
Maison >base de données >Redis >Quels sont les points de connaissance complets de Redis ?
Quels sont les points de connaissance complets de Redis ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-02 17:14:251128parcourir
Introduction à Redis
Redis est entièrement open source et gratuit, est conforme au protocole BSD et est une base de données clé-valeur hautes performances
Redis présente les trois caractéristiques suivantes avec d'autres produits de cache clé-valeur :
Redis prend en charge la persistance des données peut enregistrer les données de la mémoire sur le disque et les charger à nouveau pour les utiliser lors du redémarrage.
Redis prend non seulement en charge les données simples de type clé-valeur, mais fournit également le stockage de structures de données telles que la liste, l'ensemble, le zset, le hachage, etc.
Redis prend en charge la sauvegarde des données, c'est-à-dire le mode maître-esclave sauvegarde des données
Avantages de Redis
Performances extrêmement élevées - La vitesse de lecture de Redis est de 110 000 fois/s et la vitesse d'écriture est de 81 000 fois/s.
Types de données riches - Redis prend en charge les opérations de type de données Chaînes, Listes, Hachages, Ensembles et Ensembles ordonnés pour les cas binaires.
Atomicité - Toutes les opérations de Redis sont atomiques, ce qui signifie qu'elles sont soit exécutées avec succès, soit pas exécutées du tout. Les opérations individuelles sont atomiques. Des transactions de plusieurs opérations peuvent être mises en œuvre à l'aide des instructions MULTI et EXEC pour garantir l'atomicité.
Autres fonctionnalités - Redis prend également en charge les notifications de publication/abonnement, l'expiration des clés et d'autres fonctionnalités.
Type de données Redis
Redis prend en charge 5 types de données : string (string), hash (hash), list (list), set (set), zset (ensemble trié : ensemble ordonné)
string
string est le type de données le plus basique de Redis. Une clé correspond à une valeur.
string est sécurisé en binaire. C'est-à-dire que la chaîne de redis peut contenir n'importe quelle donnée. Par exemple, des images jpg ou des objets sérialisés.
L'un des types de données de base de Redis est le type chaîne, et la taille de la valeur du type chaîne peut aller jusqu'à 512 Mo.
Comprendre : la chaîne est comme une carte en Java, une clé correspond à une valeur
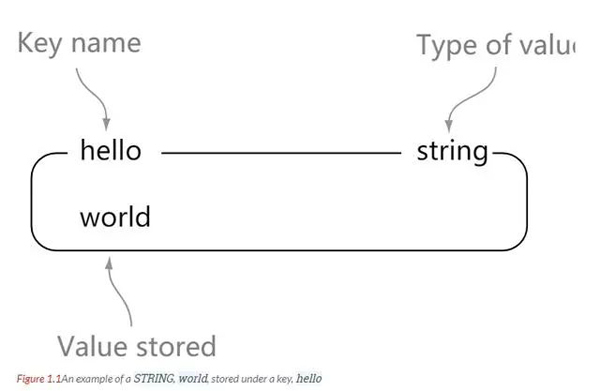
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> get hello "world"
hash
La collection de hachage est un type de données Redis composé de paires clé-valeur. Le hachage Redis est une table de mappage de clés et de valeurs de type chaîne. Le hachage est particulièrement adapté au stockage d'objets.
Compréhension : Vous pouvez considérer le hachage comme un ensemble clé-valeur. Vous pouvez également le considérer comme un hachage correspondant à plusieurs chaînes. La différence entre
et string : la chaîne est une paire clé-valeur, tandis que le hachage est constitué de plusieurs paires clé-valeur.
