
Maison >base de données >tutoriel mysql >Comment faire en sorte que Spark SQL prenne en charge l'opération de mise à jour lors de l'écriture de MySQL
Comment faire en sorte que Spark SQL prenne en charge l'opération de mise à jour lors de l'écriture de MySQL

- PHPzavant
- 2023-06-02 15:19:211969parcourir
En plus de prendre en charge : Append, Overwrite, ErrorIfExists, Ignore ; il prend également en charge les opérations de mise à jour
1. Commencez par comprendre l'arrière-plan
spark fournit une classe d'énumération pour prendre en charge le mode de fonctionnement des sources de données d'ancrage
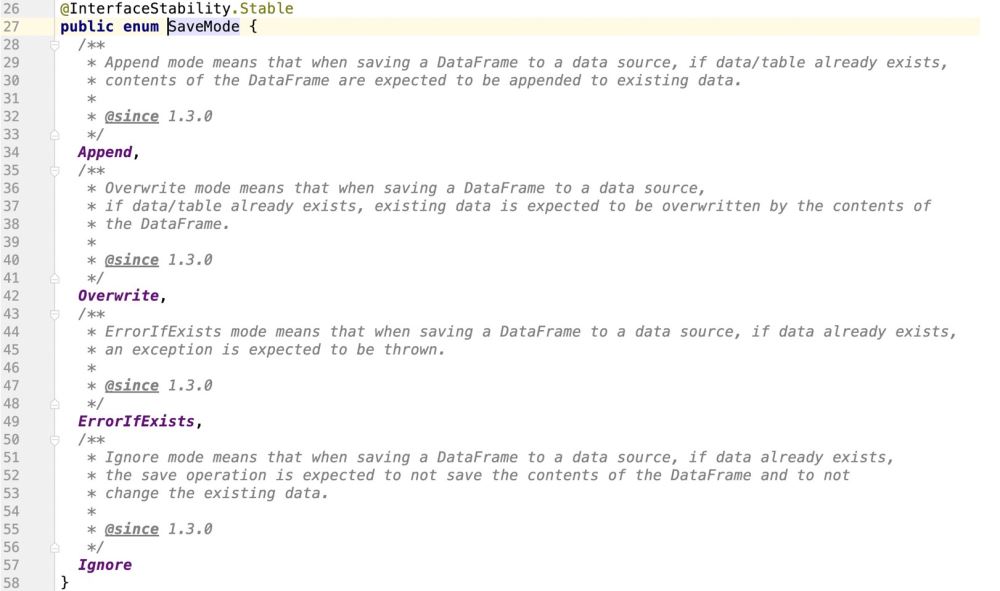
Pass Viewing. le code source, il est évident que Spark ne prend pas en charge les opérations de mise à jour
2. Comment mettre à jour le support SparkSQL
Les points de connaissance clés sont :
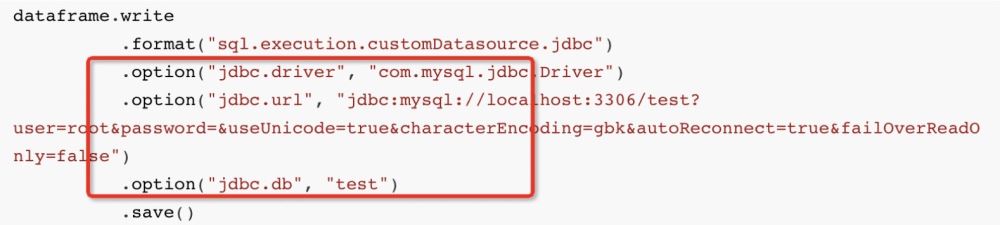
Lorsque nous écrivons normalement des données sur MySQL dans SparkSQL :
L'API approximative est :
dataframe.write
.format("sql.execution.customDatasource.jdbc")
.option("jdbc.driver", "com.mysql.jdbc.Driver")
.option("jdbc.url", "jdbc:mysql://localhost:3306/test?user=root&password=&useUnicode=true&characterEncoding=gbk&autoReconnect=true&failOverReadOnly=false")
.option("jdbc.db", "test")
.save()Ensuite, au niveau inférieur, Spark utilisera le dialecte JDBC JdbcDialect pour traduire les données dans lesquelles nous voulons insérer :
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
