
Maison >Opération et maintenance >Sécurité >Analyse des instances de panne de serveur
Analyse des instances de panne de serveur

- 王林avant
- 2023-06-02 15:12:051367parcourir
1. Quelque chose s'est mal passé
Étant donné que nous sommes dans l'industrie informatique, nous devons faire face à des pannes et des problèmes chaque jour, c'est pourquoi nous pouvons être appelés pompiers, courant partout pour résoudre les problèmes. Cependant, l'étendue du défaut est cette fois un peu grande et la machine hôte ne peut pas être ouverte.
Heureusement, le système de surveillance a laissé des preuves.
Des preuves ont montré que le processeur, la mémoire et les descripteurs de fichiers de la machine ont continué à augmenter avec la croissance de l'activité... jusqu'à ce que la surveillance ne puisse plus collecter les informations.
Le pire, c'est qu'il y a beaucoup de processus Java déployés sur ces hôtes. Sans autre raison que des économies, les candidatures ont été mélangées. Lorsqu’un hôte présente des anomalies globales, il peut être difficile d’en trouver le coupable.
La connexion à distance ayant expiré, le personnel d'exploitation et de maintenance impatient ne peut choisir que de redémarrer la machine et de commencer à redémarrer les applications après le redémarrage. Après une longue attente, tous les processus sont revenus à un fonctionnement normal, mais après seulement une courte période de temps, la machine hôte est soudainement tombée en panne.
L'entreprise est dans une impasse, ce qui est vraiment ennuyeux. Cela rend également les gens anxieux. Après plusieurs tentatives, l'exploitation et la maintenance se sont effondrées, et le plan d'urgence a été lancé : rollback !
Il y a beaucoup d'enregistrements en ligne récents, et il y a des développeurs qui se connectent et déploient en privé : Quoi. devrait être annulé ? Quoi d'autre ? Quelqu'un a soudainement eu une idée brillante et s'est rappelé qu'il existe également une commande find. Recherchez ensuite tous les packages jar récemment mis à jour et annulez-les.
find /apps/deploy -mtime +3 | grep jar$
Si vous ne connaissez pas la commande find, c'est vraiment un désastre. Heureusement, quelqu'un le sait.
J'ai annulé plus d'une douzaine de packages jar. Heureusement, il n'y a eu aucun changement de schéma dans la base de données et le système a finalement fonctionné normalement.
2. Trouvez la raison
Il n'y a pas d'autre moyen, vérifiez les journaux et effectuez une révision du code.
Afin de garantir la qualité du code, la portée de la révision du code doit être limitée aux modifications du code au cours des 1 ou 2 dernières semaines, car certains codes fonctionnels nécessitent un certain temps pour mûrir avant de pouvoir briller en ligne.
En regardant le dossier de soumission « OK » qui remplissait l'écran, le visage du responsable technique est devenu vert.
"xjjdog a dit : " 80 % des programmeurs ne peuvent pas écrire d'enregistrements de commit ", je pense que 100 % d'entre vous ne peuvent pas l'écrire. "
Tout le monde était silencieux et a enduré la douleur pour vérifier les changements historiques. Après les efforts inlassables de chacun, nous avons finalement trouvé des codes problématiques parmi les montagnes de merde. Un groupe créé par le CxO lui-même, et tout le monde y jette du code susceptible de poser des problèmes.
"Le service du système a été interrompu pendant près d'une heure et l'impact a été très grave." Le CxO a déclaré : "Le problème doit être complètement résolu. Les investisseurs sont très préoccupés par ce problème, avec l'aide de
okokok." DingTalk, les gestes de chacun sont devenus uniformes.
3. Paramètres du pool de threads
Il y a beaucoup de code et tout le monde discute du code problématique depuis longtemps. Cette phrase peut être réécrite comme suit : Nous avons examiné du code complexe utilisant des flux parallèles et imbriqué dans des expressions lambda, en accordant une attention particulière à l'utilisation de pools de threads.
En fin de compte, tout le monde a décidé de revoir le code du pool de threads. L'un des paragraphes dit ceci.
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy(); ThreadPoolExecutor executor = new ThreadPoolExecutor(100,200, 60000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque(10), handler);
Sans oublier que les paramètres sont corrects, et même une stratégie de rejet est envisagée.
Le pool de threads de Java rend la programmation très simple. Ces paramètres ne peuvent pas être revus sans les parcourir un par un, comme le montre l'image ci-dessus.
corePoolSize : le nombre de threads principaux, le thread principal survivra après sa création
maxPoolSize : le nombre maximum de threads
keepAliveTime : temps d'inactivité du thread
-
workQueue : file d'attente de blocage
-
threadFactory : thread Créer une usine
handler : Stratégie de rejet
Présentons leur relation.
