de coupe à l'avance peut garantir la contrôlabilité du système dans la plus grande mesure.
2. Rétrogradation automatique du middleware
Comme il peut être contrôlé manuellement, nous envisageons également de surveiller certains indicateurs de base à l'avenir, par exemple, lors de la commutation maître-esclave Redis, la situation normale est de quelques secondes, mais nous en avons également expérimenté. Redis 10 S'il ne peut pas être écrit pendant plus de secondes, vous pouvez surveiller la quantité de données sales qui sont incohérentes entre le cache et la base de données. Vous pouvez également appliquer certaines stratégies en surveillant le seuil de temps de réponse anormal en cas d'échec de Redis. que le middleware peut automatiquement rétrograder et supprimer ces pannes. L'hôte assure la stabilité de base du service, puis tente progressivement de récupérer après avoir détecté que les indicateurs du cluster sont stables.
3. Accès middleware à Service Mesh
L'équipe de commande actuelle utilise un middleware sous la forme de JAR. Le middleware protège les différences sous-jacentes dans la base de données et exploite Redis pour réaliser des fonctions plus complexes. , après l'accès, la mise à niveau sous-jacente est plus rapide et plus transparente, l'appel est plus léger, l'intégration du réseau avec le framework est meilleure et la migration vers le cloud est plus pratique, ce qui peut mieux soutenir les objectifs stratégiques internationaux de Ctrip.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!