Ensuite, l'instruction SQL analysée via le dialecte sera soumise à MySQL via l'executeBatch() de PrepareStatement. les données sont insérées ;
Ensuite, l'instruction SQL ci-dessus est évidente, il s'agit d'une insertion complète de code, et il n'y a aucune opération de mise à jour à laquelle nous nous attendons, similaire à :
UPDATE table_name SET field1=new-value1, field2=new-value2
Mais MySQL prend exclusivement en charge une telle instruction SQL :
INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
La signification approximative c'est-à-dire que si les données n'existent pas, insérez-les. Si les données existent, effectuez l'opération de mise à jour ;
Notre objectif est donc de permettre à Spark SQL de générer de telles instructions SQL lors de l'ancrage interne avec JdbcDialect
INSERT INTO 表名称 (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
3. pour transformer le code source, vous devez comprendre le processus global de conception et d'exécution du code
Tout d'abord :
dataframe.write
Appeler la méthode d'écriture consiste à renvoyer une classe : DataFrameWriter
Principalement parce que DataFrameWriter est la classe transportant l'entrée pour que sparksql se connecte vers des sources de données externes. Le contenu suivant est enregistré pour DataFrameWriter Transportez les informations
Ensuite, après avoir démarré l'opération save(), commencez à écrire les données
Ensuite, regardez le code source save() :
