
Maison >base de données >tutoriel mysql >Quelle est la syntaxe de l'index MySQL
Quelle est la syntaxe de l'index MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-02 18:24:071307parcourir

Définition de l'index
Un index est une structure de données ordonnée qui aide MySQL à obtenir des données efficacement. Il s'agit de la définition officielle d'un index par MySQL. Afin d'améliorer l'efficacité des requêtes, les index sont un mécanisme ajouté aux champs des tables de base de données. En plus des données, le système de base de données conserve également des structures de données qui satisfont à des algorithmes de recherche spécifiques. Ces structures de données font référence (pointent vers) les données d'une manière ou d'une autre, de sorte que des algorithmes de recherche avancés puissent être implémentés sur ces structures de données. indice. Comme le montre le schéma ci-dessous :
En fait, pour parler simplement, un index est une structure de données triée
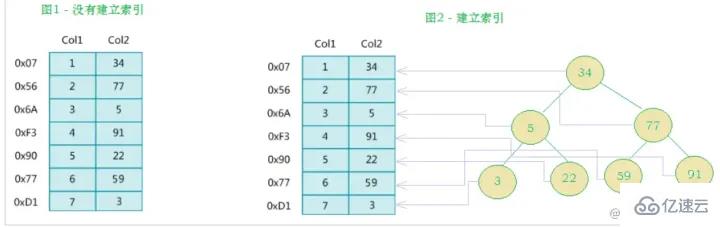
Le côté gauche est la table de données, avec un total de deux colonnes et sept enregistrements, et le côté le plus à gauche l'une est la structure physique de l'adresse de l'enregistrement de données (notez que les enregistrements logiquement adjacents ne sont pas nécessairement physiquement adjacents sur le disque). Afin d'accélérer la recherche de Col2, vous pouvez maintenir un arbre de recherche binaire comme indiqué à droite. Chaque nœud contient valeur de clé d'index et un pointeur vers l'adresse physique de l'enregistrement de données correspondant, afin que vous puissiez. utilisez la recherche binaire pour obtenir rapidement les données correspondantes.
Avantages de l'index
Accélérez la vitesse de recherche et de tri, réduisez le coût d'E/S de la base de données et la consommation du processeur
En créant un index unique, vous pouvez garantir le caractère unique de chacun ligne de données dans la table de base de données.
Inconvénients de l'index
L'index est en fait une table, qui enregistre la clé primaire et le champ d'index et pointe vers les enregistrements de la classe d'entité. Il doit lui-même prendre de la place
Bien que. cela augmente l'efficacité des requêtes, c'est Ajout, suppression et modification. Chaque fois que la table est modifiée, l'index doit être mis à jour. Nouveau : Naturellement, de nouveaux nœuds doivent être ajoutés dans l'arborescence d'index. l'arbre d'index peut devenir invalide, ce qui signifie que de nombreux nœuds dans cet arbre d'index sont invalides. Changement : Le pointeur du nœud dans l'arbre d'index doit peut-être être modifié
Mais en fait, nous n'utilisons pas. arbre de recherche binaire pour le stocker dans MySQL Pourquoi ?
Vous devez savoir que dans un arbre de recherche binaire, un nœud ici ne peut stocker qu'une seule donnée, et un nœud correspond à un bloc de disque dans MySQL. De cette façon, chaque fois que nous lisons un bloc de disque, nous ne pouvons que le faire. obtenir une donnée, l'efficacité est particulièrement faible, on pensera donc à utiliser une structure B-tree pour la stocker.
Structure de l'index
Les index sont implémentés dans la couche moteur de stockage de MySQL, pas dans la couche serveur. Par conséquent, les index peuvent différer selon les moteurs de stockage, et tous les moteurs ne prennent pas en charge tous les types d'index.
Indice BTREE : Le type d'index le plus courant, la plupart des index prennent en charge les index B-tree.
HASH Index : Uniquement pris en charge par le moteur de mémoire, le scénario d'utilisation est simple.
Indice R-tree (index spatial) : L'index spatial est un type d'index spécial du moteur MyISAM. Il est principalement utilisé pour les types de données géospatiales. Il est généralement moins utilisé et ne sera pas spécialement introduit.
Texte intégral (index de texte intégral) : L'index de texte intégral est également un type d'index spécial de MyISAM, principalement utilisé pour l'index de texte intégral. InnoDB prend en charge l'index de texte intégral à partir de la version Mysql5.6.
