
Maison >base de données >tutoriel mysql >Quelles sont les solutions pour la synchronisation des données MySQL avec Elasticsearch ?
Quelles sont les solutions pour la synchronisation des données MySQL avec Elasticsearch ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-01 18:37:281606parcourir
Récupération de produits
Vous auriez dû rechercher des produits sur différents sites de commerce électronique. Comment recherchez-vous habituellement des produits ? Moteur de recherche Elasticsearch.
Ensuite, la question se pose. Lorsqu'un produit est mis en rayon, les données sont généralement écrites dans la base de données MySQL. Alors, comment les données utilisées pour la récupération sont-elles synchronisées avec Elasticsearch ?
MySQL synchronise ES
1. Double écriture synchrone
C'est la manière la plus directe imaginable Lors de l'écriture sur MySQL, une copie des données est également directement écrite sur ES simultanément.
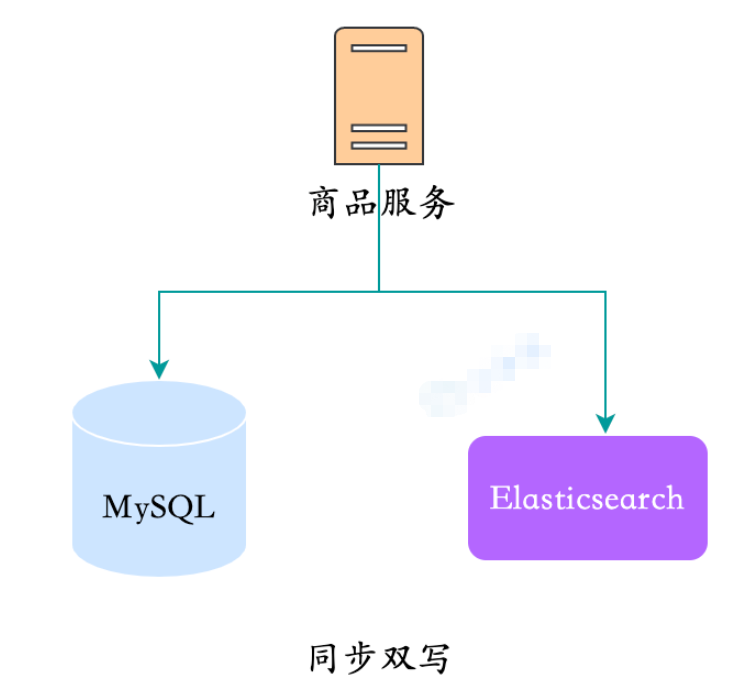
Double écriture synchrone
Pour cette méthode :
Avantages : Mise en œuvre simple
Inconvénients :
Couplage métier, couplage d'une grande quantité de code de synchronisation de données dans la gestion des marchandises
affecte les performances , écriture Avec deux stockages, le temps de réponse devient plus long
Incommode à étendre : la recherche peut avoir des exigences personnalisées et nécessiter d'agréger des données, ce qui est peu pratique à mettre en œuvre
2. Pensez-y facilement Dans la méthode asynchrone de double écriture, lors de la liste des produits, les données du produit sont d'abord jetées dans MQ. Afin de comprendre le couplage, nous divisons généralement un service de recherche et le service de recherche s'abonne aux nouvelles des modifications du produit. pour terminer la synchronisation.