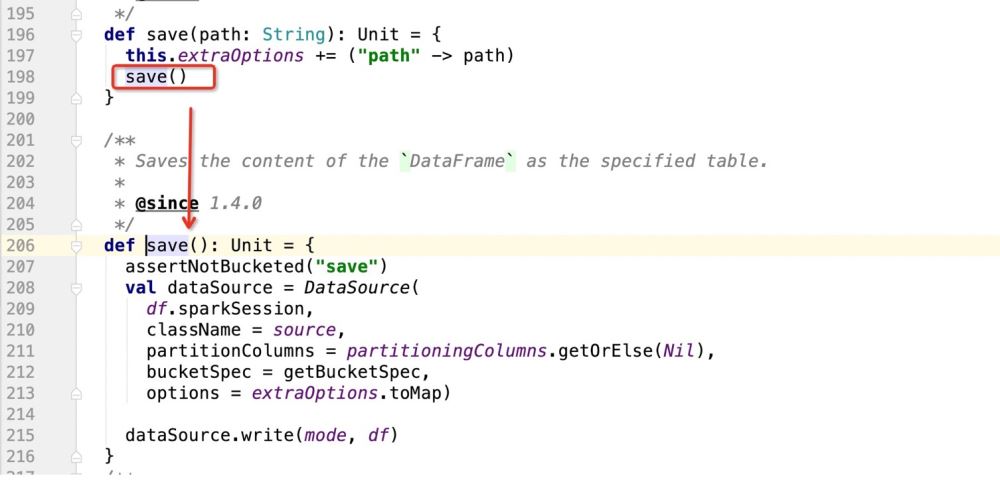
Dans le code source ci-dessus, l'essentiel est d'enregistrer l'instance DataSource, puis d'utiliser la méthode d'écriture de DataSource pour écrire des données
Lors de l'instanciation de DataSource :
def save(): Unit = {
assertNotBucketed("save")
val dataSource = DataSource(
df.sparkSession,
className = source,//自定义数据源的包路径
partitionColumns = partitioningColumns.getOrElse(Nil),//分区字段
bucketSpec = getBucketSpec,//分桶(用于hive)
options = extraOptions.toMap)//传入的注册信息
//mode:插入数据方式SaveMode , df:要插入的数据
dataSource.write(mode, df)
}Ensuite, il y a les détails de dataSource.write(mode, df). La logique entière est la suivante :
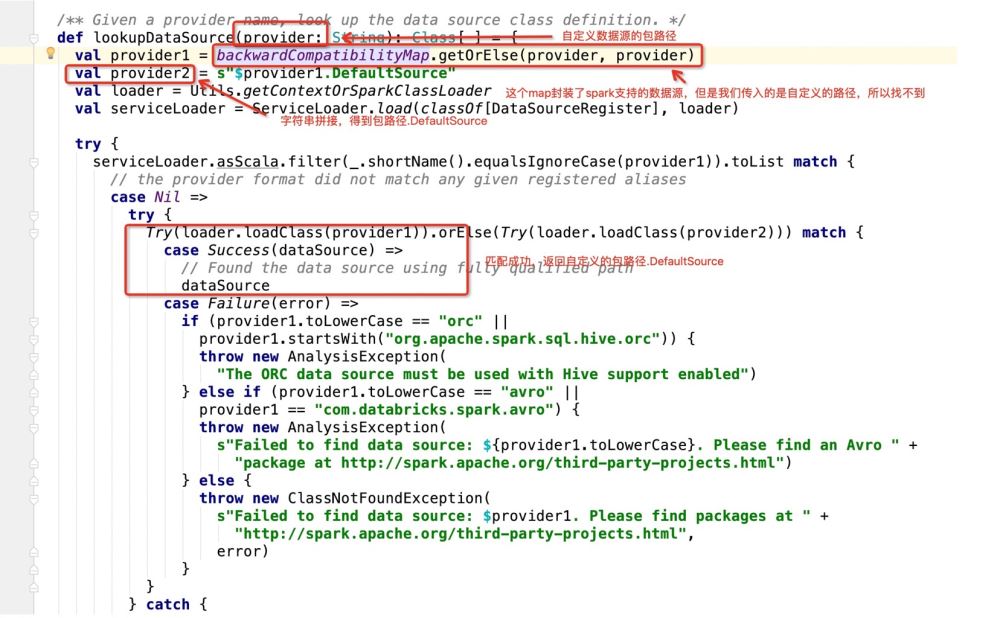
Créez le mode en fonction de provideClass.newInstance() Match, puis exécutez le code partout où il correspond ;
Après avoir obtenu le chemin du package.DefaultSource, le programme saisit : 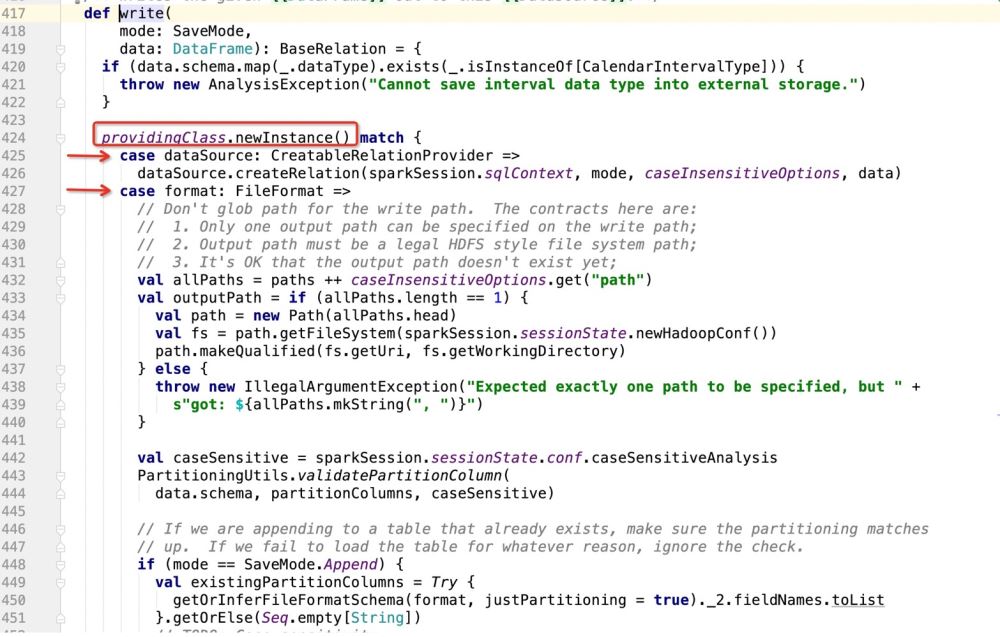
Ensuite, si la base de données est utilisée comme cible d'écriture, elle ira dans : dataSource.createRelation, et suivra directement le code source : 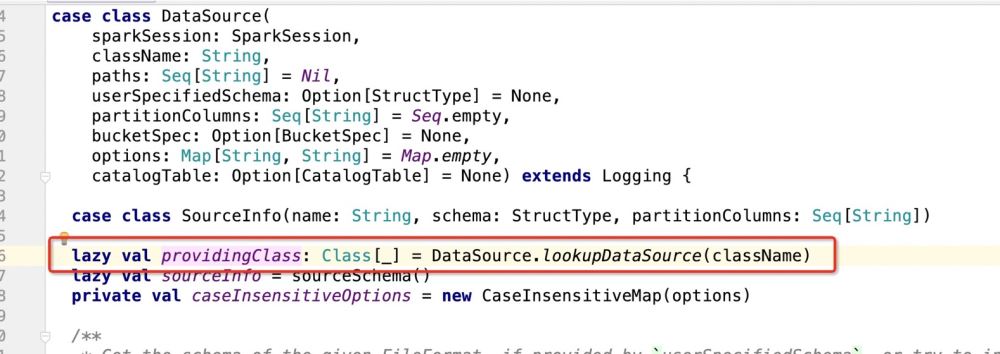
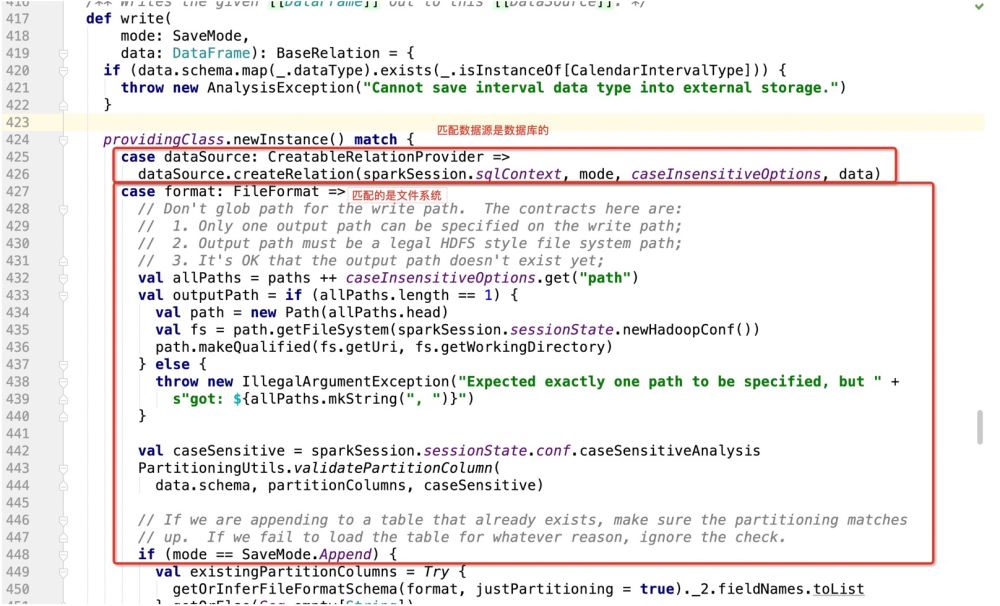 4. code
4. code
Selon le flux de code, l'opération finale d'écriture de données sparkSQL sur mysql sera Enter: package path.DefaultSource class
En d'autres termes, cette classe doit prendre en charge à la fois l'opération d'insertion normale (SaveMode) et l'opération de mise à jour de Spark. 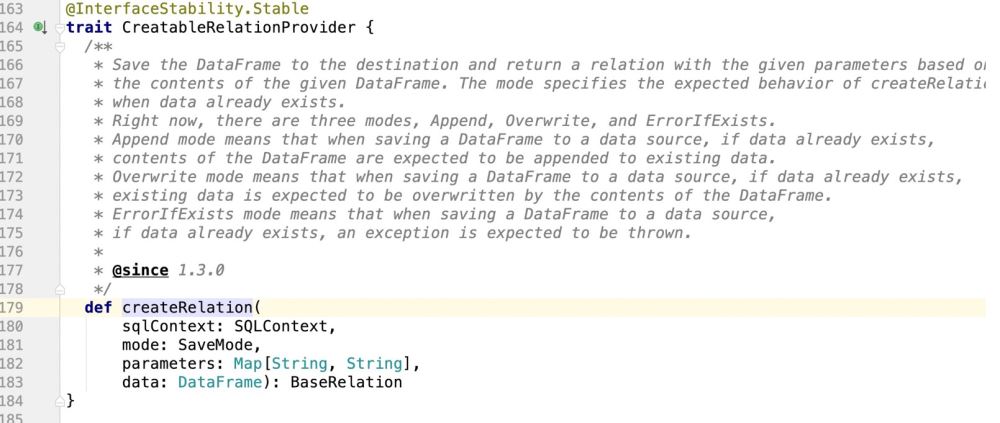