MyISAM, InnoDB et Memory trois moteurs de stockage prennent en charge différents types d'index
index |
INNODB moteur |
MYISAM moteur |
Moteur MÉMOIRE |
BTREE index |
Supporté |
Supporté |
Supporté |
Indice HASH |
Non pris en charge |
Non pris en charge |
Supporté |
| R-tree index |
Non pris en charge |
Supporté |
Non pris en charge |
Texte intégral |
Supporté après la version 5.6 | Pris en charge |
Non pris en charge |
Les index auxquels nous faisons habituellement référence, sauf indication explicite, sont organisés selon une structure d'arbre B+ (un arbre de recherche multidirectionnel, pas nécessairement binaire). Les index clusterisés, les index composés, les index de préfixe et les index uniques appelés index utilisent tous des index d'arborescence B+ par défaut.
BTREE
Arbre de recherche équilibré multidirectionnel, un ordre m (m-fork) BTREE satisfait :
Maximum de m enfants par nœud Nombre d'enfants : ceil(m/2) à m Nombre de mots-clés : ceil (m/2)-1 à m-1
ceil signifie arrondir, ceil(2.3)=3
insérer le mot-clé case

pour garantir que les propriétés de l'ordre m B- les arbres ne sont pas détruits
En raison du niveau 3, il ne peut y avoir que 2 nœuds au maximum, donc 26 et 30 sont ensemble au début, puis 85 commenceront à se diviser, 30 sera la position médiane supérieure, 26 restera, et 85 ira vers la droite
C'est-à-dire : La position médiane monte, puis le côté gauche reste à l'ancien nœud, et le côté droit va vers le nouveau nœud
Quand 70 est à nouveau inséré dans l'image, 70 se trouve être la position médiane, puis 62 reste et 85 est divisé en un nouveau nœud
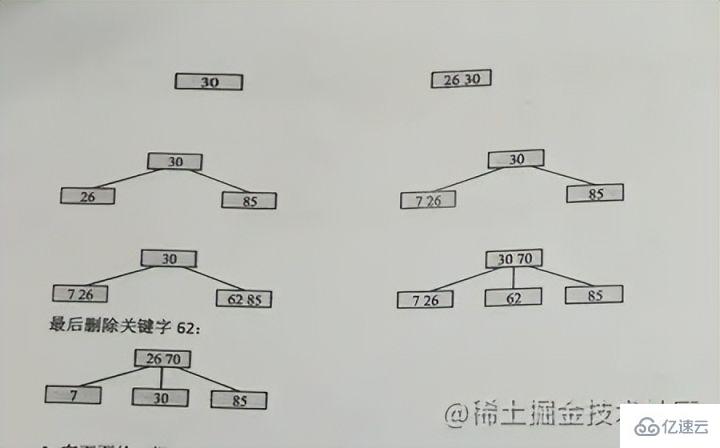
Après avoir atteint le niveau supérieur, il doit être à nouveau divisé
Continuez simplement à se diviser vers le haut
.
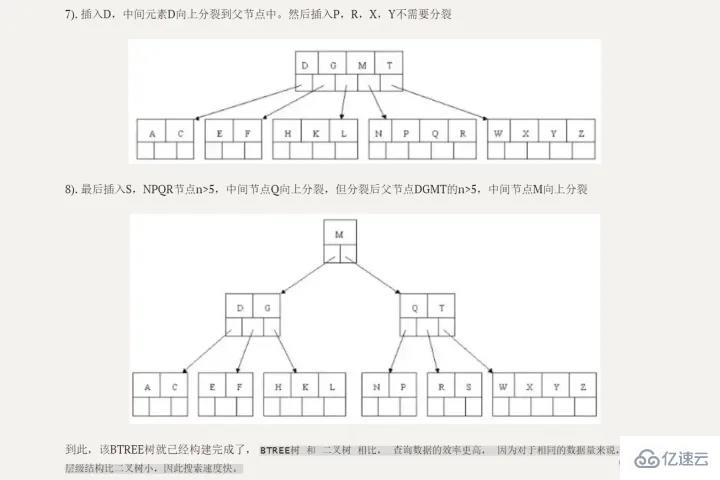
Avantages comparatifs
Par rapport aux arbres de recherche binaires, la hauteur/profondeur est inférieure et l'efficacité naturelle des requêtes est plus élevée.
B+TREE
L'arbre B+ a deux types de nœuds : les nœuds internes (également appelés nœuds d'index) et les nœuds feuilles. Les nœuds internes ne sont pas des nœuds feuilles. Les nœuds internes ne stockent pas de données, seuls des index et les données sont stockées dans des nœuds feuilles.
Les clés du nœud interne sont classées dans l'ordre de petite à grande Pour une clé dans le nœud interne, toutes les clés de l'arborescence de gauche sont inférieures à elle et toutes les clés du sous-arbre de droite sont supérieures à. ou égal à celui-ci. Les enregistrements dans les nœuds feuilles sont également classés en fonction de la taille de la clé.
Chaque nœud feuille stocke des pointeurs vers les nœuds feuilles adjacents. Les nœuds feuilles eux-mêmes sont connectés dans l'ordre du petit au grand en fonction de la taille des mots-clés.
- Le nœud parent stocke l'index
du premier élément du bon enfant.
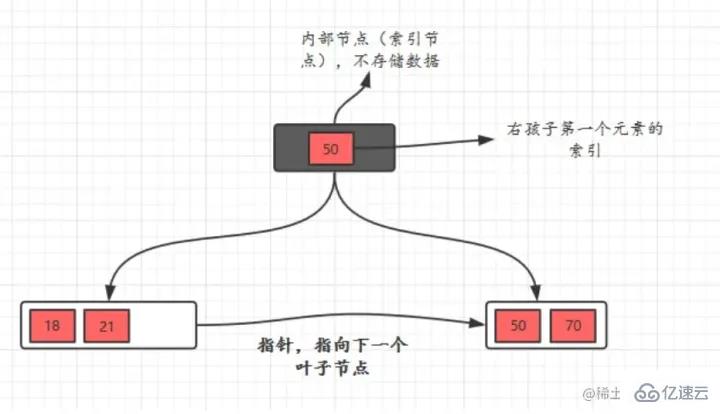
- L'efficacité des requêtes de B+Tree
est plus stable. Étant donné que seuls les nœuds feuilles de B+Tree stockent les informations clés, l’interrogation de n’importe quelle clé nécessite de passer de la racine aux feuilles, ce qui est donc plus stable.
- Il vous suffit de parcourir les nœuds feuilles pour parcourir l'arbre entier.
Les étudiants attentifs peuvent voir quelle est la plus grande différence entre cette image et notre arbre de recherche binaire ?
- arbre de recherche binaire à B-tree
- , un changement important est qu'un nœud peut stocker plusieurs données, ce qui équivaut à un bloc de disque peut stocker plusieurs données, ce qui réduit considérablement notre fréquence d'E/S ! !
Diagramme de structure d'index B+ dans MySQL :
Diagramme d'arbre de recherche binaire : 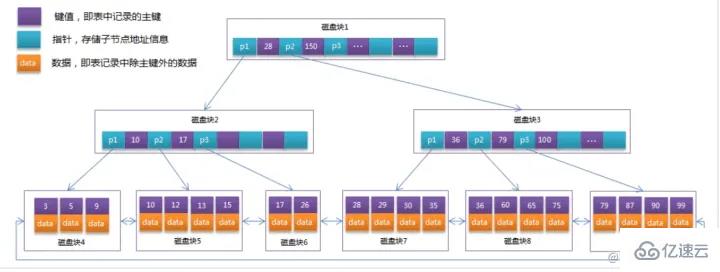
Principe de l'index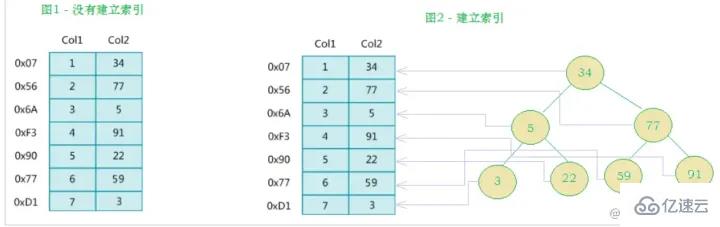
Par exemple, le bloc de disque 1 contient les éléments de données 17 et 35 et contient les pointeurs P1, P2 et
P1. représente les blocs de disque inférieurs à 17, P2 représente les blocs de disque entre 17 et 35 et P3 représente les blocs de disque supérieurs à 35.- Les données réelles existent dans les nœuds feuilles
- c'est-à-dire 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. `
Les nœuds non-feuilles ne stockent pas de données réelles, seuls les
éléments de données qui guident la direction de recherche - , tels que 17 et 35, n'existent pas réellement dans la table de données. `
Processus de recherche
Si vous souhaitez trouver l'élément de données 29, alors le bloc de disque 1 sera d'abord chargé du disque vers la mémoire, et une IO sera surviennent à ce moment. Utilisez une recherche binaire dans la mémoire pour déterminer que 29 est compris entre 17 et 35, et verrouillez le pointeur P2 du bloc disque 1. Le temps mémoire est négligeable car très court (par rapport aux IO du disque). L'adresse du pointeur P2 du bloc de disque 1 vers le bloc de disque 3 est chargée du disque dans la mémoire. La deuxième E/S se produit entre 26 et 30. Le pointeur P2 du bloc de disque 3 est verrouillé dans la mémoire. la mémoire via le pointeur. La troisième IO se produit. En même temps, la mémoire passe. La recherche binaire atteint 29 et termine la requête, avec un total de trois IO.
