
Maison >base de données >tutoriel mysql >À quoi fait référence le retour de la table MySQL ?
À quoi fait référence le retour de la table MySQL ?

- 王林avant
- 2023-06-01 22:46:043225parcourir
Introduction
Pour faire simple, le retour de table signifie que MySQL doit d'abord interroger l'index de clé primaire, puis utiliser l'index de clé primaire pour localiser les données.
Ci-dessous, nous analysons et répondons à quelques questions :
Qu'est-ce qu'un index clusterisé ? Qu'est-ce qu'un index non clusterisé ?
Pourquoi devons-nous d'abord rechercher l'index de clé primaire lors du retour d'une table ?
Quelle est la différence entre un index de clé primaire et un index de clé non primaire ?
Comment éviter le retour de formulaire ?
Que sont les index clusterisés et les index non clusterisés ?
Les index MySQL sont classés sous différentes perspectives, telles que : par structure de données, par perspective logique et par stockage physique.
Parmi eux, il existe deux types d'index basés sur le stockage physique : index clusterisé et index non cluster.
En termes simples, index clusterisé est un index de clé primaire.
Outre l'index de clé primaire, il y a l'index non clusterisé L'index non clusterisé est également appelé index auxiliaire ou index secondaire.
Quelle est la différence entre un index de clé primaire et un index de clé non primaire ?
Mêmes points : Les deux utilisent B+Tree.
Différences : Les nœuds feuilles stockent différentes données
Les nœuds feuilles de l'index de clé primaire stockent une ligne complète de données
Les nœuds feuilles de l'index de clé non primaire stockent la primaire ; valeur clé . Le nœud feuille ne contient pas toutes les données de l'enregistrement. En plus de la clé utilisée pour le tri, le nœud feuille de clé non primaire contient également un signet (bookmark), qui stocke la clé de l'index clusterisé.
Alors quelles sont les différences d’usage entre ces deux index ?
Requête utilisant l'index de clé primaire :
# 主键索引的的叶子节点存储的是**一行完整的数据**, # 所以只需搜索主键索引的 B+Tree 就可以轻松找到全部数据 select * from user where id = 1;
Requête utilisant l'index de clé non primaire :
# 非主键索引的叶子节点存储的是**主键值**, # 所以MySQL会先查询到 name 列的索引的 B+Tree,搜索得到对应的主键值 # 然后再去搜索该主键值查询主键索引的 B+Tree 才可以找到对应的数据 select * from user where name = 'Jack';
On peut voir que l'utilisation d'un index de clé non primaire utilise un B+Tree de plus que l'index de clé primaire.
Une compréhension simple de B-Tree et B+Tree
La clé pour comprendre les index clusterisés et les index non clusterisés réside dans la compréhension de B+Tree.
En utilisant une image pour le représenter, le reste ne sera pas trop expliqué :
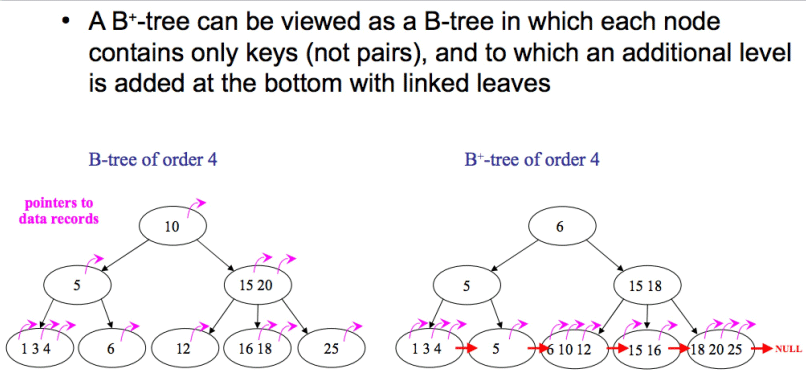
Voici juste une brève introduction à la différence entre B-Tree et B+Tree :
Dans B+Tree Seuls les nœuds feuilles auront des pointeurs vers des enregistrements, tandis que tous les nœuds du B-tree auront des pointeurs et les éléments d'index qui apparaissent dans les nœuds internes n'apparaîtront plus dans les nœuds feuilles.
Tous les nœuds feuilles de l'arbre B+ sont connectés entre eux via des pointeurs, contrairement à l'arbre B.
Comment éviter le retour de formulaire ?
Utilisez un index de couverture. Le soi-disant index de couverture signifie que l'index contient tous les champs de la requête. Dans ce cas, il n'est pas nécessaire d'effectuer une requête vers la table.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!