if(isUpdate){
sql语句:INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
}else{
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
} Cependant, dans le code source de l'instruction SQL de Spark Production, il est écrit comme ceci :
Il y a pas de logique de jugement, qui consiste finalement à en générer un :
INSERT INTO TABLE (字段1 , 字段2....) VALUES (? , ? ...)
La première tâche est donc de savoir comment le réaliser. Le code actuel prend en charge : LORS DE LA MISE À JOUR DE LA CLÉ EN DUPLICATE
Vous pouvez créer un design audacieux, c'est-à-dire porter le jugement suivant dans la méthode insertStatement
def insertStatement(conn: Connection, savemode:CustomSaveMode , table: String, rddSchema: StructType, dialect: JdbcDialect)
: PreparedStatement = {
val columns = rddSchema.fields.map(x => dialect.quoteIdentifier(x.name)).mkString(",")
val placeholders = rddSchema.fields.map(_ => "?").mkString(",")
if(savemode == CustomSaveMode.update){
//TODO 如果是update,就组装成ON DUPLICATE KEY UPDATE的模式处理
s"INSERT INTO $table ($columns) VALUES ($placeholders) ON DUPLICATE KEY UPDATE $duplicateSetting"
}esle{
val sql = s"INSERT INTO $table ($columns) VALUES ($placeholders)"
conn.prepareStatement(sql)
}
}De cette façon, dans le mode savemode transmis par l'utilisateur, nous effectuons une vérification, s'il s'agit d'une opération de mise à jour, renvoyons l'instruction sql correspondante !