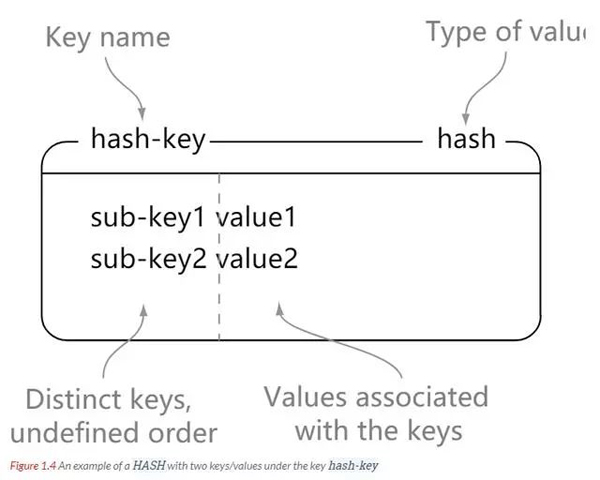
// hash-key 可以看成是一个键值对集合的名字,在这里分别为其添加了 sub-key1 : value1、 sub-key2 : value2、sub-key3 : value3 这三个键值对 127.0.0.1:6379> hset hash-key sub-key1 value1 (integer) 1 127.0.0.1:6379> hset hash-key sub-key2 value2 (integer) 1 127.0.0.1:6379> hset hash-key sub-key3 value3 (integer) 1 // 获取 hash-key 这个 hash 里面的所有键值对 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key2" 4) "value2" 5) "sub-key3" 6) "value3" // 删除 hash-key 这个 hash 里面的 sub-key2 键值对 127.0.0.1:6379> hdel hash-key sub-key2 (integer) 1 127.0.0.1:6379> hget hash-key sub-key2 (nil) 127.0.0.1:6379> hget hash-key sub-key1 "value1" 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key3" 4) "value3"
list
Les listes Redis sont de simples listes de chaînes, triées par ordre d'insertion. Nous pouvons ajouter des éléments à gauche ou à droite de la liste.
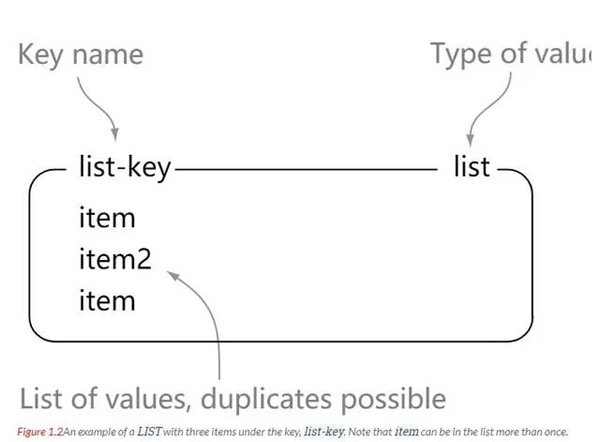
127.0.0.1:6379> rpush list-key v1 (integer) 1 127.0.0.1:6379> rpush list-key v2 (integer) 2 127.0.0.1:6379> rpush list-key v1 (integer) 3 127.0.0.1:6379> lrange list-key 0 -1 1) "v1" 2) "v2" 3) "v1" 127.0.0.1:6379> lindex list-key 1 "v2" 127.0.0.1:6379> lpop list (nil) 127.0.0.1:6379> lpop list-key "v1" 127.0.0.1:6379> lrange list-key 0 -1 1) "v2" 2) "v1"
Nous pouvons voir que cette liste est une simple collection de chaînes, ce qui n'est pas très différent de la liste en Java. La différence est que la liste ici stocke les chaînes. Les éléments de la liste sont répétables. L'ensemble de
set
redis est une collection non ordonnée de type chaîne. Étant donné que l'ensemble est implémenté en utilisant la structure de données d'une table de hachage, la complexité temporelle de ses opérations d'insertion, de suppression et de recherche est O(1)
127.0.0.1:6379> sadd k1 v1 (integer) 1 127.0.0.1:6379> sadd k1 v2 (integer) 1 127.0.0.1:6379> sadd k1 v3 (integer) 1 127.0.0.1:6379> sadd k1 v1 (integer) 0 127.0.0.1:6379> smembers k1 1) "v3" 2) "v2" 3) "v1" 127.0.0.1:6379> 127.0.0.1:6379> sismember k1 k4 (integer) 0 127.0.0.1:6379> sismember k1 v1 (integer) 1 127.0.0.1:6379> srem k1 v2 (integer) 1 127.0.0.1:6379> srem k1 v2 (integer) 0 127.0.0.1:6379> smembers k1 1) "v3" 2) "v1"
L'ensemble de redis est quelque peu différent de l'ensemble de Java.