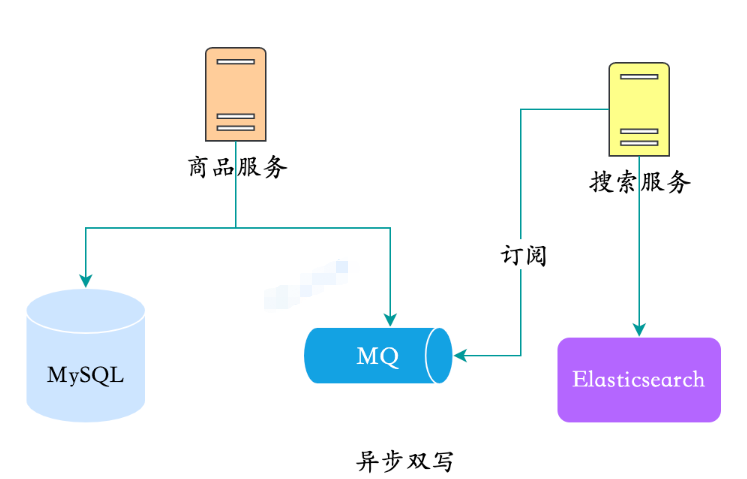 Double écriture asynchrone
Double écriture asynchrone
Comme mentionné précédemment, que dois-je faire si certaines données doivent être agrégées dans une structure similaire à un large tableau ? Par exemple, les tables de catégories de produits, spu et sku de la bibliothèque de produits sont séparées, mais la requête est multidimensionnelle. Il sera moins efficace de les agréger à nouveau dans ES. Il est préférable d'agréger les données du produit et de les utiliser. dans ES de la même manière, il est stocké sous la forme d'un large tableau, de sorte que l'efficacité des requêtes est plus élevée.
Requête multidimensionnelle et multi-conditions
Il n'existe en fait aucun bon moyen de le faire. Fondamentalement, vous devez toujours rechercher le service pour vérifier directement la base de données, ou l'appeler à distance et interroger à nouveau la base de données du produit, ce qui est le cas. ce qu'on appelle le back-check.
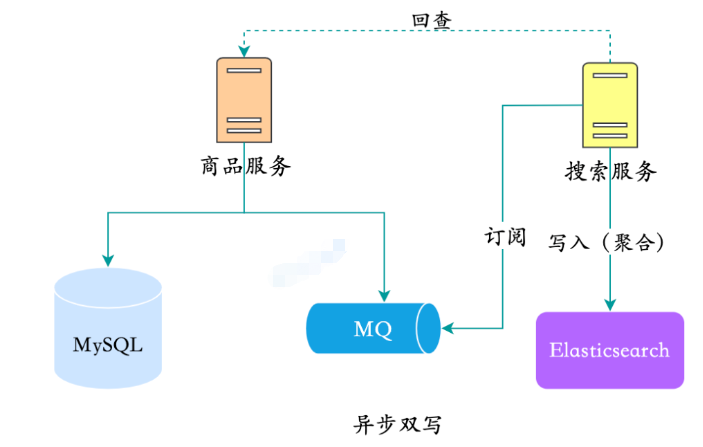 Révision pour compléter l'agrégation
Révision pour compléter l'agrégation
De cette façon :
Avantages :
- Le découplage, les produits et services n'ont pas besoin de prêter attention à la synchronisation des données
- Bonnes performances en temps réel, en utilisant MQ, sous Dans des circonstances normales, la synchronisation est terminée. Au deuxième niveau
- Inconvénients :
- Introduit de nouveaux composants et services, augmentant la complexité
- 3. les données ne sont pas si volumineuses ? Que faire ? Des tâches planifiées sont également disponibles.