Donc, selon la logique ci-dessus, notre code est écrit comme ceci : 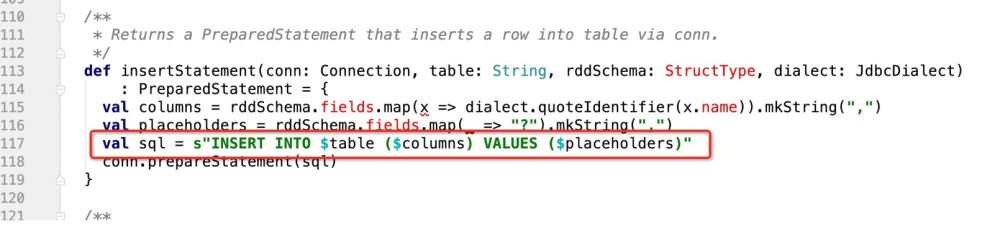
De cette façon, nous obtenons l'instruction sql correspondante
Mais seule cette instruction sql ne suffit pas, car l'opération prepareStatement de jdbc le fera. être exécuté dans Spark. Cela impliquera des curseurs.
Autrement dit, lorsque jdbc parcourt ce SQL, le code source fera ceci :
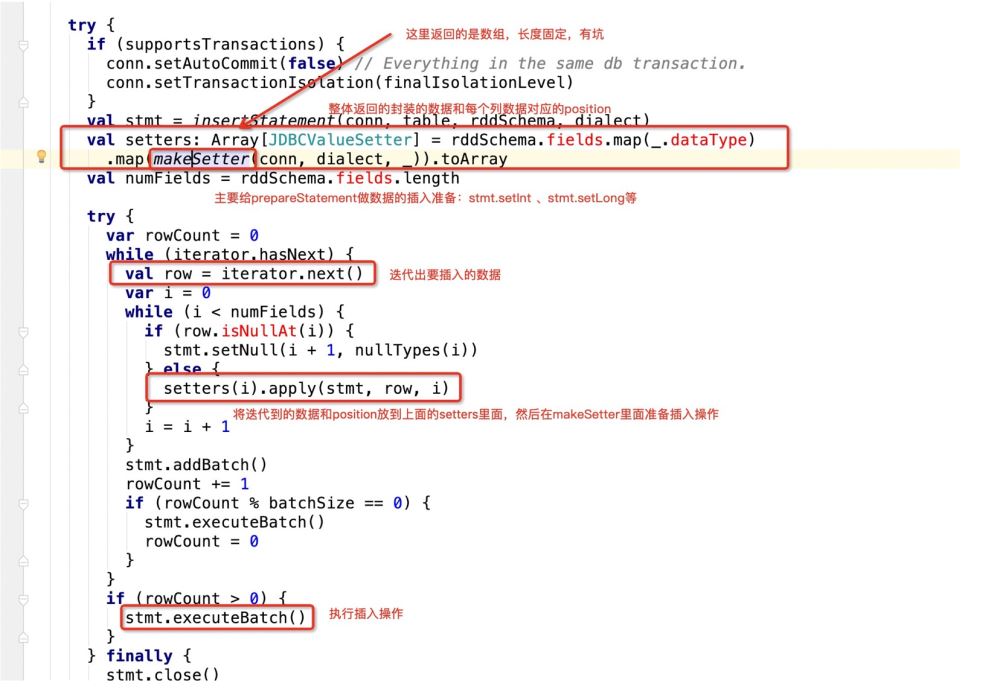
看下makeSetter:

所谓有坑就是:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?)
