
Maison >base de données >tutoriel mysql >Méthodes d'optimisation et d'indexation MySQL
Méthodes d'optimisation et d'indexation MySQL

- PHPzavant
- 2023-06-02 13:58:211199parcourir
Une brève introduction aux index
L'essence des index :
L'essence des index MySQL ou d'autres index de bases de données relationnelles n'est qu'une phrase, échangez de l'espace contre du temps.
Le rôle de l'index :
Indexer la structure des données de la base de données relationnelle (stockage sur disque) afin d'accélérer la récupération des données des lignes dans la table
Classification de l'index
Catégorie de l'index structure de données ci-dessus :
Index HASH
Haute efficacité de correspondance égale
Ne prend pas en charge la recherche par plage
Indice d'arbre
Binaire arbre, méthode de recherche binaire récursive, gauche petite droite Gros
Arbre binaire équilibré, d'arbre binaire à arbre binaire équilibré, la raison principale est la rotation gauche-droite
Inconvénient 1, trop de fois IO
Inconvénient 2, faible utilisation des IO, Saturation IO
Chemins multiples Arbre de recherche équilibré (B-Tree)
caractéristiques, réduisant considérablement la hauteur de l'arbre
B+ tree
fonctionnalités, en utilisant la comparaison fermée à gauche méthode
nœud de branche de nœud racine Il n'y a pas de zone de données, seuls les nœuds feuilles contiennent la zone de données (pour parler franchement, même si le nœud racine et les nœuds enfants ont été localisés, cela ne s'arrêtera pas car il n'y a pas de zone de données , et continuera jusqu'à ce que le nœud feuille soit trouvé.)
Lorsque nous recherchons les données 13, nous pouvons localiser à la fois le nœud racine et le nœud enfant, mais nous trouverons toujours le nœud feuille.
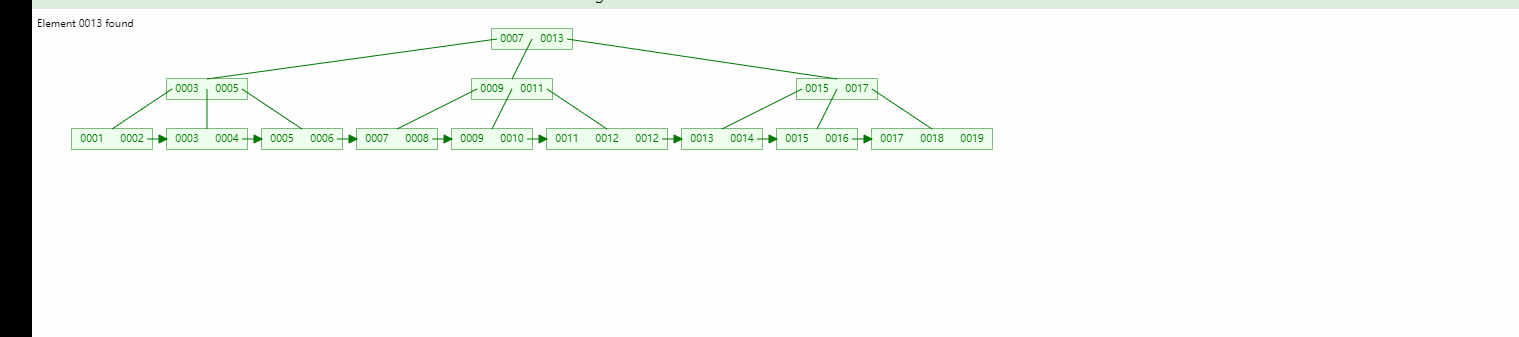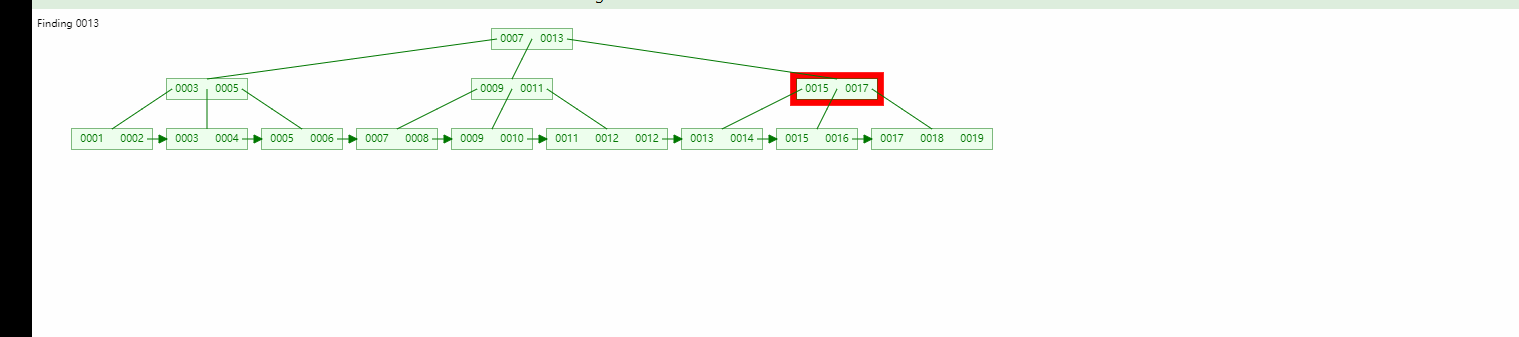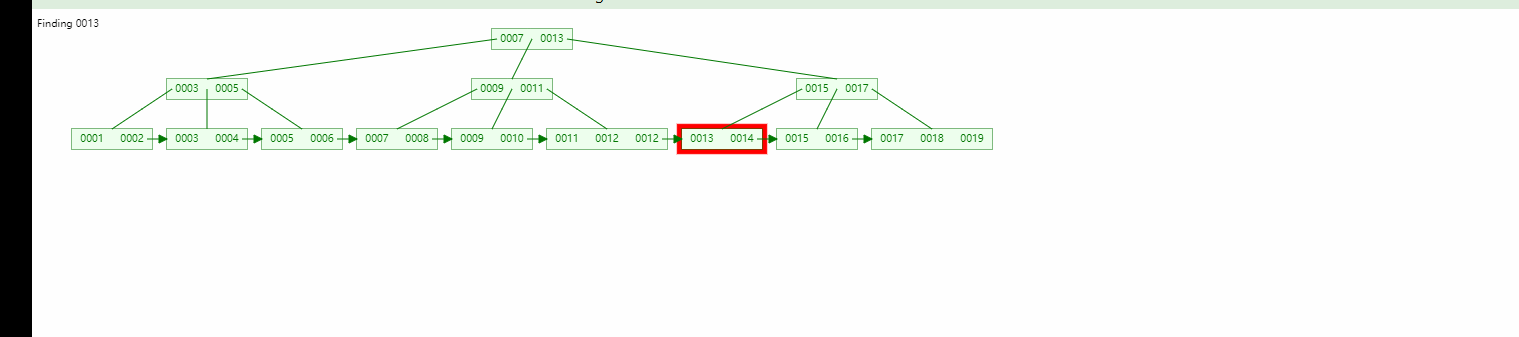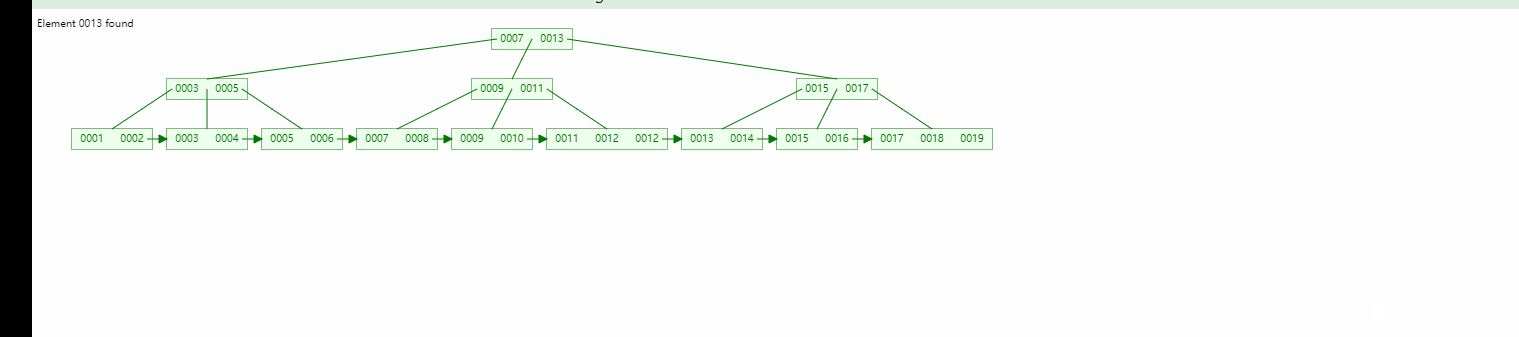
Arbre binaire Arbre binaire équilibré, comparaison B-tree :
Comme le montre la figure, s'il s'agit d'une clé primaire auto-croissante :
L'arbre binaire n'est évidemment pas adapté aux bases de données relationnelles indexation (pas différent de l'analyse complète de la table) .
