
Maison >Périphériques technologiques >IA >Comment ChatGPT affiche-t-il mot par mot ?
Comment ChatGPT affiche-t-il mot par mot ?

- WBOYavant
- 2023-06-02 17:40:222136parcourir

Lorsque ChatGPT répond aux questions, il apparaît mot par mot, donnant aux gens le sentiment de réfléchir sérieusement.
Le contenu de base de cette conversation est le suivant :
Q : Comment fonctionnent les grands modèles génératifs de langage
A : Les grands modèles génératifs de langage (tels que GPT-3) sont des réseaux de neurones basés sur une technologie d'apprentissage profond ? Modèle. Ces modèles utilisent souvent une architecture appelée « Transformer », qui a connu un grand succès dans le domaine du traitement du langage naturel.Voici un aperçu du fonctionnement des modèles de génération de langage à grande échelle :
… Omettre un paragraphe…
Générer du texte : Une fois le modèle entraîné, vous pouvez l'utiliser pour Générez du texte. Étant donné un texte ou une invite initiale, le modèle génère le mot suivant en fonction de la distribution de probabilité qu'il a apprise, puis utilise le mot généré comme entrée et continue de générer le mot suivant, et ainsi de suite jusqu'à ce que la longueur de texte souhaitée soit atteinte ou générée. symbole.