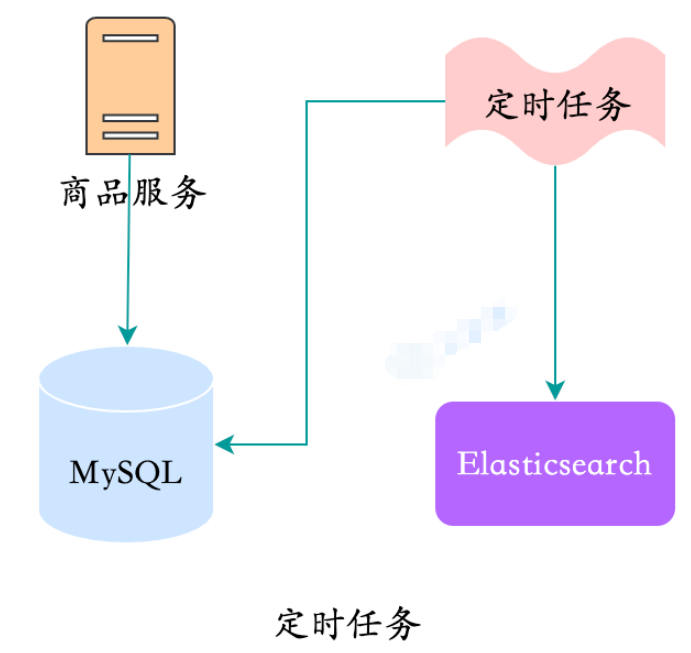 La chose la plus gênante à propos des tâches planifiées est que la fréquence est difficile à choisir. Si la fréquence est élevée, elle formera de manière anormale des pics d'activité, entraînant une augmentation de l'utilisation du processeur de stockage et de la mémoire. Si la fréquence est faible, elle augmentera en temps réel. Le sexe est relativement médiocre et il y a aussi des pics.
La chose la plus gênante à propos des tâches planifiées est que la fréquence est difficile à choisir. Si la fréquence est élevée, elle formera de manière anormale des pics d'activité, entraînant une augmentation de l'utilisation du processeur de stockage et de la mémoire. Si la fréquence est faible, elle augmentera en temps réel. Le sexe est relativement médiocre et il y a aussi des pics.
Cette méthode :
Avantages : relativement simple à mettre en œuvre
Inconvénients :
difficile de garantir des performances en temps réel
pression plus élevée sur le stockage
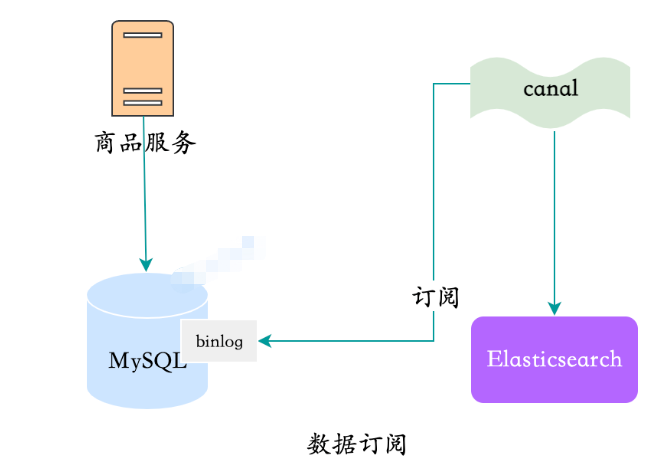
4. , c'est l'abonnement de données le plus populaire.
MySQL réalise la synchronisation maître-esclave grâce à l'abonnement binlog. Divers cadres d'abonnement aux données tels que canal utilisent ce principe pour déguiser le composant client en bibliothèque esclave pour implémenter l'abonnement aux données.