La situation réelle est qu'un arbre B+ à 3 couches peut représenter des millions de données si des millions de recherches de données ne nécessitent que trois IO, l'amélioration des performances sera énorme s'il n'y a pas d'index, chaque. Un élément de données nécessite une IO, donc un total de millions d'IO sont nécessaires. Évidemment, le coût est très, très élevé.
Classification d'index
Une table organisée en index est une table stockée dans l'ordre des clés primaires en tant qu'index. Cette méthode convient au moteur InnoDB. Étant donné qu'InnoDB utilise le modèle d'index d'arbre B+, les données sont stockées dans l'arborescence B+.
Chaque index correspond à un arbre B+ dans InnoDB.
Supposons que nous ayons une table avec la colonne de clé primaire comme ID, qu'il y ait un champ k dans la table et qu'il y ait un index sur k.
L'instruction de création de table de cette table est :
mysql> create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB; 复制代码
Les valeurs (ID,k)de R1~R5 dans la table sont (100,1), (200, 2), (300, 3), (500,5) et (600,6), l'exemple de diagramme schématique des deux arbres est le suivant :
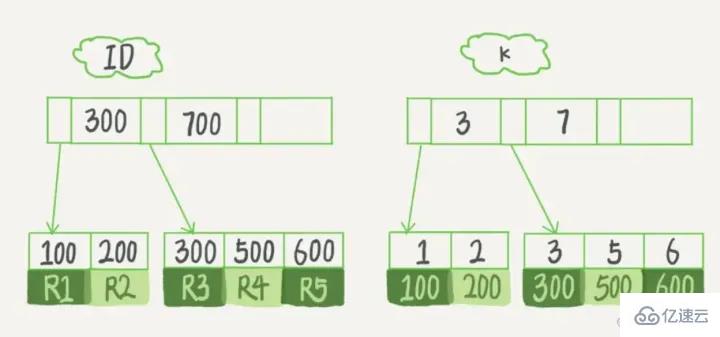
D'après l'image, il n'est pas difficile de voir qu'en fonction du contenu des nœuds feuilles, le type d'index est divisé en index de clé primaire et index de clé non primaire.
index de clé primaire stocke la ligne entière de données . Dans InnoDB, l'index de clé primaire est également appelé index clusterisé (index clusterisé).
Le contenu du nœud feuille de l'index auxiliaire est la valeur de clé primaire . Dans InnoDB, l'index auxiliaire est également appelé Secondary Index (index secondaire).
- L'index de clé primaire stocke la
ligne entière de données
- L'index auxiliaire ne se stocke que lui-même et la clé primaire id est utilisée pour la requête de table
Sur la base de la structure d'index ci-dessus, discutons d'une question : 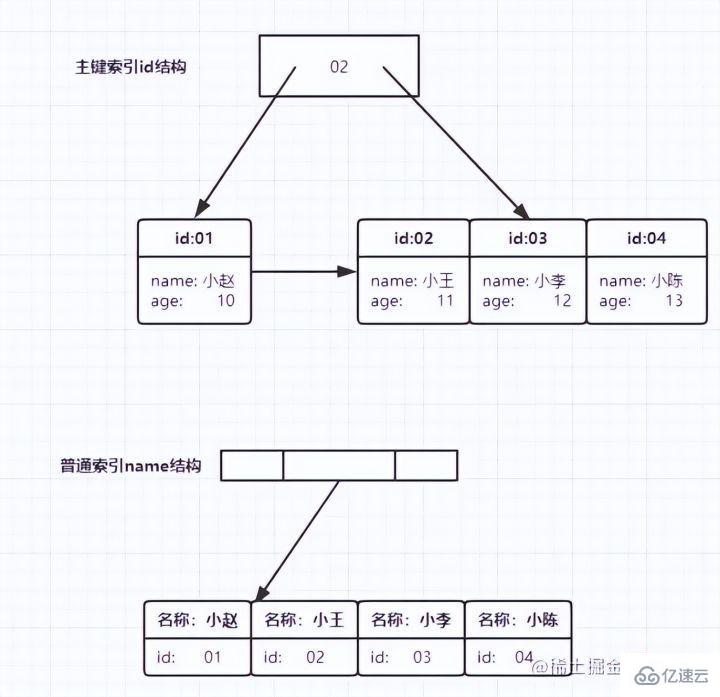 Quelle est la différence entre les requêtes basées sur des index de clé primaire et des index auxiliaires ?