... Omettre un paragraphe...
Grand modèle de langage, appelé LLM.
Du point de vue du modèle, LLM génère un jeton à chaque fois qu'il effectue une inférence jusqu'à ce que la limite de longueur du texte soit atteinte ou qu'un terminateur soit généré.
Du point de vue du serveur, les jetons générés doivent être renvoyés au navigateur un par un via le protocole HTTPS.
En mode Client-Serveur, la méthode d'interaction conventionnelle est que le client envoie une requête et reçoit une réponse. Évidemment, cela ne peut pas répondre au scénario où ChatGPT répond aux questions.
Deuxièmement, nous pouvons penser à websocket, qui s'appuie sur HTTP pour implémenter la poignée de main et est mis à niveau vers WebSocket. Cependant, WebSocket nécessite que le client et le serveur occupent en permanence un socket, et le coût côté serveur est relativement élevé.
ChatGPT utilise un compromis : l'événement envoyé par le serveur (SSE en abrégé). Nous pouvons trouver ceci dans la documentation de l'API d'OpenAI :
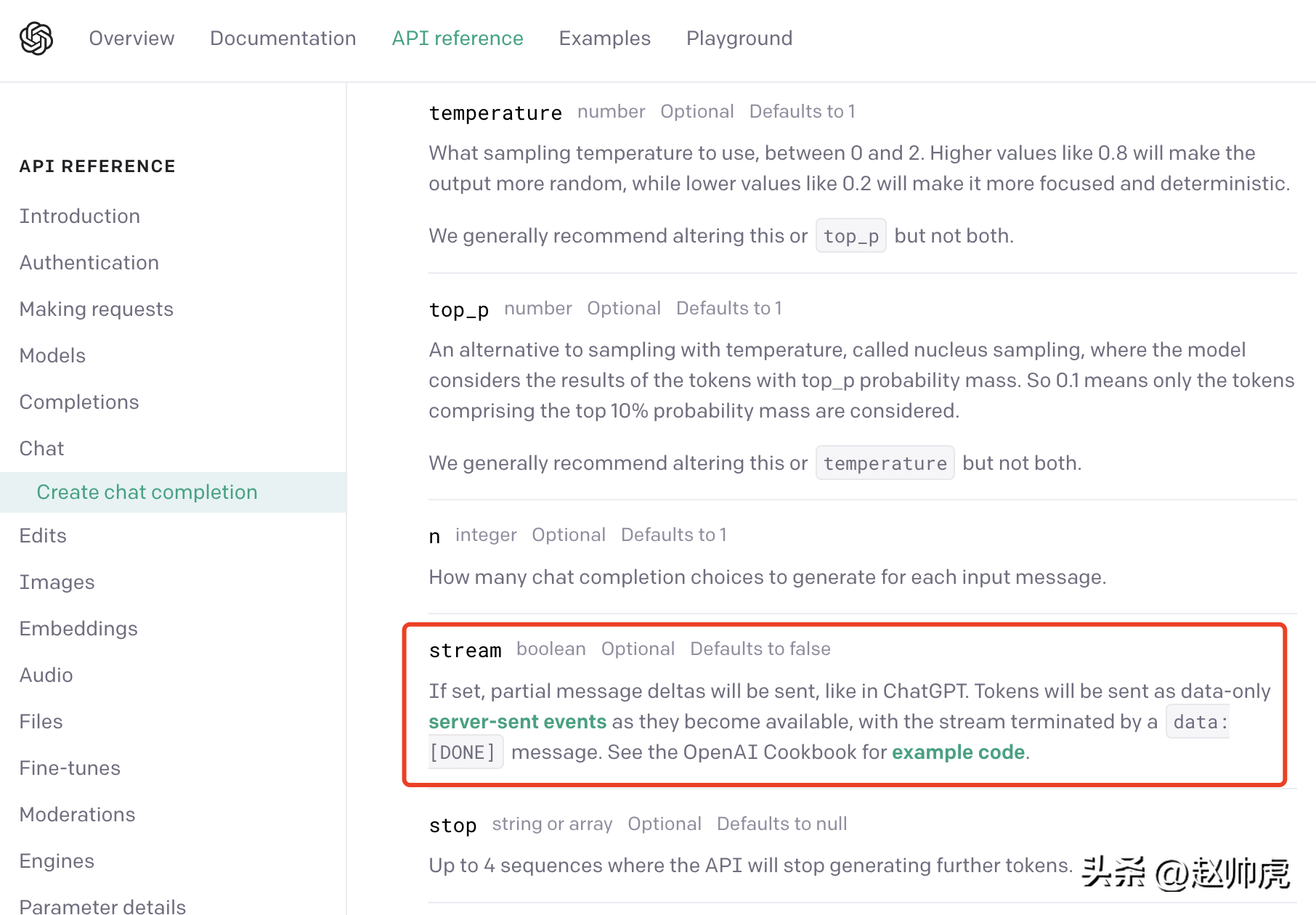