那么当前在源码中返回的数组长度应该是3:
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray但是如果我们此时支持了update操作,既:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?) ON DUPLICATE KEY UPDATE 字段1 = ?,字段2 = ?,字段3=?;
那么很明显,上面的sql语句提供了6个? , 但在规定字段长度的时候只有3
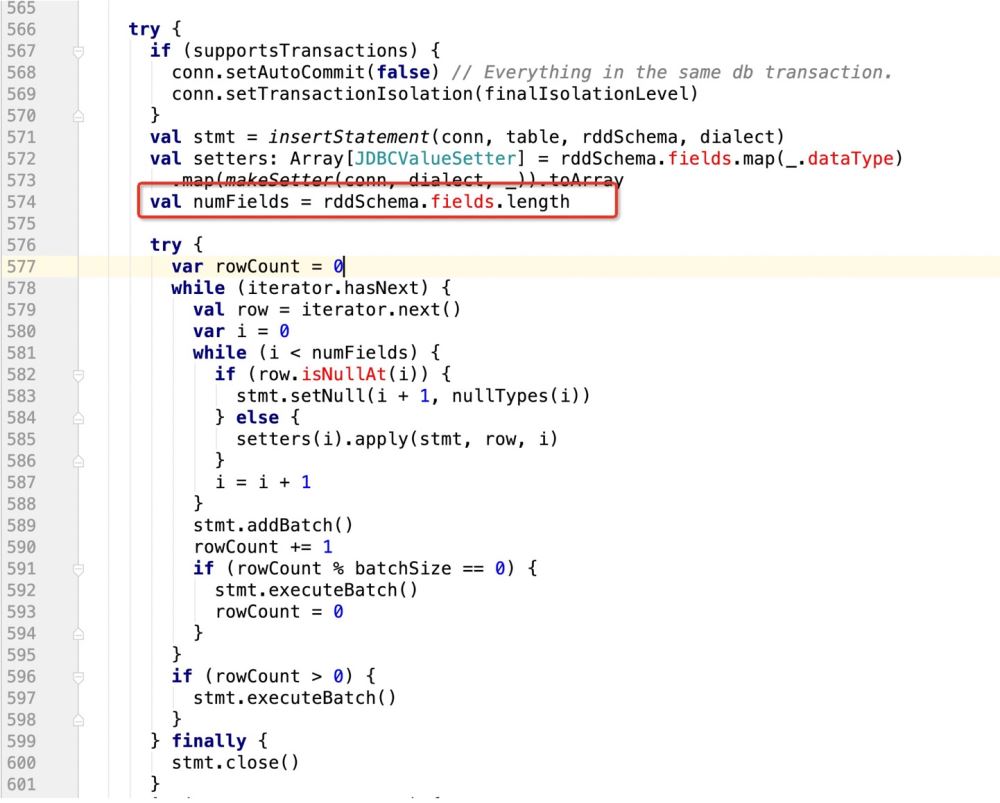
这样的话,后面的update操作就无法执行,程序报错!
所以我们需要有一个 识别机制,既:
if(isupdate){
val numFields = rddSchema.fields.length * 2
}else{
val numFields = rddSchema.fields.length