Quelle est la différence entre les requêtes basées sur des index de clé primaire et des index auxiliaires ?
- Si l'instruction est select * from T où k=5, qui est la méthode de requête d'index ordinaire, vous devez rechercher #🎜🎜 #k index tree , la valeur de l'ID est 500,
- puis recherchez à nouveau dans l'arborescence d'index ID
. Ce processus s'appelle Retour à table. En d'autres termes, les requêtes basées sur des index auxiliaires doivent analyser une arborescence d'index supplémentaire. Par conséquent, nous devrions essayer d’utiliser des requêtes par clé primaire dans nos applications.
index couvert
--c'est-à-dire l'index La colonne contient toutes les données que nous souhaitons interroger.
Dans le même temps, l'index secondaire est divisé selon les types suivants (ignorez-le pour l'instant, nous en apprendrons plus plus tard) :
#🎜🎜 #
Unique Key (Unique Key)
- Les données en double ne peuvent pas apparaître dans la colonne d'attribut d'un index unique, mais les données peuvent être NULL. Une table permet la création de plusieurs index uniques.
- La plupart du temps, l'établissement d'un index unique a pour but de garantir l'unicité des données dans la colonne d'attribut, plutôt que d'améliorer l'efficacité des requêtes.
Ordinary Index (Index)
: La seule fonction d'un index ordinaire est d'interroger rapidement des données. Une table permet. la création de plusieurs index normaux, et permet la duplication de données et NULL. -
Index de préfixe (Prefix)
: L'index de préfixe s'applique uniquement aux données de type chaîne. L'index de préfixe crée un index sur les premiers caractères du texte Par rapport à l'index ordinaire, les données créées sont plus petites car seuls les premiers caractères sont récupérés. -
Full Text Index (Full Text)
: L'index de texte intégral est principalement utilisé pour récupérer des informations sur les mots-clés dans des données de texte volumineuses, et est le moteur de recherche actuel Une technologie utilisée par les moteurs de bases de données. Avant Mysql5.6, seul le moteur MYISAM prenait en charge l'indexation en texte intégral. Après la version 5.6, InnoDB prenait également en charge l'indexation en texte intégral .
Extension - Index pushdown
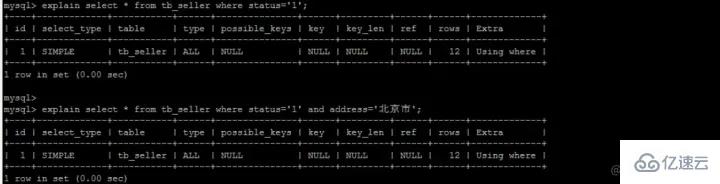
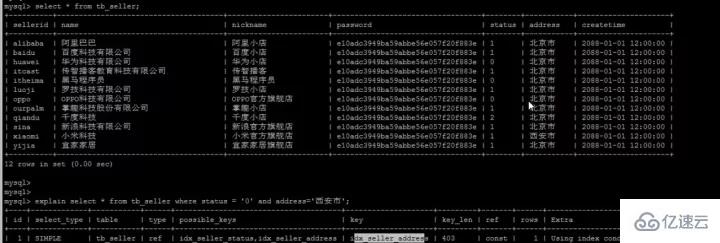
Le soi-disant pushdown, comme son nom l'indique, en fait retarde notre opération de retour de table MySQL ne nous permettra pas de renvoyer facilement la table car c'est un gaspillage considérable. Qu'est-ce que ça veut dire? Considérez l'exemple suivant.
Nous avons établi un index composite (nom, statut, adresse), qui est également stocké selon ce champ, similaire à l'image :
Arbre d'index composé (stocke uniquement les colonnes d'index et les clés primaires pour le retour de la table)
nom |
statut |
adresse |
id (clé primaire) |
Xiaomi 1 |
0 |
1 | 1 |
| Xiaomi 2 | 1 | 1 | 2 |


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!