En mode SSE, le client n'a besoin d'envoyer des messages au serveur qu'une seule fois. demandé, le serveur peut continuer à produire jusqu'à ce que la fin soit nécessaire. L'ensemble du processus d'interaction est illustré dans la figure ci-dessous :
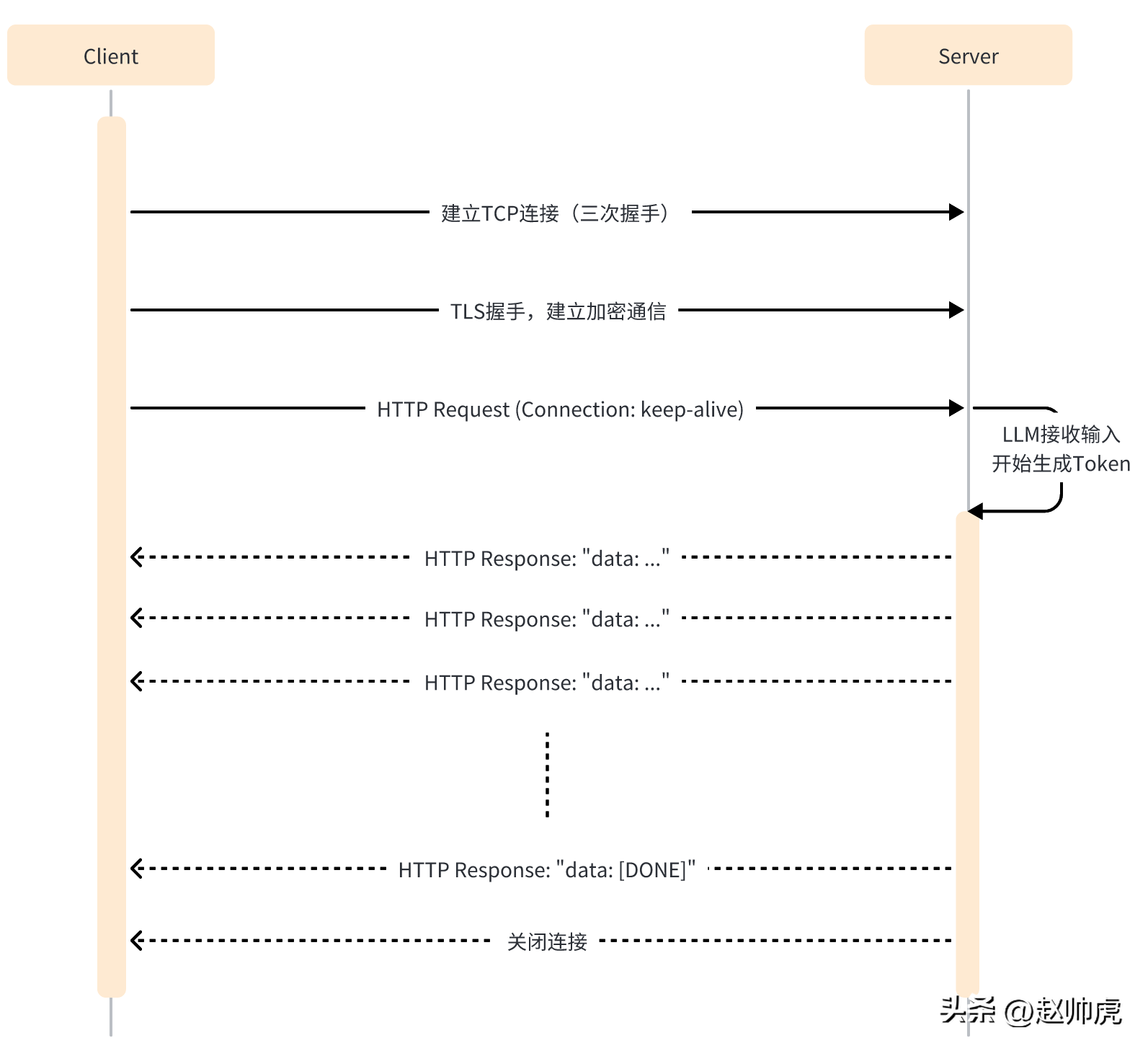
SSE utilise toujours HTTP comme protocole de transmission de couche application, exploitant pleinement la capacité de connexion longue de HTTP pour obtenir des capacités push côté serveur.
Au niveau du code, les différences entre le mode SSE et une seule requête HTTP sont :
- Le client doit activer le maintien en vie pour s'assurer que la connexion n'expirera pas.
- L'en-tête de réponse HTTP contient Content-Type=text/event-stream, Cache-Cnotallow=no-cache, etc.
- Le corps de la réponse HTTP est généralement une structure du type "data:...".
- Il peut y avoir des données vides dans la réponse HTTP pour éviter l'expiration du délai de connexion.
En prenant l'API ChatGPT comme exemple, lors de l'envoi d'une requête, définir le paramètre stream sur true active la fonctionnalité SSE, mais vous devez faire un peu attention au SDK qui lit les données.
