
Maison >base de données >tutoriel mysql >Comment localiser rapidement SQL lent dans MySQL
Comment localiser rapidement SQL lent dans MySQL

- PHPzavant
- 2023-06-02 19:34:122040parcourir
Activer le journal des requêtes lentes
Nous rencontrons souvent des requêtes lentes dans le projet. Lorsque nous rencontrons des requêtes lentes, nous devons généralement activer le journal des requêtes lentes, analyser le journal des requêtes lentes, rechercher le SQL lent, puis utiliser expliquer pour l'analyser.
Variables système
Les variables système liées à MySQL et aux requêtes lentes sont les suivantes
| Paramètres | Signification |
|---|---|
| slow_query_log | Que ce soit pour activer le journal des requêtes lentes, ON signifie activé, OFF signifie pas activé, la valeur par défaut est OFF |
| log_output | L'emplacement de sortie du journal est par défaut FILE, ce qui signifie qu'il est enregistré en tant que fichier. S'il est défini sur TABLE, le journal sera enregistré dans la table mysql.show_log. Plusieurs formats sont pris en charge. |
| slow_query_log_file | Spécifiez slow Le chemin et le nom du fichier journal des requêtes |
| long_query_time | Le journal des requêtes lentes sera enregistré uniquement si le temps d'exécution dépasse cette valeur. L'unité est en secondes. La valeur par défaut est 10. |
Exécutez l'instruction suivante pour voir si le journal des requêtes lentes est activé, ON signifie activé, OFF signifie non activé
show variables like "%slow_query_log%"
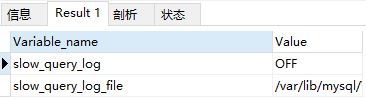
Vous pouvez voir que le mien n'est pas activé, vous pouvez activer la requête lente des deux manières suivantes
Modifier le fichier de configuration
Modifier le fichier de configuration my.ini et ajouter les paramètres suivants dans le [mysqld] paragraphe
[mysqld] log_output='FILE,TABLE' slow_query_log='ON' long_query_time=0.001
Vous devez redémarrer MySQL pour prendre effet. La commande est service mysqld restart
Set global variables#🎜🎜. #
J'exécute ce qui suit sur la ligne de commande. Ouvrez le journal des requêtes lentes en 2 phrases, définissez le délai d'attente sur 0,001 s et enregistrez le journal dans le fichier et la table mysql.slow_logset global slow_query_log = on; set global log_output = 'FILE,TABLE'; set global long_query_time = 0.001;#🎜🎜 #Si vous souhaitez que cela prenne effet de manière permanente, récupérez la configuration dans le fichier de configuration, sinon après le redémarrage de la base de données, ces configurations deviennent invalides
Analyser le journal des requêtes lentes
Parce que le journal des requêtes lentes MySQL est équivalent à un compte en cours d'exécution et n'a pas la fonction de statistiques récapitulatives, nous devons donc utiliser certains outils pour analyser
mysqldumpslow# 🎜🎜#
mysql dispose d'un outil mysqldumpslow intégré pour nous aider à analyser les journaux de requêtes lentes.Usage courant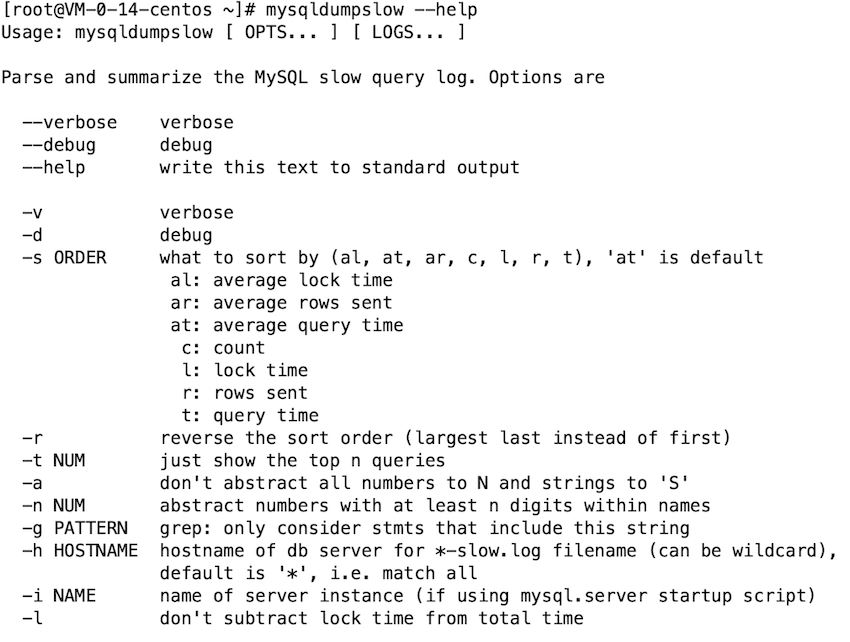
