
Maison >base de données >Redis >Comment utiliser la stratégie de double suppression retardée de Redis
Comment utiliser la stratégie de double suppression retardée de Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-02 20:32:141639parcourir
Normalement, nous donnerons la priorité à l'utilisation du cache Redis pour réduire la charge d'accès à la base de données. Cependant, nous rencontrerons également la situation suivante : lorsqu'un grand nombre d'utilisateurs accèdent à notre système, ils interrogeront d'abord le cache. S'il n'y a aucune donnée dans le cache, ils interrogeront la base de données, puis mettront à jour les données dans le cache. , et si les données de la base de données ont changé, elles doivent être synchronisées avec redis. Pendant le processus de synchronisation, la cohérence des données entre MySQL et redis doit être assurée. Il est normal qu'un court délai de données se produise pendant ce processus de synchronisation. mais au final il faut s'assurer de la cohérence entre mysql et le cache.
//我们通常使用redis的逻辑
//通常我们是先查询reids
String value = RedisUtils.get(key);
if (!StringUtils.isEmpty(value)){
return value;
}
//从数据库中获取数据
value = getValueForDb(key);
if (!StringUtils.isEmpty(value)){
RedisUtils.set(key,value);
return value;
}1. Qu'est-ce que la double suppression différée ?
La stratégie de double suppression retardée est une stratégie courante pour le stockage de bases de données et les données de cache afin de maintenir la cohérence dans les systèmes distribués, mais elle n'est pas fortement cohérente. En fait, quelle que soit la solution utilisée, le problème des données sales dans Redis ne peut être évité. Pour le résoudre complètement, des verrous de synchronisation et les niveaux de logique métier correspondants doivent être utilisés pour le résoudre.
2. Pourquoi devrions-nous effectuer une double suppression différée ?
Généralement, lorsque nous mettons à jour les données de la base de données, nous devons synchroniser les données mises en cache dans Redis, nous proposons donc généralement deux solutions :
La première solution : effectuez d'abord l'opération de mise à jour, puis effectuez la suppression du cache.
La deuxième option : effectuez d'abord une suppression du cache, puis effectuez l'opération de mise à jour.
Cependant, ces deux solutions sont sujettes aux problèmes suivants dans les requêtes simultanées
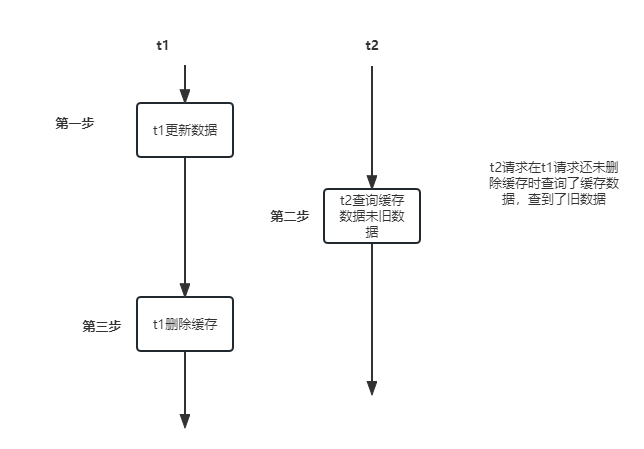
Inconvénients de la première solution : Une fois que la requête 1 a effectué l'opération de mise à jour de la base de données, la requête 2 arrive avant que la suppression du cache ne soit effectuée. est interrogée à ce stade, les données dans le cache sont encore des données anciennes, ce qui entraîne des problèmes avec les données. Cependant, une fois que t1 a effectué l'opération de suppression du cache, les requêtes suivantes ne peuvent pas interroger le cache, puis interroger. les données, puis les mettre à jour dans le cache. , cet impact est relativement faible
le thread t1 met à jour la base de données en premier ;
la requête du thread t2 atteint le cache et renvoie les anciennes données
; le thread t1 a mis à jour la base de données, on estime que le cache sera supprimé dans 5 millisecondes. Le résultat du cache de requête de la clé dans les 5 millisecondes des autres threads est toujours les anciennes données, mais le résultat du cache de requête après 5 millisecondes est vide, et le dernier résultat de la base de données est à nouveau synchronisé avec Redis.
Il est très courant que des retards dans un projet se produisent, donc l'impact de tels retards sur l'entreprise est en réalité très limité. Mais que se passe-t-il si cela se produit et que la suppression du cache échoue ?
1. Continuez à réessayer ---- Si c'est dans l'interface du protocole http, la réponse de l'interface ralentira. 2. Ou synchronisez via mq de manière asynchrone
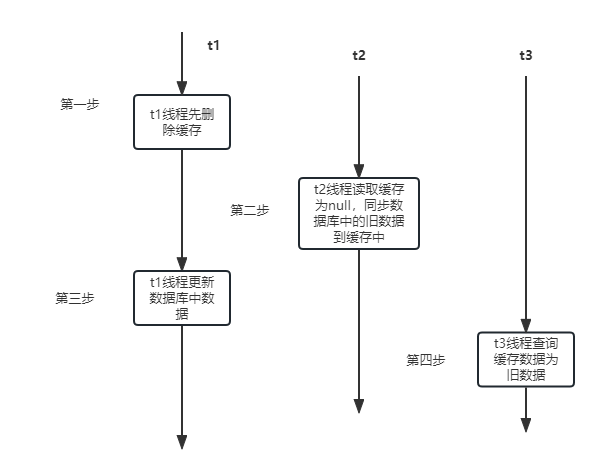
Le. deuxième Inconvénients de la solution : Lorsque la requête 1 efface le cache mais n'a pas encore effectué l'opération de mise à jour des données, la requête 2 arrive pour interroger les anciennes données de la base de données et les écrit dans redis, ce qui conduit au problème d'incohérence entre les base de données et données Redis. Le thread
t1 supprime le cache en premier ; le thread
t2 lit le cache comme nul et synchronise les données de la base de données avec le cache ; le thread
t1 met à jour les données dans la base de données ; interroge le cache Les données sont des données anciennes ;
3. Il y a des inconvénients dans le traitement de la solution, nous devons donc utiliser la stratégie de double suppression retardée
Videz le cache avant d'effectuer l'opération de mise à jour et attendez N secondes pour effacer le cache. cache à nouveau une fois la mise à jour terminée. Deux suppressions sont effectuées, et une période de délai est nécessaire entre les deux
RedisUtils.del(key);// 先删除缓存 updateDB(user);// 更新db中的数据 Thread.sleep(N);// 延迟一段时间,在删除该缓存key RedisUtils.del(key);// 先删除缓存
4. Points à noter
Le temps ci-dessus (délai N secondes) est supérieur au temps d'une opération d'écriture. Si le temps d'écriture sur redis est antérieur au délai, la requête 1 videra le cache, mais le cache de la requête 2 n'a pas encore été écrit, ce qui entraîne une situation embarrassante. . .
5. Comment déterminer le temps de retard ?
Estimé en fonction du temps de fonctionnement de l'exécution de la logique métier pour la lecture des données et l'écriture du cache, lorsque le programme métier est en cours d'exécution. La « double suppression retardée » est due au fait que cette solution supprimera à nouveau la valeur mise en cache après un certain temps après sa première suppression.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!