Quant à l'arbre binaire équilibré, bien qu'il résolve cette situation, il rendra également l'arbre mince et grand, ce qui entraînera également trop de temps d'E/S de requête et une faible utilisation des E/S mentionnée ci-dessus.
B-tree a évidemment résolu ces deux problèmes, donc ce qui suit explique pourquoi MySQL utilise toujours l'arbre B+ dans ce cas et a apporté ces améliorations.

Comparaison du B-tree et du B+-tree :

Optimisation de l'arbre B+ sur le B-tree :
IO est plus efficace (chaque nœud du B-tree conservera le zone de données, contrairement aux arbres B+. En supposant que nous devions parcourir trois couches pour interroger une donnée, alors évidemment la consommation d'E/S dans la requête d'arborescence B+ est plus petite)
L'efficacité de la recherche de plage est plus élevée (comme indiqué dans le figure, l'arbre B+ a formé une forme de liste chaînée naturelle, et n'a besoin d'être basé que sur la dernière recherche de structure de chaîne)

L'analyse des données basée sur un index est plus efficace.
Classification des types d'index
Les types d'index peuvent être divisés en deux catégories :
Index de clé primaire
index auxiliaire (index secondaire)
Index unique
-
Indice composé
Index normal
Indice de couverture
Bien que les performances de l'index de clé primaire soient relativement meilleures, généralement dans l'optimisation SQL, nous améliorerons et compléterons l'index auxiliaire.
L'arborescence B+ est implémentée au niveau du moteur de stockage
Nous créons respectivement deux tables
test_innodb(en utilisant InnoDB comme moteur de stockage) test_myisam (en utilisant MyISAM comme moteur de stockage) La figure suivante représente les fichiers pertinents pour l'implémentation du disque des deux tables. Les deux moteurs de stockage sur le plancher de disque d'arborescence B+ sont complètement différents.
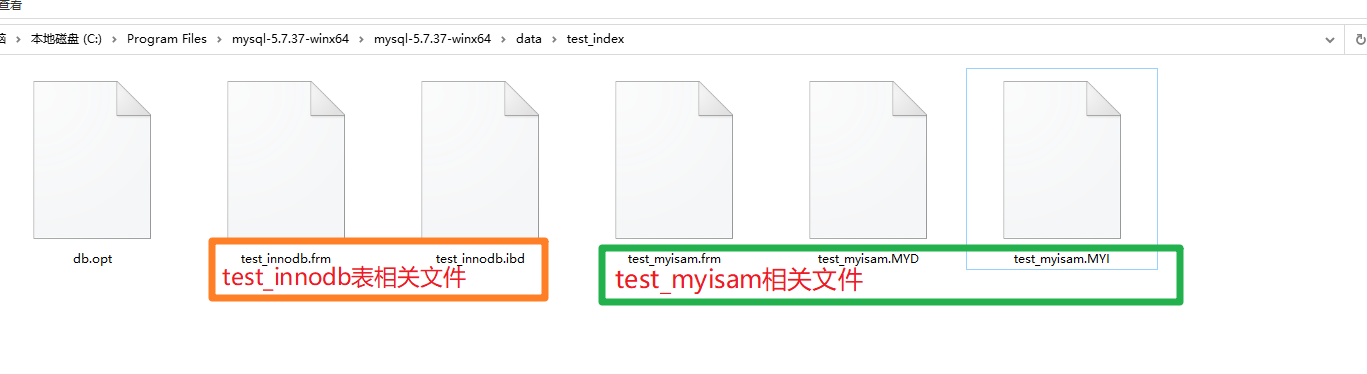
L'arborescence B+ est implémentée dans MyISAM :
*.frm est un fichier squelette de table. Par exemple, quel type de champ de nom de champ d'identifiant dans cette table est stocké ici
. *.MYD (D=data) stocke les données
*.MYI (I=index) stocke l'index

Par exemple, si l'instruction SQL suivante est exécutée maintenant, alors dans MyISAM, elle est d'abord dans test_myisam.MYI, recherchez-y 103, obtenez l'adresse 0x194281, puis recherchez les données dans test_myisam.MYD et renvoyez-les.