}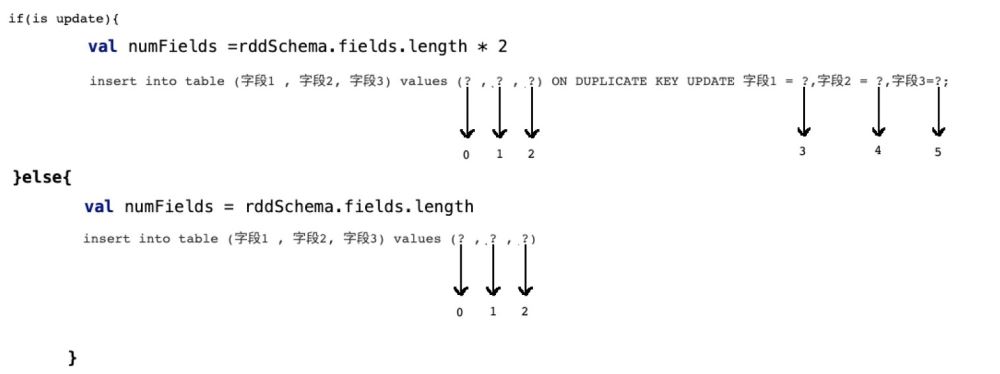
row[1,2,3] setter(0,1) //index of setter , index of row setter(1,2) setter(2,3) setter(3,1) setter(4,2) setter(5,3)
所以在prepareStatment中的占位符应该是row的两倍,而且应该是类似这样的一个逻辑
因此,代码改造前样子:
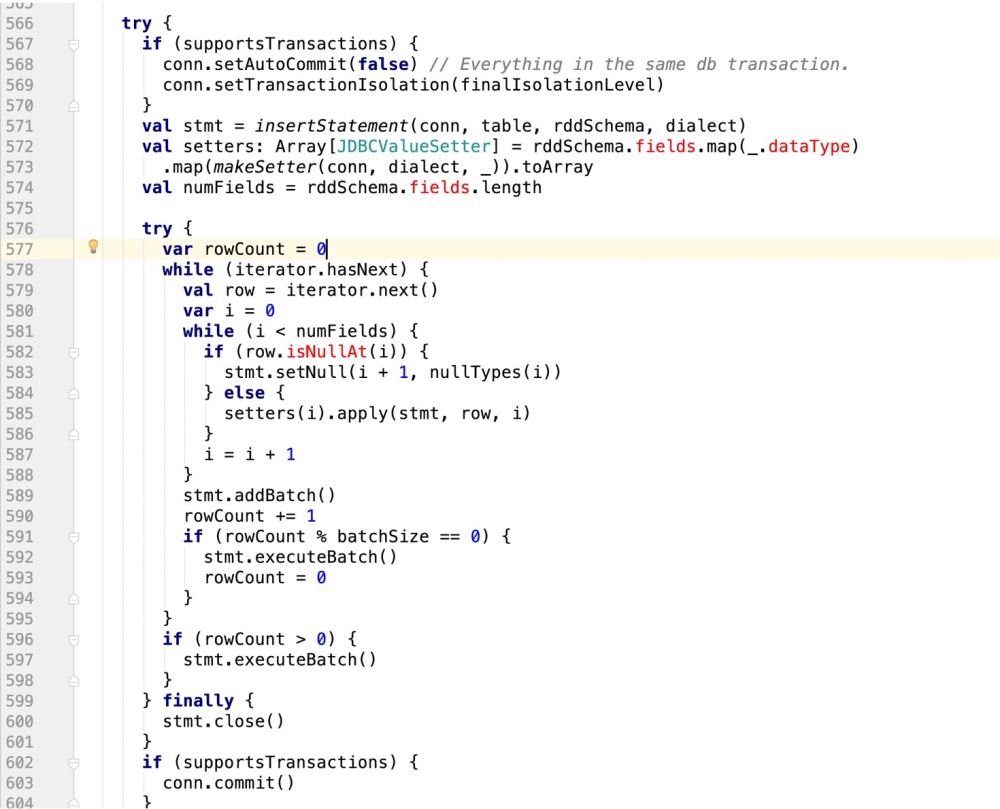
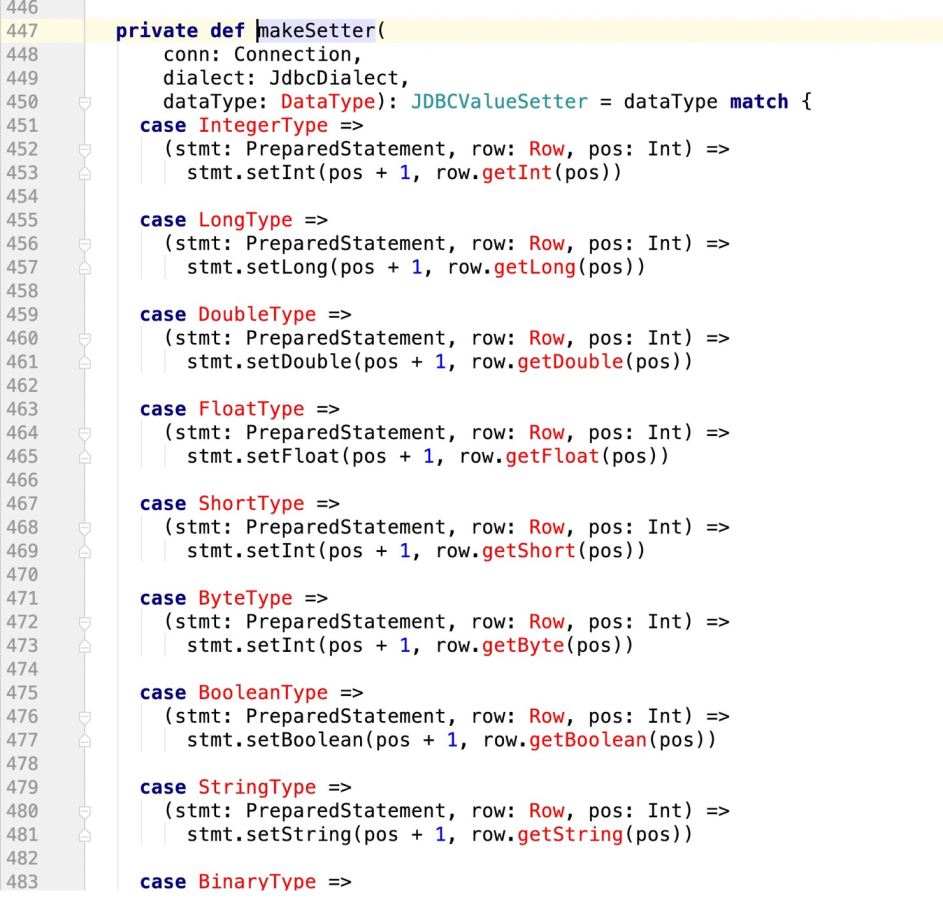
改造后的样子:
try {
if (supportsTransactions) {
conn.setAutoCommit(false) // Everything in the same db transaction.