En mode normal, après avoir obtenu http.Response, utilisez ioutil.ReadAll pour lire les données. Le code est le suivant :
func main() {payload := strings.NewReader(`{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "大语言生成式模型是如何工作的"}],"max_tokens": 1024,"temperature": 1,"top_p": 1,"n": 1,"stream": false}`)client := &http.Client{}req, _ := http.NewRequest("POST", "https://api.openai.com/v1/chat/completions", payload)req.Header.Add("Content-Type", "application/json")req.Header.Add("Authorization", "Bearer <openai-token>")resp, err := client.Do(req)if err != nil {fmt.Println(err)return}defer resp.Body.Close()body, _ := ioutil.ReadAll(resp.Body)fmt.Println(string(body))}</openai-token>
L'exécution prend environ 20 s+ et nous obtenons un résultat complet :
{"id": "chatcmpl-7KklTf9mag5tyBXLEqM3PWQn4jlfD","object": "chat.completion","created": 1685180679,"model": "gpt-3.5-turbo-0301","usage": {"prompt_tokens": 21,"completion_tokens": 358,"total_tokens": 379},"choices": [{"message": {"role": "assistant","content": "大语言生成式模型通常采用神经网络来实现,具体工作流程如下:\n\n1. 数据预处理:将语料库中的文本数据进行预处理,包括分词、删除停用词(如“的”、“了”等常用词汇)、去重等操作,以减少冗余信息。\n\n2. 模型训练:采用递归神经网络(RNN)、长短期记忆网络(LSTM)或变种的Transformers等模型进行训练,这些模型都具有一定的记忆能力,可以学习到语言的一定规律,并预测下一个可能出现的词语。\n\n3. 模型应用:当模型完成训练后,可以将其应用于实际的生成任务中。模型接收一个输入文本串,并预测下一个可能出现的词语,直到达到一定长度或遇到结束符号为止。\n\n4. 根据生成结果对模型进行调优:生成的结果需要进行评估,如计算生成文本与语料库文本的相似度、流畅度等指标,以此来调优模型,提高其生成质量。\n\n总体而言,大语言生成式模型通过对语言的规律学习,从而生成高质量的文本。"},"finish_reason": "stop","index": 0}]}
Si nous définissons le flux sur true sans apporter aucune modification, la consommation totale de la requête est de 28 s+, ce qui se reflète dans de nombreux messages de flux :
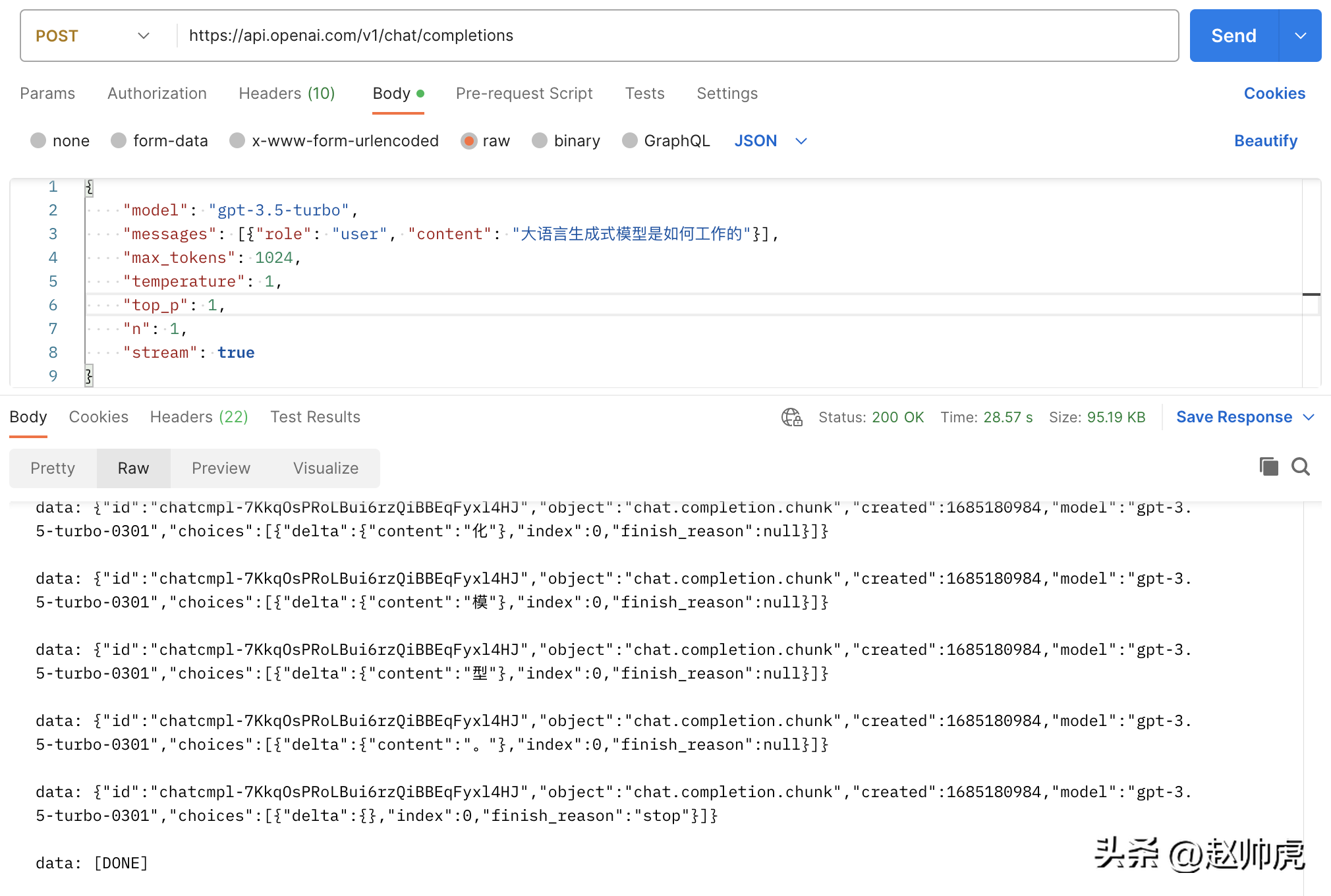
L'image ci-dessus est une image de Postman appelant l'API chatgpt, en utilisant le mode ioutil.ReadAll. Afin d'implémenter la lecture de flux, nous pouvons lire http.Response.Body en segments. Voici la raison pour laquelle cette méthode est réalisable :
- http.Response.Body est de type io.ReaderCloser La couche sous-jacente repose sur une connexion HTTP et prend en charge la lecture de flux.
- Les données renvoyées par SSE sont divisées par le caractère de nouvelle ligne n