# 取出使用最多的10条慢查询 mysqldumpslow -s c -t 10 /var/run/mysqld/mysqld-slow.log # 取出查询时间最慢的3条慢查询 mysqldumpslow -s t -t 3 /var/run/mysqld/mysqld-slow.log # 得到按照时间排序的前10条里面含有左连接的查询语句 mysqldumpslow -s t -t 10 -g “left join” /database/mysql/slow-logpt-query-digestpt-query-digest est L'outil que j'utilise le plus est très puissant. Il peut analyser le binlog, le journal général, le slowlog et peut également être analysé via show processlist ou les données du protocole MySQL capturées via tcpdump. Téléchargez simplement et autorisez l'exécution du script Perl pt-query-digestTélécharger et responsabiliser
wget www.percona.com/get/pt-query-digest chmod u+x pt-query-digest ln -s /opt/soft/pt-query-digest /usr/bin/pt-query-digestIntroduction à l'utilisation
// 查看具体使用方法 pt-query-digest --help // 使用格式 pt-query-digest [OPTIONS] [FILES] [DSN]# 🎜🎜#COMMON OPTIONS
--create-review-table Lors de l'utilisation du paramètre --review pour afficher les résultats de l'analyse dans la table, s'il n'y a pas de table. est créé automatiquement.
--create-history-table Lorsque vous utilisez le paramètre --history pour afficher les résultats de l'analyse dans une table, celle-ci sera automatiquement créée s'il n'y a pas de table.
--filter Correspond et filtre la requête lente d'entrée en fonction de la chaîne spécifiée, puis l'analyse
- #🎜 🎜 #--limit limite le pourcentage ou la quantité des résultats de sortie. La valeur par défaut est 20, ce qui signifie que les 20 instructions les plus lentes seront générées. Si elle est de 50 %, elles seront triées de grande à petite en fonction du temps de réponse total. et la sortie sera émise jusqu'à ce que le total atteigne la date limite de 50 %.
- --adresse du serveur mysql de l'hôte
- --utilisateur nom d'utilisateur mysql
#🎜 🎜 #
--password mysql user password - --history Enregistrez les résultats de l'analyse dans le tableau Les résultats de l'analyse seront plus détaillés ensuite. time. Lorsque --history est à nouveau utilisé, si la même instruction existe et que l'intervalle de temps de la requête est différent de celui de la table d'historique, elle sera enregistrée dans la table de données. Vous pouvez comparer les changements historiques d'un certain type. de requête en interrogeant le même CHECKSUM.
- --review Enregistrez les résultats de l'analyse dans la table. Cette analyse ne paramétre que les conditions de requête. Un type de requête concerne un enregistrement, ce qui est relativement simple. Si la même analyse de déclaration se produit, elle ne sera pas enregistrée dans le tableau de données la prochaine fois que --review sera utilisé.
- --type de sortie du résultat de l'analyse de sortie, la valeur peut être rapport (rapport d'analyse standard), slowlog (journal lent MySQL), json, json-anon, généralement utilisé rapport , pour une lecture plus facile.
- --depuis quand commencer l'analyse, la valeur est une chaîne, qui peut être un "aaaa-mm-jj [hh:mm:ss]" spécifié. le point temporel dans le format peut également être une simple valeur temporelle : s (secondes), h (heures), m (minutes), d (jours). Par exemple, 12h signifie que les statistiques ont commencé il y a 12 heures.
- --jusqu'à la date limite, combiné avec puisque peut analyser les requêtes lentes sur une période donnée.
- Common DSN A Spécifier le jeu de caractères
S Connectez-vous au fichier Socketh Connectez-vous au nom d'hôte de la base de donnéesp Mot de passe pour vous connecter à la base de données
t Où stocker les données lors de l'utilisation de --review ou --history Zhang Biaoliu Connexion au nom d'utilisateur de la base de données
DSN est configuré sous la forme de clé=valeur, plusieurs DSN sont utilisés, séparés
;
Exemple d'utilisation# 🎜🎜#
# 展示slow.log中最慢的查询的报表 pt-query-digest slow.log # 分析最近12小时内的查询 pt-query-digest --since=12h slow.log # 分析指定范围内的查询 pt-query-digest slow.log --since '2020-06-20 00:00:00' --until '2020-06-25 00:00:00' # 把slow.log中查询保存到query_history表 pt-query-digest --user=root --password=root123 --review h=localhost,D=test,t=query_history --create-review-table slow.log # 连上localhost,并读取processlist,输出到slowlog pt-query-digest --processlist h=localhost --user=root --password=root123 --interval=0.01 --output slowlog # 利用tcpdump获取MySQL协议数据,然后产生最慢查询的报表 # tcpdump使用说明:https://blog.csdn.net/chinaltx/article/details/87469933 tcpdump -s 65535 -x -nn -q -tttt -i any -c 1000 port 3306 > mysql.tcp.txt pt-query-digest --type tcpdump mysql.tcp.txt # 分析binlog mysqlbinlog mysql-bin.000093 > mysql-bin000093.sql pt-query-digest --type=binlog mysql-bin000093.sql # 分析general log pt-query-digest --type=genlog localhost.log
utilisation pratique Écriture de procédures stockées pour créer des données par lots
# 🎜🎜#Il n'y a pas de test de performance en travail réel, nous devons souvent transformer de gros lots de données, et l'insertion manuelle est impossible Pour le moment, nous devons utiliser des procédures stockées
CREATE TABLE `kf_user_info` ( `id` int(11) NOT NULL COMMENT '用户id', `gid` int(11) NOT NULL COMMENT '客服组id', `name` varchar(25) NOT NULL COMMENT '客服名字' ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='客户信息表';#🎜🎜. #Comment définir une procédure stockée ?
CREATE PROCEDURE 存储过程名称 ([参数列表])
BEGIN
需要执行的语句
ENDPar exemple, insérez 100 000 éléments de données avec les ID 1 à 100 000
Utilisez Navicat pour exécuter -- 删除之前定义的
DROP PROCEDURE IF EXISTS create_kf;
-- 开始定义
CREATE PROCEDURE create_kf(IN loop_times INT)
BEGIN
DECLARE var INT;
SET var = 1;
WHILE var < loop_times DO
INSERT INTO kf_user_info (`id`,`gid`,`name`)
VALUES (var, 1000, var);
SET var = var + 1;
END WHILE;
END;
-- 调用
call create_kf(100000);
Trois types de paramètres de procédures stockées # 🎜🎜#
Type de paramètre
Que ce soit à retourner
Fonction
# 🎜🎜#
IN| Passer les paramètres dans la procédure stockée La valeur du paramètre est modifiée lors de la procédure stockée et ne peut pas être renvoyée#🎜🎜 ##🎜 🎜# | OUT | est |
|---|---|---|
| INOUT | est la combinaison de | |
|
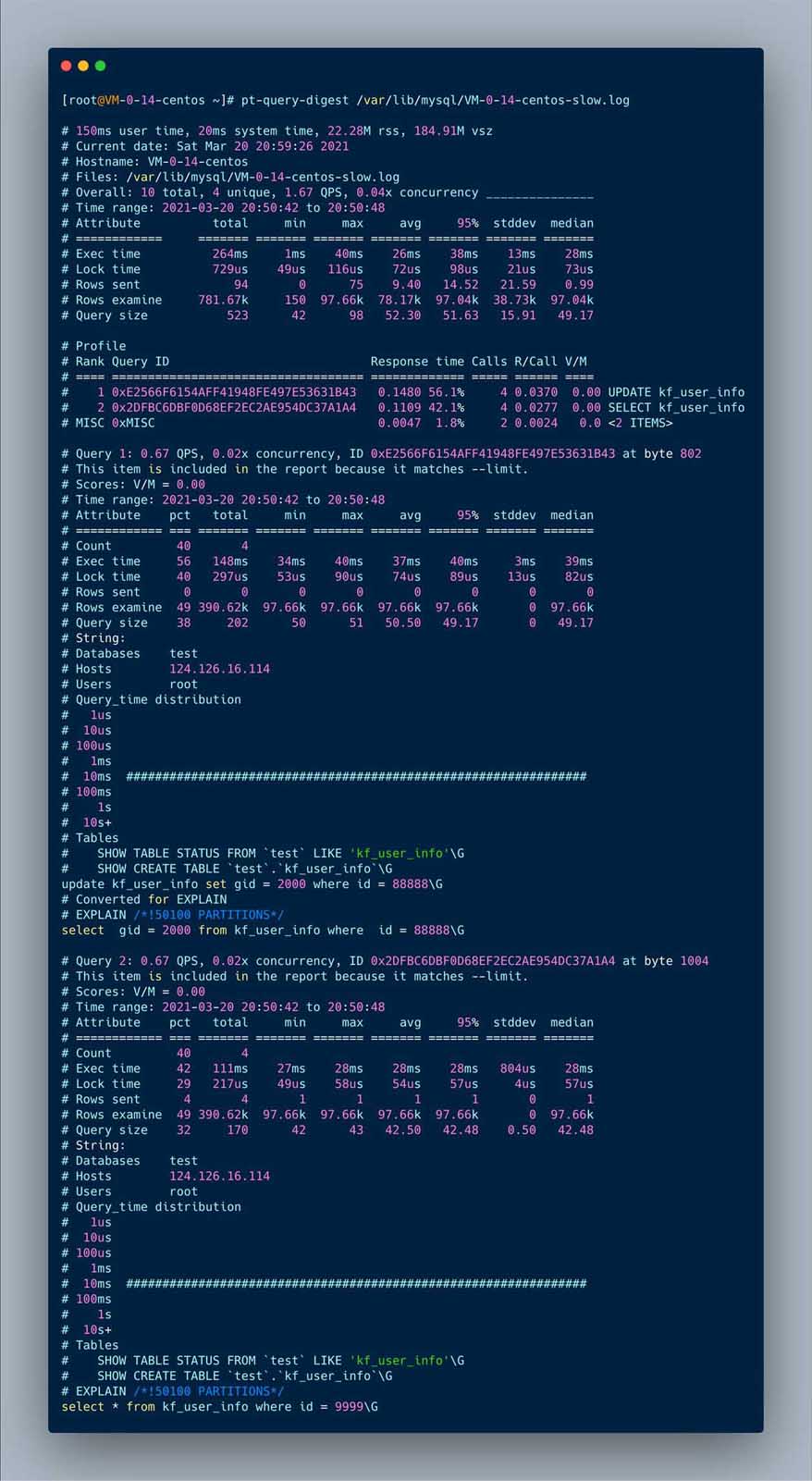
用MySQL执行 得用DELIMITER 定义新的结束符,因为默认情况下SQL采用(;)作为结束符,这样当存储过程中的每一句SQL结束之后,采用(;)作为结束符,就相当于告诉MySQL可以执行这一句了。但是存储过程是一个整体,我们不希望SQL逐条执行,而是采用存储过程整段执行的方式,因此我们就需要定义新的DELIMITER ,新的结束符可以用(//)或者($$) 因为上面的代码应该就改为如下这种方式 DELIMITER // CREATE PROCEDURE create_kf_kfGroup(IN loop_times INT) BEGIN DECLARE var INT; SET var = 1; WHILE var <= loop_times DO INSERT INTO kf_user_info (`id`,`gid`,`name`) VALUES (var, 1000, var); SET var = var + 1; END WHILE; END // DELIMITER ; 查询已经定义的存储过程 show procedure status; 开始执行慢sql select * from kf_user_info where id = 9999; select * from kf_user_info where id = 99999; update kf_user_info set gid = 2000 where id = 8888; update kf_user_info set gid = 2000 where id = 88888; 可以执行如下sql查看慢sql的相关信息。 SELECT * FROM mysql.slow_log order by start_time desc; 查看一下慢日志存储位置 show variables like "slow_query_log_file" pt-query-digest /var/lib/mysql/VM-0-14-centos-slow.log 执行后的文件如下
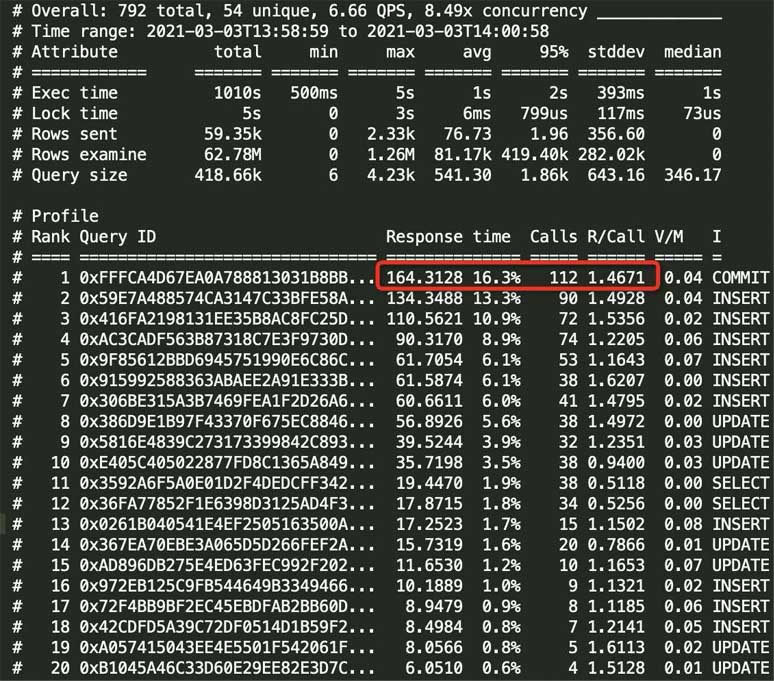
# Profile # Rank Query ID Response time Calls R/Call V/M # ==== =================================== ============= ===== ====== ==== # 1 0xE2566F6154AFF41948FE497E53631B43 0.1480 56.1% 4 0.0370 0.00 UPDATE kf_user_info # 2 0x2DFBC6DBF0D68EF2EC2AE954DC37A1A4 0.1109 42.1% 4 0.0277 0.00 SELECT kf_user_info # MISC 0xMISC 0.0047 1.8% 2 0.0024 0.0 <2 ITEMS> 从最上面的统计sql中就可以看到执行慢的sql 可以看到响应时间,执行次数,每次执行耗时(单位秒),执行的sql 下面就是各个慢sql的详细分析,比如,执行时间,获取锁的时间,执行时间分布,所在的表等信息 不由得感叹一声,真是神器,查看慢sql超级方便 最后说一个我遇到的一个有意思的问题,有一段时间线上的接口特别慢,但是我查日志发现sql执行的很快,难道是网络的问题? 为了确定是否是网络的问题,我就用拦截器看了一下接口的执行时间,发现耗时很长,考虑到方法加了事务,难道是事务提交很慢? 于是我用pt-query-digest统计了一下1分钟左右的慢日志,发现事务提交的次很多,但是每次提交事务的平均时长是1.4s左右,果然是事务提交很慢。
|
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!