conn.setTransactionIsolation(finalIsolationLevel)
}
// val stmt = insertStatement(conn, table, rddSchema, dialect)
//此处采用最新自己的sql语句,封装成prepareStatement
val stmt = conn.prepareStatement(sqlStmt)
println(sqlStmt)
/**
* 在mysql中有这样的操作:
* INSERT INTO user_admin_t (_id,password) VALUES ('1','第一次插入的密码')
* INSERT INTO user_admin_t (_id,password)VALUES ('1','第一次插入的密码') ON DUPLICATE KEY UPDATE _id = 'UpId',password = 'upPassword';
* 如果是下面的ON DUPLICATE KEY操作,那么在prepareStatement中的游标会扩增一倍
* 并且如果没有update操作,那么他的游标是从0开始计数的
* 如果是update操作,要算上之前的insert操作
* */
//makeSetter也要适配update操作,即游标问题
val isUpdate = saveMode == CustomSaveMode.Update
val setters: Array[JDBCValueSetter] = isUpdate match {
case true =>
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray
Array.fill(2)(setters).flatten
case _ =>
rddSchema.fields.map(_.dataType)
val numFieldsLength = rddSchema.fields.length
val numFields = isUpdate match{
case true => numFieldsLength *2
case _ => numFieldsLength
val cursorBegin = numFields / 2
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if(isUpdate){
//需要判断当前游标是否走到了ON DUPLICATE KEY UPDATE
i < cursorBegin match{
//说明还没走到update阶段
case true =>
//row.isNullAt 判空,则设置空值
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i, 0)
}
//说明走到了update阶段
case false =>
if (row.isNullAt(i - cursorBegin)) {
//pos - offset
stmt.setNull(i + 1, nullTypes(i - cursorBegin))
setters(i).apply(stmt, row, i, cursorBegin)
}
}else{
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i ,0)
}
//滚动游标
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
if (rowCount > 0) {
stmt.executeBatch()
} finally {
stmt.close()
conn.commit()
committed = true
Iterator.empty
} catch {
case e: SQLException =>
val cause = e.getNextException
if (cause != null && e.getCause != cause) {
if (e.getCause == null) {
e.initCause(cause)
} else {
e.addSuppressed(cause)
throw e
} finally {
if (!committed) {
// The stage must fail. We got here through an exception path, so
// let the exception through unless rollback() or close() want to
// tell the user about another problem.
if (supportsTransactions) {
conn.rollback()
conn.close()
} else {
// The stage must succeed. We cannot propagate any exception close() might throw.
try {
conn.close()
} catch {
case e: Exception => logWarning("Transaction succeeded, but closing failed", e)// A `JDBCValueSetter` is responsible for setting a value from `Row` into a field for
// `PreparedStatement`. The last argument `Int` means the index for the value to be set
// in the SQL statement and also used for the value in `Row`.
//PreparedStatement, Row, position , cursor
private type JDBCValueSetter = (PreparedStatement, Row, Int , Int) => Unit
private def makeSetter(
conn: Connection,
dialect: JdbcDialect,
dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int,cursor:Int) =>
stmt.setInt(pos + 1, row.getInt(pos - cursor))
case LongType =>
stmt.setLong(pos + 1, row.getLong(pos - cursor))
case DoubleType =>
stmt.setDouble(pos + 1, row.getDouble(pos - cursor))
case FloatType =>
stmt.setFloat(pos + 1, row.getFloat(pos - cursor))
case ShortType =>
stmt.setInt(pos + 1, row.getShort(pos - cursor))
case ByteType =>
stmt.setInt(pos + 1, row.getByte(pos - cursor))
case BooleanType =>
stmt.setBoolean(pos + 1, row.getBoolean(pos - cursor))
case StringType =>
// println(row.getString(pos))
stmt.setString(pos + 1, row.getString(pos - cursor))
case BinaryType =>
stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos - cursor))
case TimestampType =>
stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos - cursor))
case DateType =>
stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos - cursor))
case t: DecimalType =>
stmt.setBigDecimal(pos + 1, row.getDecimal(pos - cursor))
case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase.split("\\(")(0)
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos - cursor).toArray)
stmt.setArray(pos + 1, array)
case _ =>
(_: PreparedStatement, _: Row, pos: Int,cursor:Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!