, y compris l'adaptateur ES. Après avoir commencé avec certaines configurations, vous pouvez directement synchroniser les données MySQL avec. ES, ce processus est sans code. 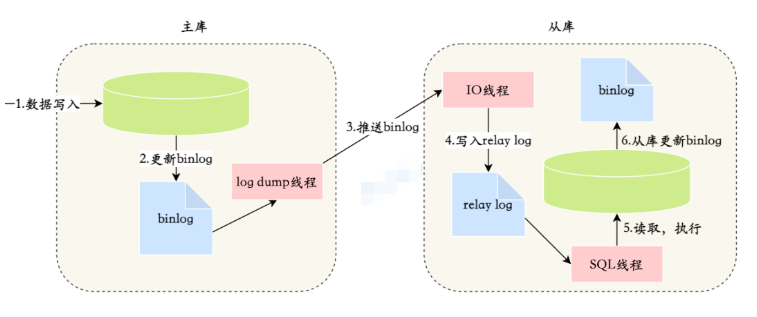
données de synchronisation du canalcanal-adapter
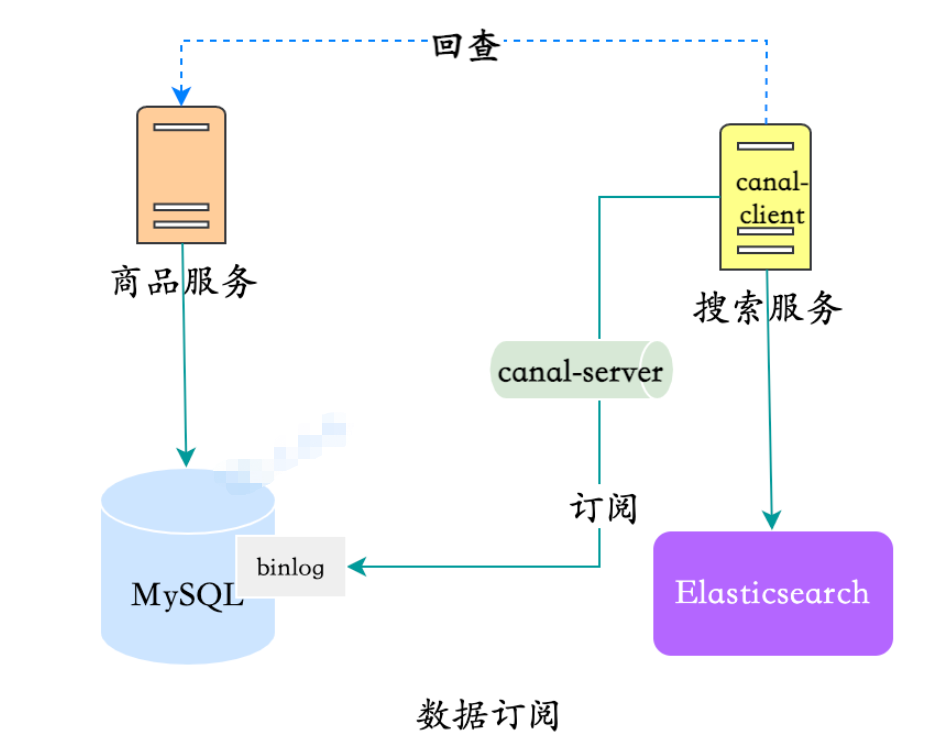
 En raison de la prise en charge limitée de Canal, l'agrégation de données de plusieurs tables mentionnée ci-dessus doit encore être mise en œuvre par révision. Pour le moment, il n'est pas approprié d'utiliser canal-adapter. Vous devez implémenter canal-client vous-même, surveiller et agréger les données, et écrire dans ES :
En raison de la prise en charge limitée de Canal, l'agrégation de données de plusieurs tables mentionnée ci-dessus doit encore être mise en œuvre par révision. Pour le moment, il n'est pas approprié d'utiliser canal-adapter. Vous devez implémenter canal-client vous-même, surveiller et agréger les données, et écrire dans ES :
 Alors utilisez l'abonnement aux données :
Alors utilisez l'abonnement aux données :
Avantages :
Moins d'intrusion commerciale
- Meilleures performances en temps réel
En ce qui concerne la sélection des frameworks d'abonnement aux données, les plus courants sont généralement les suivants :
| Cancal | Maxwell | Python-Mysql-Rplication | |
|---|---|---|---|
| Open Source | Alibaba | Communauté ZendeskHaute disponibilité | |
| Support | Pas de support | Client | |
| Aucun | Python | Atterrissage de messages | |
| Kafka/RabbitNQ/Redis etc. | personnalisé | Format du message | |
| JSON | Personnalisé | Document détaillé | |
| Détaillé | Détaillé | Boostrap | |
| Supporté | Non pris en charge | ||
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!