L'ensemble de redis est une clé correspondant à plusieurs valeurs de type chaîne, et c'est également une collection de type chaîne. Cependant, contrairement à la liste de redis, les éléments de la collection de chaînes dans l'ensemble ne peuvent pas être répétés, mais la liste le peut.
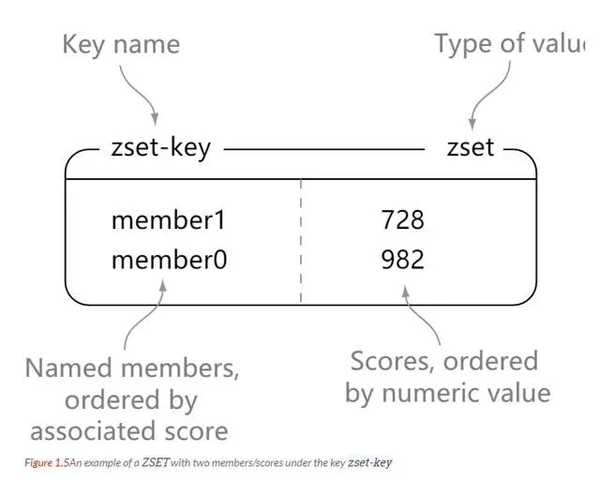
Zset
redis zset, comme set, est une collection d'éléments de type chaîne, et les éléments de l'ensemble ne peuvent pas être répétés.
La différence est que chaque élément de zset est associé à un score de type double. Redis utilise des scores pour trier les membres de l'ensemble de petit à grand. Les éléments de
zset sont uniques, mais les scores peuvent être répétés.
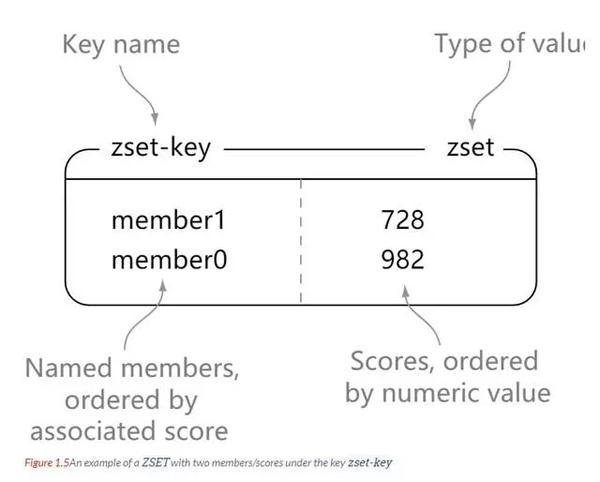
127.0.0.1:6379> zadd zset-key 728 member1 (integer) 1 127.0.0.1:6379> zadd zset-key 982 member0 (integer) 1 127.0.0.1:6379> zadd zset-key 982 member0 (integer) 0 127.0.0.1:6379> zrange zset-key 0 -1 withscores 1) "member1" 2) "728" 3) "member0" 4) "982" 127.0.0.1:6379> zrangebyscore zset-key 0 800 withscores 1) "member1" 2) "728" 127.0.0.1:6379> zrem zset-key member1 (integer) 1 127.0.0.1:6379> zrem zset-key member1 (integer) 0 127.0.0.1:6379> zrange zset-key 0 -1 withscores 1) "member0" 2) "982"
zset est trié en fonction de la taille du score.