SELECT id,name from test_myisam where id =103
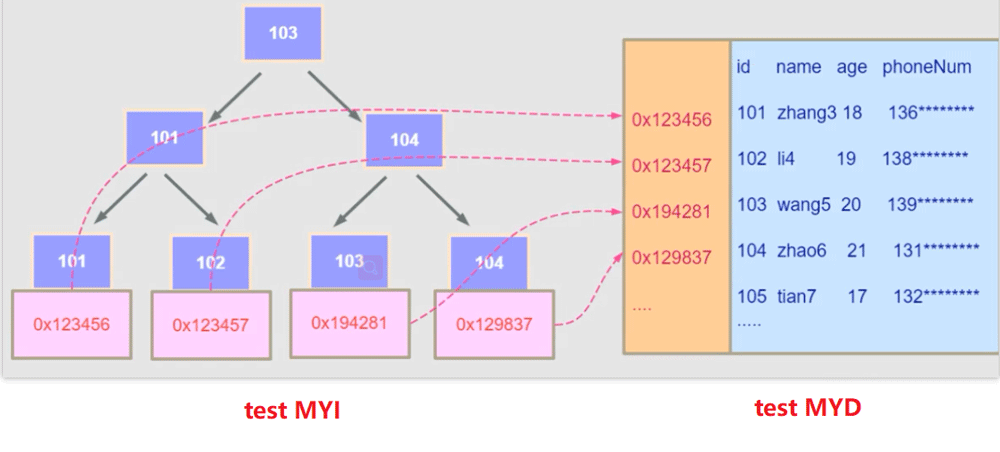
如果
test_myisam表中,id为主键索引,name也是一个索引,那么在test_myisam.MYI中则会有两个平级的B+树,这也导致MyISAM引擎中主键索引和二级索引是没有主次之分的,是平级关系。因为这种机制在MyISAM引擎中,有可能使用多个索引,在InnoDB中则不会出现这种情况。
B+树在InnoDB落地:

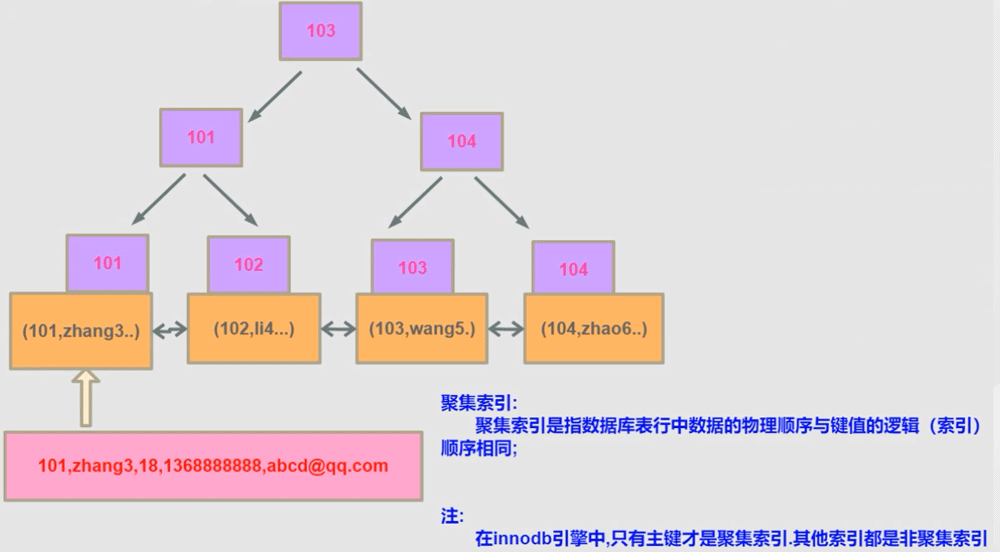
InnoDB不像MyISAM来独立一个MYD 文件来存储数据,它的数据直接存储在叶子结点关键字对应的数据区在这保存这一个id列所有行的详细记录。
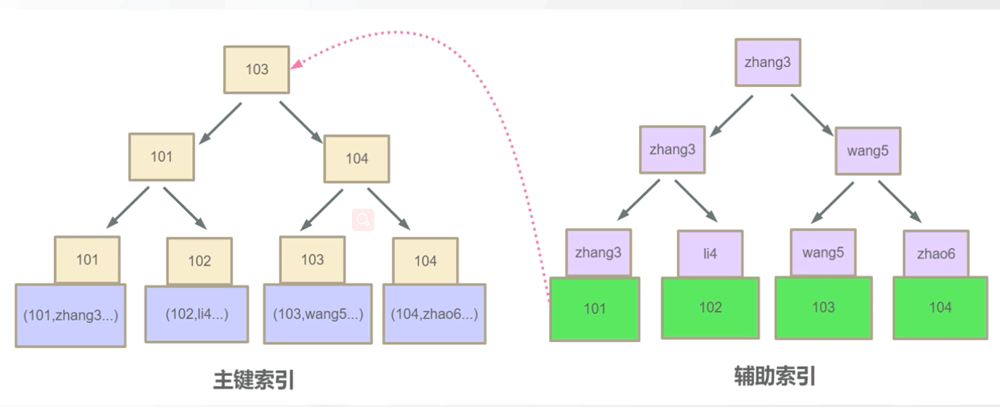
InnoDB 主键索引和辅助索引关系
我们现在执行如下SQL语句,他会先去找辅助索引,然后找到辅助索引下101的主键,再去回表(二次扫描)根据主键索引查询103这条数据将其返回。
SELECT id,name from test_myisam where name ='zhangsan'
这里就有一个问题了,为什么不像MyISAM在辅助索引下直接记录磁盘地址,而是要多此一举再去回表扫描主键索引,这个问题在下面相关面试题中回答,记一下这个问题是这里来的。
相关面试题
为什么MySQL选择B+树作为索引结构
这个就不说了,上文应该讲清楚了。
B+树在MyISAM和InnoDB落地区别。
这个可以总结一下,MyISAM落地数据储存会有三个类型文件 ,.frm文件是表骨架文件,.MYD(D=data)则储存数据 ,.MYI (I=index)则储存索引,MyISAM引擎中主键索引和二级索引平级关系,在MyISAM引擎中,有可能使用多个索引,InnoDB则相反,主键索引和二级索有严格的主次之分在InnoDB一条语句只能用一个索引要么不用。
如何判断一条sql语句是否使用了索引。
可以通过执行计划来判断 可以在sql语句前explain/ desc
set global optimizer_trace='enabled=on' 打开执行计划开关他将会把每一条查询sql执行计划记录在information_schema 库中OPTIMIZER_TRACE表中
为什么主键索引最好选择自增列?
自增列,数据插入时整个索引树是只有右边在增加的,相对来说索引树的变动更小。
为什么经常变动的列不建议使用索引?
和上一个问题原因一样,当一个索引经常发生变化,那么就意味这,这个缩印树也要经常发生变化。4
为什么说重复度高的列,不建议建立索引?
这个原因是因为离散性,比如说,一张一百万数据的表,其中一个字段代表性别,0代表男1代表女,把这字段加了索引,那么在索引树上,将会有大量的重复数据。而我们常见的索引建立一般都是驱动型的。其目的是,尽可能的删减数据的查询范围,这个显然是不匹配的。
什么是联合索引
联合索引是一个包含了多个功效的索引,他只是一个索引而不是多个,
其次,单列索引是一种特殊的联合索引
联合索引的创立要遵循最左前置原则(最常用列>离散度>占用空间小)
什么是覆盖索引
通过索引项信息可直接返回所需要查询的索引列,该索引被称之为覆盖索引,说白了就是不需要做回表操作,可以从二级索引中直接取到所需数据。
什么是ICP机制
索引下推,简单点来说就是,在sql执行过程中,面对where多条件过滤时,通过一个索引,完成数据搜索和过滤条件其,特点能减少io操作。
在InnoDB表中不可能没有主键对还是不对原因是什么?
首先这句话是对的,但是情况有三种:
C'est-à-dire que lorsque vous spécifiez manuellement ce champ comme clé primaire, ce champ sera utilisé comme index clusterisé.
Il existe deux situations dans lesquelles la clé primaire n'est pas explicitement spécifiée :
Il recherchera le premier Royaume-Uni (clé unique) comme index de clé primaire pour organiser la disposition des index.
Si ni la clé primaire ni le Royaume-Uni ne sont spécifiés, le rowId (chaque enregistrement de la table InnoDB aura un rowId caché (6 octets)) sera utilisé comme index clusterisé.
Qu'est-ce qu'une opération de retour de table
Dans InnoDB, le contenu interrogé en fonction de l'index auxiliaire ne peut pas être obtenu directement à partir de l'index auxiliaire. L'opération qui nécessite une analyse secondaire basée sur la clé primaire. index est appelé une opération de retour de table.
Pourquoi la zone de données du nœud feuille d'index auxiliaire dans InnoDB enregistre-t-elle la valeur de l'index de clé primaire au lieu d'enregistrer l'adresse du disque comme dans MyISAM.
La raison est en fait très simple, car la structure des données de l'index de clé primaire change fréquemment. Si l'adresse du disque est enregistrée dans la zone de données d'index auxiliaire, alors en supposant que nous ayons 10 index auxiliaires, lorsque notre index de clé primaire est enregistré. changements de structure Enfin, les index auxiliaires doivent être notifiés un par un, et la structure de l'index de clé primaire change fréquemment, et les ajouts et suppressions peuvent affecter sa structure de données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!