La méthode de correction consiste donc à les envelopper dans bufio.NewReader(resp.Body) et à les lire dans une boucle for , Le code est le suivant :
// stream event 结构体定义type ChatCompletionRspChoiceItem struct {Deltamap[string]string `json:"delta,omitempty"` // 只有 content 字段Indexint `json:"index,omitempty"`Logprobs *int`json:"logprobs,omitempty"`FinishReason string`json:"finish_reason,omitempty"`}type ChatCompletionRsp struct {IDstring`json:"id"`Objectstring`json:"object"`Created int `json:"created"` // unix secondModel string`json:"model"`Choices []ChatCompletionRspChoiceItem `json:"choices"`}func main() {payload := strings.NewReader(`{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "大语言生成式模型是如何工作的"}],"max_tokens": 1024,"temperature": 1,"top_p": 1,"n": 1,"stream": true}`)client := &http.Client{}req, _ := http.NewRequest("POST", "https://api.openai.com/v1/chat/completions", payload)req.Header.Add("Content-Type", "application/json")req.Header.Add("Authorization", "Bearer "+apiKey)req.Header.Set("Accept", "text/event-stream")req.Header.Set("Cache-Control", "no-cache")req.Header.Set("Connection", "keep-alive")resp, err := client.Do(req)if err != nil {fmt.Println(err)return}defer resp.Body.Close()reader := bufio.NewReader(resp.Body)for {line, err := reader.ReadBytes('\n')if err != nil {if err == io.EOF {// 忽略 EOF 错误break} else {if netErr, ok := err.(net.Error); ok && netErr.Timeout() {fmt.Printf("[PostStream] fails to read response body, timeout\n")} else {fmt.Printf("[PostStream] fails to read response body, err=%s\n", err)}}break}line = bytes.TrimSuffix(line, []byte{'\n'})line = bytes.TrimPrefix(line, []byte("data: "))if bytes.Equal(line, []byte("[DONE]")) {break} else if len(line) > 0 {var chatCompletionRsp ChatCompletionRspif err := json.Unmarshal(line, &chatCompletionRsp); err == nil {fmt.Printf(chatCompletionRsp.Choices[0].Delta["content"])} else {fmt.Printf("\ninvalid line=%s\n", line)}}}fmt.Println("the end")}
Après avoir lu le côté client, regardons le côté serveur. Nous essayons maintenant de nous moquer du serveur chatgpt et de renvoyer un morceau de texte textuellement. Deux points sont impliqués ici :
- Response Header doit définir Connection sur keep-alive et Content-Type sur text/event-stream.