Publier et s'abonner
Généralement, Redis n'est pas utilisé pour la publication de messages et l'abonnement.
Introduction
Redis publier et s'abonner (pub/sub) est un modèle de communication par message : l'expéditeur (pub) envoie des messages et les abonnés (sub) reçoivent des messages.
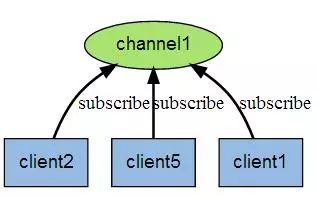
Les clients Redis peuvent s'abonner à n'importe quel nombre de chaînes.
La figure suivante montre la relation entre le canal canal1 et les trois clients abonnés à ce canal - client2, client5 et client1 :
学Redis这篇就够了
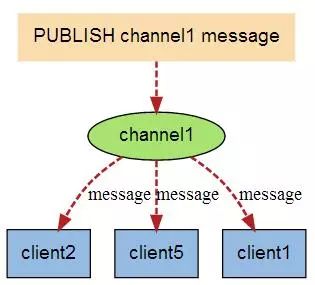
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
学Redis这篇就够了
实例
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
127.0.0.1:6379> SUBsCRIBE redisChat Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "redisChat"
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
127.0.0.1:6379> PUBLISH redisChat "send message" (integer) 1 127.0.0.1:6379> PUBLISH redisChat "hello world" (integer) 1 # 订阅者的客户端显示如下 1) "message" 2) "redisChat" 3) "send message" 1) "message" 2) "redisChat" 3) "hello world"
事务
redis 事务一次可以执行多条命令,服务器在执行命令期间,不会去执行其他客户端的命令请求。
事务中的多条命令被一次性发送给服务器,而不是一条一条地发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
批量操作在发送 EXEC 命令前被放入队列缓存。
在接收到 EXEC 命令后,进入事务执行。如果在事务中有命令执行失败,其他命令仍然会继续执行。也就是说 Redis 事务不保证原子性。
在事务执行过程中,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
开始事务。
命令入队。
执行事务。
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
redis 127.0.0.1:6379> MULTI OK redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days" QUEUED redis 127.0.0.1:6379> GET book-name QUEUED redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series" QUEUED redis 127.0.0.1:6379> SMEMBERS tag QUEUED redis 127.0.0.1:6379> EXEC 1) OK 2) "Mastering C++ in 21 days" 3) (integer) 3 4) 1) "Mastering Series" 2) "C++" 3) "Programming"
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
这是官网上的说明 From redis docs on transactions:
It's important to note that even when a command fails, all the other commands in the queue are processed – Redis will not stop the processing of commands.
比如:
redis 127.0.0.1:7000> multi OK redis 127.0.0.1:7000> set a aaa QUEUED redis 127.0.0.1:7000> set b bbb QUEUED redis 127.0.0.1:7000> set c ccc QUEUED redis 127.0.0.1:7000> exec 1) OK 2) OK 3) OK
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。
Redis 事务命令
下表列出了 redis 事务的相关命令:
序号命令及描述:
1. DISCARD 取消事务,放弃执行事务块内的所有命令。
2. EXEC 执行所有事务块内的命令。
3. MULTI 标记一个事务块的开始。
4. UNWATCH 取消 WATCH 命令对所有 key 的监视。
5. WATCH key [key …]监视一个 (或多个) key ,如果在事务执行之前这个 (或这些) key 被其他命令所改动,那么事务将被打断。
持久化
Redis 是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
RDB 持久化
将某个时间点的所有数据都存放到硬盘上。
可以将快照复制到其他服务器从而创建具有相同数据的服务器副本。
如果系统发生故障,将会丢失最后一次创建快照之后的数据。
如果数据量大,保存快照的时间会很长。
AOF 持久化
将写命令添加到 AOF 文件(append only file)末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。
这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。
选项同步频率always每个写命令都同步eyerysec每秒同步一次no让操作系统来决定何时同步
always 选项会严重减低服务器的性能
everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。
no 选项并不能给服务器性能带来多大的提升,而且会增加系统崩溃时数据丢失的数量。
随着服务器写请求的增多,AOF 文件会越来越大。Redis提供了一项称作AOF重写的功能,能够消除AOF文件中的重复写入命令。
复制
Faites d'un serveur l'esclave d'un autre serveur en utilisant la commande slaveof host port.
