
Maison >base de données >Redis >Comment utiliser Gaussian Redis pour implémenter un index secondaire
Comment utiliser Gaussian Redis pour implémenter un index secondaire

- PHPzavant
- 2023-06-02 18:53:231379parcourir
1. Contexte
En matière d'indexation, la première impression est le terme base de données, mais Gaussian Redis peut également implémenter une indexation secondaire ! ! ! Les index secondaires dans Gaussian Redis sont généralement implémentés à l'aide de zset. Gaussian Redis présente des avantages en termes de stabilité et de coût plus élevés que Redis open source. L'utilisation de Gaussian Redis zset pour implémenter des index secondaires commerciaux peut permettre d'obtenir une situation gagnant-gagnant en termes de performances et de coûts.
L'essence de l'indexation est d'utiliser des structures ordonnées pour accélérer les requêtes, de sorte que les index de type numérique et caractère puissent être facilement implémentés via la structure Zset Gaussian Redis.
• Index de type numérique (zset est trié par score) :
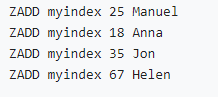

•
Passons en deux types de scénarios commerciaux classiques, voyons comment utiliser Gaussian Redis pour créer un système d'index secondaire stable et fiable. 2. Scénario 1 : Complétion du dictionnaire
2. Scénario 1 : Complétion du dictionnaire
Lors de la saisie d'une requête dans le navigateur, le navigateur recommande généralement des recherches avec le même préfixe en fonction de la vraisemblance. Ce scénario peut être réalisé à l'aide de la fonction d'index secondaire Gaussian Redis. 
2.1 Solution de base
Le moyen le plus simple est d'ajouter chaque requête de l'utilisateur à l'index. Si vous devez fournir des invites de complétion aux utilisateurs, vous pouvez utiliser ZRANGEBYLEX pour effectuer des requêtes de plage. Pour réduire le nombre de résultats, l'utilisation de l'option LIMIT est une méthode prise en charge par Gaussian Redis.
• Ajoutez une banane de recherche d'utilisateur à l'index : 
ZADD myindex 0 banana:1• Supposons que l'utilisateur saisisse "bit" dans le formulaire de recherche et que nous souhaitions fournir des mots-clés de recherche pouvant commencer par "bit".
ZRANGEBYLEX myindex "[bit" "[bit\xff"
Autrement dit, utilisez ZRANGEBYLEX pour effectuer une requête de plage. La plage de requête est la chaîne saisie par l'utilisateur maintenant, et la même chaîne plus un octet de fin de 255 (xff). Nous pouvons utiliser cette méthode pour obtenir toutes les chaînes préfixées par la chaîne saisie par l'utilisateur. 2.2 Complétion de dictionnaire liée à la fréquence Dans les applications pratiques, les gens souhaitent généralement trier automatiquement les termes de complétion pour s'adapter à la fréquence d'occurrence et éliminer les termes qui ne sont plus populaires, tout en s'adaptant aux entrées futures. Nous pouvons toujours utiliser la structure ZSet de Gaussian Redis pour atteindre cet objectif, mais dans la structure d'index, non seulement les termes de recherche doivent être stockés, mais également les fréquences qui leur sont associées. • Ajouter la banane de recherche d'utilisateur à l'index • Déterminer si la banane existe ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1
• Supposons que la banane n'existe pas, ajoutez la banane : 1, où 1 est la fréquence ZADD myindex 0 banana:1• pour augmenter la fréquence Si la fréquence renvoyée dans ZRANGEBYLEX monindex "[banane :" + LIMITE 0 1 est 11) Supprimez l'ancienne entrée :
ZREM myindex 0 banana:12) Ajoutez la fréquence par une et rejoignez :
ZADD myindex 0 banana:2S'il vous plaît notez qu'en raison de la possibilité de mises à jour simultanées, les trois commandes ci-dessus doivent être envoyées via un script Lua, qui obtient automatiquement l'ancien décompte et rajoute l'entrée après avoir incrémenté le score. Si l'utilisateur saisit « banane » dans le formulaire de recherche, nous espérons fournir des mots-clés de recherche pertinents. Trier par fréquence après avoir obtenu les résultats via ZRANGEBYLEX.
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 10 1) "banana:123" 2) "banaooo:1" 3) "banned user:49" 4) "banning:89"• Utilisez l'algorithme de streaming pour nettoyer les entrées rarement utilisées. Sélectionnez au hasard une entrée renvoyée et soustrayez-en une de son score, puis ajoutez-la à nouveau avec le score mis à jour. Cependant, si le nouveau score est 0, nous devons supprimer l’entrée de la liste. • Si la fréquence des entrées sélectionnées au hasard est de 1, comme banaooo:1
ZREM myindex 0 banaooo:1• Si la fréquence des entrées sélectionnées au hasard est supérieure à 1, comme banane:123
ZREM myindex 0 banana:123 ZADD myindex 0 banana:122À long terme, le L'index inclura les recherches populaires. Il s'adaptera également automatiquement si les recherches populaires changent au fil du temps. 3. Scénario 2 : Index multidimensionnel Gaussian Redis prend non seulement en charge les requêtes dans une seule dimension, mais peut également récupérer des données multidimensionnelles. Par exemple, recherchez des personnes qualifiées : âge entre 50 et 55 ans, et salaire entre 70 000 et 85 000. La conversion du codage de données bidimensionnelles en données unidimensionnelles, puis l'utilisation du stockage Redis zset distribué gaussien, est une méthode importante pour implémenter des index secondaires multidimensionnels. Représentez l'index bidimensionnel d'un point de vue visuel. Dans cet espace, certains points d'échantillonnage de données sont représentés sous forme de coordonnées (x, y), et les valeurs maximales des variables x et y dans ces coordonnées sont de 400. La case bleue dans l'image représente notre requête. Nous voulons trouver tous les points dont les coordonnées x sont comprises entre 50 et 100 et y entre 100 et 300.
3.1 Codage des données
Si le point de données inséré est x = 75 et y = 200
1) Remplissez 0 (la donnée maximale est de 400, donc remplissez 3 chiffres)
2)交织数字,以x表示最左边的数字,以y表示最左边的数字,依此类推,以便创建一个编码
027050
若使用00和99替换最后两位,即027000 to 027099,map回x和y,即:
x = 70-79
y = 200-209
因此,针对x=70-79和y = 200-209的二维查询,可以通过编码map成027000 to 027099的一维查询,这可以通过高斯Redis的Zset结构轻松实现。

同理,我们可以针对后四/六/etc位数字进行相同操作,从而获得更大范围。
3)使用二进制
如果将数据表示为二进制,就可以获得更细的粒度,而在数字替换时,每次都将搜索范围扩大两倍。如果我们使用二进制表示法数字,每个变量最多需要9位(表示最多400个值),那么我们将得到:
x = 75 -> 001001011
y = 200 -> 011001000
交织后,000111000011001010
让我们看看在交错表示中用0s ad 1s替换最后的2、4、6、8,...位时我们的范围是什么:

3.2 添加新元素
若插入数据点为x = 75和y = 200
x = 75和y = 200二进制交织编码后为000111000011001010,
ZADD myindex 0 000111000011001010
3.3 查询
查询:x介于50和100之间,y介于100和300之间的所有点
从索引中替换N位会给我们边长为2^(N/2)的搜索框。因此,我们要做的是检查搜索框较小的尺寸,并检查与该数字最接近的2的幂,并不断切分剩余空间,随后用ZRANGEBYLEX进行搜索。
下面是示例代码:
def spacequery(x0,y0,x1,y1,exp)
bits=exp*2
x_start = x0/(2**exp)
x_end = x1/(2**exp)
y_start = y0/(2**exp)
y_end = y1/(2**exp)
(x_start..x_end).each{|x|
(y_start..y_end).each{|y|
x_range_start = x*(2**exp)
x_range_end = x_range_start | ((2**exp)-1)
y_range_start = y*(2**exp)
y_range_end = y_range_start | ((2**exp)-1)
puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}"
# Turn it into interleaved form for ZRANGEBYLEX query.
# We assume we need 9 bits for each integer, so the final
# interleaved representation will be 18 bits.
xbin = x_range_start.to_s(2).rjust(9,'0')
ybin = y_range_start.to_s(2).rjust(9,'0')
s = xbin.split("").zip(ybin.split("")).flatten.compact.join("")
# Now that we have the start of the range, calculate the end
# by replacing the specified number of bits from 0 to 1.
e = s[0..-(bits+1)]+("1"*bits)
puts "ZRANGEBYLEX myindex [#{s} [#{e}"
}
}
end
spacequery(50,100,100,300,6)Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!