Si le nombre de threads est inférieur au nombre de threads principaux et qu'une nouvelle tâche arrive, le système créera un nouveau thread pour gérer la tâche. Si le nombre actuel de threads dépasse le nombre de threads principaux et que la file d'attente de blocage n'est pas pleine, la tâche sera placée dans la file d'attente de blocage. Lorsque le nombre de threads est supérieur au nombre de threads principaux et que la file d'attente de blocage est pleine, de nouveaux threads seront créés pour être servis jusqu'à ce que le nombre de threads atteigne la taille maximale de PoolSize. A ce moment, s'il y a de nouvelles tâches, la politique de rejet sera déclenchée.
Parlons à nouveau de la stratégie de rejet. JDK dispose de 4 stratégies intégrées, dont la valeur par défaut est AbortPolicy, qui lève directement une exception. Plusieurs autres sont présentés ci-dessous.
DiscardPolicy est plus agressif que l'abandon, rejetant directement la tâche sans même les informations d'exception
Le traitement de la tâche est exécuté par le thread appelant, qui est l'implémentation de CallerRunsPolicy. Lorsque les ressources du pool de threads d'une application Web sont pleines, de nouvelles tâches seront attribuées aux threads Tomcat pour exécution. Dans certains cas, cette méthode peut réduire la pression d'exécution de certaines tâches, mais dans la plupart des cas, elle bloquera directement l'exécution du thread principal
-
DiscardOldestPolicy supprime la tâche en début de file d'attente puis tente de s'exécuter. la tâche à nouveau
Ce code de pool de threads a été récemment ajouté et les paramètres sont relativement raisonnables, il n'y a donc pas de gros problème. L’utilisation de la politique de rejet DiscardOldestPolicy est le seul risque possible. Lorsqu'il y a beaucoup de tâches, cette politique de rejet entraînera la mise en file d'attente des tâches et l'expiration du délai d'attente des demandes.
Bien sûr, nous ne pouvons pas laisser de côté ce risque. Pour être honnête, c'est le code de risque le plus probable que l'on puisse trouver jusqu'à présent.
"Remplacez DiscardOldestPolicy par AbortPolicy par défaut, reconditionnez-le et essayez-le en ligne." » a déclaré le gourou technique dans le groupe.
4. Quel est le problème ?
En conséquence, après le lancement du service en niveaux de gris, l'hôte est décédé peu de temps après. C'est la raison pour laquelle il n'a pas fonctionné, mais pourquoi ?
La taille du pool de threads, le minimum est de 100, le maximum est de 200, rien n'est de trop. La capacité de la file d’attente de blocage n’est que de 10, donc rien ne posera de problème. Si vous dites que cela est dû à ce pool de threads, je ne vous croirai même pas à mort.
Mais le service commercial a signalé que si ce code est ajouté, il mourra, mais s'il n'est pas ajouté, tout ira bien. Les experts techniques se grattent la tête et s'interrogent sur sa sœur.
En fin de compte, quelqu'un n'a finalement plus pu s'en empêcher et a téléchargé le code commercial pour le déboguer.
Quand il a ouvert Idea, il était confus et a compris instantanément. Il a enfin compris pourquoi ce code posait problème.
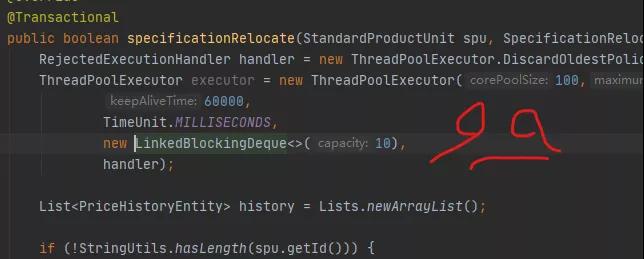
Le pool de threads est en fait créé dans la méthode !
Lorsque chaque demande arrive, il créera un pool de threads jusqu'à ce que le système ne puisse plus allouer de ressources.
Comme c'est dominateur.
Tout le monde fait attention à la façon dont les paramètres du pool de threads sont définis, mais personne n'a jamais douté de l'emplacement de ce code.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Introduction détaillée à la sécurité de la transmission des données de DSMM
- Résumé de 40 ports d'intrusion couramment utilisés par les pirates informatiques qui méritent d'être collectés
- Trois techniques d'injection de processus dans la matrice Mitre ATT&CK
- Principes de pratiques de développement sécuritaires
- Comment corriger la vulnérabilité d'exécution de commande à distance dans le composant Apache Axis