Un serveur esclave ne peut avoir qu'un seul serveur maître et la réplication maître-maître n'est pas prise en charge.
Processus de connexion
Le serveur maître crée un fichier instantané, c'est-à-dire un fichier RDB, et l'envoie au serveur esclave, et utilise le tampon pour enregistrer les commandes d'écriture exécutées lors de l'envoi.
Une fois le fichier instantané envoyé, commencez à envoyer les commandes d'écriture stockées dans le tampon depuis le serveur.
Le serveur esclave supprime toutes les anciennes données, charge le fichier d'instantané envoyé par le serveur maître, puis le serveur esclave commence à accepter les commandes d'écriture du serveur maître.
Chaque fois que le serveur maître exécute une commande d'écriture, il envoie la même commande d'écriture au serveur esclave.
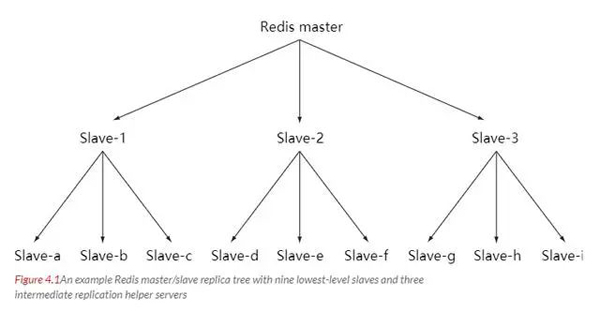
Chaîne maître-esclave
Lorsque la charge continue d'augmenter, si le serveur maître ne peut pas mettre à jour rapidement tous les serveurs esclaves, ou reconnecter et synchroniser les serveurs esclaves, le système sera surchargé.
Pour résoudre ce problème, une couche intermédiaire peut être établie pour réduire la charge de travail de réplication du serveur principal. Le serveur de niveau intermédiaire agit simultanément comme serveur esclave du serveur de niveau supérieur et comme serveur maître du serveur de niveau inférieur.
Sentinel
Sentinel peut surveiller les serveurs du cluster et élire automatiquement un nouveau serveur maître parmi les serveurs esclaves lorsque le serveur maître se déconnecte.
Sharding
Le partage est une méthode de division des données en plusieurs parties. Les données peuvent être stockées sur plusieurs machines. Cette méthode peut atteindre un niveau linéaire d'amélioration des performances lors de la résolution de certains problèmes.
Supposons qu'il y ait 4 instances Redis R0, R1, R2, R3 et de nombreuses clés représentant les utilisateurs user:1, user:2, …, il existe différentes manières de choisir dans quelle instance une clé spécifiée est stockée.
Le plus simple est le partage de plage, par exemple, les ID utilisateur de 0 à 1 000 sont stockés dans l'instance R0, les ID utilisateur de 1 001 à 2 000 sont stockés dans l'instance R1, et ainsi de suite. Cependant, cela nécessite de maintenir une table de plages de mappage, dont la maintenance est coûteuse.
Un autre exemple est le partage de hachage. Les instances qui doivent être stockées sont déterminées en exécutant une fonction de hachage CRC32 sur la clé, en la convertissant en nombre, puis en modulo le nombre d'instances.
Selon l'emplacement où le sharding est effectué, il peut être divisé en trois méthodes de sharding :
Sharding côté client : le client utilise des algorithmes tels que le hachage cohérent pour décider à quel nœud il doit être distribué.
Partage de proxy : envoyez la demande du client au proxy, et le proxy la transmet au bon nœud.
Sharding de serveur : Cluster Redis.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!