- Après avoir rédigé la réponse, celle-ci doit être transmise au client.
Le code est le suivant :
func streamHandler(w http.ResponseWriter, req *http.Request) {w.Header().Set("Connection", "keep-alive")w.Header().Set("Content-Type", "text/event-stream")w.Header().Set("Cache-Control", "no-cache")var chatCompletionRsp ChatCompletionRsprunes := []rune(`大语言生成式模型通常使用深度学习技术,例如循环神经网络(RNN)或变压器(Transformer)来建模语言的概率分布。这些模型接收前面的词汇序列,并利用其内部神经网络结构预测下一个词汇的概率分布。然后,模型将概率最高的词汇作为生成的下一个词汇,并递归地生成一个词汇序列,直到到达最大长度或遇到一个终止符号。在训练过程中,模型通过最大化生成的文本样本的概率分布来学习有效的参数。为了避免模型产生过于平凡的、重复的、无意义的语言,我们通常会引入一些技巧,如dropout、序列扰动等。大语言生成模型的重要应用包括文本生成、问答系统、机器翻译、对话建模、摘要生成、文本分类等。`)for _, r := range runes {chatCompletionRsp.Choices = []ChatCompletionRspChoiceItem{{Delta: map[string]string{"content": string(r)}},}bs, _ := json.Marshal(chatCompletionRsp)line := fmt.Sprintf("data: %s\n", bs)fmt.Fprintf(w, line)if f, ok := w.(http.Flusher); ok {f.Flush()}time.Sleep(time.Millisecond * 100)}fmt.Fprintf(w, "data: [DONE]\n")}func main() {http.HandleFunc("/stream", streamHandler)http.ListenAndServe(":8088", nil)}
Dans un scénario réel, les données à renvoyer proviennent d'un autre appel de service ou de fonction. Si l'heure de retour de cet appel de service ou de fonction est instable, le client peut. ne pas pouvoir recevoir de données pendant une longue période. La méthode de traitement générale est donc la suivante :
- Mettez l'appel au tiers dans une goroutine.
- Créez une minuterie dans le temps. Cochez et envoyez un message vide au client.
- Créez un canal de délai d'attente pour éviter un temps de réponse trop long.
Afin de pouvoir lire les données de différents canaux, select est un bon mot-clé, comme ce code de démonstration :
// 声明一个 event channel// 声明一个 time.Tick channel// 声明一个 timeout channelselect {case ev := <h2>Pour résumer</h2><p style="text-align: justify;"><span style="color: #333333;">Le processus de génération d'une réponse au résultat complet d'un le grand modèle de langage est relativement long Oui, mais la réponse générée jeton par jeton est relativement rapide. ChatGPT combine pleinement cette fonctionnalité avec la technologie SSE pour afficher des réponses mot par mot, obtenant ainsi une amélioration qualitative de l'expérience utilisateur. </span></p><p style="text-align: justify;"><span style="color: #333333;">Regard sur les modèles génératifs, qu'il s'agisse de LAMA/Petit Alpaga (non disponible dans le commerce) ou de Diffusion Stable/Midjourney. Lors de la fourniture de services en ligne, la technologie SSE peut être utilisée pour améliorer l'expérience utilisateur et économiser les ressources du serveur. </span></p>Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI